目錄
- 一、摘要
- 二、雜記
- 三、模型思想
- 3.1 問題定義:
- 3.2 模型框架
- 四、實驗
- 五、其他
- 六、參考文獻
一、摘要
深度學習不用去手工提取特征,但是現有深度模型沒有在傳播預測任務中使用社區結構,所以提出一個CS-RNN框架,把社區在傳播中的影響考慮在內,做傳播預測,
二、雜記
- 貢獻:①引入community structure information;②CS-RNN模型包含社區結構標簽預測層(community structure labels prediction layer),可以預測下一個活躍節點的社區結構標簽;③引數健壯、結果好;(PS:原文中3、4點被總結到此處第3點了,單從此處來看創新并不是很吸引人,)
- 參考文獻結論:strong community 通過加強區域和社區內部的傳播,有利于資訊進行全域傳播,
- 文章缺點:參考文獻列舉了隨著神經網路發展產生的一些深度模型,但是并沒有描述這些深度模型的側重點或者缺點,(PS:那如何突出自己作業的重要性)
三、模型思想
3.1 問題定義:
Network:\(G=(V,E)\),\(V\)是頂點代表用戶,\(E\)是邊代表用戶間關系;
Cascade:\(S=\{\left(t_{i}, v_{i}\right) | v_{i} \in V, t_{i} \in[0,+\infty), t_i \le t_{i+1}, i=1,2,...,N \}\),代表節點\(v_i\)在\(t_i\)時刻分享了訊息;
Community:\(G(V',E')\)代表內部連接緊密的子圖,假設圖\(G=(V,E)\)可以被分為q個子部分\(\mathcal{L} = \left\{L_{1}, L_{2} \ldots L_{q}\right\}\),一個用戶 \(v_i\) 只能屬于一個社區,且它的社區標簽并定義為\(c_{v_i} \in X_{\mathcal{X}}\);
問題描述:觀察之前的傳播程序,給定k個時間節點對(Cascade)表示為\(S_{\le k}\),在傳播級聯中進行序列建模,來預測下一個激活節點的概率,即\(p(v_{k+1}|S_{\le k})\),還要預測下一個激活節點的社區標簽\(c_{v_{k+1}}\),即\(P{c_{v_{k+1}}|S_{\le k}}\),還要預測節點激活的確切時間,
3.2 模型框架
基本原理:資訊傳播到下一個節點不僅跟活躍節點的歷史序列狀態有關,還跟資訊傳播過的社區有關,
模型框架圖如下,帶標號和有顏色背景的無邊緣線圖形,是我為了更好的描述框架而加上的:
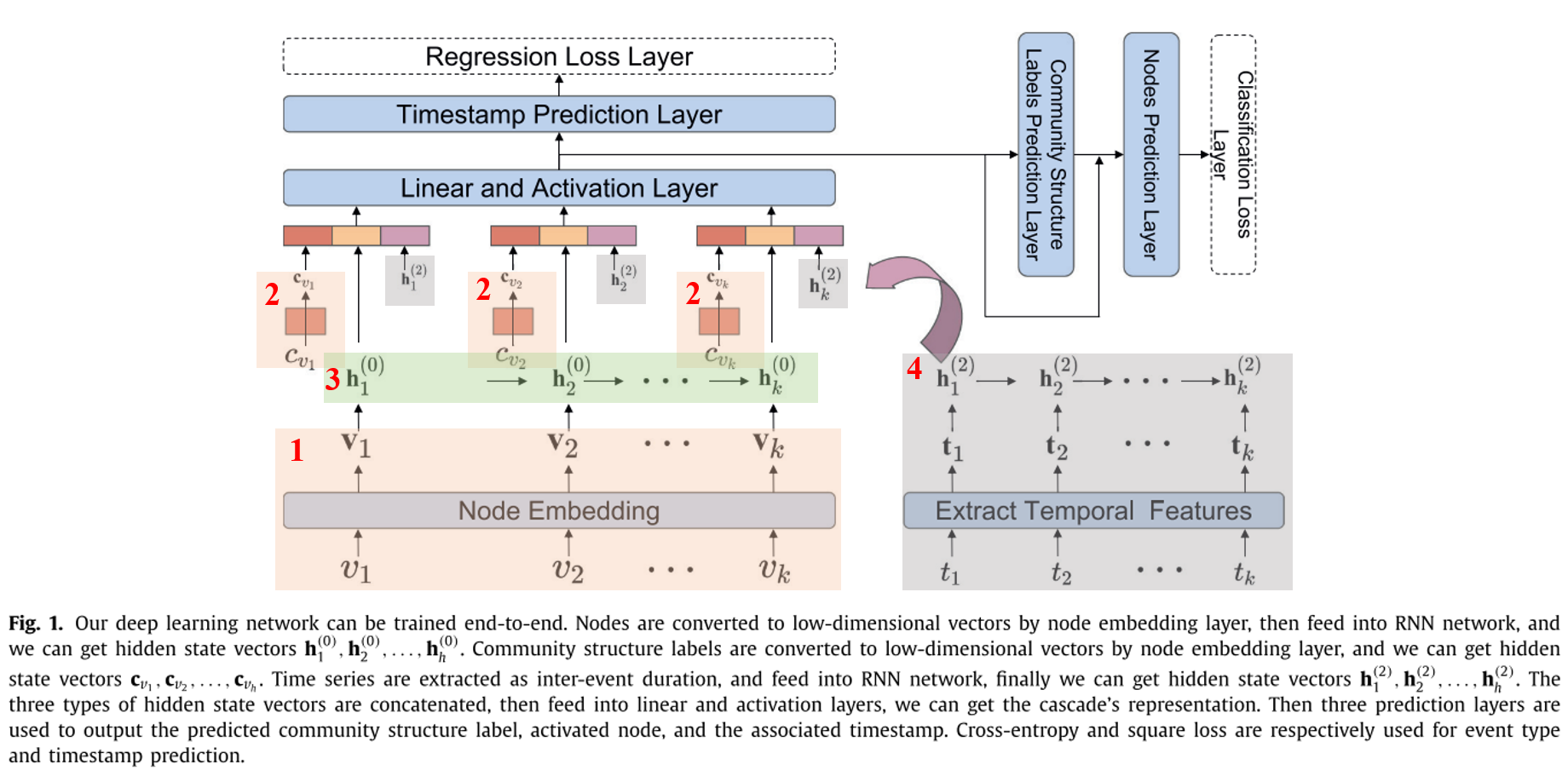
輸入層:
①圖中標記1的部分,把節點\(v_k\)轉換成一個低維的向量\(\mathbf{v}_k \in R^{d_v}\),\(\mathbf{v}_{k}=\mathbf{W}_{e m v}^{T} v_{k}\);
