{% note info %}
論文線上閱讀
{% endnote %}
Questions
| heuristic | fundamental |
|---|---|
| 資料少,指的是樣本少; 資料的質量低,我覺得并不是資料不可信,而是資料的特征空間小,包含的資訊少,建模后并不能得到有效的結論, 早期有一種觀點是直接在這種資料少且質量低的情況下訓練模型,并致力于提高該模型的精確度,我覺得這不可行,至少使用機器學習的方法不能做到,機器學習研究的是統計問題,歸根到底是數學方法,它并不關心資料特征的具體含義,而敏感于資料的分布,我們借助機器學習,最終得到的是期望/可能性,是關于概率的,因此自然是樣本越多越好,精確度就越高了, 資料的持有者結成聯盟共同訓練模型,是另一種觀點,我覺得聯邦學習走在正確的路上, |
1. 如何清洗資料? |
| 理想的方法是直接將所有參與方的資料聚集在一起,不顧慮法律、技術和成本的約束, 而即使這樣,因為不同機構所持有的資料或多或少都是異構的,在聚集時就必須將資料對齊,這也意味著非交集資料的損失, 既然如此,為何不先完成對齊,再將資料聚合呢?并且加密需聚合的資料,這一方面,于最終訓練效果而言,并沒有太大影響;另一方面,又滿足了公眾對資料隱私的訴求, |
2. 什么是資料中毒(data poisoning)? |
| 水平聯邦學習增大了樣本空間,能夠提高模型的精確度; 垂直聯邦學期拓寬了特征空間,使得分析結果能夠涵蓋更多領域,產生1+1>2的效果 |
|
| 聯邦遷移學習到底是什么? | |
| 聯邦學習中,參與者越多越好嗎? |
Abstract
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| strengthening | n. 加強 | propose | vt. 提出,建議 |
| beyond | prep. 晚于,遲于 | secure federated learning | 安全聯邦學習 |
| federated transfer learing | 聯邦遷移學習 | mechanism | n. 機制,原理 |
| compromise | vt. 泄漏,使陷入危險,妥協 | CCS | abbr. Council of Communication Societies 通信學會理事會 |
| methodology | n. 方法論 | phrase | n. 短語 |
| GDPR | General Data Protection Regulation 通用資料保護協議 |
{% endhideToggle %}
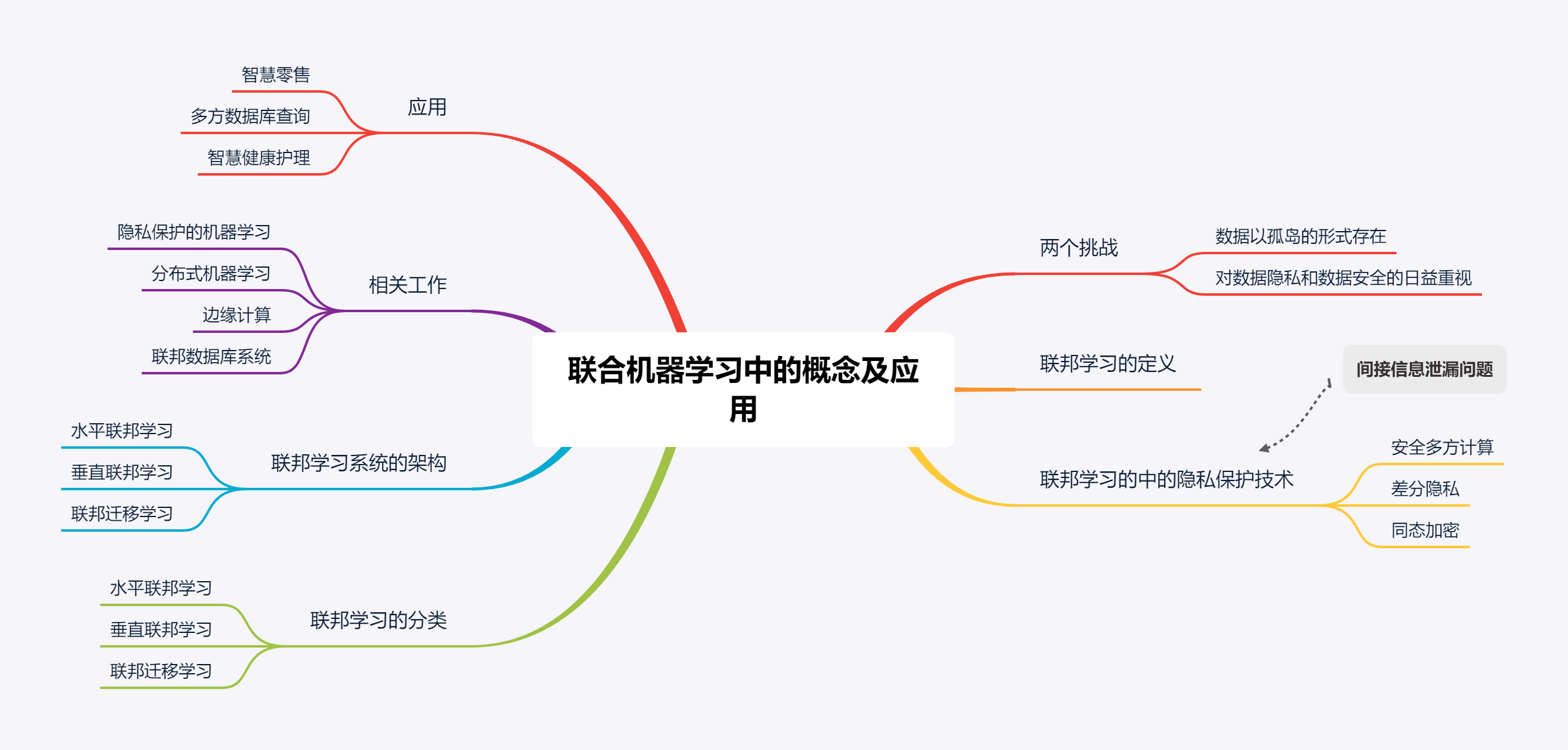
目前AI領域面臨著兩個重要的挑戰:
- 在大部分行業中,資料以孤島的形式存在
- 加強資料隱私和安全
安全聯邦學習(secure federated learning)中包含的三個方面:
- 水平聯邦學習(horizontal federated learning)
- 垂直聯邦學習(vertical federated learning)
- 聯邦遷移學習(federated transfer learning)
論文介紹了聯邦學習框架中的一些定義、架構和應用,并全面調查了聯邦學習方面已有的作業,此外,論文中還提出了如何在不同的組織之間基于聯邦機制來構建資料網路,作為一個解決方案使得能在不泄漏用戶隱私的情況下分享知識(knowledge),
Introduction
