目錄
- 動機
- 單層視角
- 多層視角
- 什么是Batch Normalization
- Batch Normalization的反向傳播
- Batch Normalization的預測階段
- Batch Normalization的作用
- 幾個問題
- 卷積層如何使用BatchNorm?
- 沒有scale and shift程序可不可以?
- BN層放在ReLU前面還是后面?
- BN層為什么有效?
- 參考
博客:blog.shinelee.me | 博客園 | CSDN
動機
在博文《為什么要做特征歸一化/標準化? 博客園 | csdn | blog》中,我們介紹了對輸入進行Standardization后,梯度下降演算法更容易選擇到合適的(較大的)學習率,下降程序會更加穩定,
在博文《網路權重初始化方法總結(下):Lecun、Xavier與He Kaiming 博客園 | csdn | blog》中,我們介紹了如何通過權重初始化讓網路在訓練之初保持激活層的輸出(輸入)為zero mean unit variance分布,以減輕梯度消失和梯度爆炸,
但在訓練程序中,權重在不斷更新,導致激活層輸出(輸入)的分布會一直變化,可能無法一直保持zero mean unit variance分布,還是有梯度消失和梯度爆炸的可能,直覺上感到,這可能是個問題,下面具體分析,
單層視角
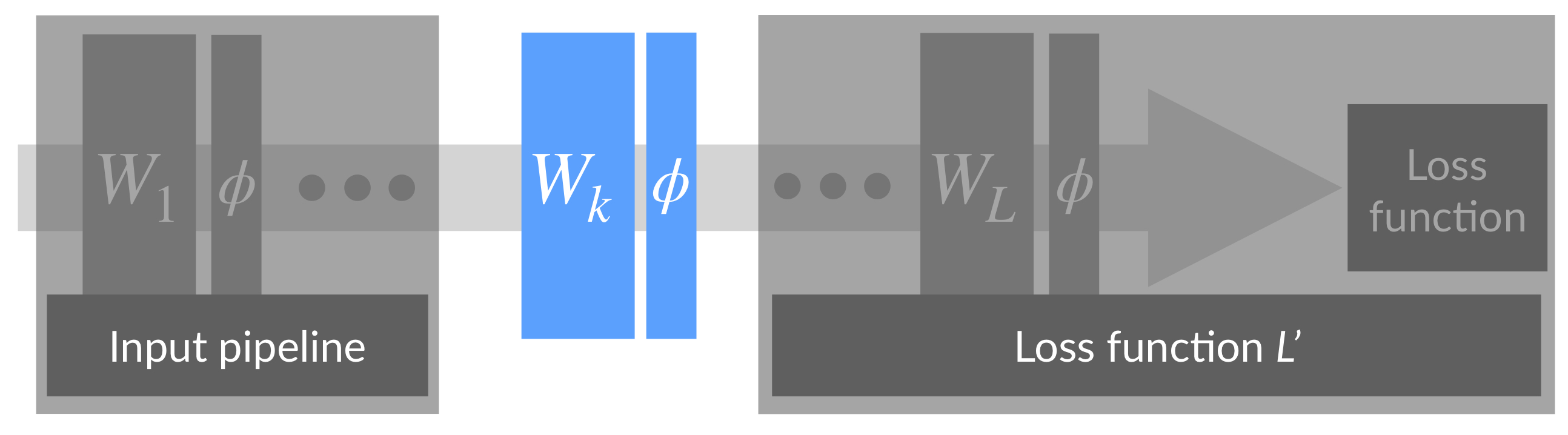
神經網路可以看成是上圖形式,對于中間的某一層,其前面的層可以看成是對輸入的處理,后面的層可以看成是損失函式,一次反向傳播程序會同時更新所有層的權重\(W_1, W_2, \dots, W_L\),前面層權重的更新會改變當前層輸入的分布,而跟據反向傳播的計算方式,我們知道,對\(W_k\)的更新是在假定其輸入不變的情況下進行的,如果假定第\(k\)層的輸入節點只有2個,對第\(k\)層的某個輸出節點而言,相當于一個線性模型\(y = w_1 x_1 + w_2 x_2 + b\),如下圖所示,
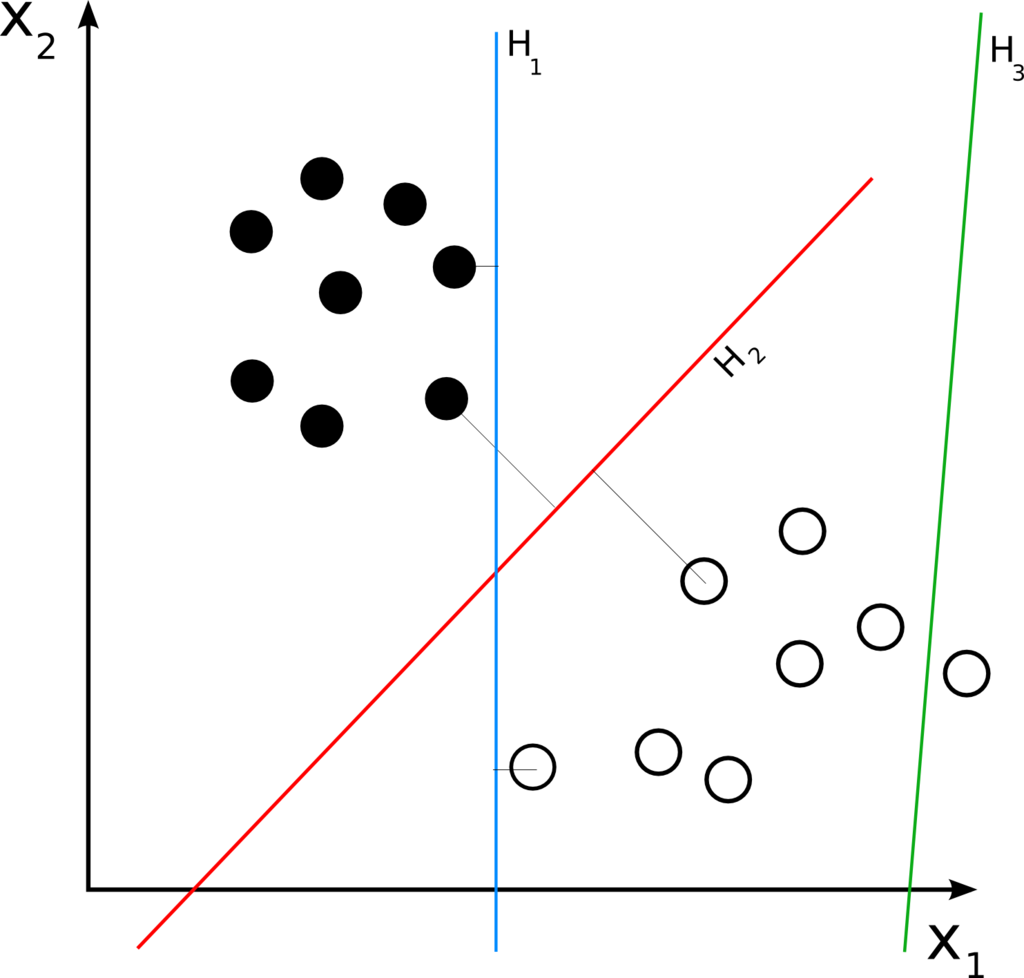
假定當前輸入\(x_1\)和\(x_2\)的分布如圖中圓點所示,本次更新的方向是將直線\(H_1\)更新成\(H_2\),本以為切分得不錯,但是當前面層的權重更新完畢,當前層輸入的分布換成了另外一番樣子,直線相對輸入分布的位置可能變成了\(H_3\),下一次更新又要根據新的分布重新調整,直線調整了位置,輸入分布又在發生變化,直線再調整位置,就像是直線和分布之間的“追逐游戲”,對于淺層模型,比如SVM,輸入特征的分布是固定的,即使拆分成不同的batch,每個batch的統計特性也是相近的,因此只需調整直線位置來適應輸入分布,顯然要容易得多,而深層模型,每層輸入的分布和權重在同時變化,訓練相對困難,