②圖中標記2的部分,把社區標簽\(c_{v_k}\)也初始化轉換為低維向量\(\mathbf{c}_{v_k} \in R^{d_c}\),\(\mathbf{c}_{v_{k}}=\mathbf{W}_{e m c}^{T} c_{v_{k}}\);
隱藏層:
①圖中標記3的部分,這里是把\(\mathbf{v}_1\)到\(\mathbf{v}_k\)用一個RNN串聯起來,表示每個節點的初始隱含表示,由之前得到的表示向量\(\mathbf{v}_k\)和傳播程序中上一個節點的隱含表示所決定:\(\mathbf{h}_{k}^{(0)}=R N N\left(\mathbf{v}_{k}, \mathbf{h}_{k-1}^{(0)}\right)\),其中,\(h_0^{(0)}\)由全0的向量初始化,RNN層中可以使用GRU和LSTM,這里暫時把\(\mathbf{h}_{k}^{(0)}\)和上一步得到的\(\mathbf{c}_{v_{k}}\)拼接起來,組成\(\mathbf{h}_{k}^{(1)}= \mathbf{h}_{k}^{(0)} \oplus \mathbf{c}_{v_{k}}\),備用,
②圖中標記4的部分,把傳播級聯中的時間t,也按照序列順序用RNN串聯,得到\(\mathbf{h}_{k}^{(2)}=R N N\left(\mathbf{t}_{k}, \mathbf{h}_{k-1}^{(2)}\right)\),
最后,把上述的兩個(其實是三個\(\mathbf{h}_{k}^{(1)}\)由兩部分組成)拼接起來,組成一個向量(圖中三色向量圖形),然后通過一個線性變換層(FC層)和一個非線性變換(激活層)【圖中Linear and Activation Layer】,得到結果:\(\mathbf{h}_{k}^{\mathrm{cas}}=\delta\left(\mathbf{W}_{h}^{T}\left(\mathbf{h}_{k}^{(1)} \oplus \mathbf{h}_{k}^{(2)}\right)+\mathbf{b}_{h}\right)\),
社區結構標簽產生:(圖中右上部分)
由上面得到的\(\mathbf{h}_{k}^{\mathrm{cas}}\),在通過一個線性變換層和激活層,目的是為了把\(\mathbf{h}_{k}^{\mathrm{cas}}\)映射到和社區結構標簽嵌入向量同樣的空間中去,得到\(\mathbf{h}_{k}^{\mathrm{com}}=\delta\left(\mathbf{W}_{\mathrm{com}}^{T} \mathbf{h}_{k}^{\mathrm{cas}}+\mathbf{b}_{\mathrm{com}}\right)\),然后把\(\mathbf{h}_{k}^{\mathrm{com}}\)和所有社區標簽向量做余弦相似度,在用一個softmax層歸一化所有相似度,得到(預測)下一個激活節點的社區標簽,\(\mathbf{p}_{k}^{c o m}=\operatorname{sigmoid}\left(\mathbf{h}_{k}^{c o m} \mathbf{W}_{e m c}^{T}\right)\),