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| Go | n. 圍棋 | defeat | vt. 擊敗 |
| cutting-edge | adj. 最新的,先進的 | medical care | 醫療護理 |
| walks of life | 各行各業 | inevitable | adj. 不可避免的 |
| availability | n. 可獲得性 | permission | n. 許可 |
| hard copy | 復印件 | grant | vt. 授予 |
| commercial | adj. 商業的,營利的 | citation | n. 參考 |
| fuse | vt. 融合 | if not impossible | 如果有可能的話 |
| recommendation | n. 推薦 | complicated administrative procedure | 復雜的管理程式 |
| integration | n. 集成 | resistance | n. 阻力,反抗 |
| institution | n. 公共機構 | issue | n. 問題 |
| cause great concern | 引起巨大的影響 | data breach | 資料外泄 |
| protest | n. 抗議,反抗 | enforce | vt. 實施 |
| protect | vt. 保護,防衛 | plain | adj. 簡單的 |
| stiff fine | 硬性罰款,嚴厲處罰 | violate | vt. 違反 |
| bill | n. 法案 | act | n. 法令 |
| enact | vt. 頒布 | Cyber Security Law | 網路安全法 |
| General Principles of Civil Law | 民法通則 | tamper | vi. 做手腳,破壞 |
| tamper with | 篡改 | conduct | vt. 實施,進行 |
| obligation | n. 義務,責任 | pose | vt. 造成,形成 |
| dilemma | n. 困境,進退兩難 | data fragmentation | 資料碎片 |
| to be more specific | 具體而言,準確來說 | be responsible for | 對...負責 |
| promote | vt. 促進 | complaint | adj. 服從的,順從的 |
{% endhideToggle %}
由于市場資金的注入和大資料的支持,AI自2016年便迎來了空前的繁榮,
在大部分領域,資料有限或者資料的質量低,這使得AI技術的實作超乎想象的困難,一種可能的方法就是將不同機構的資料運輸到同一個地方融合在一起,但是由于行業競爭、隱私安全和復雜管理程式方面的原因,即使是同一公司內不同部門之間的資料集成也會遇到很大的阻力,

facebook 的隱私外泄引起了廣泛的抗議,世界各國開始加強資料安全和隱私方面的法律法規,這也給如今在AI領域普遍使用的資料事務程式帶來了新的挑戰,

GDPR:
- 禁止自主的建模和決定
- 解釋模型的決定
- 授予用戶遺忘資料的能力,允許用戶洗掉或者撤銷其個人資料
- 在設計層上就考慮資料隱私
- 使用清晰簡單的語言說明資料使用的用戶許可授權
