系列文章
- 實時存盤引擎和實時計算引擎
- 美團點評 Hadoop/Spark 系統實踐
本文目錄
- 系列文章
- 一、Hadoop/Spark 定位與應用架構
- 1.1 功能和定位(是什么)
- 1.2 在互聯網企業的應用場景和外圍系統(怎么用)
- 二、Hadoop / Spark 核心架構
- 2.1 核心架構 review
- 2.1.1 HDFS 分布式檔案存盤
- 2.1.2 YARN 分布式資源調度
- 2.1.3 Spark 通用分布式計算框架
- 2.2 進一步學習
- 三、 美團點評架構改造案例
- 3.1 Hadoop 異地多機房架構改造
- 3.2 YARN 核心調度流程優化
- 3.3 資料倉庫SQL引擎Spark替換Hive on MR
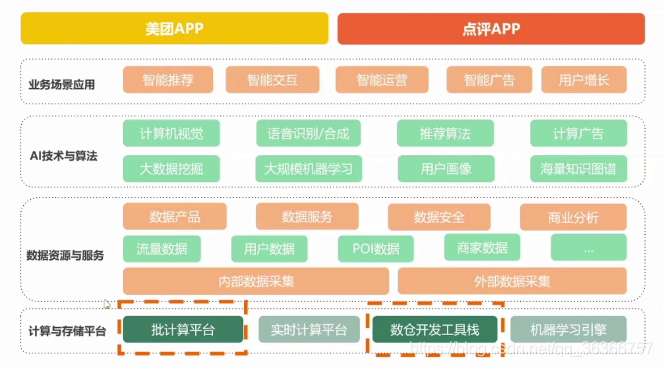
美團大資料系統整體架構

一、Hadoop/Spark 定位與應用架構
1.1 功能和定位(是什么)
Hadoop 開源地址和官網
Spark 開源地址和官網
簡單來說,拆解之后的 Hadoop/Spark 專案基本分為三層:① 最底層是資源調度和檔案存盤 ② 往上是分布式計算內核 ③最上層是 Spark 衍生的一些框架,今天說的主要是三個黑框的部分,
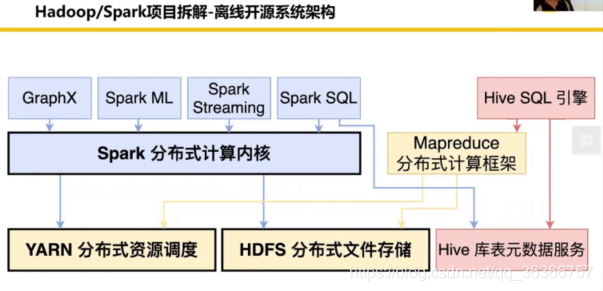
我們可以看到,三個黑框部分有一個共同點——都有“分布式”,那為什么是分布式呢?
以下是一臺單點機器的資料
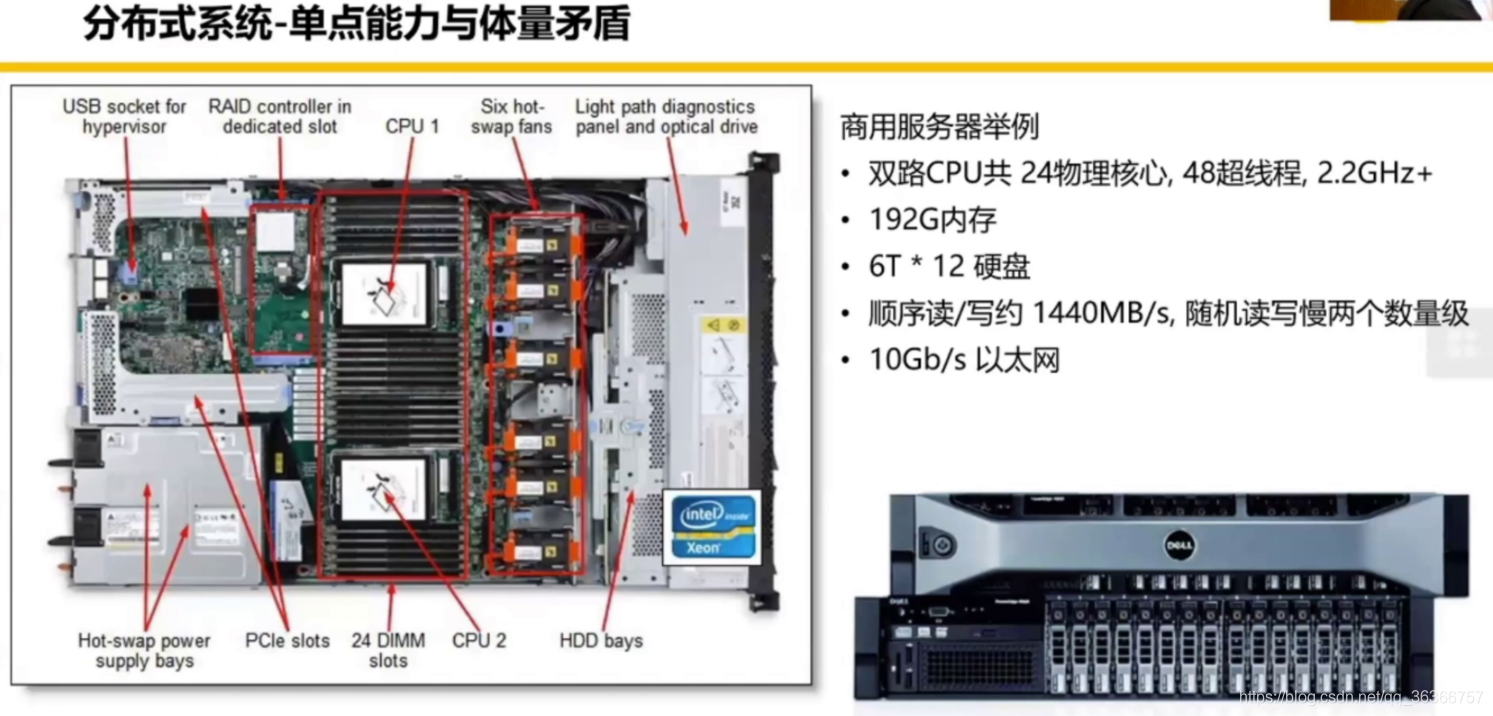
這是美團對于資料存盤和應用的需要:

我們可以看到,一塊商用硬碟滿打滿算也就能寫幾十 T 的資料,但是美團每日單表的增量就有 235T 的資料,這是單節點機器遠遠無法滿足的,這是不得已要做分布式的原因,
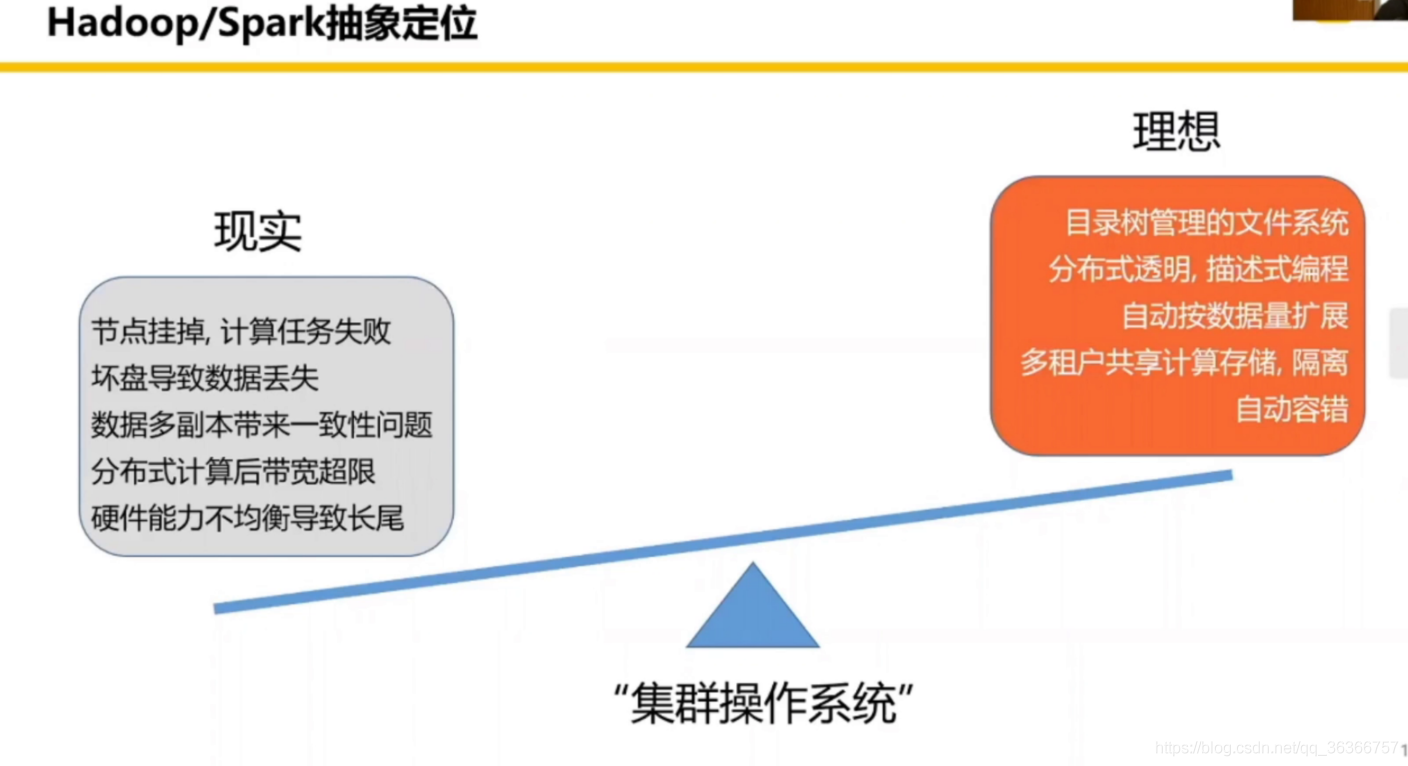
我們想要一個能夠像個人電腦一樣的目錄樹形式的去管理自己的檔案,最好存盤空間沒有限制,操作簡單,平臺無關等等,但是現實卻需要面臨很多問題,節點掛掉、計算失敗等等,那我們通過 Hadoop/Spark 這樣的集群作業系統,通過訪問統一的分布式操作介面,去實作從理想到現實的這樣的一個程序,
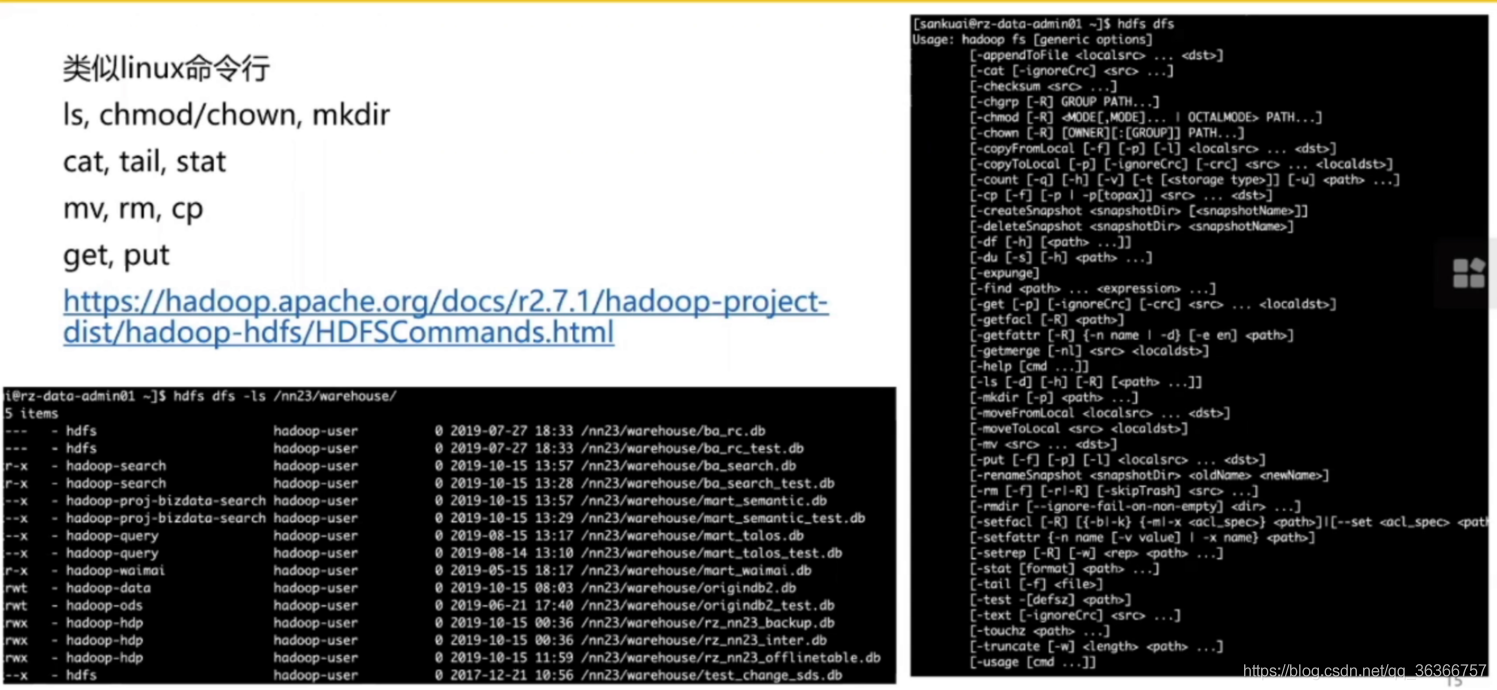
這是HDFS暴露的介面,可以去訪問管理集群的檔案
同時提供了 Java 編程的介面,

