IPFS是如何進行檔案存盤的
- IPFS采用的索引結構是DHT(分布式哈希表),資料結構是MerkleDAG(Merkle有向無環圖)
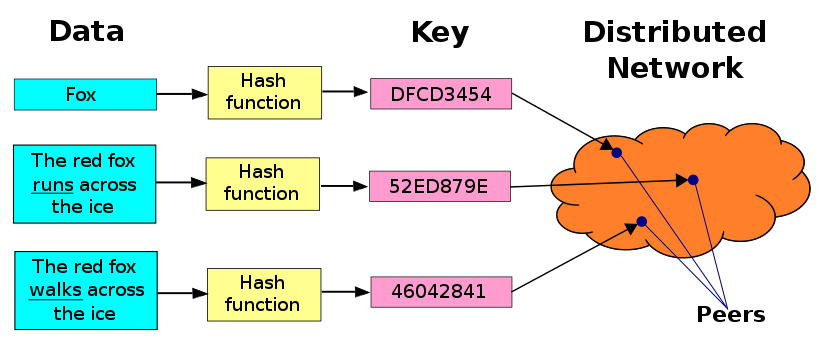
DHT(分布式哈希表)
- 參考鏈接
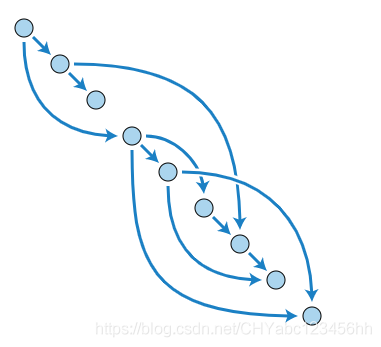
MerkleDAG(Merkle有向無環圖)
- 參考鏈接
MerkleDAG功能
- 內容尋址:使用多重哈希來唯一識別一個資料塊的內容
- 防篡改:可以方便的檢查哈希值來確認資料是否被篡改,如果資料被篡改或損壞,IPFS會檢測到
- 去重:由于內容相同的資料塊哈希是相同的,可以很容去掉重復的資料,節省存盤空間
IPFS的單檔案存盤
步驟
- 1、把單個檔案拆分成若干個256KB大小的塊(block);
- 2、逐塊(block)計算blockhash,hashn=hash(blockn);
- 3、把所有的blockhash拼湊成一個陣列,再計算一次hash,便得到了檔案最終的hash,hash(file)=hash(hash1……n),并將這個hash(file)和blockhash陣列“捆綁”起來,組成一個物件,把這個物件當做一個索引結構;
- 4、把block,索引結構全部上傳給IPFS節點,檔案便同步到了IPFS網路了;
注意
- 小檔案(小于1KB)的檔案,IPFS會把資料內容直接和Hash(索引)放在一起上傳給IPFS節點,不會再額外的占用一個block的大小
- 如果對于大的檔案進行資料的追加操作,僅僅是新增1KB的資料,也需要重新上傳嗎?事實并非如此,IPFS在儲存資料的時候,同一份資料只存盤一次,檔案是分塊(block)存盤的,hash相同的block,只會存盤一次,也就說,前面1G的內容沒有發生改變,其實IPFS并不會為這些資料分配新的空間,只會為最后1K的資料分配一個新的block,再重新上傳hash,實際占用的空間是:1G+1K;
- 即使是不同檔案的相同部分也僅僅會存盤一份,比如電影資源的影音部分相同,但是只有字幕部分不一樣,那么不同的字幕會和音影資源拼接,形成新的檔案資源,這樣一來就可能會有很多檔案的索引指向同一個block,就構成了前面提到的一個資料結構——MerkleDAG,
參考鏈接
- DHT 分布式哈希表
- Merkle trees and directed acyclic graphs (DAG)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/186469.html
標籤:其他