作者|Bex Tuychiev
編譯|VK
來源|Towards Datas Science
介紹
本文的目標是讓你對使用Seaborn的relplot()函式繪制統計圖有一定的了解,
當我開始學習資料可視化時,我第一次被介紹到Matplotlib,它是一個如此巨大的庫,你幾乎可以看到任何與資料相關的東西,正是這種廣闊的空間,使人們能夠以多種方式創造一個單一的圖表,
雖然它的靈活性對于經驗豐富的科學家來說是理想的,但作為一個初學者,要區分這些方法之間的代碼對我來說簡直是一場噩夢,作為一名程式員,我甚至考慮過使用Tableau的無代碼介面,這一點我深感羞愧,我想要一個易于使用的東西,同時,使我能夠創建那些其他人(在代碼中)正在制作的酷圖,
我在學生階段了解了Seaborn,最后找到了我的選擇,我對資料可視化的黃金法則理解是“如果你能在Seaborn做的話,就在Seaborn做”,它比其對應的Matplotlib提供了許多優勢,
首先,它非常容易使用,只需幾行代碼就可以創建復雜的繪圖,并且使用內置樣式仍然可以使其看起來很漂亮,其次,它與Pandas資料幀配合得非常好,這正是作為資料科學家所需要的,
最后但并非最不重要的是,它構建在Matplotlib本身之上,這意味著你將享受Mpl提供的大部分靈活性,同時仍將代碼語法保持在最低限度,
Seaborn將其所有API分為三類:繪制統計關系、可視化資料分布和分類資料繪圖,Seaborn提供了三個高級函式,它們包含了它的大部分特征,其中之一是relplot(),
relplot()可以可視化定量變數之間的任何統計關系,在本文中,我們將介紹這個函式的幾乎所有特性,包括如何創建子圖等等,
概述
- 簡介
- 安裝
- 帶有relplot()的散點圖
- 散點圖的點大小
- 散點圖的色調
- 散點圖樣式
- 散點圖的點透明度
- 散點圖中的子圖
- 線圖
- 多行線圖
- 線圖線條樣式
- 線條的點標記
- 線圖置信區間
- 結論
獲取此GitHub repo上文章的notebook和示例資料:https://github.com/BexTuychiev/medium_stories/tree/master/learn_one_third_of_seaborn_relplot
安裝
# 加載必要的庫
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 繪制漂亮的圖形,避免模糊的影像
%config InlineBackend.figure_format = 'retina'
# 設定環境
sns.set_context('notebook')
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 啟用多個單元輸出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