Spark 也提供了同樣類似的介面,支持 Java, Scala 和 Python,安裝后從 bin/spark-shell 可以快速起一個 Spark 環境,同時封裝了提交集群作業的介面,

在寫代碼的時候,右邊的是分布式的 “Hello World”—— wordCount,無論資料量有多大,都可以統計出來每個字符的出現次數,左邊一些特性,具體可以參考 API 檔案,

YARN 資源調度
有不同的資源劃分模式,可以劃分給不同的組織結構,后面會詳細講到,
1.2 在互聯網企業的應用場景和外圍系統(怎么用)
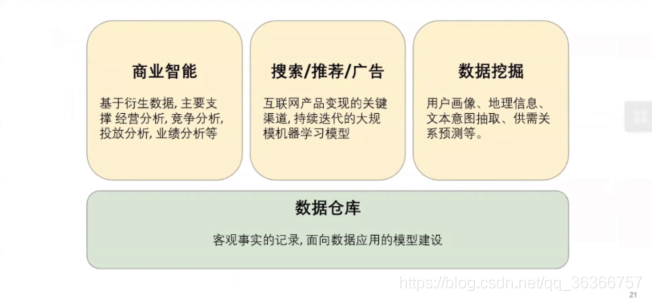
直觀的來看,主要分為以上三種應用,主要通過資料倉庫支撐,下面分別舉例講述,
-
商業智能 —— 經營分析
一個旅游的漏斗模型,用于整個流量轉化資料的建模和分析支撐,

-
搜索/推薦/廣告系統——系統架構
各種資料的存盤和處理和需要很強的分布式支持,
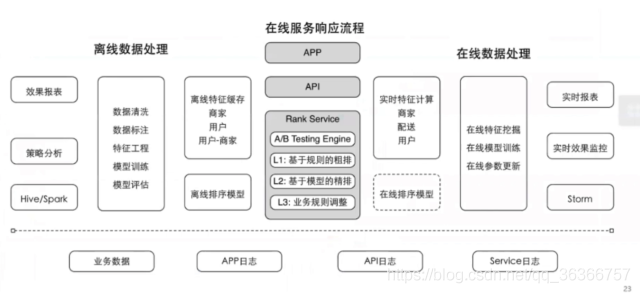
-
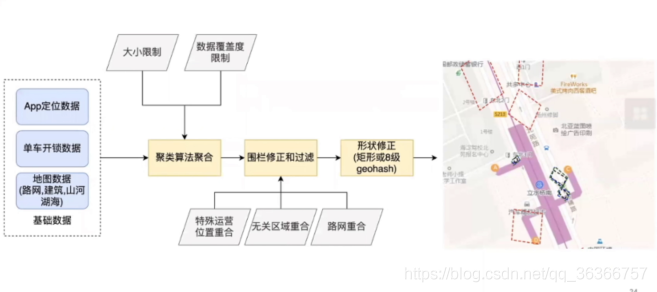
資料挖掘——單車停車點聚合
通過獲得得各種基礎資料,經過處理,把單車調度到大家可能要騎得地方,
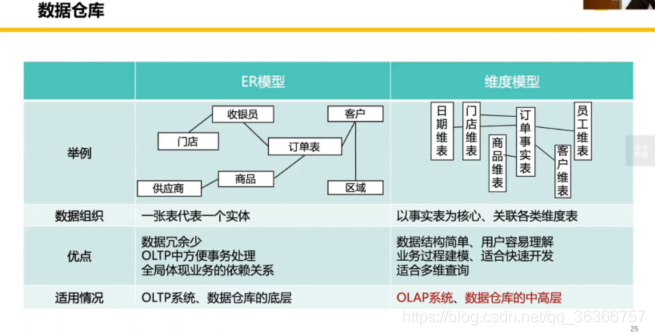
上述三種應用場景都需要用到資料倉庫的支持,我們常見的資料組織形式是 E-R 模型,即物體關系模型,但是在面對線上業務的時候,我們往往想要看到業務發生了哪些變更,或者需要恢復事實等,使用ER模型可能需要分表、大量連接,所以就產生新的資料組織形式——維度模型,面向分析性系統,
維度建模的程序簡單來講就是把資料拉到集群上,經過一系列的 sql 處理分別分成維度表、事實表等,

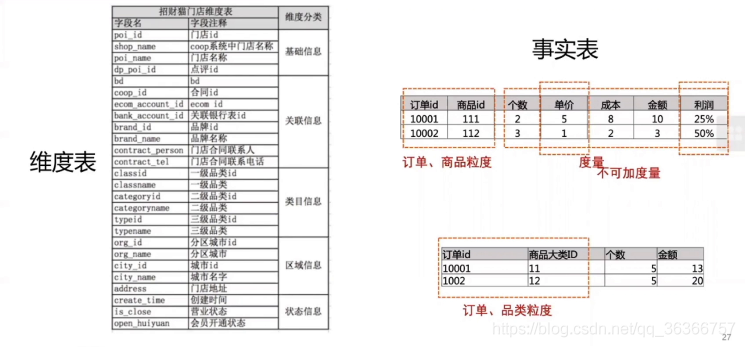
什么是事實呢?比如下面訂單可能就是一個事實,整個表可能是一個門店的資料,最主要的是 poi_id,
通常關系型資料庫是為了記錄、修改和查詢資料本身(增刪改差),對資料本身所含有的業務含義并不關心,簡單說是為了記錄,而資料倉庫則是重點關注資料與資料之間的業務含義,如不同統計口徑與分析方式下數值差的意義,簡單說是為了分析,那么為了保證分析結果的準確和有效,必須分解和細化分析口徑,精確定位影響因素,維表和度量值就是定義分析角度和影響因素的一種方式,(參考:資料倉庫為什么要用事實表和維度表)
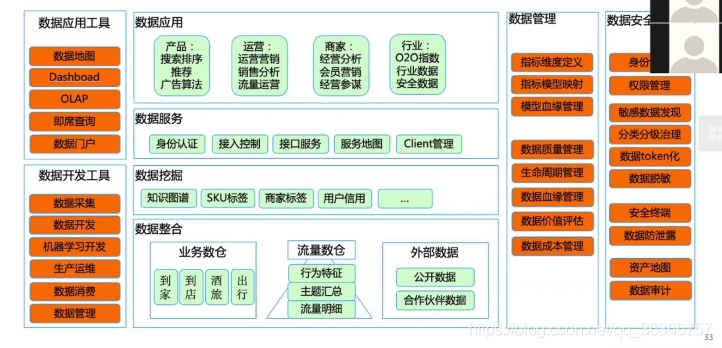
這是美團點評大資料架構全景圖
更加具體或者形象的來說,整個架構可以看作下圖:
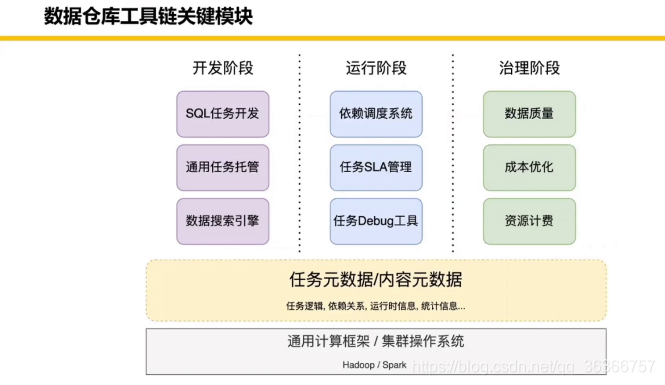
我們主要講到的部分是最底層的一塊,上層任務暫不細講,(在說到成本優化的時候,老師說美團的利潤非常薄,然后就不好意思的笑了)
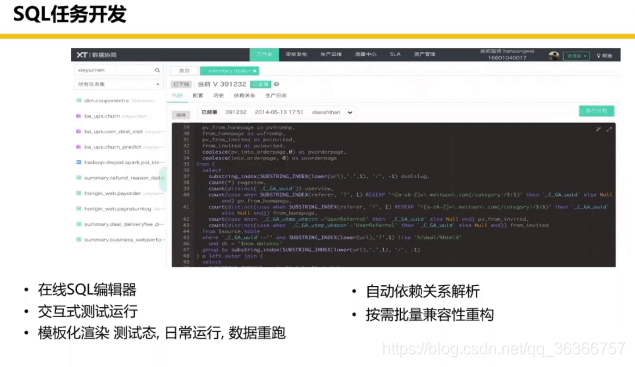
下面是一些美團離線工具鏈關鍵模塊:
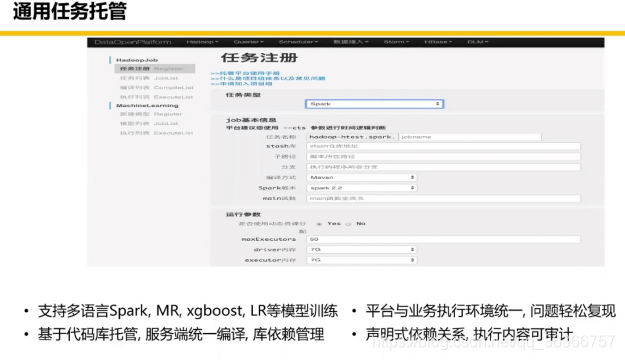
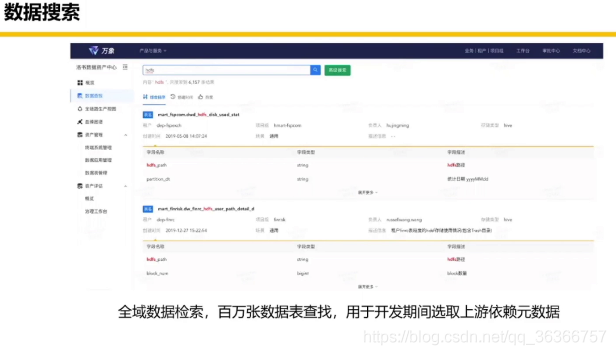
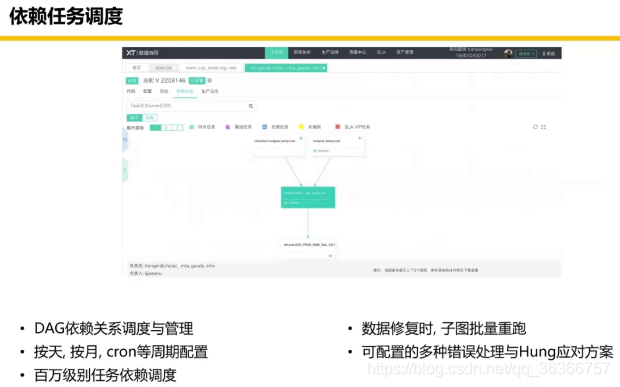
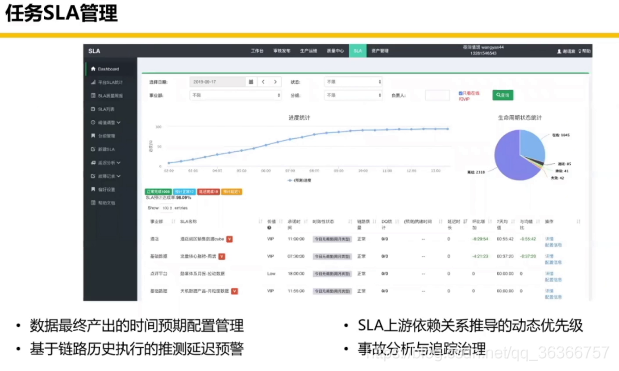
我們回顧一下第一部分,講了 Hadoop/Spark 的功能和定位(理想和現實),應用場景(三個例子),然后資料倉庫的資料組織形式,
二、Hadoop / Spark 核心架構
2.1 核心架構 review
2.1.1 HDFS 分布式檔案存盤
Hadoop 簡介