AI 領域中傳統的資料處理(data processing)模型涉及了一些簡單的資料事務(data transactions)模型,其中一方收集和傳輸資料到負責清洗并融合資料的另一方,最終一個第三方會得到集成好的資料并構建其他方也可以使用的模型,構建好的模型通常也是最終的產品,作為一項服務銷售,傳統的處理程式面對著來自新法規的挑戰,而用戶也可能因不清楚模型在未來的使用從而觸犯法律,因此,我們處在這樣一個困境中:資料處于一種孤島的形式,而我們在很多情境中被禁止去收集、融合來自不同地點的資料用以AI處理,
為了促進聯邦學習的發展,論文作者希望能將AI發展的焦點從提高模型的表現切換到探索符合資料隱私安全法的資料集成方法上,前者是當前大部分AI領域都在做的事情,
An Overview of Federated Learning
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| effort | n. 努力 | personalizable | adj. 個性化的 |
| optimization | n. 最佳化 | massive | adj. 大量的 |
| partition | vt. 分割,區分 | decentralized | adj. 分散管理的 |
| preliminary | adj. 初步的,開始的 | foundation | n. 基金會 |
| multiagent theory | 可替換主體理論 | data mining | 資料挖掘 |
| workflow | n. 作業流程 | consolidate | vt. 聯合,鞏固 |
| respective | adj. 各自的,分別的 | conventional | adj. 常見的,慣例的 |
| guarantee | n. 保證 | identify | vt. 鑒別,識別 |
| simulation | n. 模擬,仿真 | proof | n. 驗證 |
| complete | adj. 完全的,徹底的 | desirable | adj. 可取的,令人向往的 |
| partial | adj. 區域的 | disclosure | adj. 披露 |
| semi-honest | adj. 半誠實的 | verification | n. 核查,驗證 |
| reveal | vt. 顯示,泄漏 | collude | vi. 勾結,串通 |
| well-defined | adj. 定義明確的,界限清楚的 | desire | vt. 要求 |
| line of work | 行業 | anonymity | n. 匿名性,匿名者 |
| diversification | n. 多樣化,分化 | obscure | vt. 使...模糊不清,隱藏 |
| restore | vt. 恢復,重建 | approach to | 約等于,通往...的方法 |
| transmit | vt. 傳輸,傳播 | homomorphic encryption | 同態加密 |
| adopt | vt. 采用,采納 | additively | adv. 附加地,疊加地 |
| polynomial approximation | 多項式逼近 | intermediate | adj. 中間的,過渡的 |
| constrain | vt. 驅使 n. 約束 |
scale | n. 規模 |