多層視角
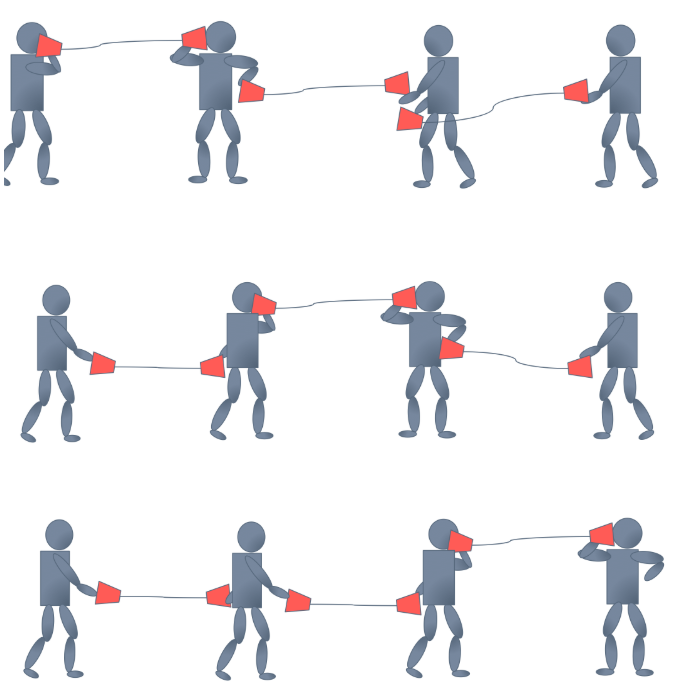
上面是從網路中單拿出一層分析,下面看一下多層的情況,在反向傳播程序中,每層權重的更新是在假定其他權重不變的情況下,向損失函式降低的方向調整自己,問題在于,在一次反向傳播程序中,所有的權重會同時更新,導致層間配合“缺乏默契”,每層都在進行上節所說的“追逐游戲”,而且層數越多,相互配合越困難,文中把這個現象稱之為 Internal Covariate Shift,示意圖如下,為了避免過于震蕩,學習率不得不設定得足夠小,足夠小就意味著學習緩慢,
為此,希望對每層輸入的分布有所控制,于是就有了Batch Normalization,其出發點是對每層的輸入做Normalization,只有一個資料是談不上Normalization的,所以是對一個batch的資料進行Normalization,
什么是Batch Normalization
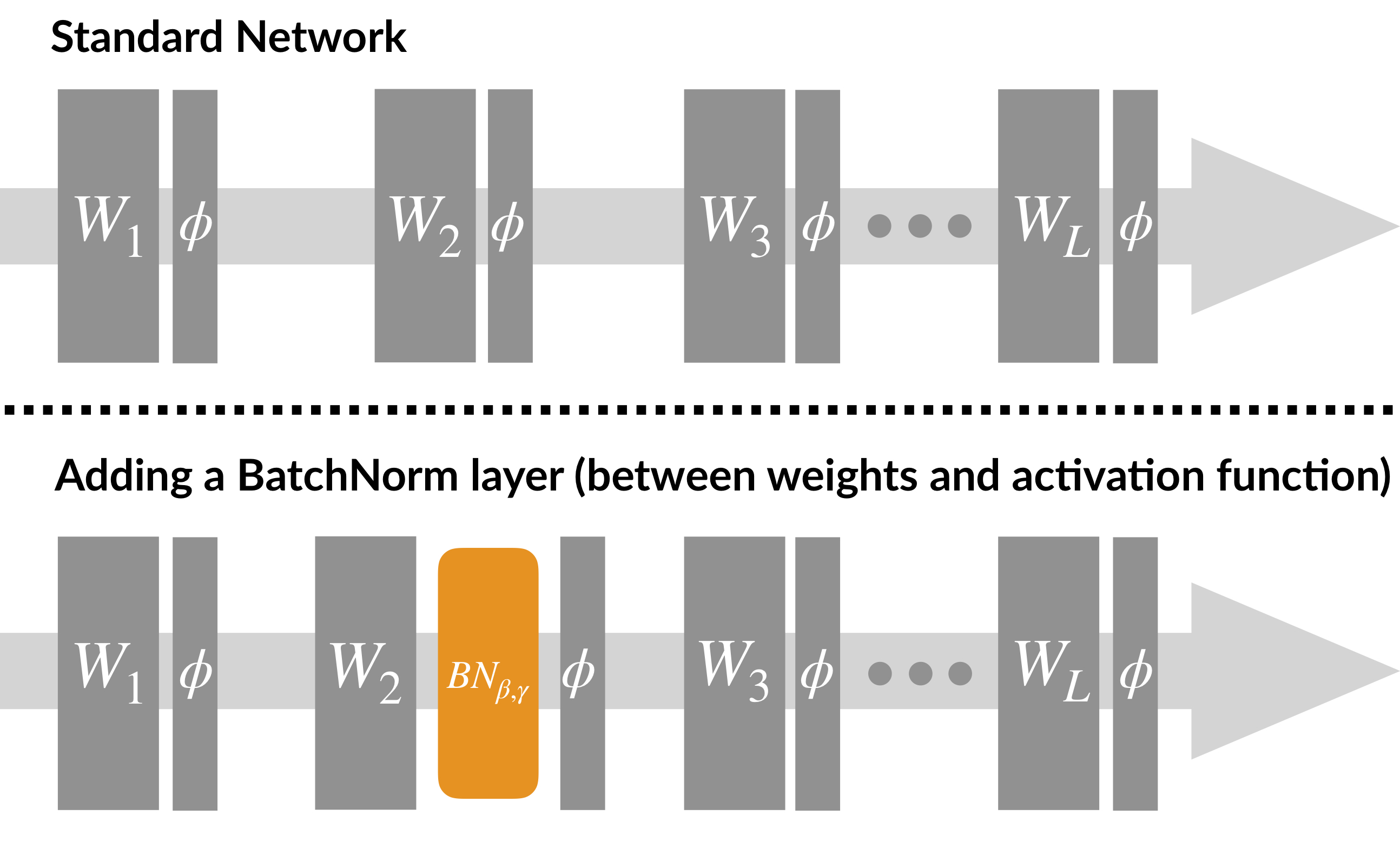
Batch Normalization,簡稱BatchNorm或BN,翻譯為“批歸一化”,是神經網路中一種特殊的層,如今已是各種流行網路的標配,在原paper中,BN被建議插入在(每個)ReLU激活層前面,如下所示,
如果batch size為\(m\),則在前向傳播程序中,網路中每個節點都有\(m\)個輸出,所謂的Batch Normalization,就是對該層每個節點的這\(m\)個輸出進行歸一化再輸出,具體計算方式如下,

其操作可以分成2步,
- Standardization:首先對\(m\)個\(x\)進行 Standardization,得到 zero mean unit variance的分布\(\hat{x}\),
- scale and shift:然后再對\(\hat{x}\)進行scale and shift,縮放并平移到新的分布\(y\),具有新的均值\(\beta\)方差\(\gamma\),
假設BN層有\(d\)個輸入節點,則\(x\)可構成\(d \times m\)大小的矩陣\(X\),BN層相當于通過行操作將其映射為另一個\(d\times m\)大小的矩陣\(Y\),如下所示,
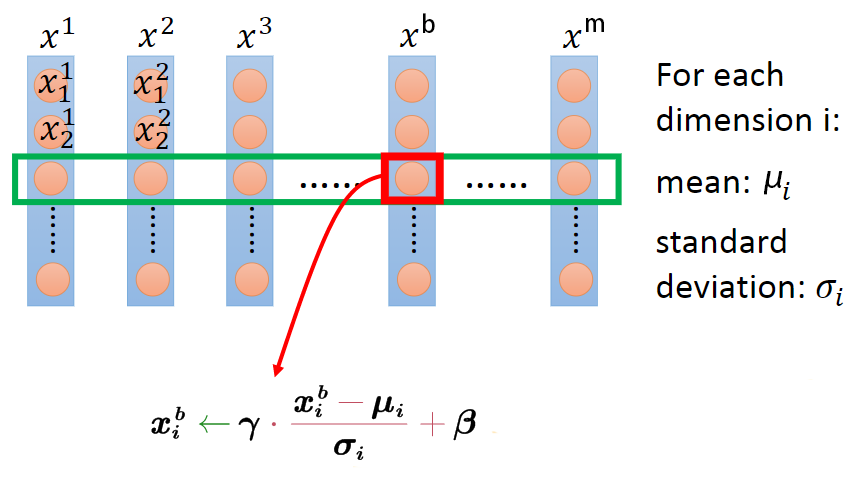 將2個程序寫在一個公式里如下,