我們以sns的縮寫匯入Seaborn,你可能一直在想,為什么它不被縮寫為sb,好吧,看看這個:它的別名來自電視劇《The West Wing》中的一個虛構人物Samuel Norman Seaborn,這是一個開玩笑的首字母縮寫,
對于示例資料,我將使用Seaborn的一個內置資料集和一個我從Kaggle下載的資料集,你可以通過這個鏈接得到它:https://www.kaggle.com/dgawlik/nyse/download
# 加載示例資料
cars = sns.load_dataset('mpg')
stocks = pd.read_csv('data/prices-split-adjusted.csv',
parse_dates=['date'],
index_col=0)
第一個資料集是關于汽車的資料,包括發動機、車型等,第二個資料集提供了500多家公司的紐約股票價格資訊,
基礎探索
cars.head()
cars.info()
cars.describe()
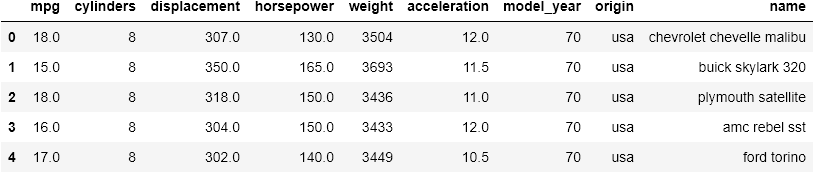
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 392 non-null float64
4 weight 398 non-null int64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null object
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
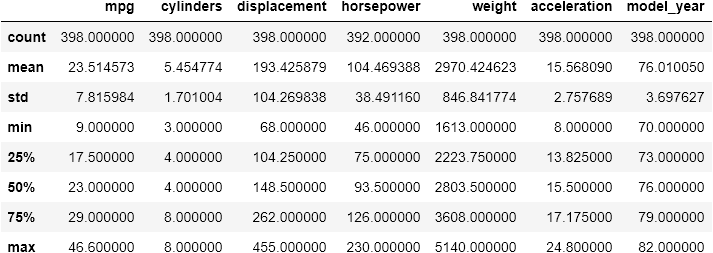
stocks.head()
stocks.info()
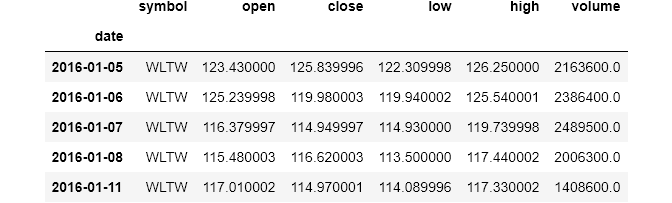
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 851264 entries, 2016-01-05 to 2016-12-30
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 symbol 851264 non-null object
1 open 851264 non-null float64
2 close 851264 non-null float64
3 low 851264 non-null float64
4 high 851264 non-null float64
5 volume 851264 non-null float64
dtypes: float64(5), object(1)
memory usage: 45.5+ MB
兩個資料集中都有一些空值,我們目的是演示,我們就可以放心的丟棄它們,
cars.dropna(inplace=True)