| poisoning | n. 中毒 | loophole | n. 漏洞 |
| variant | n. 變體,轉變 | constant fraction | 恒比 |
| blockchain | n. 區塊鏈 | facilitate | vt. 促進,幫助 |
| leverage | vt. 利用 | scalability | n. 可拓展性 |
| robustness | n. 健壯性 | categorize | vt. 分類 |
| identical | adj. 完全相同的 | regional | adj. 地區的,區域的 |
| scheme | n. 計劃,方案,模式 | intersection | n. 交集 |
| address | vt. 設法解決 | straggler | n. 掉隊者 |
| partition | vt. 分割,區分 | compression | n. 壓縮 |
| bandwidth | n. 帶寬 | preserving | n. 保護,保存 |
| regression | n. 回歸 | linear | adj. 線性的 |
| entity | n. 物體 | applicable | adj. 可應用的,合適的 |
| commerce | n. 貿易,商務 | revenue | n. 收益 |
| expenditure | n. 支出,花費 | retain | vt. 保持,記住 |
| corrupted | adj. 毀壞的 | geographical | adj. 地理的 |
| restriction | n. 限制 | portion | n. 部分 |
| exceeding | vt. 超越 | decrypt | vt. 解碼 |
| converge | vi. 聚集,收斂 | subject | adj. 容易遭受...的 |
| Generative Adervasarial Network | GAN 生成對抗性網路 | entity | n. 物體 |
| alignment | n. 對齊 | lossless | adj. 無損的 |
| gather | vt. 收集 | scale | vi. 改變大小 |
| parallel | adj. 平行的 | randomness | n. 隨機性 |
| secrecy | n. 機密性 | inability | n. 無能力 |
| terminate | vt. 使結束 | oblivious | adj. 遺忘的 |
| overall | adj. 全部的 | commercialize | vt. 商業化 |
| incentive | n. 激勵,動機 | manifest | vt. 表明,證明 |
| permanent | adj. 永久的,永恒的 | better off | 達到某數量的,富裕的,漸入佳境 |
| consensus | n. 一致 |
{% endhideToggle %}
聯邦學習中最優化問題的幾個重要因素:
- 在大量分布地間進行交流的成本
- 資料分布的不平衡
- 設備的可靠性
Definition of Federated Learning