將2個程序寫在一個公式里如下,
其中,\(x_i^{(b)}\)表示輸入當前batch的\(b\)-th樣本時該層\(i\)-th輸入節點的值,\(x_i\)為\([x_i^{(1)}, x_i^{(2)}, \dots, x_i^{(m)}]\)構成的行向量,長度為batch size \(m\),\(\mu\)和\(\sigma\)為該行的均值和標準差,\(\epsilon\)為防止除零引入的極小量(可忽略),\(\gamma\)和\(\beta\)為該行的scale和shift引數,可知
- \(\mu\)和\(\sigma\)為當前行的統計量,不可學習,
- \(\gamma\)和\(\beta\)為待學習的scale和shift引數,用于控制\(y_i\)的方差和均值,
- BN層中,\(x_i\)和\(x_j\)之間不存在資訊交流\((i \neq j)\)
可見,無論\(x_i\)原本的均值和方差是多少,通過BatchNorm后其均值和方差分別變為待學習的\(\beta\)和\(\gamma\),
Batch Normalization的反向傳播
對于目前的神經網路計算框架,一個層要想加入到網路中,要保證其是可微的,即可以求梯度,BatchNorm的梯度該如何求取?
反向傳播求梯度只需抓住一個關鍵點,如果一個變數對另一個變數有影響,那么他們之間就存在偏導數,找到直接相關的變數,再配合鏈式法則,公式就很容易寫出了,
\[\begin{array}{l}{\frac{\partial \ell}{\partial \gamma}=\sum_{i=1}^{m} \frac{\partial \ell}{\partial y_{i}} \cdot \widehat{x}_{i}} \\ {\frac{\partial \ell}{\partial \beta}=\sum_{i=1}^{m} \frac{\partial \ell}{\partial y_{i}}} \\{\frac{\partial \ell}{\partial \widehat{x}_{i}}=\frac{\partial \ell}{\partial y_{i}} \cdot \gamma} \\ {\frac{\partial \ell}{\partial \sigma_{B}^{2}}=\sum_{i=1}^{m} \frac{\partial \ell}{\partial \widehat{x}_{i}} \cdot\left(x_{i}-\mu_{\mathcal{B}}\right) \cdot \frac{-1}{2}\left(\sigma_{\mathcal{B}}^{2}+\epsilon\right)^{-3 / 2}} \\ {\frac{\partial \ell}{\partial \mu_{\mathcal{B}}}=\left(\sum_{i=1}^{m} \frac{\partial \ell}{\partial \widehat{x}_{i}} \cdot \frac{-1}{\sqrt{\sigma_{\mathcal{B}}^{2}+\epsilon}}\right)+\frac{\partial \ell}{\partial \sigma_{\mathcal{B}}^{2}} \cdot \frac{\sum_{i=1}^{m}-2\left(x_{i}-\mu_{\mathcal{B}}\right)}{m}} \\ {\frac{\partial \ell}{\partial x_{i}} = \frac{\partial \ell}{\partial \widehat{x}_{i}} \cdot \frac{1}{\sqrt{\sigma_{\mathcal{B}}^{2}+\epsilon}} + \frac{\partial \ell}{\partial \sigma_{\mathcal{B}}^{2}} \cdot \frac{2\left(x_{i}-\mu_{\mathcal{B}}\right)}{m} + \frac{\partial \ell}{\partial \mu_{\mathcal{B}}} \cdot \frac{1}{m}} \\ \end{array} \]根據反向傳播的順序,首先求取損失\(\ell\)對BN層輸出\(y_i\)的偏導\(\frac{\partial \ell}{\partial y_{i}}\),然后是對可學習引數的偏導\(\frac{\partial \ell}{\partial \gamma}\)和\(\frac{\partial \ell}{\partial \beta}\),用于對引數進行更新,想繼續回傳的話還需要求對輸入 \(x\)偏導,于是引出對變數\(\mu\)、\(\sigma^2\)和\(\hat{x}\)的偏導,根據鏈式法則再求這些變數對\(x\)的偏導,
在實際實作時,通常以矩陣或向量運算方式進行,比如逐元素相乘、沿某個axis求和、矩陣乘法等操作,具體可以參見Understanding the backward pass through Batch Normalization Layer和BatchNorm in Caffe,
Batch Normalization的預測階段