下一個激活節點的產生:(圖中右上部分)
我們可以看到,圖中的右上部分有一個類似殘差神經網路(大霧)的連接,其實是作者又做了一個下一個激活節點的預測,具體如下:
通過模型左側得到的\(h_k^{cas}\),和剛剛預測的社區結構標簽 $ \mathbf{p}_{k}^{\text {com}}$,作者把這兩個向量拼接起來,再送入線性變換層和激活層,得到 \(\mathbf{h}_{k}^{\text {node }}=\delta\left(\mathbf{W}_{\text {node }}^{T}\left(\mathbf{h}_{k}^{\text {cas }} \oplus \mathbf{p}_{k}^{\text {com }}\right)+\mathbf{b}_{\text {node }}\right)\),然后如法炮制,在計算隱向量\(h_k^{node}\)和所有節點的嵌入表示之間的余弦相似度,再用softmax層歸一化,得到每個節點的概率表示,從而預測下一個激活結點是哪個節點,
下一個激活時間預測:(圖中左上部分)
利用最開始得到的傳播級聯第K步的表示\(h_k^{cas}\),還可以預測傳播程序的第K+1步和第k步之間的時間間隔,即\(t_{k+1}-t_{k}=\mathbf{W}_{t}^{T} \mathbf{h}_{k}^{c a s}+\mathbf{b}_{t}\),
哇,這是一口氣做了三個預測,通過傳播級聯第K步的表示\(h_k^{cas}\),文中做了下一個激活節點的預測,下一激活節點所在的社區標簽的預測,還做了時間間隔的預測,感覺文章要做multi-task了(是不是做multi-task會有識訓呢?),然而沒有,文中的損失函式:
\[\operatorname{Loss}(Q)=\sum_{f=1}^{F} \sum_{i=1}^{N_{f}-1} \log p\left(\left(t_{k+1}, v_{k+1}, c_{k+1}\right) | c_{v_{k}}, S_{\leq k}\right) \]利用基于時間的反向傳播(backpropagation through time,BPTT)來訓練模型,最后用SGD,mini-batch和Adam優化,為了加快速度,在訓練程序中使用正交初始化方法,
四、實驗
利用合成資料和真實資料(Digg資料集),主要在合成資料集上做了分析,對于真實資料集分析簡短,
設備:Tesla V100 32G GPU, Intel Xeon E5 CPU,512G記憶體,
合成資料生成方法:(不太懂,之后用到生成資料可以參考這里,關鍵是傳播都能夠生成!)