直觀來看,Hadoop 架構如下:
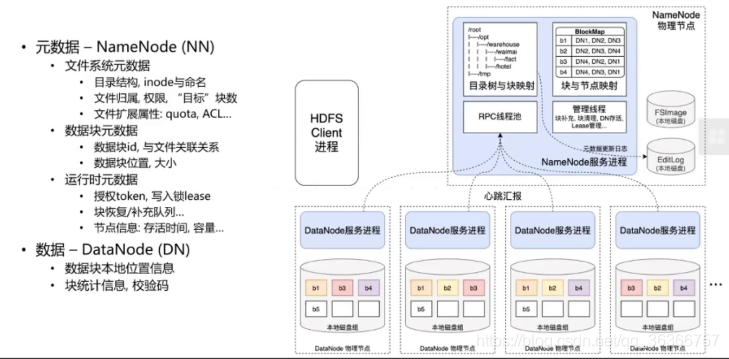
這種配色的圖呢,圓框代表一個行程,虛框代表一個物理機,虛線代表元資料的訪問或者同步,
整體架構主要分成兩部分,一個是 NameNode, 負責資料的組織管理,一個是 DataNode,負責資料的實際存盤,DataNode 會通過心跳定時向 NameNode 匯報自己還活著,
- Editslog :保存了所有對 hdfs 中檔案的操作資訊
- FSImage 是記憶體元資料在本地磁盤的映射,用于維護管理檔案系統樹,即元資料(metadata),
hadoop 中 FsImage 與 Editslog 合并決議
然后集中精神,最難的一部分來了,就是資料的寫流程,
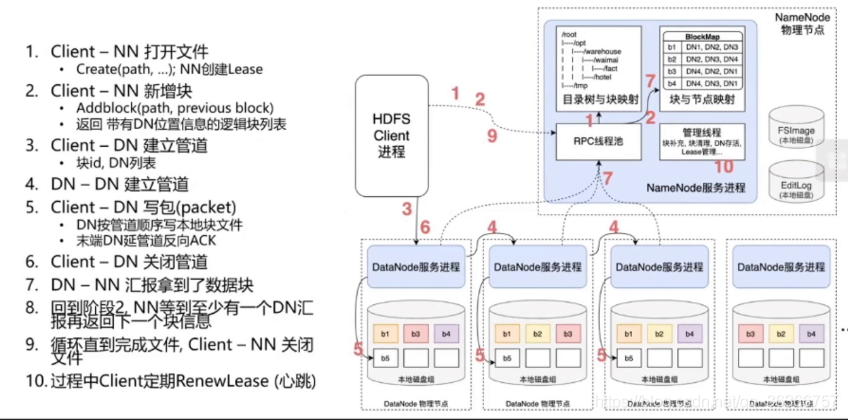
圖中的序號代表執行順序,NN 是 NameNode, DN 是 DataNode,Lease 是心跳(檢測DN是否存活),
當你寫入一個檔案的時候到底發生了什么呢?
首先你打開的客戶端(可能是我們之前提到的命令列或者連接了 SDK 的其他 IDE)會創建一個邏輯檔案,建立心跳,然后客戶端和NN手拉手建立管道, NameNode 找到空的 DN 分配給新檔案并把分配的DN 的地址回傳,然后客戶端和第一個 DN 手拉手建立資料管道,第一個 DN(主節點)和其他 DNs(從節點,也叫副本,一般兩個,防止資料丟失)手拉手建立資料管道,建好管道之后資料就通車了,把資料塊先寫進第一個DN,第一個DN寫完之后寫入第二個 DN,依次往下直至所有資料寫入,最后一個 DN 寫完之后會回傳 ACK 確認碼,說我終于寫好了,接收到的 DN 繼續傳遞(和烽火狼煙差不多),客戶端接收到確認資訊之后就會關閉 Clint-DN 之間的管道,DN 給 NN 報告,我寫完了,這樣第一個資料塊就寫完了,
然后 NN 會繼續找空的 DN,回傳地址,……等等和以上程序一樣,直到所有資料塊全都寫完,客戶端和 NN 之間的管道關閉,資料寫入結束,
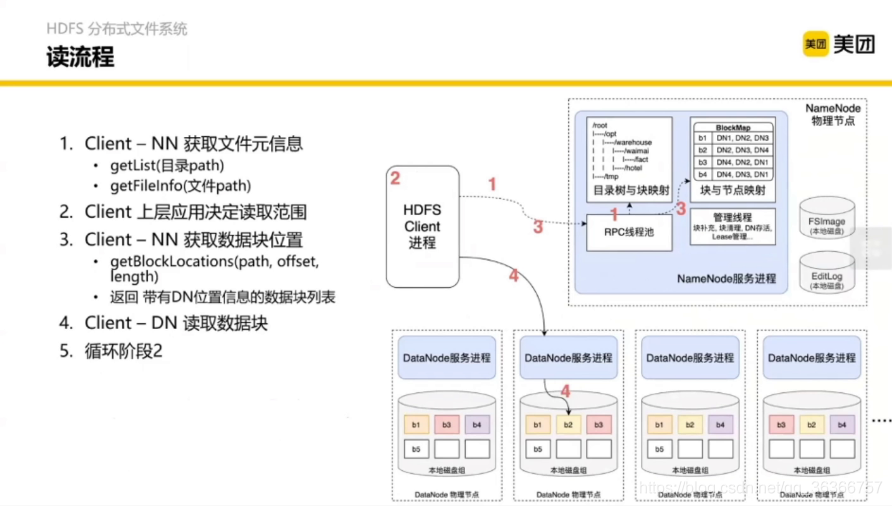
如果寫程序懂了,讀程序就不用介紹了,如果沒懂,那就再回去看看寫程序 (笑),
如果在寫入或者讀取的程序,發生了意外情況,我們該怎么辦呢?這就牽扯到容錯處理了,但是這非常復雜,這里就簡單介紹,
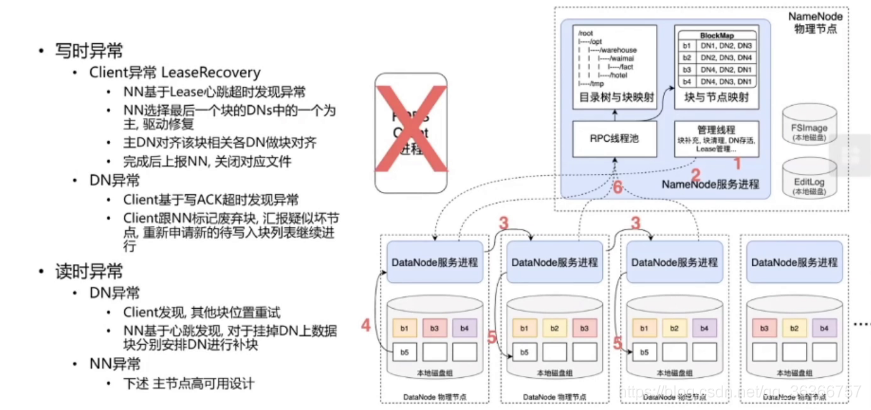
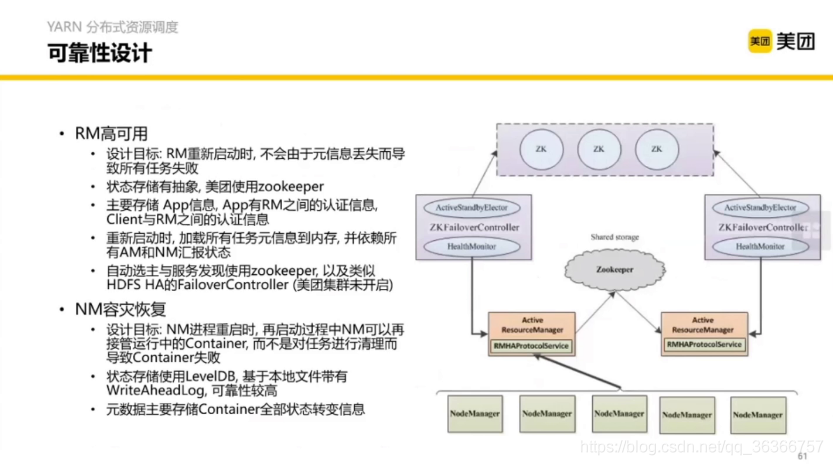
DN 掛掉一定時間以后,NN 會補上一個新的 DN,NN 掛掉會比較麻煩,為了不讓 NN 掛掉產生可怕的影響,所以進行了一定的安全保障的設計,
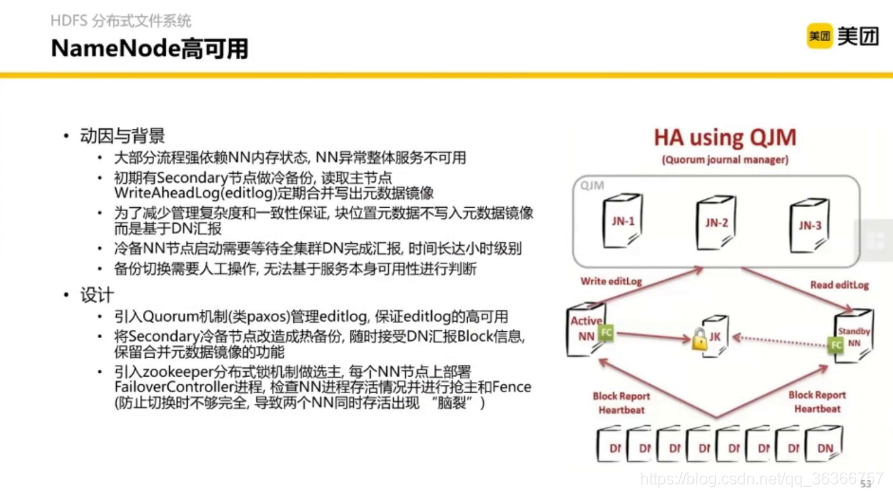
作為一個小白,這里的設計術語也不是很明白,略過不講,想要了解可以參考美團HDFS NameNode重啟優化,或者參考社區解決方案,
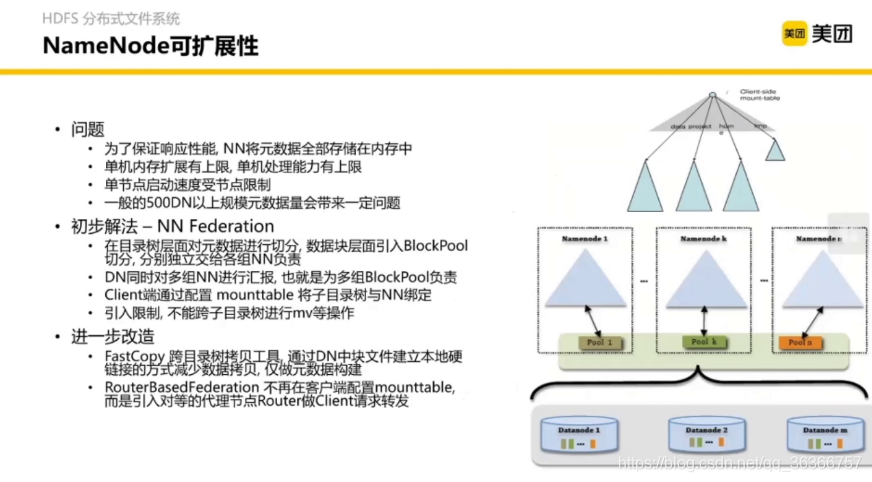
以上兩張圖主要解決記憶體結點高可用,單節點擴展方法問題,
2.1.2 YARN 分布式資源調度
YARN 這里簡單介紹,