在預測階段,所有引數的取值是固定的,對BN層而言,意味著\(\mu\)、\(\sigma\)、\(\gamma\)、\(\beta\)都是固定值,
\(\gamma\)和\(\beta\)比較好理解,隨著訓練結束,兩者最終收斂,預測階段使用訓練結束時的值即可,
對于\(\mu\)和\(\sigma\),在訓練階段,它們為當前mini batch的統計量,隨著輸入batch的不同,\(\mu\)和\(\sigma\)一直在變化,在預測階段,輸入資料可能只有1條,該使用哪個\(\mu\)和\(\sigma\),或者說,每個BN層的\(\mu\)和\(\sigma\)該如何取值?可以采用訓練收斂最后幾批mini batch的 \(\mu\)和\(\sigma\)的期望,作為預測階段的\(\mu\)和\(\sigma\),如下所示,

因為Standardization和scale and shift均為線性變換,在預測階段所有引數均固定的情況下,引數可以合并成\(y=kx+b\)的形式,如上圖中行號11所示,
Batch Normalization的作用
使用Batch Normalization,可以獲得如下好處,
- 可以使用更大的學習率,訓練程序更加穩定,極大提高了訓練速度,
- 可以將bias置為0,因為Batch Normalization的Standardization程序會移除直流分量,所以不再需要bias,
- 對權重初始化不再敏感,通常權重采樣自0均值某方差的高斯分布,以往對高斯分布的方差設定十分重要,有了Batch Normalization后,對與同一個輸出節點相連的權重進行放縮,其標準差\(\sigma\)也會放縮同樣的倍數,相除抵消,
- 對權重的尺度不再敏感,理由同上,尺度統一由\(\gamma\)引數控制,在訓練中決定,
- 深層網路可以使用sigmoid和tanh了,理由同上,BN抑制了梯度消失,
- Batch Normalization具有某種正則作用,不需要太依賴dropout,減少過擬合,
幾個問題
卷積層如何使用BatchNorm?
For convolutional layers, we additionally want the normalization to obey the convolutional property – so that different elements of the same feature map, at different locations, are normalized in the same way. To achieve this, we jointly normalize all the activations in a mini-batch, over all locations.