網路結構和傳播程序都是生成的,
網路結構生成,兩種方法:①kronecker graph model;②LFR bechmark,更像真實網路,產生兩種網路結構①random network(RD);②層級社區網路(HC),
傳播程序生成,對于每個節點,按照一定的時間分布來設定被激活用戶的激活時間,參考其他文獻,也設定了兩種分布,①混合指數分布(Exp);②混合瑞利分布(Ray);
對比演算法:
CYANRNN(AAAI’17):使用attention-based RNN,利用傳播程序中的交叉依賴性(什么是交叉依賴性?),
RNNPP(AAAI’17):用RNN的視角處理point process,建模背景和歷史作用,可以預測event時間,主要型別的event和子型別的event,作者在論文中把社區結構當做main-types,把node當做sub-type,
RMTPP(SIGKDD‘16):將時間點程序的強度函式視為歷史的非線性函式,利用RNN自動學習事件歷史影響的表示,
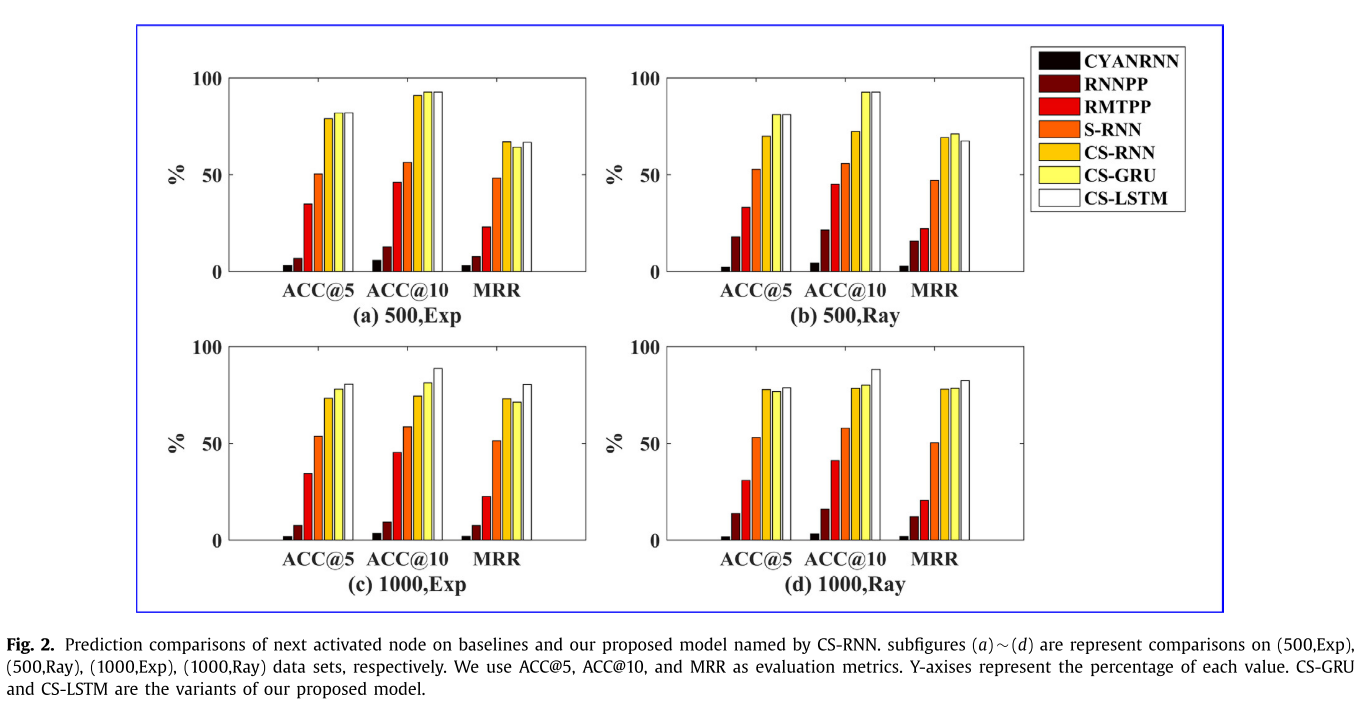
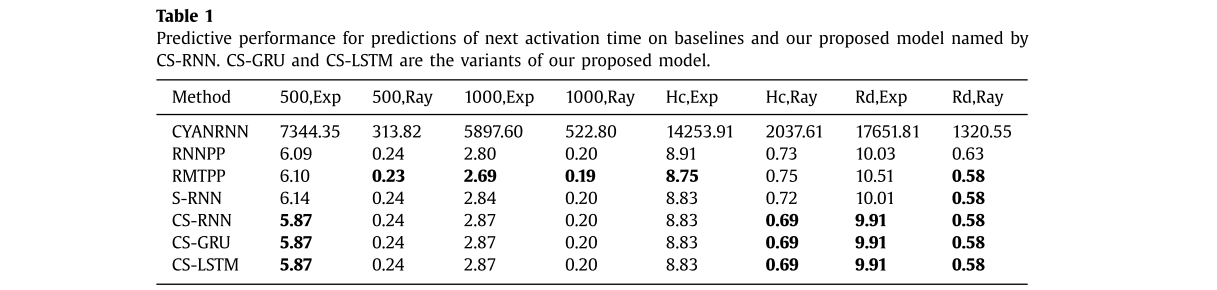
