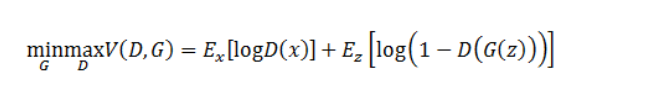
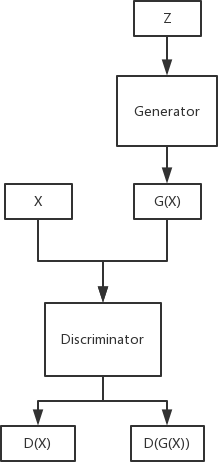
同VAE模型類似,GAN模型也包含了一對子模型,GAN的名字中包含一個對抗的概念,為了體現對抗這個概念,除了生成模型,其中還有另外一個模型幫助生成模型更好地學習觀測資料的條件分布,這個模型可以稱作判別模型D,它的輸入是資料空間內的任意一張影像x,輸出是一個概率值,表示這張影像屬于真實資料的概率,對于生成模型G來說,它的輸入是一個隨機變數z,z服從某種分布,輸出是一張影像G(z),如果它生成的影像經過模型D后的概率值很高,就說明生成模型已經比較好地掌握了資料的分布模式,可以產生符合要求的樣本;反之則沒有達到要求,還需要繼續訓練,
兩個模型的目標如下所示,
判別模型的目標是最大化這個公式:Ex[D(x)],也就是甄別出哪些圖是真實資料分布中的,
生成模型的目標是最大化這個公式:Ez[D(G(z))],也就是讓自己生成的圖被判別模型判斷為來自真實資料分布,
看上去兩個模型目標聯系并不大,下面就要增加兩個模型的聯系,如果生成模型生成的影像和真實的影像有區別,判別模型要給它判定比較低的概率,這里可以舉個形象的例子,x好比是一種商品,D是商品的檢驗方,負責檢驗商品是否是正品;G是一家山寨公司,希望根據拿到手的一批產品x研究出生產山寨商品x的方式,對于D來說,不管G生產出來的商品多像正品,都應該被判定為贗品,更何況一開始G的技術水品不高,生產出來的產品必然是漏洞百出,所以被判定為贗品也不算冤枉,只有不斷地提高技術,才有可能迷惑檢驗方,
基于上面的例子,兩個模型的目標就可以統一成一個充滿硝煙味的目標函式,
上面這個公式對應的模型架構如圖10-5所示,
————————————————
著作權宣告:本文為CSDN博主「csdn_csdn__AI」的原創文章,遵循 CC 4.0 BY-SA 著作權協議,轉載請附上原文出處鏈接及本宣告,
原文鏈接:https://blog.csdn.net/heyc861221/article/details/80130968
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/187360.html
標籤:其他