...
so for a mini-batch of size m and feature maps of size p × q, we use the effective mini-batch of size m′
= |B| = m · pq. We learn a pair of parameters γ(k) and β(k) per feature map, rather than per activation.
—— Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
1個卷積核產生1個feature map,1個feature map有1對\(\gamma\)和\(\beta\)引數,同一batch同channel的feature map共享同一對\(\gamma\)和\(\beta\)引數,若卷積層有\(n\)個卷積核,則有\(n\)對\(\gamma\)和\(\beta\)引數,
沒有scale and shift程序可不可以?
BatchNorm有兩個程序,Standardization和scale and shift,前者是機器學習常用的資料預處理技術,在淺層模型中,只需對資料進行Standardization即可,Batch Normalization可不可以只有Standardization呢?
答案是可以,但網路的表達能力會下降,
直覺上理解,淺層模型中,只需要模型適應資料分布即可,對深度神經網路,每層的輸入分布和權重要相互協調,強制把分布限制在zero mean unit variance并不見得是最好的選擇,加入引數\(\gamma\)和\(\beta\),對輸入進行scale and shift,有利于分布與權重的相互協調,特別地,令\(\gamma=1, \beta = 0\)等價于只用Standardization,令\(\gamma=\sigma, \beta=\mu\)等價于沒有BN層,scale and shift涵蓋了這2種特殊情況,在訓練程序中決定什么樣的分布是適合的,所以使用scale and shift增強了網路的表達能力,
表達能力更強,在實踐中性能就會更好嗎?并不見得,就像曾經引數越多不見得性能越好一樣,在caffenet-benchmark-batchnorm中,作者實驗發現沒有scale and shift性能可能還更好一些,圖見下一小節,
BN層放在ReLU前面還是后面?