stocks.dropna(inplace=True)
專業提示:讓你的資料集盡可能的整潔,這樣Seaborn才能表現出色,確保每一行都是一個觀察值,每一列都是一個變數,
使用relplot繪散點圖
讓我們從散點圖開始,散點圖是用來找出變數之間的模式和關系的最好和最廣泛使用的圖之一,
這些變數通常是定量的,例如測量值、一天中的溫度或任何數值,散點圖將x和y值的每個元組可視化為一個點,并且該圖將形成一個點云,這些型別的圖是人眼探測模式和關系的理想選擇,
你可以使用sb(我將從現在開始縮寫為sb)的內置scatterplot()函式創建散點圖,但是這個函式缺少relplot()中版本所提供的靈活性,讓我們看一個使用relplot()的示例,

利用汽車資料集,我們想知道重型汽車是否具有更大的馬力,由于這兩個特征都是數值型的,我們可以使用散點圖:
sns.relplot(x='weight', y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars, kind='scatter');
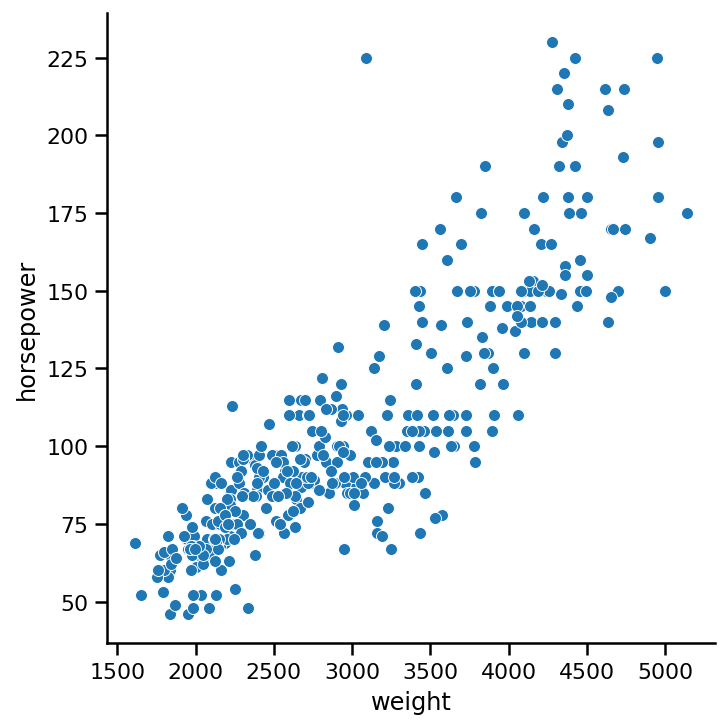
函式具有引數x、y和data引數,分別指定要在X、Y軸上繪制的值以及它應該使用的資料,我們使用kind引數指定它應該使用散點圖,實際上,默認情況下,它被設定為scatter,
從圖表來看,可以解釋為較重的汽車確實有更大的馬力,很明顯,還有更多的汽車重量在1500到3000之間,馬力50-110,
散點圖的點大小
在前面的圖的基礎上,現在我們還想添加一個新變數,讓我們看看重車是否有更大的排量(他們能儲存多少燃料),理想情況下,我們希望將此變數繪制為點的大小:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement');
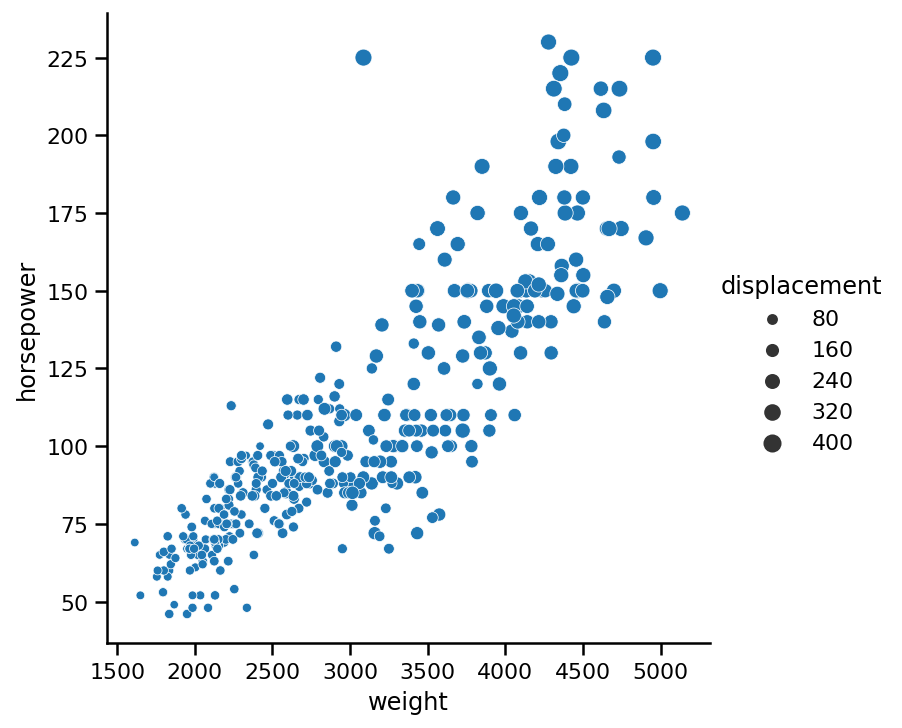
使用size引數來改變相對于第三個變數的點大小,只需將列名作為字串傳遞,就可以進行設定,就像我們的示例中一樣,此圖顯示了重量和發動機尺寸之間的明確關系,但是,你可以在中心看到一些不符合趨勢的點,
重要的是傳遞一個數值變數,它將具有較少的“值周期”,如果太多的話,你的眼睛會很難理解這些事情,如果我們用第三個變數weight創建上面的圖,你可以看到:
sns.relplot(x='displacement',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='weight');
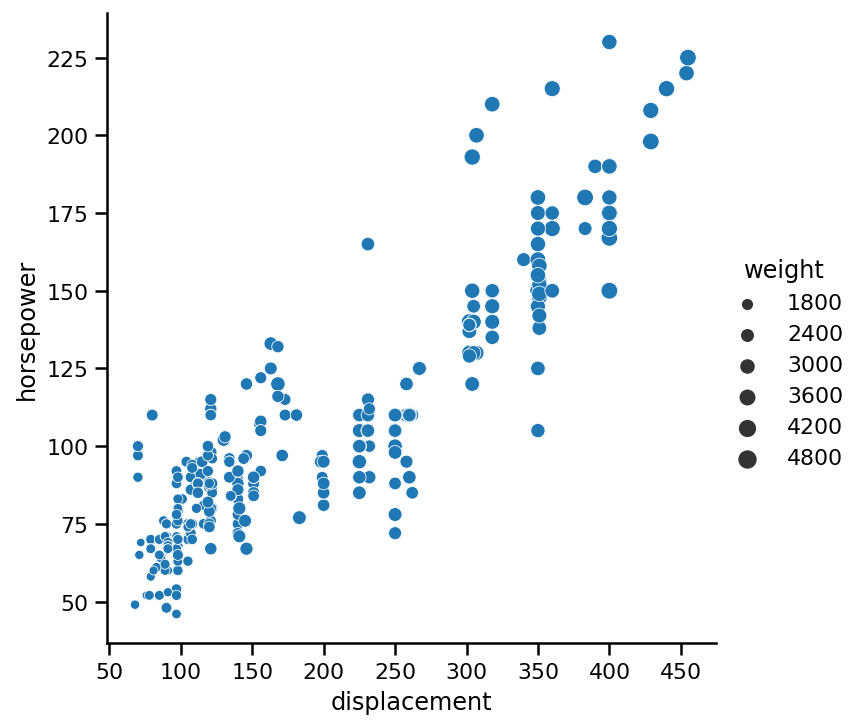
正如你所見,趨勢并不明顯,很難區分大小,
散點圖的色調
也可以將顏色標記用于散點圖中的第三個變數,它也非常簡單,就像點大小一樣,假設我們還想將加速度(汽車達到60英里/小時(秒)的時間)編碼為點顏色:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='acceleration');