YARN 這名字就像是硬湊的(老師說的,與我無瓜),其實就是資源協調器,為了使 Hadoop1.0 版本中資源調度和計算框架進行分析而提出的,YARN 的模塊設計如下,主要包含三個 Manager,
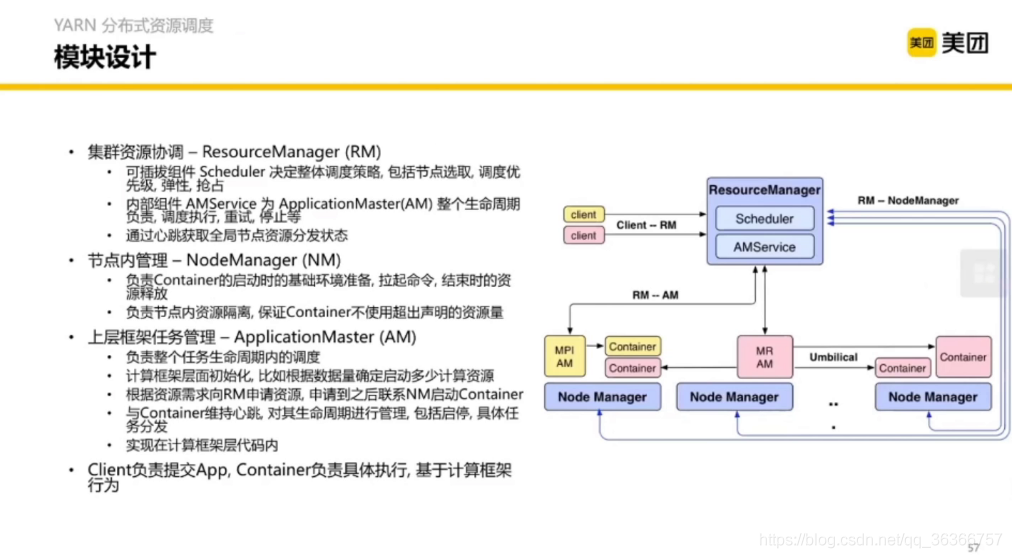
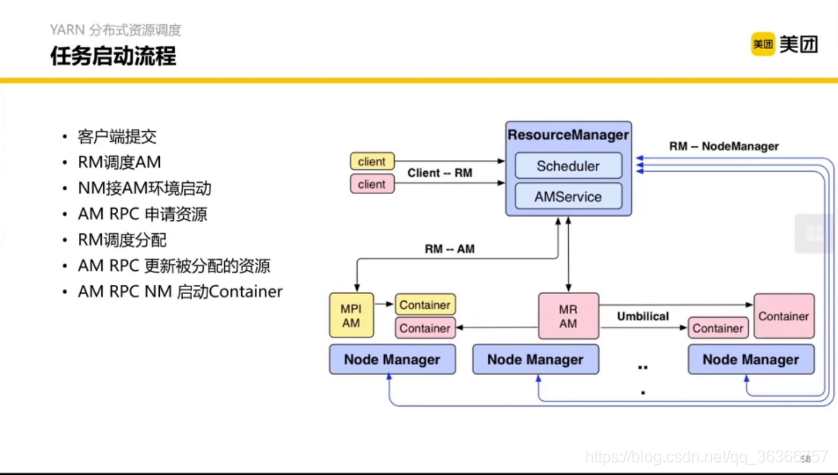
任務啟動流程可大致了解,
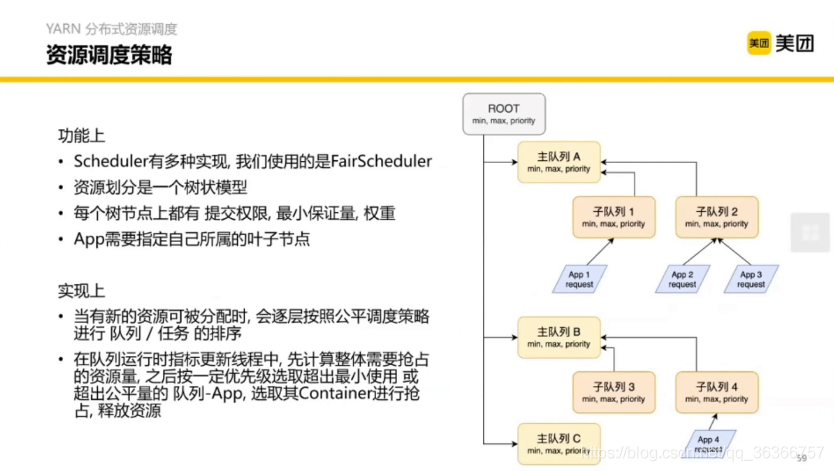
資源調度策略——FairScheduler(公平調度)
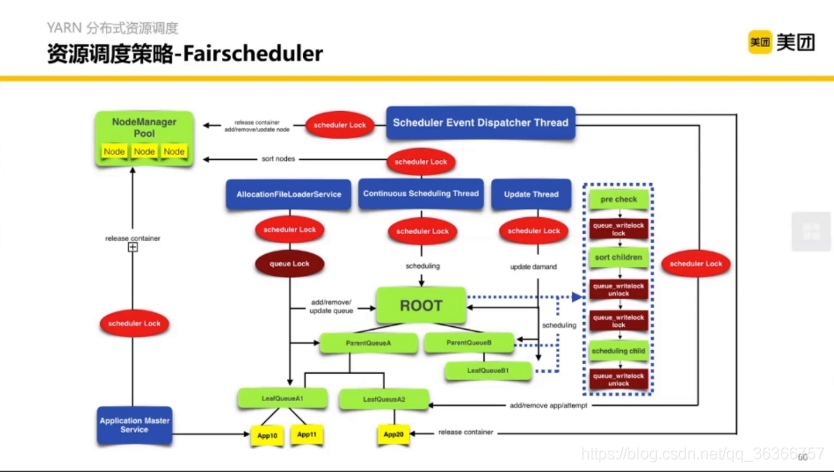
這是 FairScheduler 的內部實作,
具體有哪些資源調度以及什么原理我覺得可以參考這個:Hadoop 的三種調度器
2.1.3 Spark 通用分布式計算框架
Spark 自稱 比 Hadoop 有100倍提升,
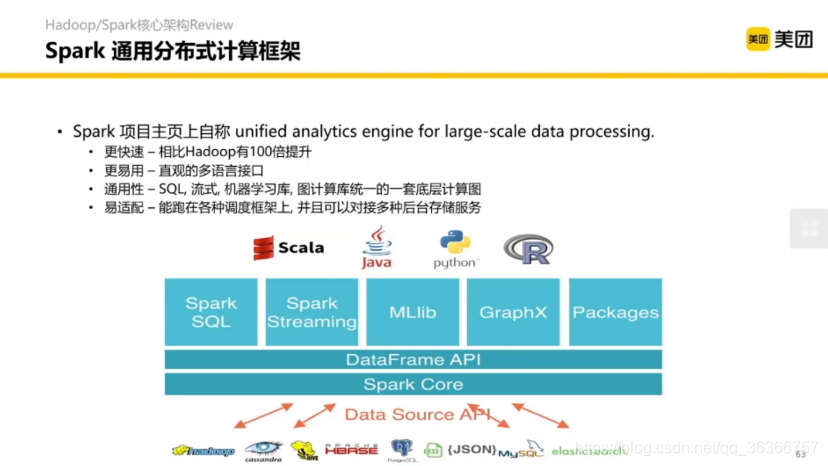
除了支持多語言,也提供了四個框架,包括 Spark SQL,Spark Streaming(流式框架),MLlib(機器學習庫),GraphX(圖計算庫)等,比較完備,
Spark 具體暴露了什么樣的編程介面呢?下圖還是上面提到的 “Hello World” ,通過一個入口命令列啟動自己的程式,自己宣告一個 Spark Session 或者 命令列提供的 Session 去構造 RDD(彈性分布式資料集) 的一個最底層的邏輯抽象,可以把 RDD看作一個大的 list 來用,里面包含各種檔案和資料,RDD 包含兩個算子,一個叫做 Transform,理解為資料的轉換操作;一個叫 Action,理解為對資料的計算操作,

這里是一些其他介面:

這里舉了一個 wordcount 的例子,右邊的圖使左邊代碼的一個直觀體現,主要對應了左邊紅框部分的運算,
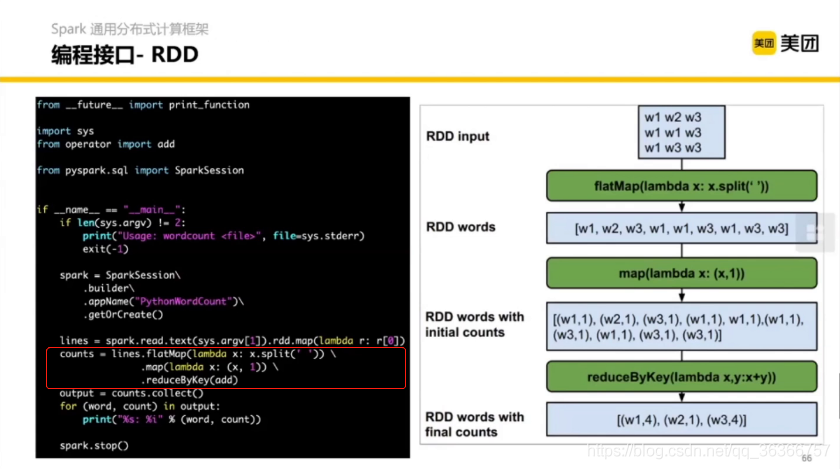
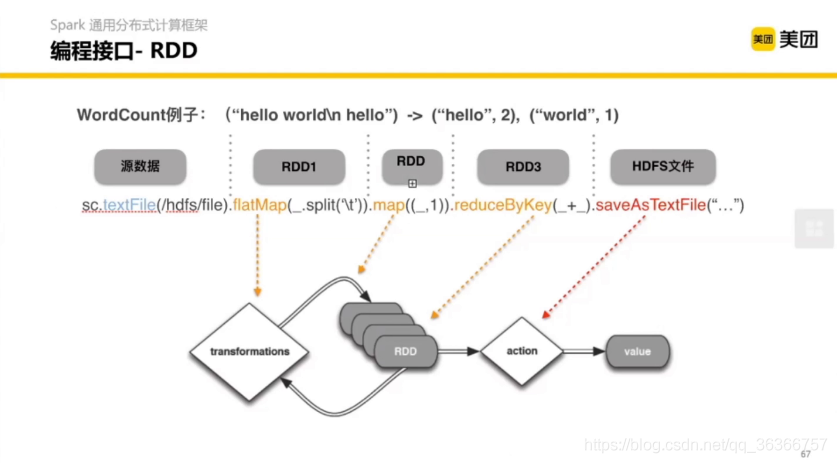
直觀來看,flatMap,map,reduceByKey 是一個 transform 因為其將語料進行了切分,就是進行了資料的轉換,而 saveAsFile 都是 Action,因為其對資料進行計算了存盤,(個人理解)
我們寫好了程式,又該如何提交呢?我們來看一下 Spark 的提交流程,其實和我們的 YARN 的架構很相似,Driver 相當于 YARN 的 app master,基于自己的調度邏輯和 RM 拿資源, 拿到資源后把 Spark Executer 提起來,
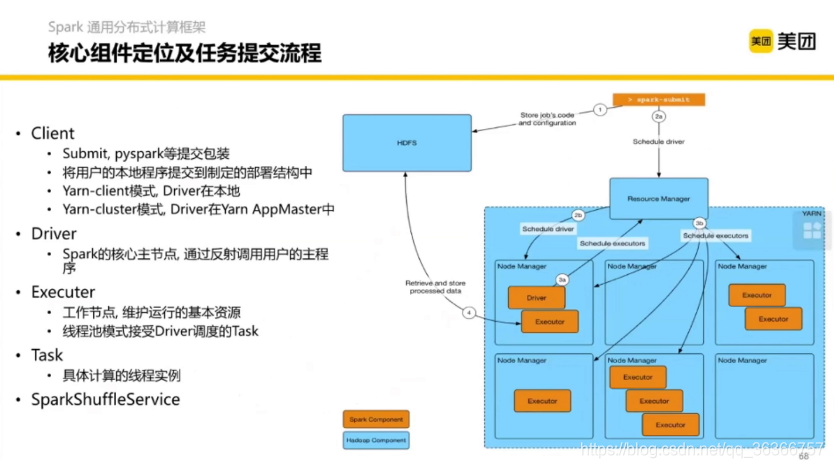
這是一個 RDD 的一個描述圖,最左邊可能是一個 Java 程式,然后通過邏輯進行分割成不同的 stages,每一個小框(一個邏輯)包含幾個塊(task),對于每個task,要到集群(Cluster manager )上申請資源,然后調度到實際在跑的結點上去執行該執行的邏輯,這里的 Worker 就是 Executor,
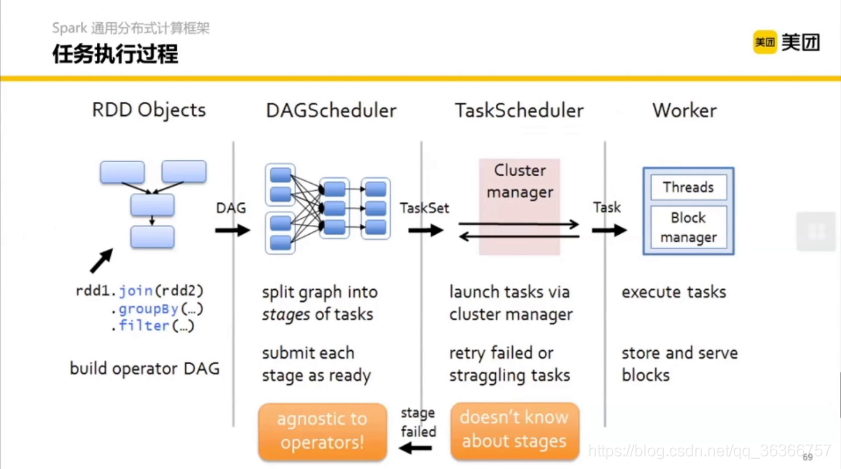
這些概念有印象就行,一般也只有 debug 才會用到,
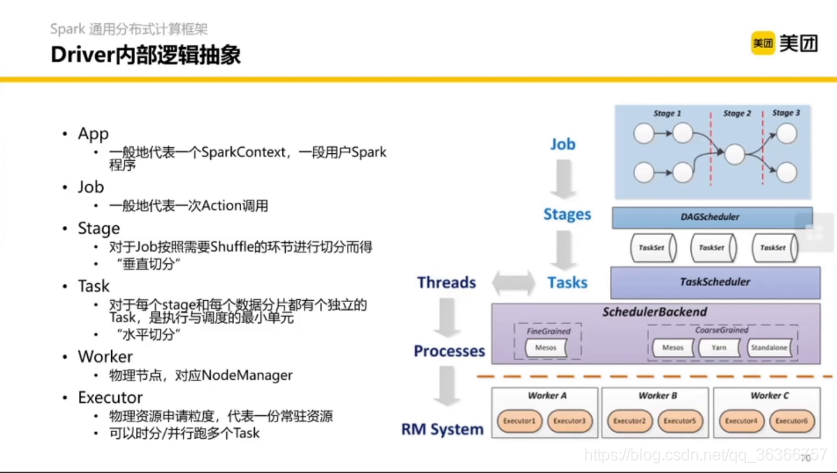
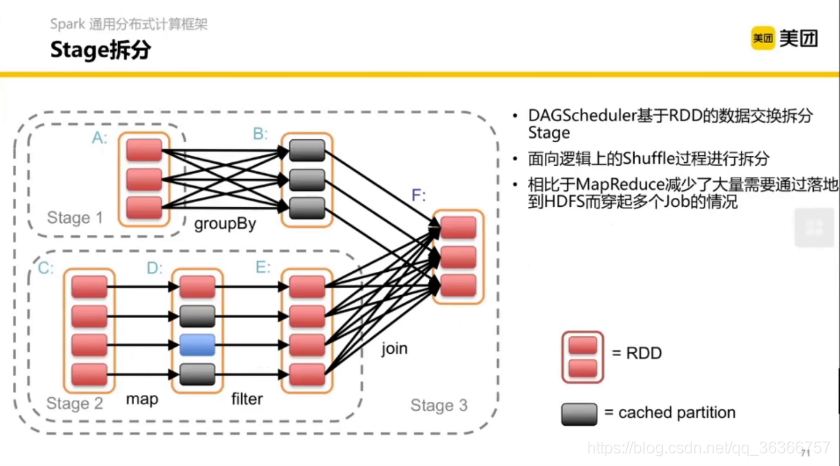
前面我們提到了 Stage,那么 Satge 具體怎么拆分的呢?
用戶提交的計算任務是一個由 RDD 構成的 DAG,如果 RDD 在轉換的時候需要做 Shuffle,那么這個 Shuffle 的程序就將這個 DAG 分為了不同的階段(即Stage),由于 Shuffle 的存在,不同的Stage 是不能并行計算的,因為后面 Stage 的計算需要前面 Stage 的 Shuffle 的結果,
然后我們來看一個比較完整的包含 shuffle 的 mapreduce 的例子,(大家注意區分 mapredcue 中的 map 和 map func 中的 map 的區別)
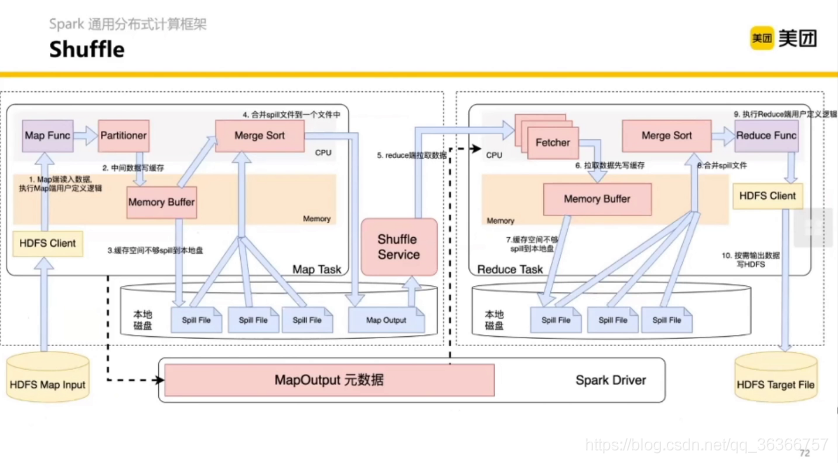
*藍色是資料流轉的程序,圓角黑框是行程,Memory 部分是記憶體部分
流程如下:
- Map 端通過 HDFS Client 讀入資料,執行 Map 端用戶自定義邏輯,
- 通過 key 和 用戶定義 Map Func 對資料進行磁區,中間結果寫入快取,
- 快取空間不夠時(一般使用到80%)會將快取資料寫入檔案,保存到磁盤,這個程序叫 Spill(這里輸出的資料是根據 key 組織,相對有序的),然后就可以繼續寫入記憶體,直到所有資料被處理,
- 對于所有 Spill 得到的檔案(檔案之間無序)和記憶體資料,進行 Merge Sort 按序寫入大檔案,一個 Map 端的結果可能被不同的 Reduce 讀取,所以會有一個 Map 和 Reduce 的映射關系,以及檔案是怎么切分的都會記錄在Spark 中的 MapOutput 元資料中,
- 所有 Map 端 task 跑完之后,Reduce 端服務啟動,拉取 Shuffle 之后的 Map 端結果,
- 拉取資料先寫快取,
- 快取不夠 Spill 到本地磁盤,
- 合并所有 Spill 檔案,
- 執行 Reduce 端用戶定義邏輯
- 按需輸出資料,寫HDFS,
總的來說:
Map 端:map -> partition -> spill -> merge sort -> shuffle
Reduce 端:fetch -> spill -> merge sort -> reduce -> some where
Spark 的容錯相對簡單, 一個 Worker 掛了,就把對應 Task 調度到其他 Worker 就行了,如果 Driver 結點掛掉了,YARN 會幫忙拉起來,
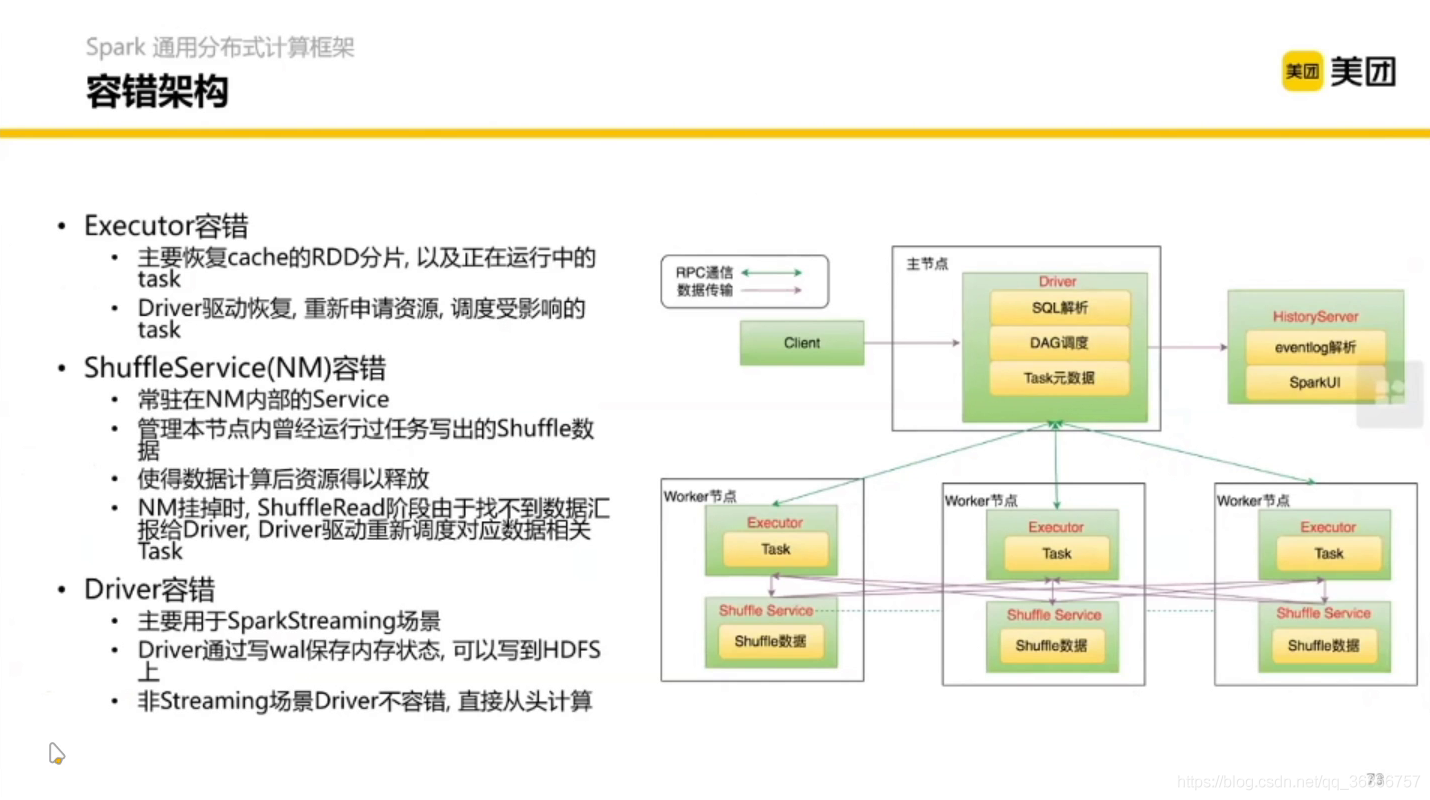
2.2 進一步學習
深入學習建議:
- 動手搭建
- 理論閱讀(如圖)