原paper建議將BN層放置在ReLU前,因為ReLU激活函式的輸出非負,不能近似為高斯分布,
The goal of Batch Normalization is to achieve a stable distribution of activation values throughout training, and in our experiments we apply it before the nonlinearity since that is where matching the first and second moments is more likely to result in a stable distribution.
—— Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
但是,在caffenet-benchmark-batchnorm中,作者基于caffenet在ImageNet2012上做了如下對比實驗,
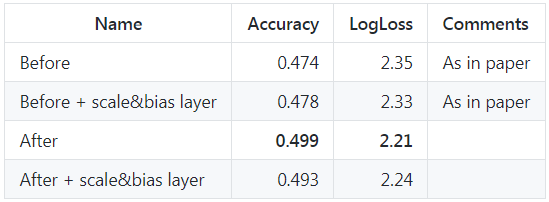
實驗表明,放在前后的差異似乎不大,甚至放在ReLU后還好一些,
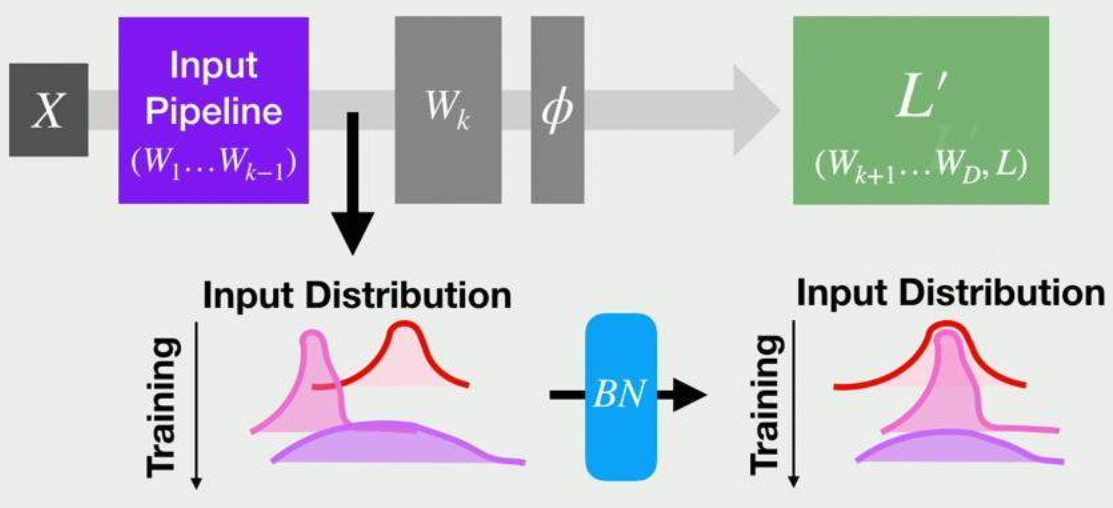
放在ReLU后相當于直接對每層的輸入進行歸一化,如下圖所示,這與淺層模型的Standardization是一致的,
caffenet-benchmark-batchnorm中,還有BN層與不同激活函式、不同初始化方法、dropout等排列組合的對比實驗,可以看看,
所以,BN究竟應該放在激活的前面還是后面?以及,BN與其他變數,如激活函式、初始化方法、dropout等,如何組合才是最優?可能只有直覺和經驗性的指導意見,具體問題的具體答案可能還是得實驗說了算(微笑),
BN層為什么有效?