假定有 \(N\) 個資料擁有者 \(\{ \mathcal{F}_1,\cdots,\mathcal{F}_N \}\) 希望通過聯合他們各自的資料 \(\{ \mathcal{D}_1,\cdots,\mathcal{D}_N \}\) 來訓練一個機器學習的模型,一種常見的方法就是把資料放在一起,即有 \(\mathcal{D}=\mathcal{D}_1\cup\cdots\mathcal{D}_N\),由此訓練模型 \(\mathcal{M}_{SUM}\)
聯邦學習系統就是一個資料擁有者們合作性地訓練模型 \(\mathcal{M}_{FED}\) 的學習程序,在這個程序中任意資料擁有者 \(\mathcal{F}_i\) 都不會將其資料 \(\mathcal{D}_i\) 暴露給其他的資料持有者
用 \(\mathcal{V}_{FED}\) 表示模型 \(\mathcal{M}_{FED}\) 的精確度,\(\mathcal{V}_{FED}\) 必須十分接近 \(\mathcal{V}_{SUM}\) (\(\mathcal{M}_{SUM}\) 的性能)
令 \(\delta > 0\),若
\[\vert \mathcal{V}_{FED}-\mathcal{V}_{SUM} \vert < \delta \tag{1} \]則稱這個聯邦學習演算法有 \(\delta\) 精確度損失
Privacy of Federated Learning
隱私是聯邦學習中的一個重要屬性,其需要安全模型和分析以提供有意義的隱私保證,論文介紹了聯邦學習中一些隱私技術,識別方法以及間接隱私泄漏的預防中的潛在挑戰,
-
安全多方計算(Secure Multi-party Computation, SMC):
SMC安全模型自然而然地包含了多個參與方,并且提供了安全驗證在定義明確的模擬框架中用以保證 complete zero knowledge,也就是每個參與方只能知道自身的輸入和輸出,zero knowledge 很讓人向往,但其通常需要復雜的計算協議,且也許不能有效的將之實作,而在低安全需求的情境中,可以構建一個基于SMC的安全模型以追求效率,
已進行的研究:
- MPC protocols:用以模型的訓練和驗證,且不會泄漏敏感資料
- Sharemind:最先進的SMC框架之一
- 3PC model:在半誠實和惡意的假設(malicious assumptions)中,考慮安全性
-
差分隱私(Differential Privacy):
在差分隱私(Differential Privacy)、k-匿名(k-Anonymity)和分化(diversification)的方法中,都向資料中添加了噪聲,或者使用泛化方法(generalization methods)來隱藏一些敏感屬性讓第三方不能區分出個體之間的區別,由此使得資料不可能被重建,從而保護了用戶的隱私,然而這些方法的根本仍然是將資料傳輸到其他地方,且這些方法也需要在精確度和隱私之間權衡,
-
同態加密(Homomorphic Encryption):
(不同于差別隱私的保護方法)在同態加密中,資料和模型本身不會被運輸,也不能通過其他參與方的資料來猜中它們,因此,在原始資料的層次上幾乎不可能發生泄漏,
在實踐中,疊加同態加密(Additively Homomorphic Encryption)被廣泛的使用,而多項式逼近(polynomial approximations)也被用于評估機器學習演算法中的非線性函式,這都將導致需要在精確度和隱私之間權衡,
-
間接資訊泄漏(indirect information leakage):
聯邦學習中的一些前驅作業會暴露中間結果,比如從優化演算法(如SGD演算法)中上傳引數時,由于未提供安全保證,梯度泄漏加上資料結構的暴露也許會導致重要的資料資訊外泄,