Designing Data-Intensive Applications 英文版 emmm
三、 美團點評架構改造案例
(這部分我不太了解,就不詳細注釋了,大家有問題可私我)
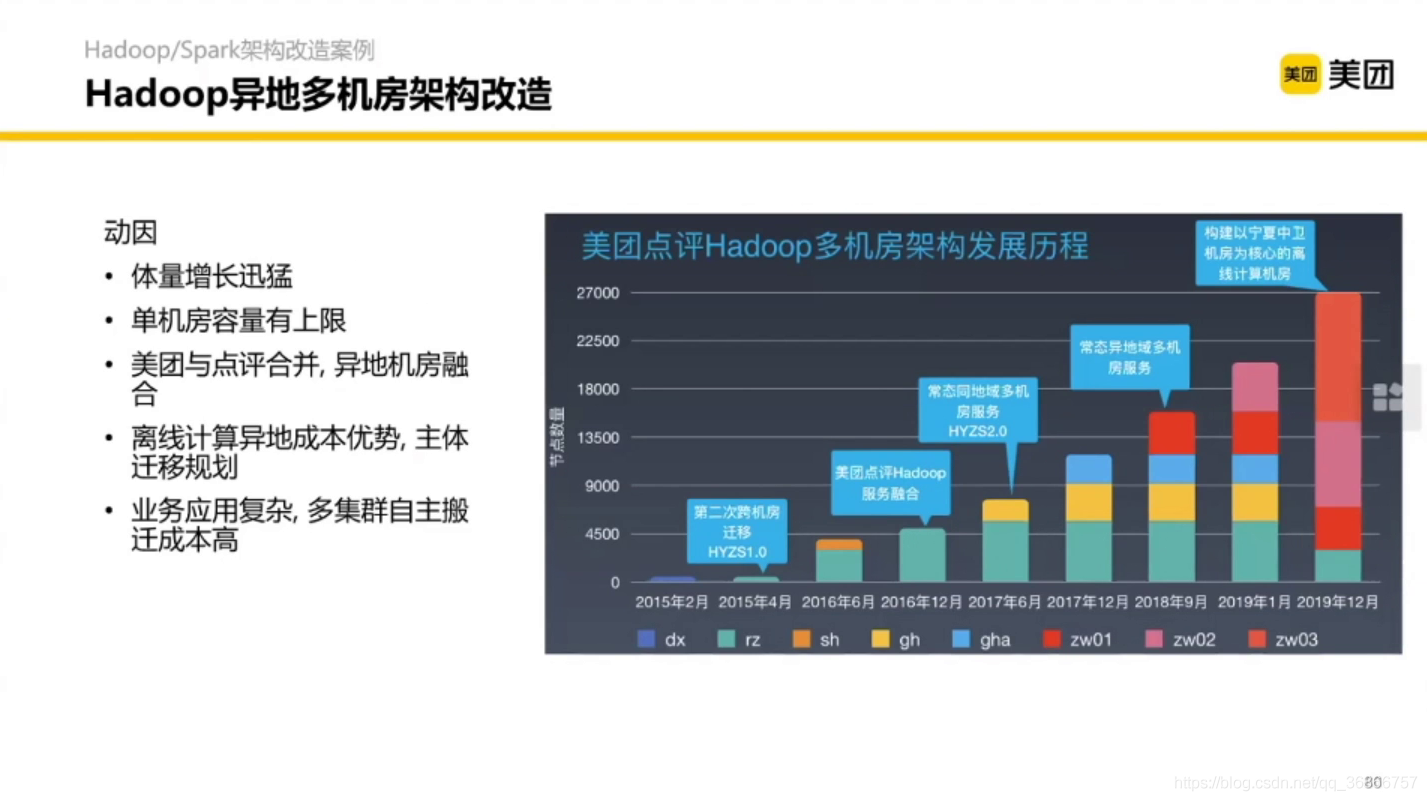
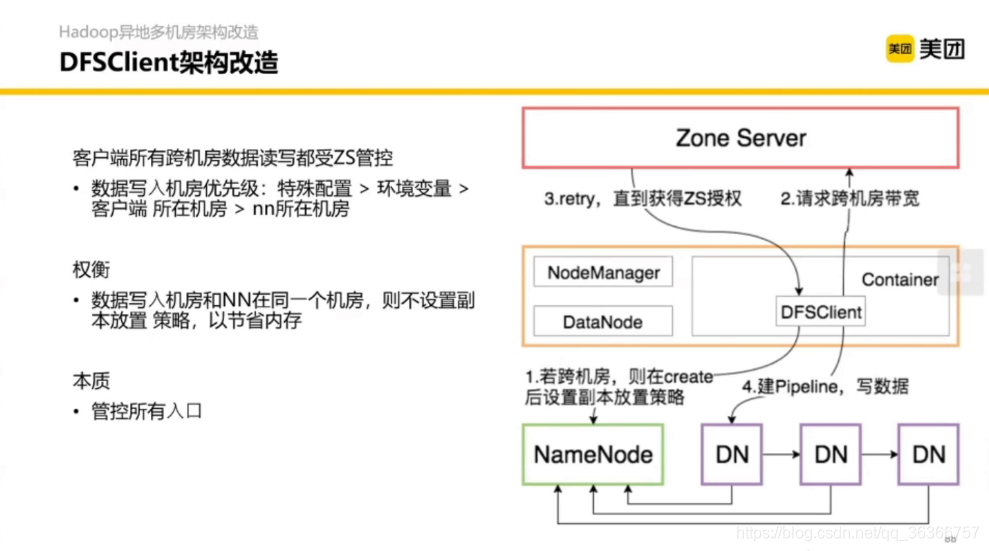
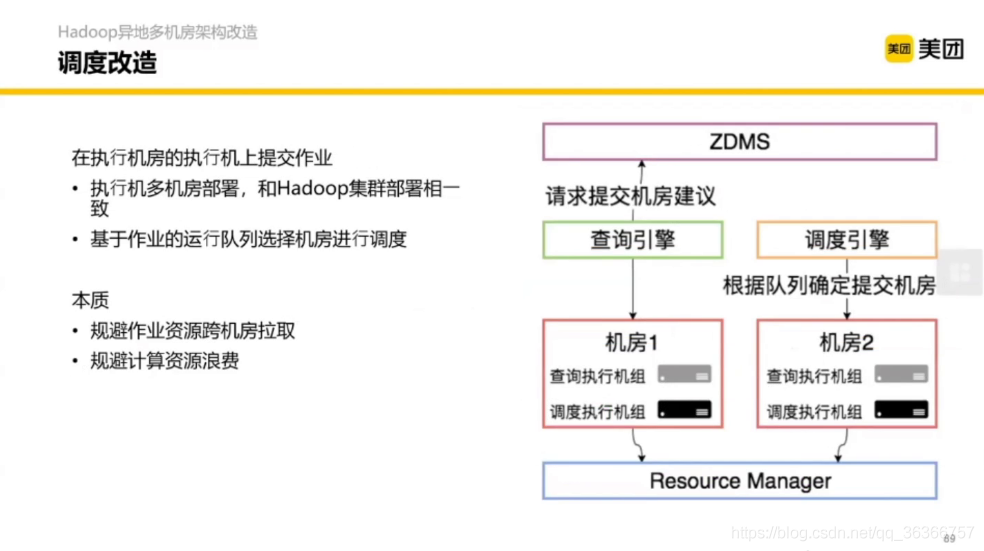
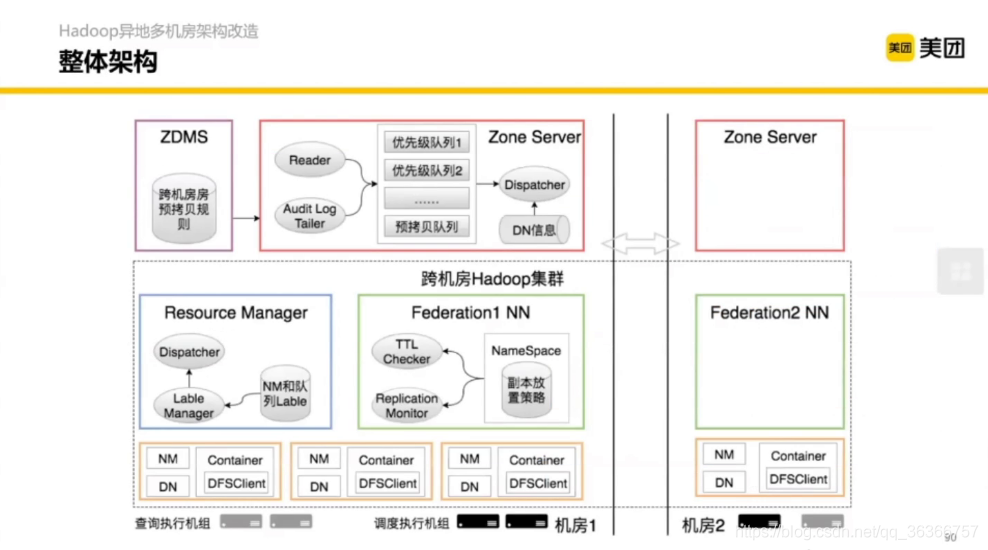
3.1 Hadoop 異地多機房架構改造
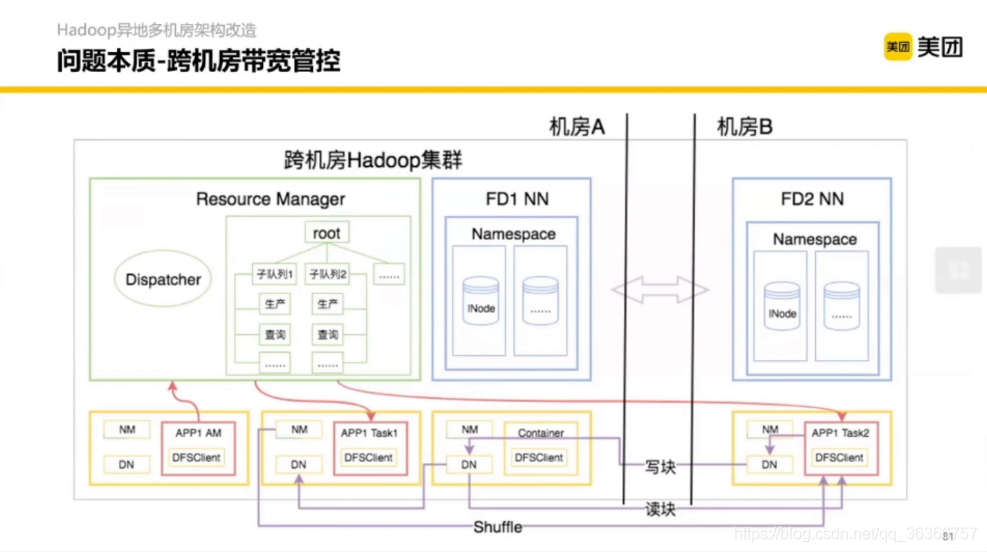
不同顏色代表了不同機房,機房之間可能只用光纖通信,機房之間的通信量遠小于機房之內的機器的,抽象起來就是跨機房帶寬管控,
下面藍框和紅框都是交換機,
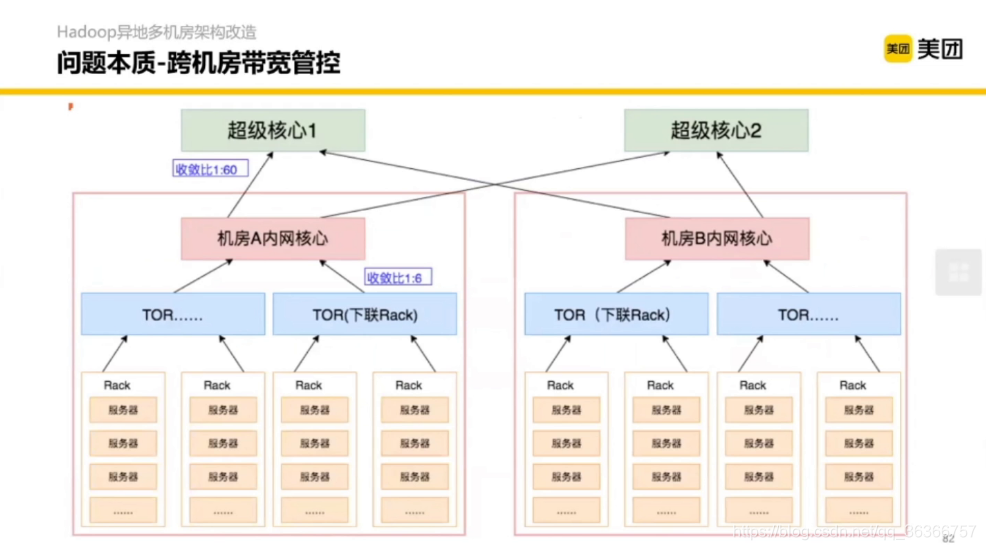