BN層的有效性已有目共睹,但為什么有效可能還需要進一步研究,這里有一些解釋,
-
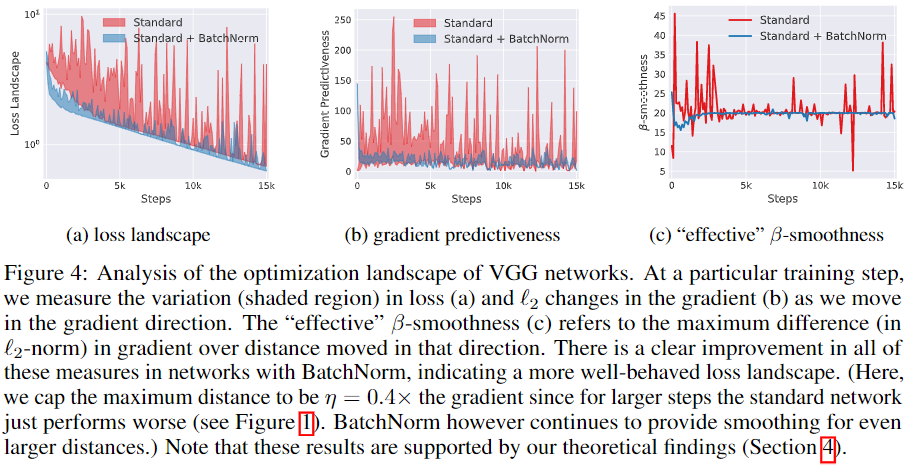
BN層讓損失函式更平滑,論文How Does Batch Normalization Help Optimization中,通過分析訓練程序中每步梯度方向上步長變化引起的損失變化范圍、梯度幅值的變化范圍、光滑度的變化,認為添加BN層后,損失函式的landscape(loss surface)變得更平滑,相比高低不平上下起伏的loss surface,平滑loss surface的梯度預測性更好,可以選取較大的步長,如下圖所示,
-
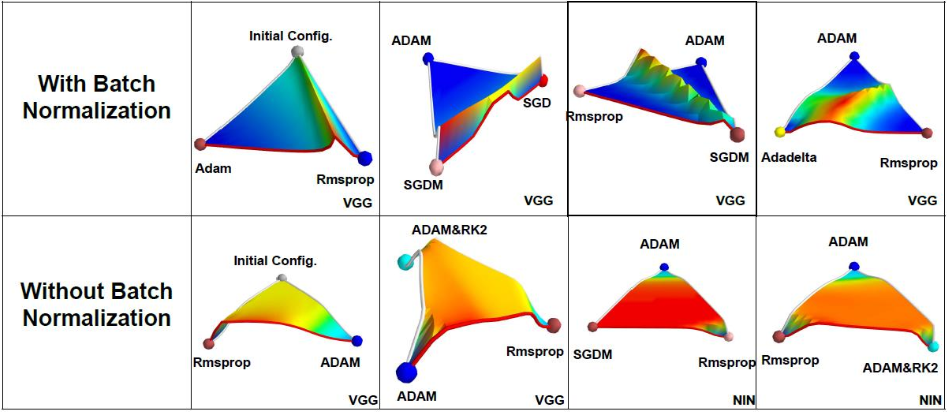
BN更有利于梯度下降,論文An empirical analysis of the optimization of deep network loss surfaces中,繪制了VGG和NIN網路在有無BN層的情況下,loss surface的差異,包含初始點位置以及不同優化演算法最終收斂到的local minima位置,如下圖所示,沒有BN層的,其loss surface存在較大的高原,有BN層的則沒有高原,而是山峰,因此更容易下降,
-
這里再提供一個直覺上的理解,沒有BN層的情況下,網路沒辦法直接控制每層輸入的分布,其分布前面層的權重共同決定,或者說分布的均值和方差“隱藏”在前面層的每個權重中,網路若想調整其分布,需要通過復雜的反向傳播程序調整前面的每個權重實作,BN層的存在相當于將分布的均值和方差從權重中剝離了出來,只需調整\(\gamma\)和\(\beta\)兩個引數就可以直接調整分布,讓分布和權重的配合變得更加容易,
這里多說一句,論文How Does Batch Normalization Help Optimization中對比了標準VGG以及加了BN層的VGG每層分布隨訓練程序的變化,發現兩者并無明顯差異,認為BatchNorm并沒有改善 Internal Covariate Shift,但這里有個問題是,兩者的訓練都可以收斂,對于不能收斂或者訓練程序十分震蕩的模型呢,其分布變化是怎樣的?我也不知道,沒做過實驗(微笑),
以上,
參考
- arxiv-Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- arxiv-How Does Batch Normalization Help Optimization?
- arxiv-An empirical analysis of the optimization of deep network loss surfaces
- talk-How does Batch Normalization Help Optimization?
- How does Batch Normalization Help Optimization?
- Understanding the backward pass through Batch Normalization Layer
- Batch Normalization — What the hey?
- Why Does Batch Normalization Work?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/187965.html
標籤:其他