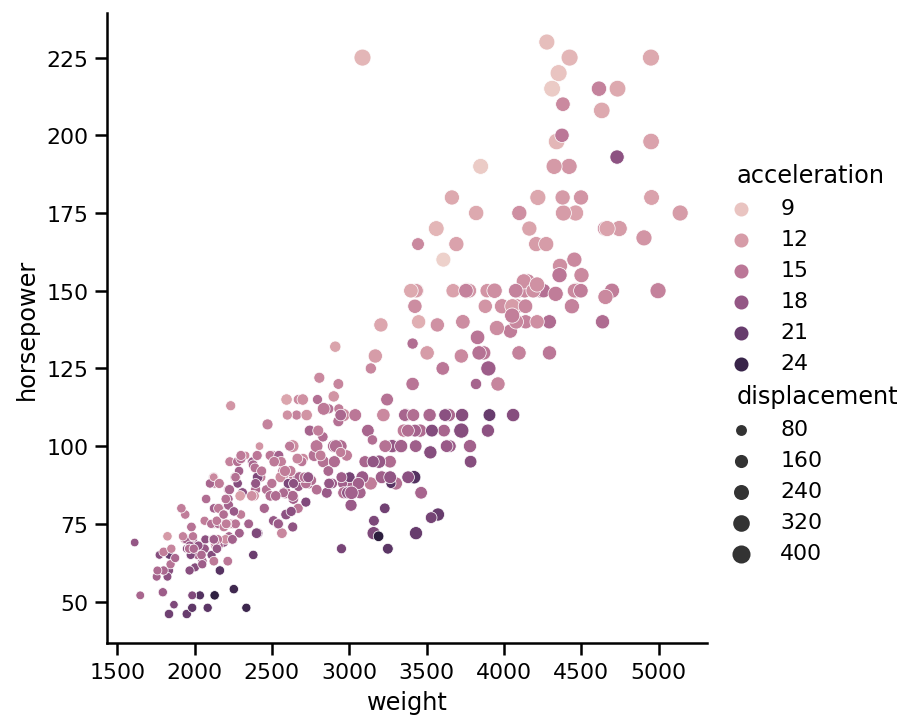
從圖中,我們可以看到資料集中一些速度最快的汽車(較暗的點)馬力較低,但重量也較輕,注意,我們使用hue引數來編碼顏色,顏色根據傳遞給此引數的變數型別而變化,如果我們傳遞origin列,它是一個范疇變數,那么它將有三個顏色標記,而不是一個連續的(從亮到暗)色調:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='origin');
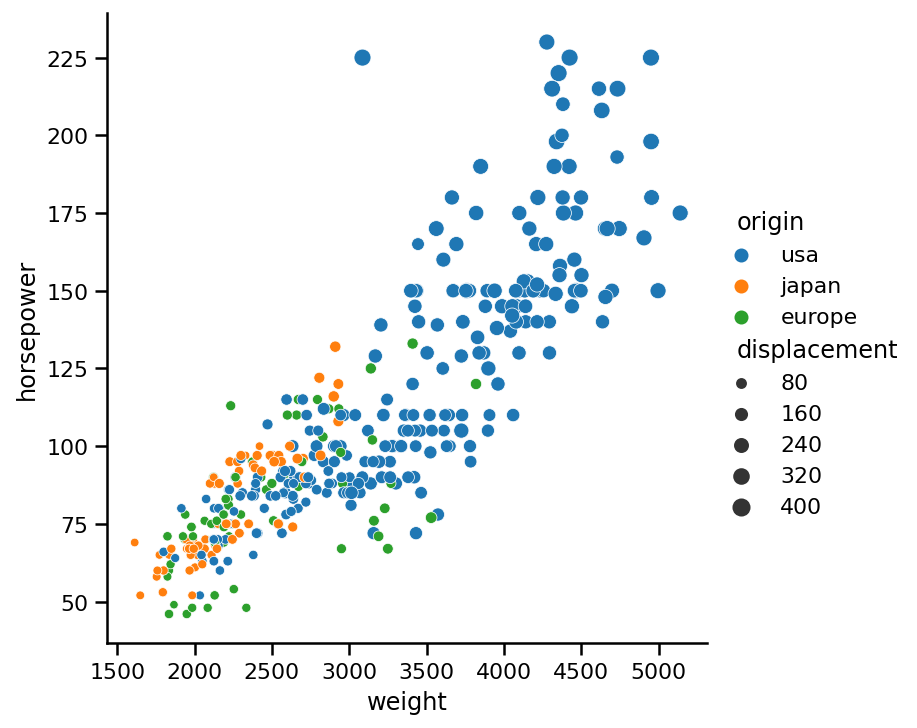
專業提示:注意輸入到hue引數的變數型別,型別可以完全更改結果,
如果你不喜歡默認調色板(默認情況下非常好),可以輕松自定義:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest');
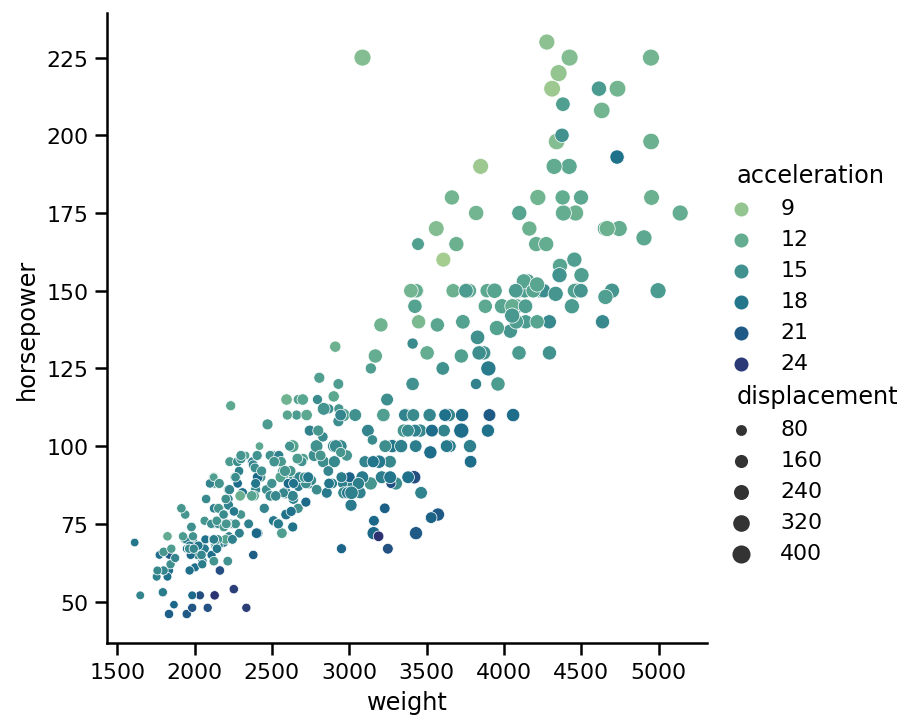
將palette引數設定為你自己的顏色映射,可在此處找到可用選項板的串列:http://seaborn.pydata.org/tutorial/color_palettes.html
散點圖樣式
讓我們回到第一個圖,我們繪制了重量與馬力的散點圖,現在,讓我們添加origin列作為第三個變數:
sns.relplot(x='weight', y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars, hue='origin');
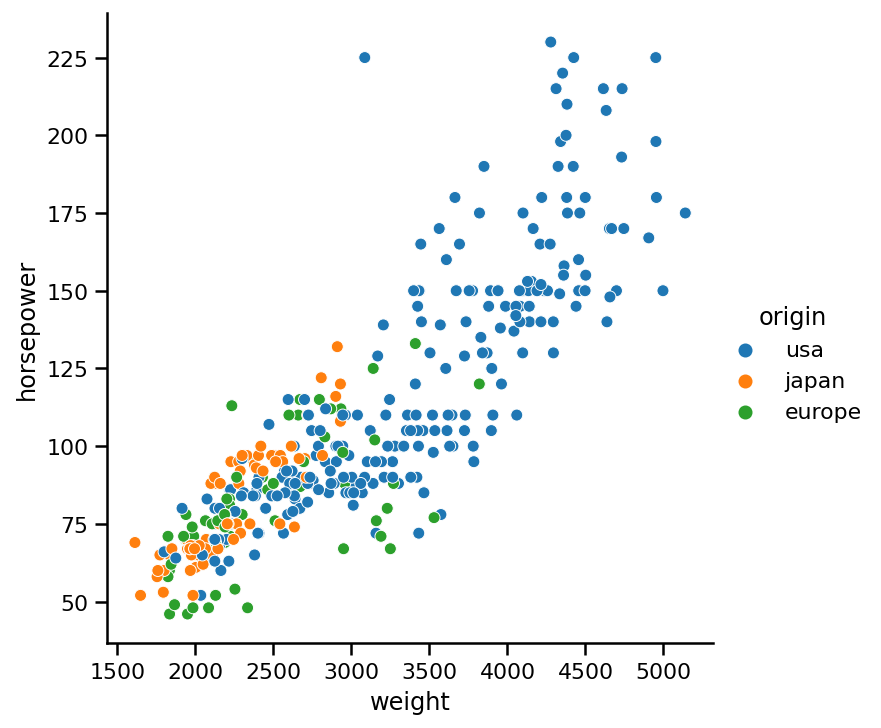
雖然顏色在這張圖中增加了一層額外的資訊,但在更大的資料集中,可能很難區分點群中的顏色,為了更清晰起見,我們將點的樣式添加到繪圖中:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
hue='origin',
style='origin');
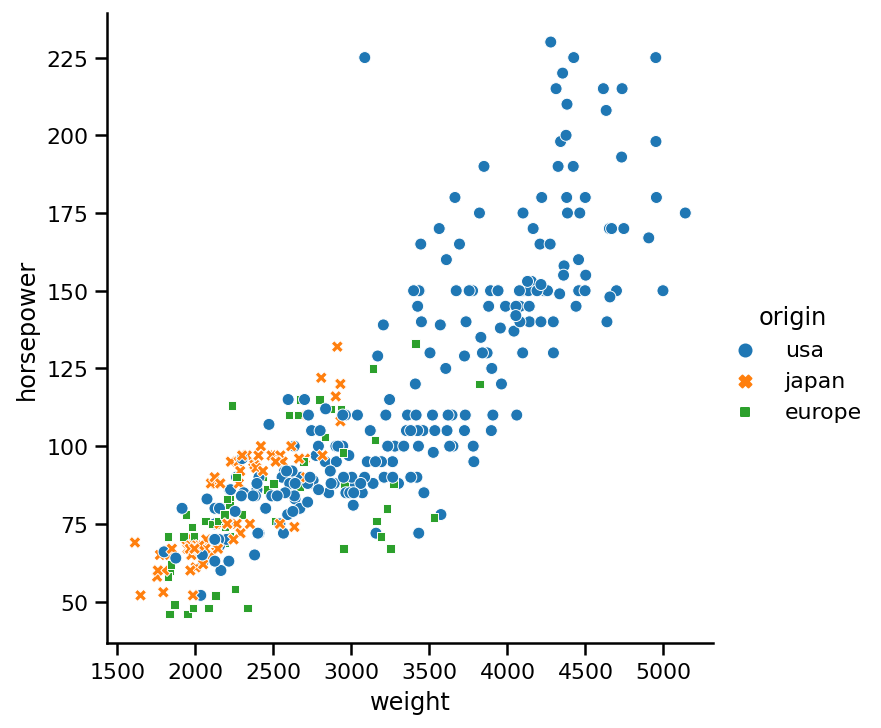
好一點了,改變點的樣式和顏色是非常有效的,如果我們只使用點的樣式來指定原點,看看會發生什么:
sns.relplot(x='weight', y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars, style='origin');
提示:將色調和樣式引數結合使用,可以使繪圖更加清晰,
我們去掉了色調的引數,這使得我們的圖表更難理解,如果不喜歡默認顏色,你可以更改:
首先,你應該創建一個字典,將各個顏色映射到每個類別,請注意,該字典的鍵應該與圖例中的名稱相同,