聯邦學習系統中的成員可以惡意地攻擊其他參與者,通過植入后門來學習他們的資料,
研究者們也開始考慮引入區塊鏈(blockchain)作為平臺來促進聯邦學習,Hysung Kim 等人提出了一個基于區塊鏈的聯邦學習架構(BlockFL),通過利用區塊鏈來交換并驗證移動設備之間本地學習模型的更新,他們也考慮了 an optimal block generation、網路的可拓展性及健壯性的問題,
A Categorization of Federated Learning
我們可以資料的分布特征為標準,來給聯邦學習分類,
用矩陣 \(\mathcal{D}_i\) 表示資料擁有者 \(i\) 所持有的資料,矩陣的每一行都代表一個樣本,每一列都代表一種特征,
同時,一些資料集可能還包含了標簽(label)欄位,我們用 \(\mathcal{X}\) 表示特征空間,\(\mathcal{Y}\) 表示標簽空間,\(\mathcal{I}\) 表示樣本ID空間,這三者組成了完整的訓練資料集 \((\mathcal{I},\mathcal{X},\mathcal{Y})\),
參與方們的資料的特征空間和樣本空間也許不是完全相同的,所以我們可以基于資料在不同參與方(parties)的特征空間和樣本 ID 空間上的分布情況,將聯邦學習分為水平聯邦學習(horizontal federated learing)、垂直聯邦學習(vertical federated learning)和聯邦遷移學習(federated transfer learning),
-
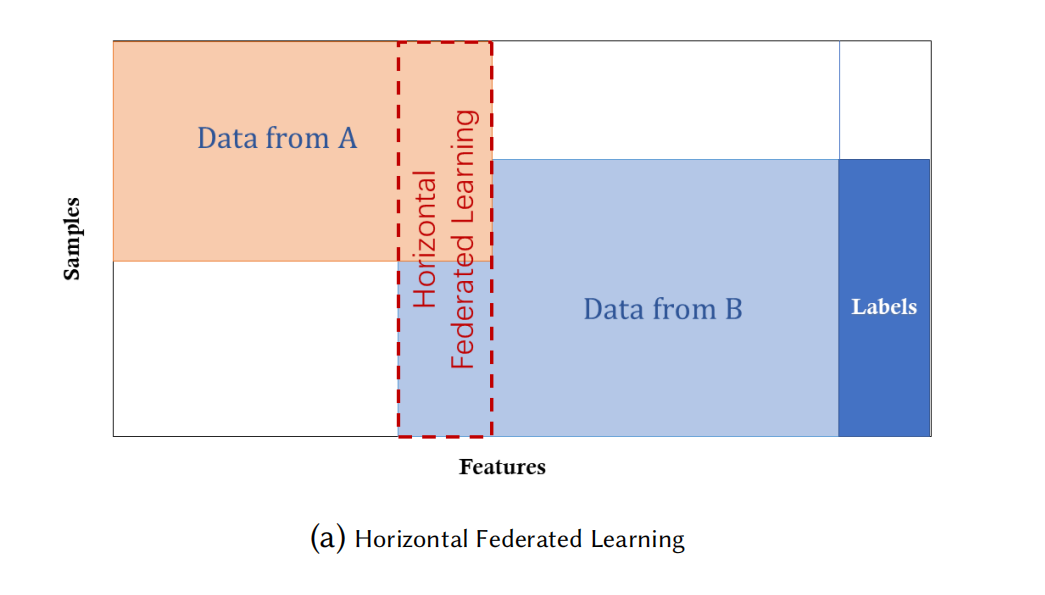
水平聯邦學習(horizontal federated learning):
也就是基于樣本的聯邦學習(sample-based federated learning),在這種聯邦學習中,資料集共享了相同的特征但是各自的樣本不同,可以描述為:
\[\mathcal{X}_i=\mathcal{X}_j,\quad\mathcal{Y}_i=\mathcal{Y}_j,\quad\mathcal{I}_i\neq\mathcal{I}_j,\quad\forall\mathcal{D}_i,\mathcal{D}_j,i\neq j \tag{2} \]比如兩個不同地區的銀行,它們的用戶來自各自的地區,樣本空間的交集很小,但是它們的業務是非常相近的,所以特征空間相同,
安全定義(security definition):一個典型的聯邦學習系統假定參與者是誠實的,而服務器是 honest-but-curious,也就是說只有服務器才有可能會泄漏參與者的隱私,但是參與者也可能不懷好意,這帶來了額外的隱私挑戰,
-
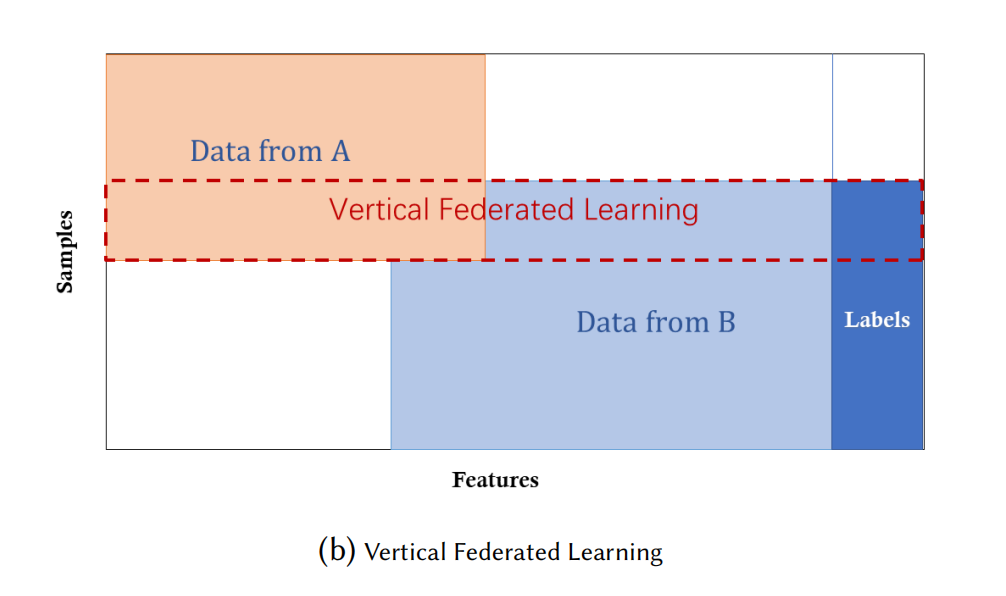
垂直聯邦學習(vertical federated learning):
也叫做基于特征的聯邦學學習(feature-based federated learning),適用于兩個資料集共享了相同的樣本 ID 空間但特征空間不同的情景,
比如,同一個城市中的一家銀行以及一家電子商務公司,它們的用戶群體就是這個地區中的大部分居民,所以他們的樣本空間有很大的交集,但是,銀行記錄的是用戶的收入、支出以及信用等級,而電子商務公司保存的是用戶的瀏覽和購物的歷史資訊,它們的特征空間非常不同,