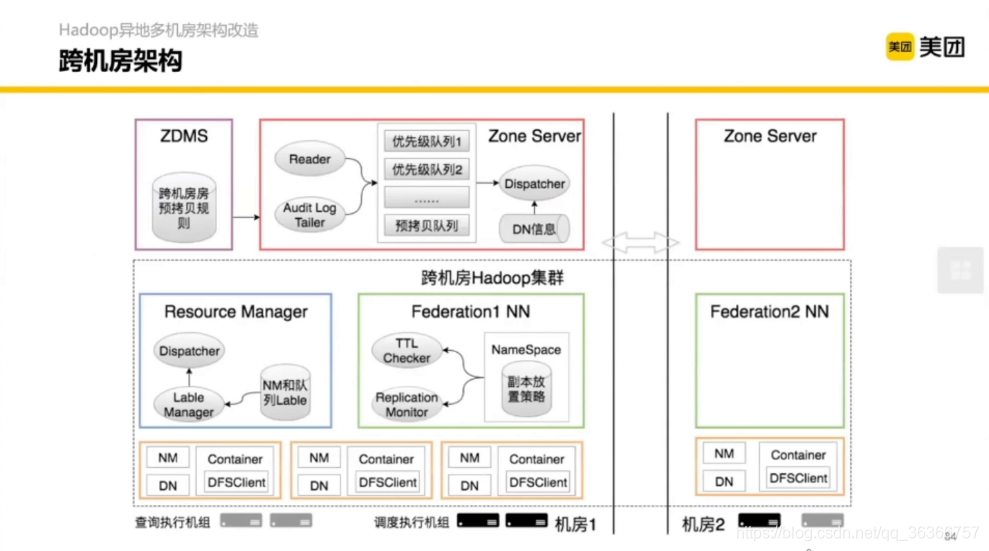
Zone Server 代表了一個機房的服務,
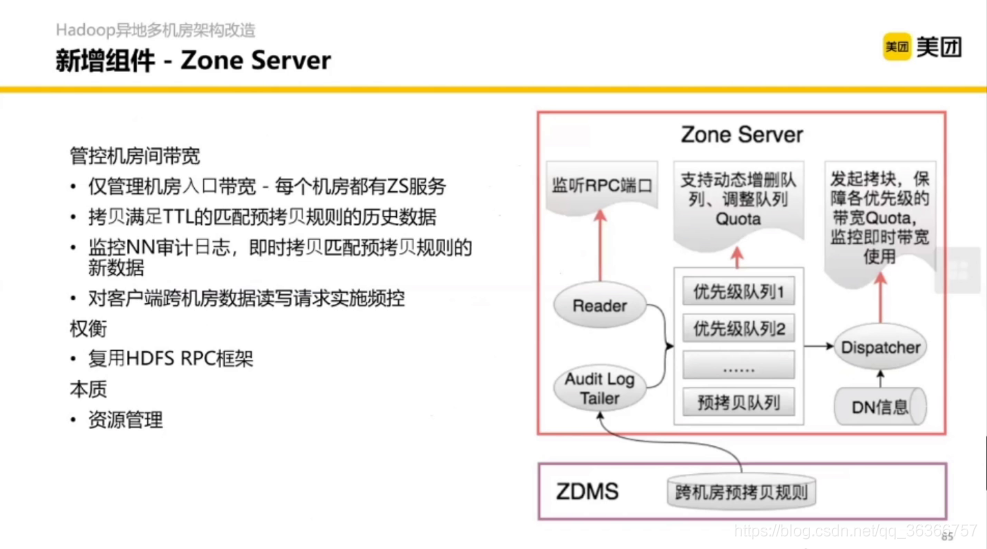
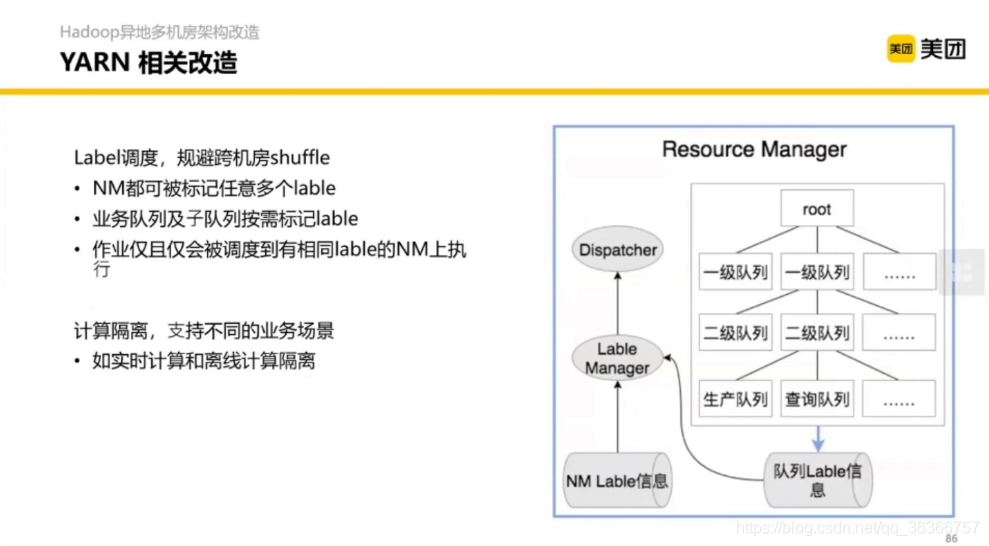
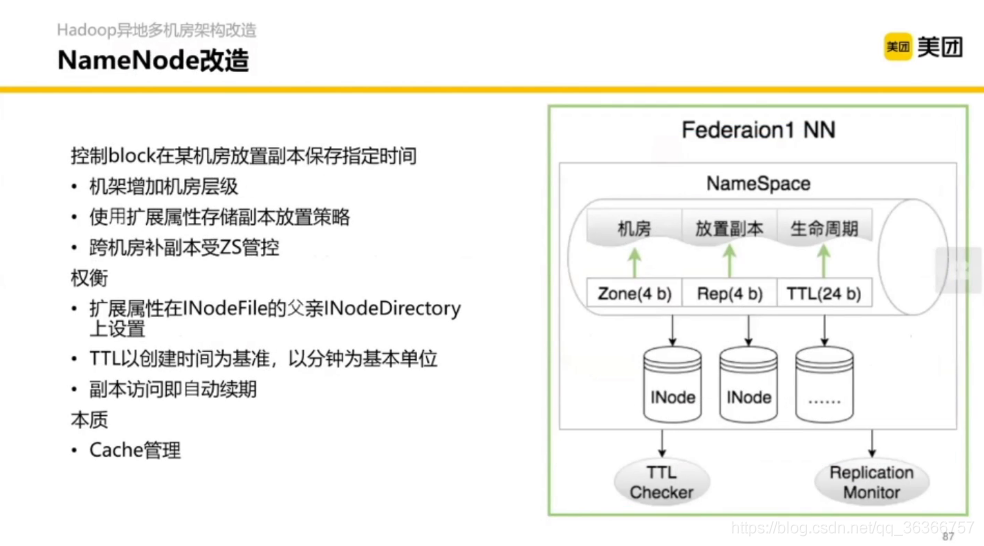


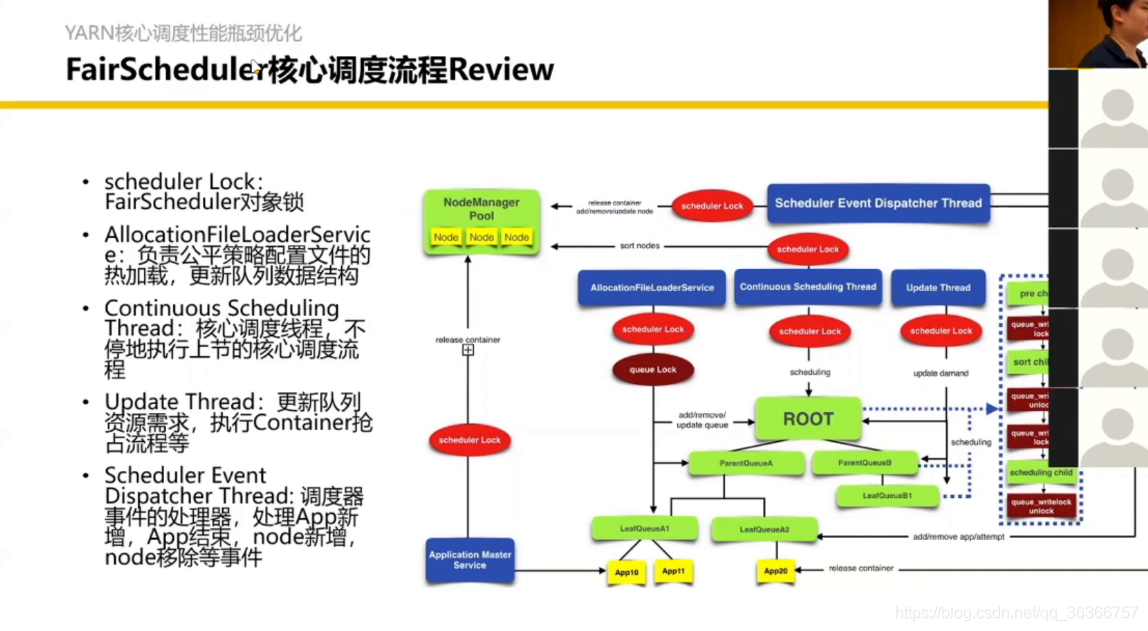
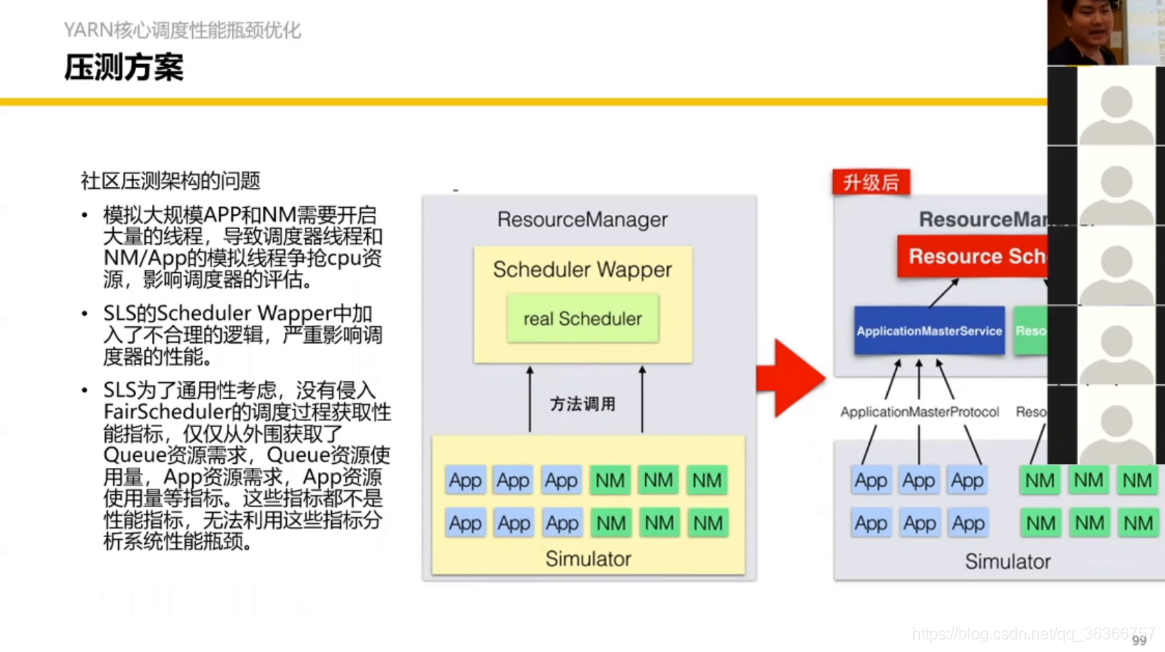
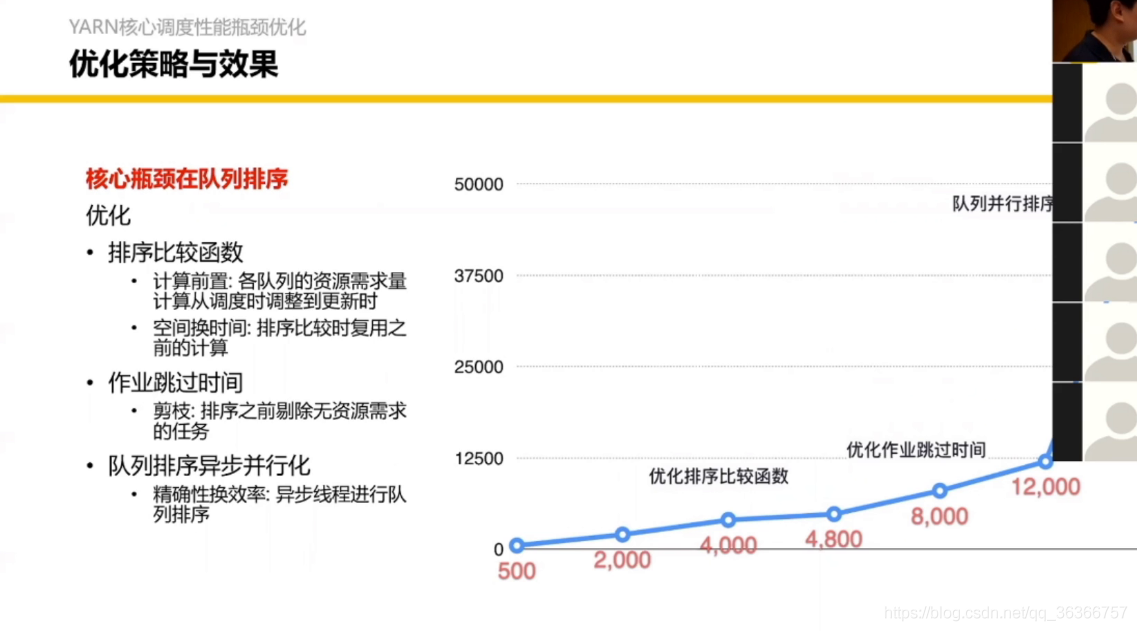
3.2 YARN 核心調度流程優化