hue_colors = {'usa': 'red',
'japan': 'orange',
'europe': 'green'}
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
hue='origin',
style='origin',
palette=hue_colors);
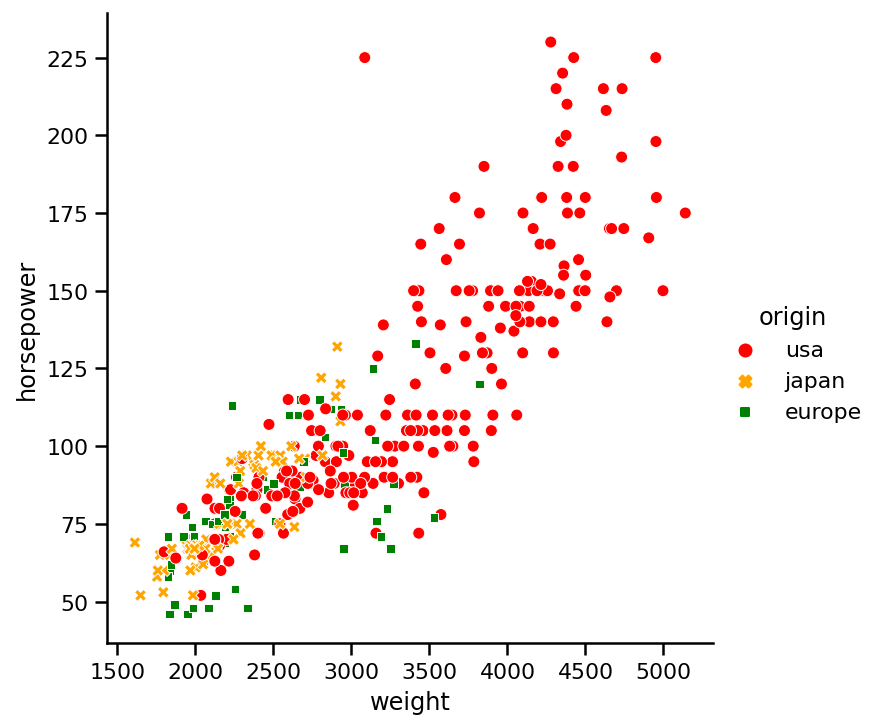
從圖中可以看出,我們資料集中的大部分汽車都來自美國,
散點圖的點透明度
讓我們再次回到我們的第一個例子,讓我們再畫一次,但要增加一點透明度:
sns.relplot(x='weight', y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars, alpha=0.6);
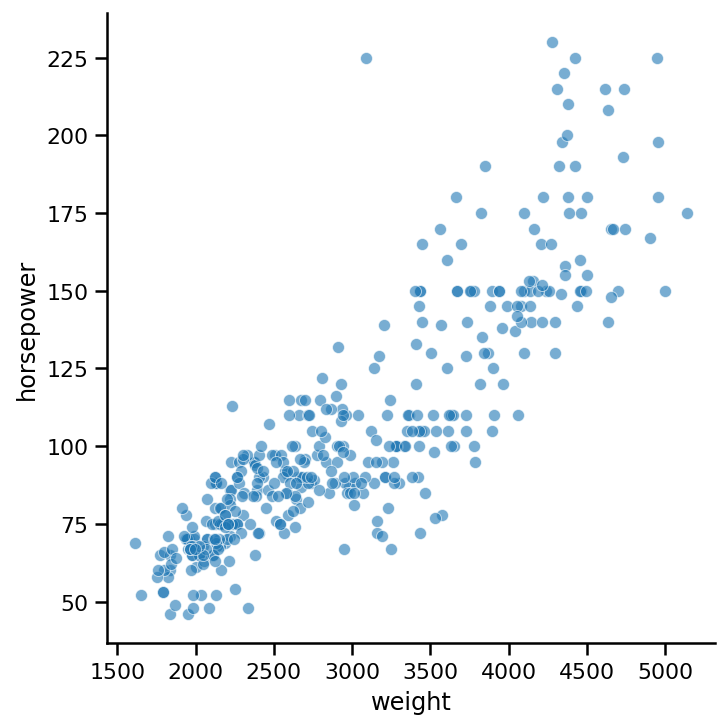
我們使用alpha引數來設定點的透明度,它接受0到1之間的值,0是完全透明的,1是完全不透明的,當你有一個大的資料集并且你想找出圖中的簇或組時,它是一個非常有用的特性,降低透明度時,圖中有許多圓點的部分將變暗,
散點圖中的子圖
在Seaborn也可以使用子圖,我之所以使用relplot()而不是scatterplot(),因為它不能創建一個子圖,
由于relplot是一個圖形級別的函式,它生成一個FacetGrid(一個由多個繪圖組成的網格)物件,而scatterplot()只列印到一個matplotlib.pyplot.Axes(單個繪圖)不能轉換為子圖的物件:
fg = sns.relplot()
print(type(fg))
plot = sns.scatterplot()
print(type(plot))
<class 'seaborn.axisgrid.FacetGrid'>
<class 'matplotlib.axes._subplots.AxesSubplot'>
讓我們看一個例子,我們想在其中使用子圖,在上面的其中一個圖中,我們將4個變數編碼到一個單獨的圖中(重量,馬力,排量和加速度),現在,我們還要添加汽車的原產地,為了使資訊更易于解釋,我們應該將其劃分為子圖:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
col='origin');
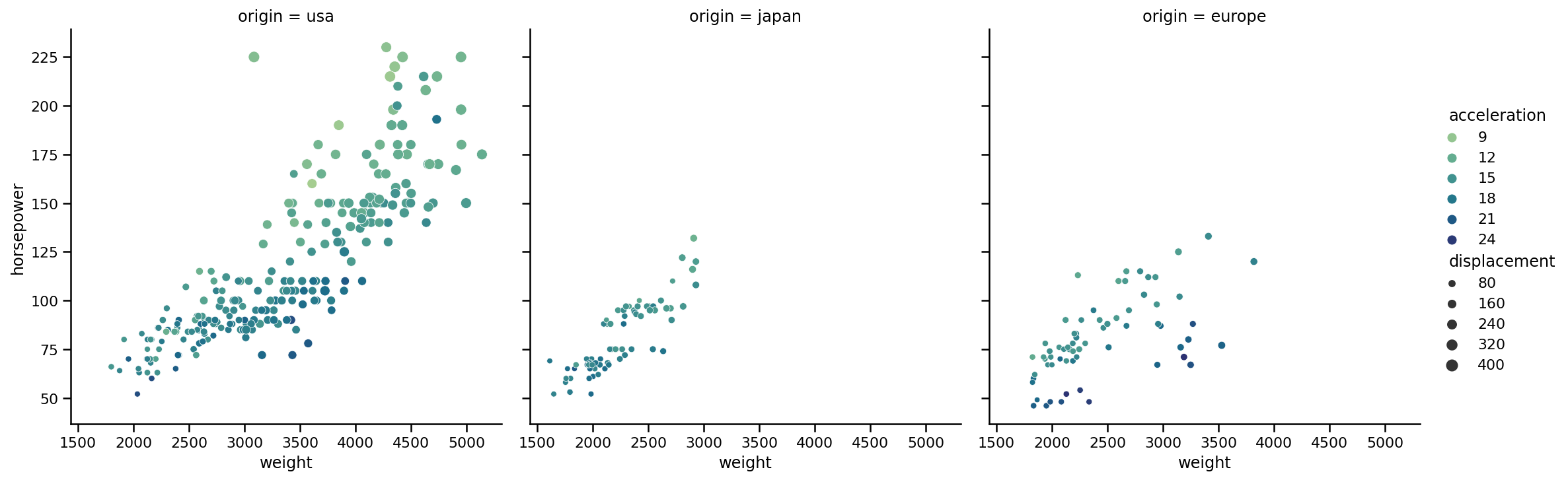
這一次,我們添加了一個新引數col,指出我們希望在列中創建子圖,這些型別的子區間非常有用,因為現在很容易看到第五個變數的趨勢,順便說一句,傳遞給col的變數應該是離散的,這樣才能起作用,此外,SB在一行中顯示列,如果有多個類別需要繪制,我們不希望這樣,讓我們看一個使用我們的資料的用例,盡管它的類別較少:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