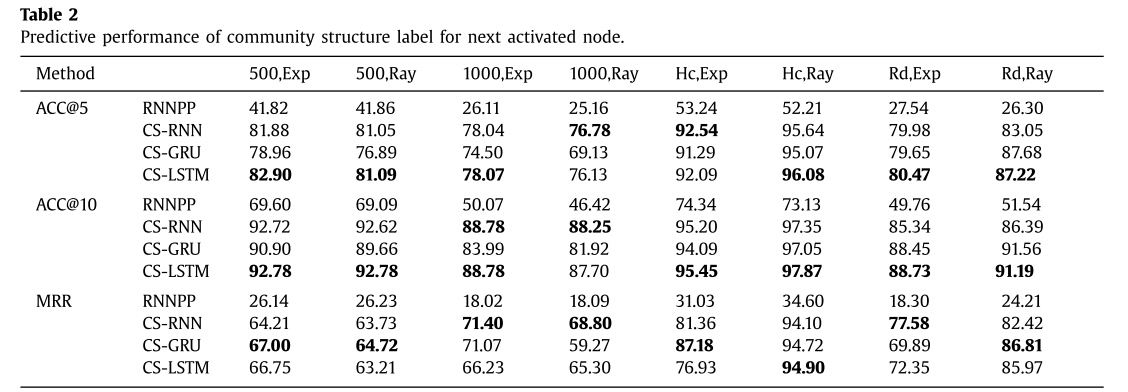
S-RNN,CS-RNN,CS-GRU,CS-LSTM:分別是去掉社區結構的方法,原始方法,使用GRU的方法和使用LSTM的方法,前兩個是為了對比結果證明,社區結構有用的,后面兩個是對比GRU好還是LSTM好,
結果還是比較中規中矩的,提出的方法肯定是最優的,社區結構是有用的,
五、其他
瑞利分布(Rayleigh Distribution):當一個隨機二維向量的兩個分量呈獨立的、有著相同的方差的正態分布時,這個向量的模呈瑞利分布,
六、參考文獻
[1]. Liu, Chaochao, et al. “Community Structure Enhanced Cascade Prediction.” Neurocomputing, vol. 359, Elsevier B.V., 2019, pp. 276–84, doi:10.1016/j.neucom.2019.05.069.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/187365.html
標籤:其他