之前的YARN調度圖,平均可能一個機器都跑不滿,


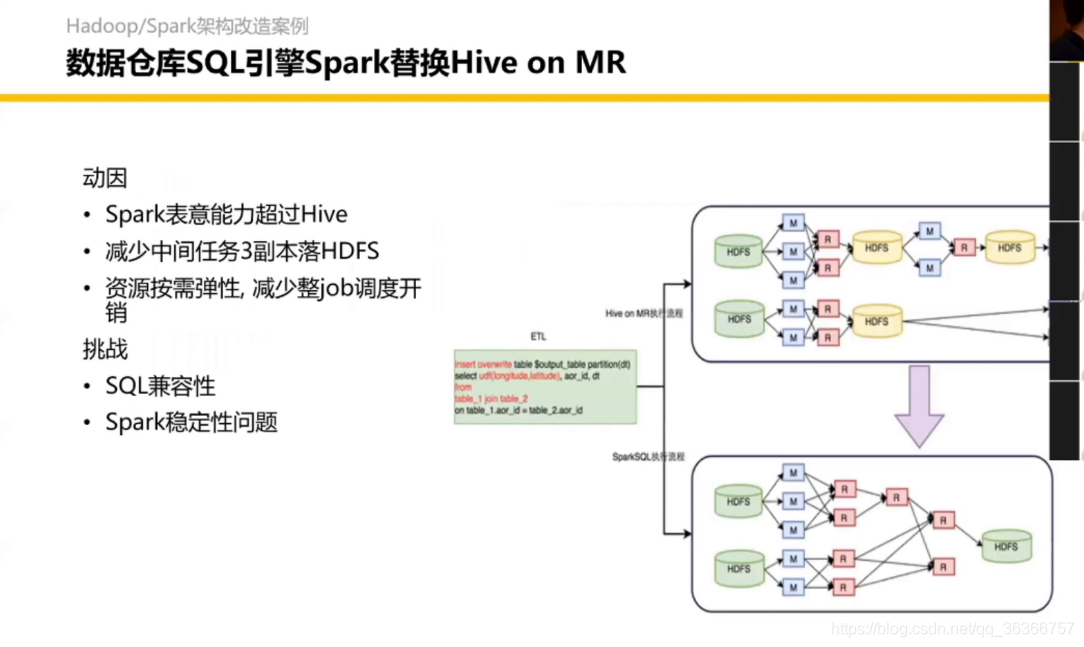
3.3 資料倉庫SQL引擎Spark替換Hive on MR
支持SQL方言不同,不敢全面上線,就把SQL在兩種資料庫上跑一遍,不兼容的情況進一步處理,
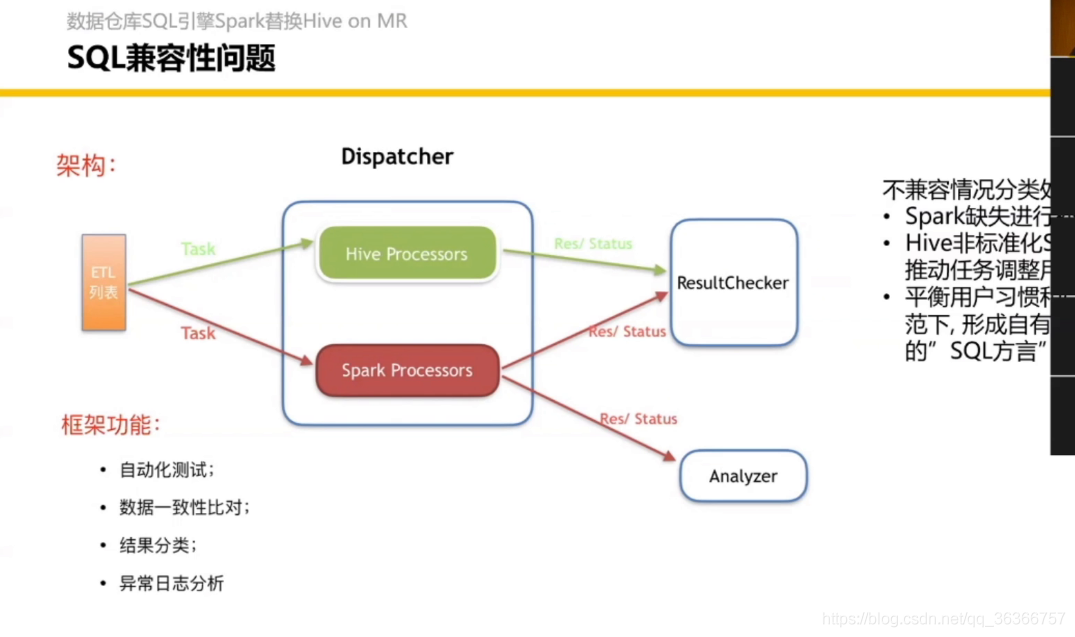
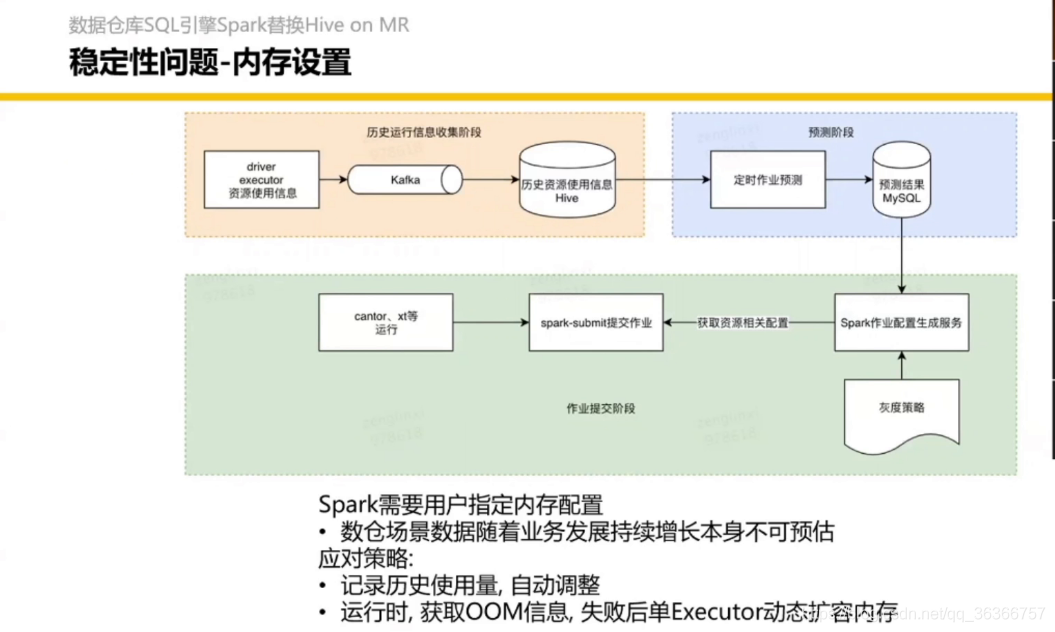
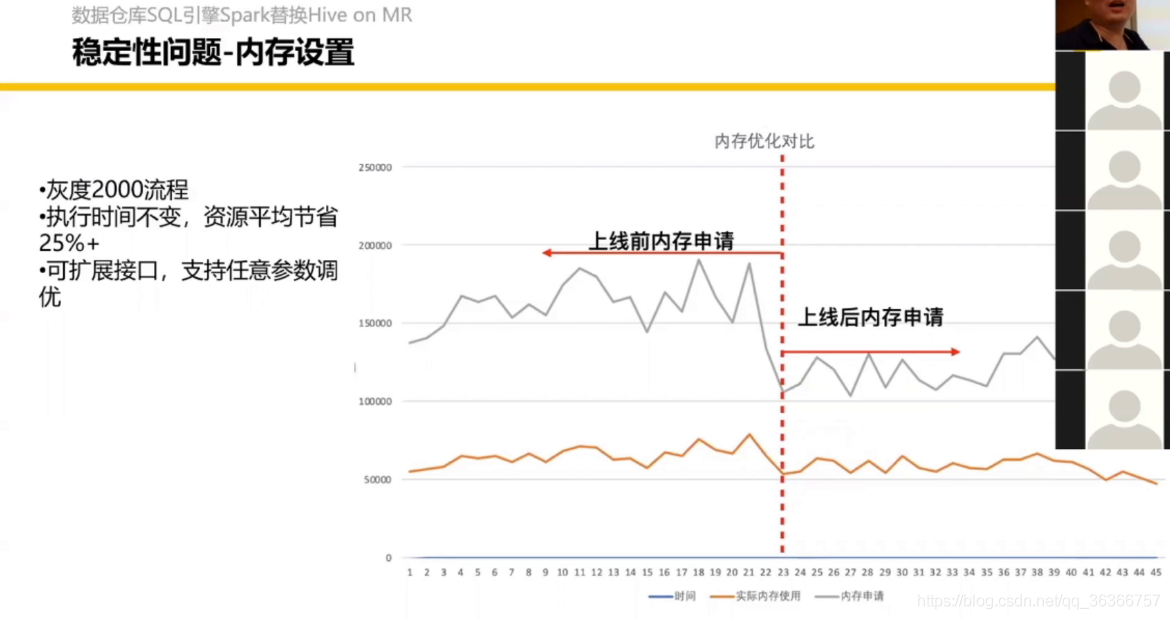
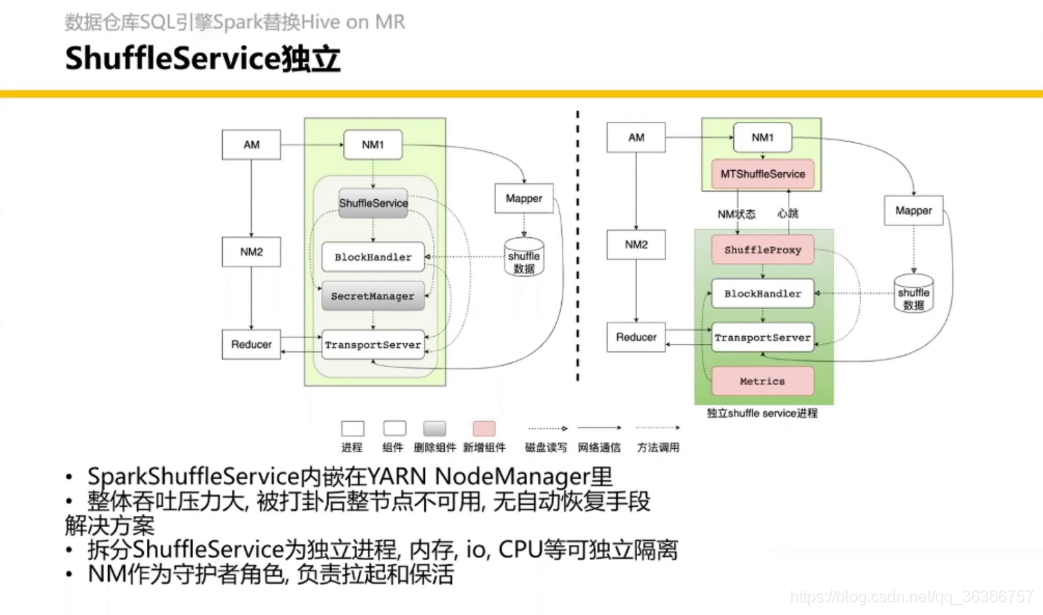
Shuffle Service 會有專門的 paper,最近要發,
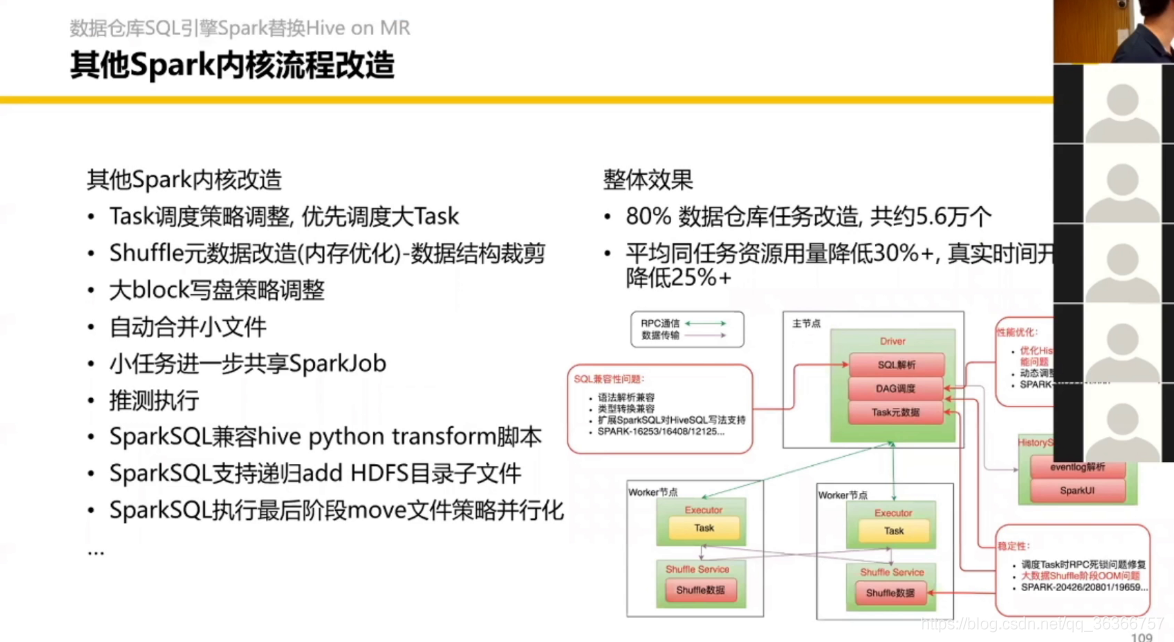

本人剛學不久,可能有地方注釋不是很清楚或者有錯誤,歡迎大家批評指正,分享交流,
相關資料和參考:
- 美團 HDFS NameNode 記憶體詳解
- 美團 HDFS NameNode 重啟優化
- HDFS Federation 在美團點評的應用與改進
- Spark 在美團的實踐
- 美團 Spark 性能優化指南——高級篇
- Hadoop 的三種調度器
- Spark 基本概念、模塊、架構
- hadoop中FsImage與Editslog合并決議
- Designing Data-Intensive Applications
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/187888.html
標籤:其他
上一篇:簡直是千年難遇!這一份最火kafaka實戰筆記 ,細節詳細到你無法想象!
下一篇:前端搞搞基建(二)