col='origin',
col_wrap=2);
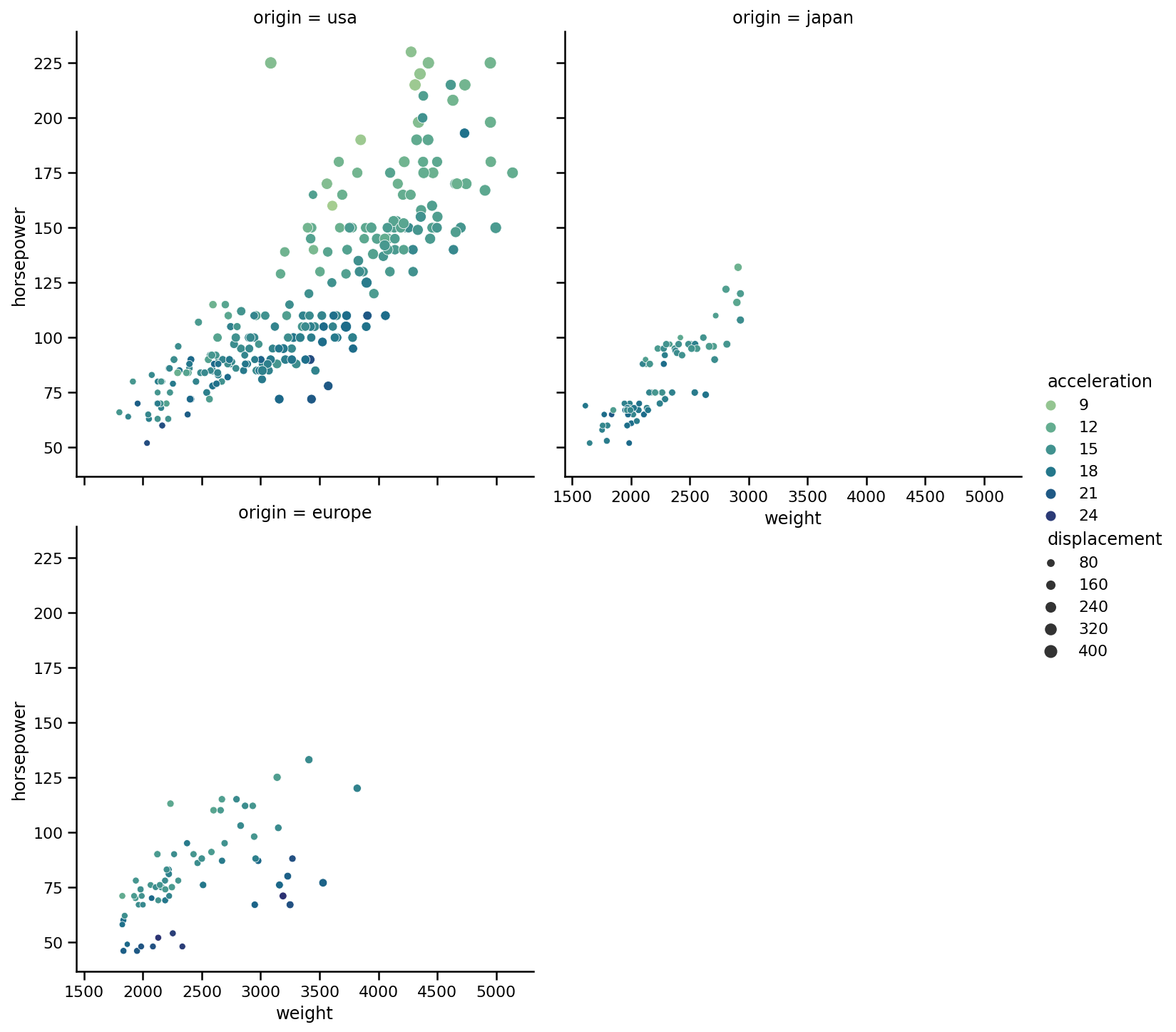
col_wra引數告訴SB我們希望一行中有多少列,
還可以指定列中類別的順序:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
col='origin',
col_order=['japan', 'europe', 'usa']);
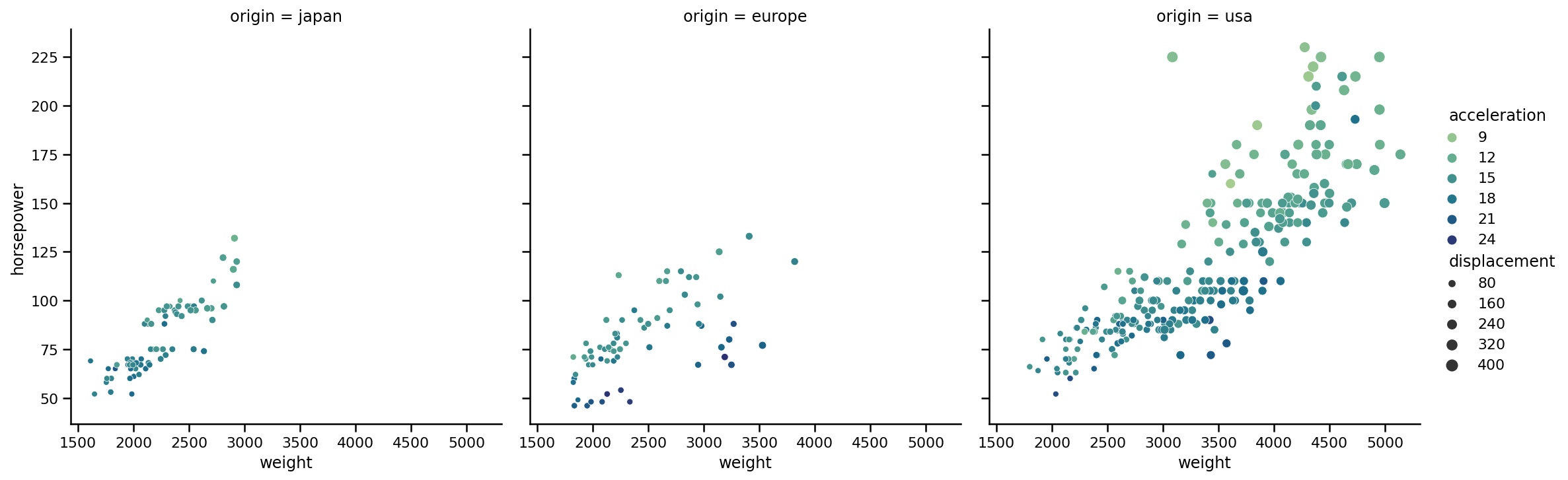
也可以在行中顯示相同的資訊:
sns.relplot(x='weight',
y='horsepower',
data=https://www.cnblogs.com/panchuangai/p/cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
row='origin');

如果有很多類別,那么使用行并不是很有用,最好還是堅持使用列,你可以再次使用row_order指定行的順序,
線圖
關系圖的另一種常見型別是線圖,而在散點圖中,每個點都是一個獨立的觀察點,在線圖中,我們繪制了一個變數和一些連續變數,通常是一段時間,我們的第二個樣本資料集包含2010年至2016年跟蹤的501家公司的紐約證券交易所資料,
為了便于說明,讓我們觀察給定時間段內所有公司的收盤價,由于涉及日期,因此線條圖是此任務的最佳視覺型別:
專業提示:如果資料集中有一個日期列,請將其設定為日期型別,然后使用set_index()函式將其設定為索引,或使用pd.read_csv(parse_dates=['date_column'], index_col='date_column'),它將允許你繪制線圖,并使日期的設定更容易,
對于線圖,我們再次使用relplot()并將kind設定為line,這將繪制第二個連續變數(通常是時間)上跟蹤的單個變數,
sns.relplot(x=stocks.index, y='close',
data=https://www.cnblogs.com/panchuangai/p/stocks, kind='line');
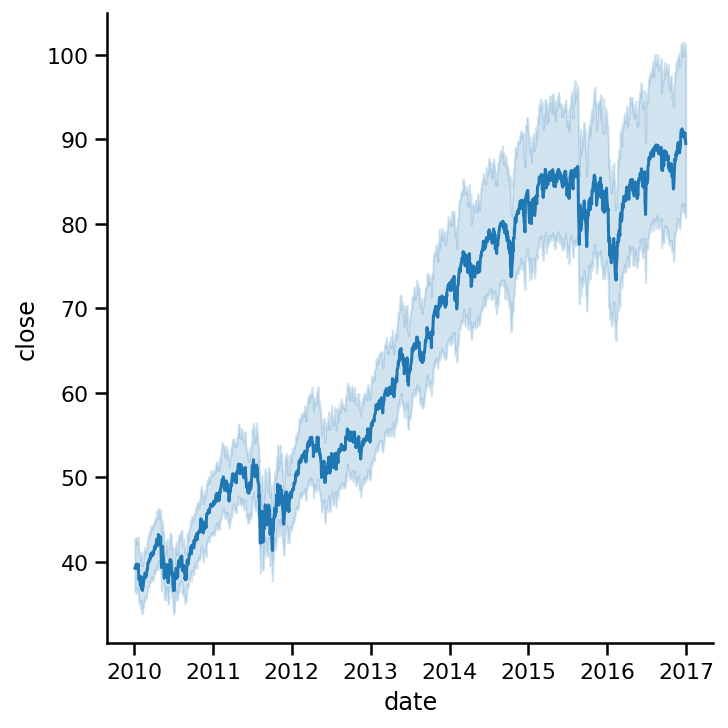
我們可以看到明顯的趨勢,所有公司的股票在給定的時間段內都在增長,藍色較深的線代表6年來追蹤的所有公司收盤價的平均值,
SB會自動增加一個置信區間,如果對一個點有多個觀測會添加那條線周圍的陰影區域,稍后會詳細介紹,現在,讓我們把資料集中到3家公司:
am_ap_go = stocks[stocks['symbol'].isin(['AMZN', 'AAPL', 'GOOGL'])]
am_ap_go.shape
(5286, 6)
多行線圖
現在,讓我們通過將資料分組到三個公司來重新創建上面的線圖,這將在同一繪圖中創建三條線,而不是一條:
sns.relplot(x=am_ap_go.index,
y='close',
data=https://www.cnblogs.com/panchuangai/p/am_ap_go,
kind='line',
hue='symbol');
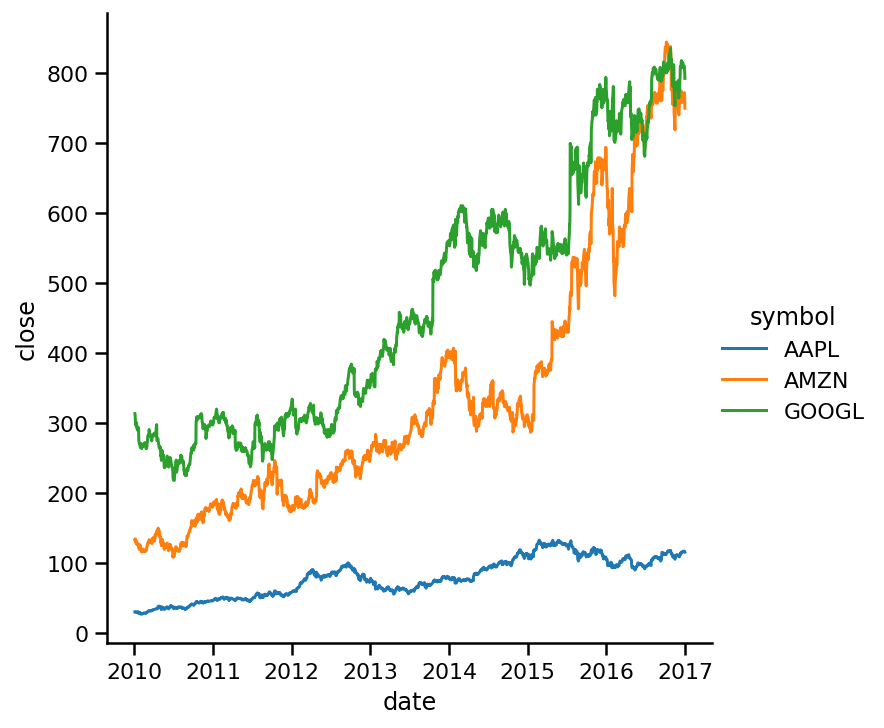
就像我們在散點圖示例中所做的那樣,我們使用hue引數在資料中創建子組,同樣,你必須將一個范疇變數傳遞到hue中,在這幅圖中,我們可以看到,在2016年之后,亞馬遜和谷歌的股價非常接近,而蘋果在整個期間都處于底部,現在,讓我們看看我們是如何將每一行與顏色區分開來的:
線圖線條樣式
我們使用style引數來指定每一行需要不同的線條樣式:
sns.relplot(x=am_ap_go.index,
y='close',
data=https://www.cnblogs.com/panchuangai/p/am_ap_go,
kind='line',
hue='symbol',
style='symbol');
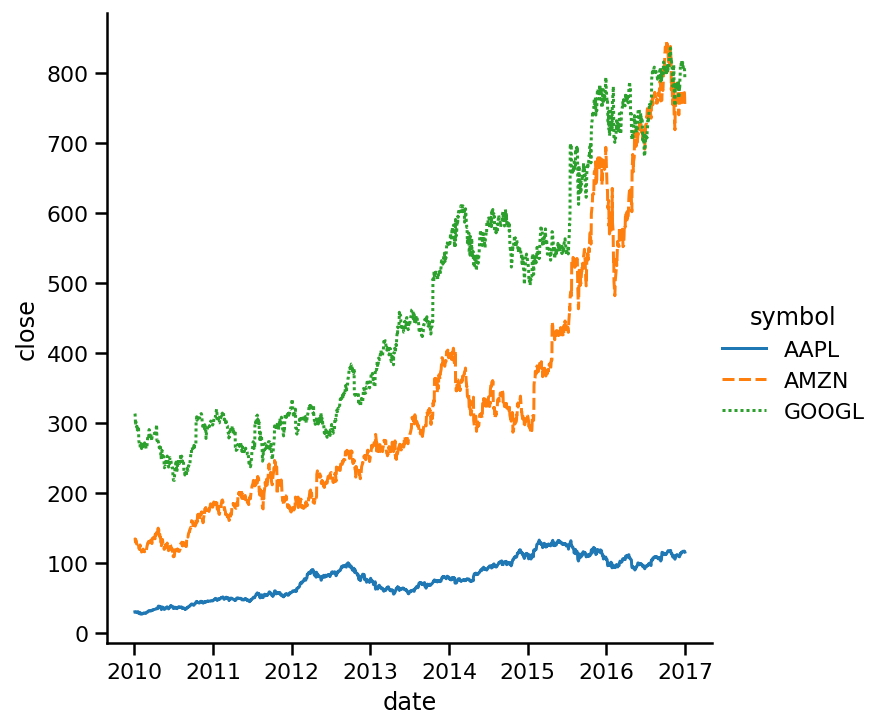
好吧,這可能不是不同線條風格的最佳例子,因為觀察是針對每一天的,而且非常緊湊,讓我們僅對2015-2016年期間進行子集劃分,并繪制相同的線圖:
am_ap_go_subset = am_ap_go.loc['2015-01-01':'2015-12-31']
sns.relplot(x=am_ap_go_subset.index,
y='close',
data=https://www.cnblogs.com/panchuangai/p/am_ap_go_subset,
kind='line',
hue='symbol',
style='symbol');
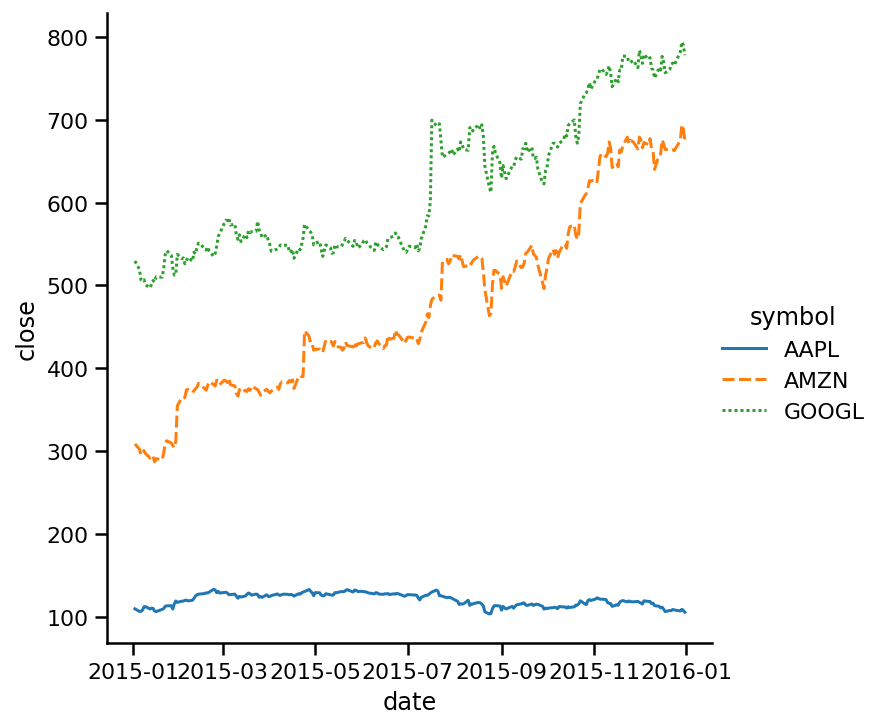
現在線條風格更清晰了,你可能會說,這好像沒什么分別,但是當你有一個圖表,它的線非常緊湊的話,這可能可以幫助你理解某些東西,
線圖的點標記
當你有一個較小的資料集并且想要創建一個線圖時,用點標記來標記每個資料點可能會很有用,對于我們較小的股票價格分布資料來說仍然是非常緊張的,所以,讓我們用一個更小的時間段,來看看如何使用點標記:
smaller_subset = am_ap_go_subset.loc["2015-01-01":"2015-03-01"]
sns.relplot(x=smaller_subset.index,
y='close',
data=https://www.cnblogs.com/panchuangai/p/smaller_subset,
kind='line',
hue='symbol',
style='symbol',
markers=True)
plt.xticks(rotation=60);
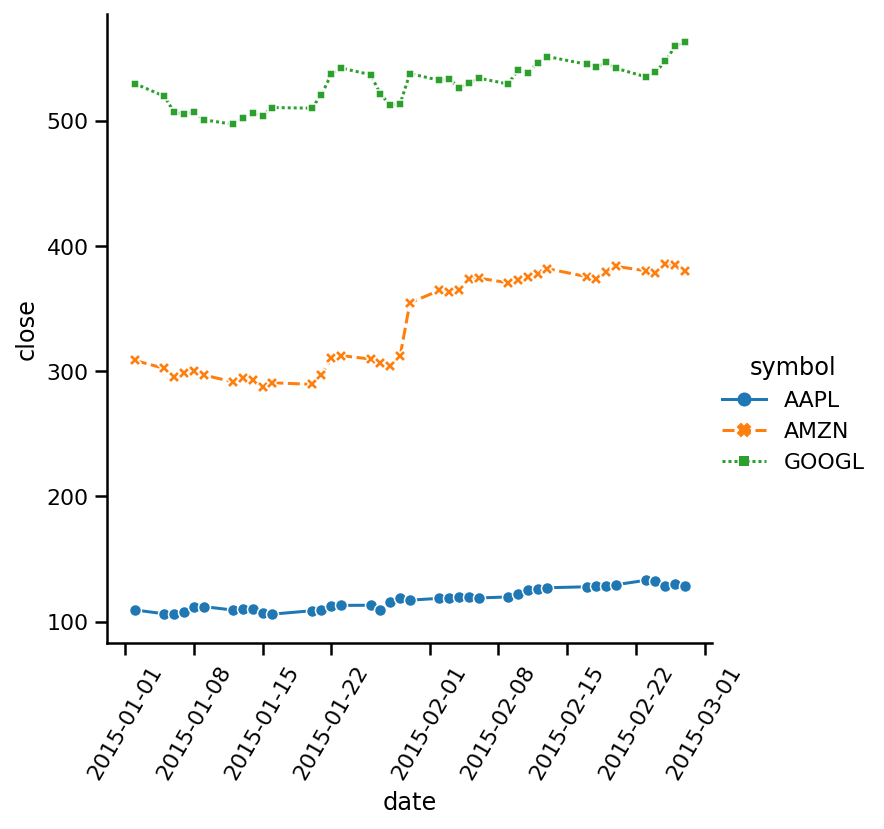
現在每行都有不同的標記,我們將markers引數設定為True以激活此功能,
線圖置信區間
接下來,我們將探討在SB中計算線圖的置信區間,如果對一個點有多個觀測值,則會自動添加置信區間,
在我們對這三家公司的資料中,每一天都有三個觀察結果:一個是亞馬遜,一個是谷歌,一個是蘋果,當我們創建不帶子組(不帶色調引數)的線條圖時,默認情況下,SB取這三個值的平均值:
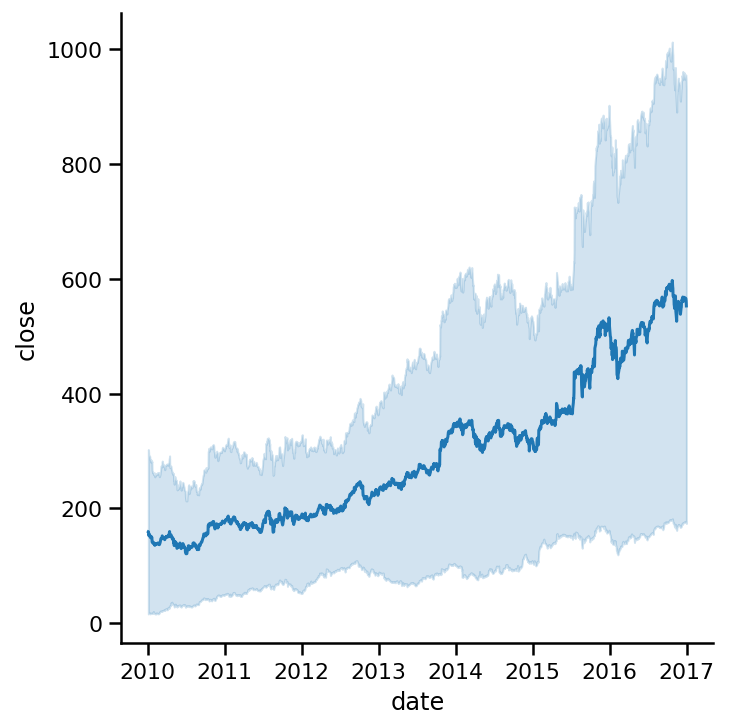
sns.relplot(x=am_ap_go.index, y='close',
data=https://www.cnblogs.com/panchuangai/p/am_ap_go, kind='line');
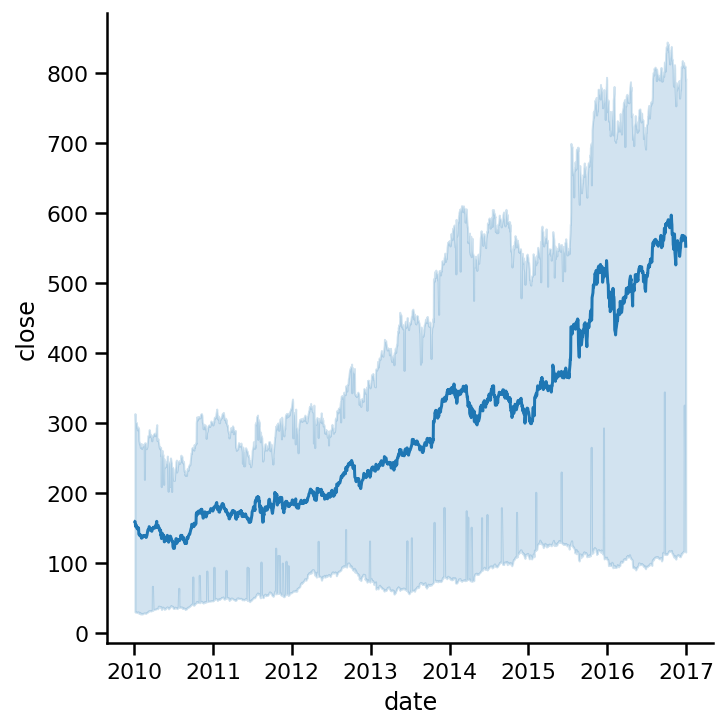
較暗的線表示這三家公司股價的平均值,陰影區域為95%置信區間,這是非常巨大的,因為我們的樣本資料只有三家公司,陰影區意味著95%的人的平均值在這個區間內,它表明了我們資料的不確定性,
例如,2017年,人口平均數在100到800之間,置信區間的范圍是巨大的,將ci引數設定為“None”可以關閉置信區間:
sns.relplot(x=am_ap_go.index,
y='close',
data=https://www.cnblogs.com/panchuangai/p/am_ap_go,
kind='line', ci=None);
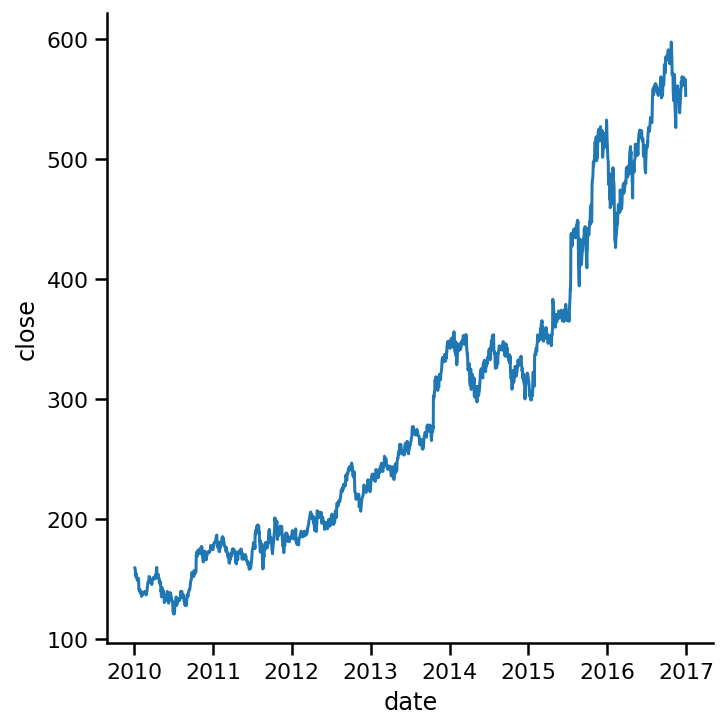
或者,如果需要,可以顯示標準偏差而不是置信區間,將ci引數設定為sd:
sns.relplot(x=am_ap_go.index,
y='close',
data=https://www.cnblogs.com/panchuangai/p/am_ap_go,
kind='line',
ci='sd');
也許這些引數對于我們的示例資料不是很有用,但是當你處理大量真實資料時,它們將非常重要,
最后一點:如果要為線圖創建子圖,可以使用相同的col和row引數,
結論
最后,我們完成了Seaborn的關系圖,線圖和散點圖是在資料海洋中發現洞察力和趨勢的非常重要的視覺輔助工具,因此,掌握它們是很重要的,盡可能使用Seaborn來創建它們,
原文鏈接:https://towardsdatascience.com/master-a-third-of-seaborn-statistical-plotting-with-relplot-df8642718f0f
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/186556.html
標籤:其他
上一篇:資料科學家的Pytest