垂直聯邦學習是一個聚集(aggregate)不同特征并計算訓練損失和梯度的程序,以隱私保護的方式來構建模型,資料來自所有的合作參與方,在這種聯邦機制下,所有參與方的身份和地位都相同,并且該聯邦系統會幫助所有人建立一個 common wealth 的策略,這就是其被稱為聯邦學習(federated learning)的原因,
\[\mathcal{X}_i\neq\mathcal{X}_j,\quad\mathcal{Y}_i\neq\mathcal{Y}_j,\quad\mathcal{I}_i=\mathcal{I}_j,\quad\forall\mathcal{D}_i,\mathcal{D}_j,i\neq j \tag{3} \]安全定義(security definition):一個典型的垂直聯邦學習系統假定了存在 honest-but-curious 的參與方,比如在一個只有兩個參與方的情境中,雙方沒有相互串通且最多只有一方被對手攻擊而發生資訊泄漏,那么安全就可以定義為,對手只能學習到被毀壞的客戶端的資料,并不能得到其他未發生泄漏的客戶端的資料,為了促進雙方之間的安全計算,可以引入一個半誠實的第三方(Semi-honest Third Party, STP),且假定其不與其他參與方串通,學習結束后,每個參與方只能持有與自身特征關聯的模型引數,因此在推理時,雙方需要一起合作來生成輸出,
-
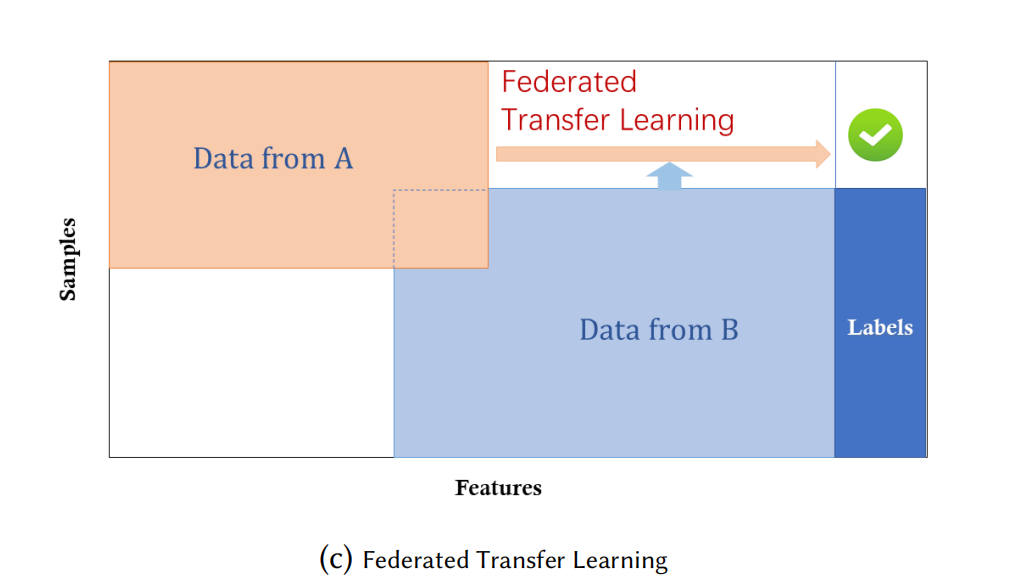
聯邦遷移學習(federated transfer learning):
聯邦遷移學習應用于這樣的場景中:兩個資料集在其樣本空間和特征空間上均不相同,
假設有兩個機構,一個是位于中國的銀行,另一個是位于美國的電子商務公司,由于地理上的限制,這兩個機構的用戶群體只有很小的交集,另一方面,由于兩者業務的不同,特征空間也只有很小部分的重疊,
\[\mathcal{X}_i\neq\mathcal{X}_j,\quad\mathcal{Y}_i\neq\mathcal{Y}_j,\quad\mathcal{I}_i\neq\mathcal{I}_j\quad\forall\mathcal{D}_i,\mathcal{D}_j,i\neq j \tag{4} \]安全定義:一個典型的聯邦遷移學習系統包含了兩個參與方,其安全定義與垂直聯邦學習系統相同,
Architecture for a federated learning system
水平聯邦學習系統的架構
在水平聯邦學習系統中,k 個參與者擁有相同的資料結構,通過引數服務器或者云服務器來共同學習一個機器學習模型,假設參與者都是誠實的,而服務器是 honest-but-curious,因此從任何參與方到服務器的泄漏是不被允許的,水平聯邦學習系統的訓練程序包含了以下4個程序:
- 參與者在本地計算訓練梯度,使用加密(encryption)/差分隱私(differential privacy)/密鑰共享(secret sharing)技術來掩飾(mask)精選出來的梯度(a selection of gradients),然后將masked結果上傳到服務器
- 服務器執行安全資料聚集(secure aggregation),且不需要學習任何參與方的資訊
- 服務器將聚合結果(aggregated results)返還給參與方
- 參與方們使用解碼后的梯度更新各自的模型
不斷的迭代這4個步驟直到損失函式收斂,整個訓練程序就完成了,
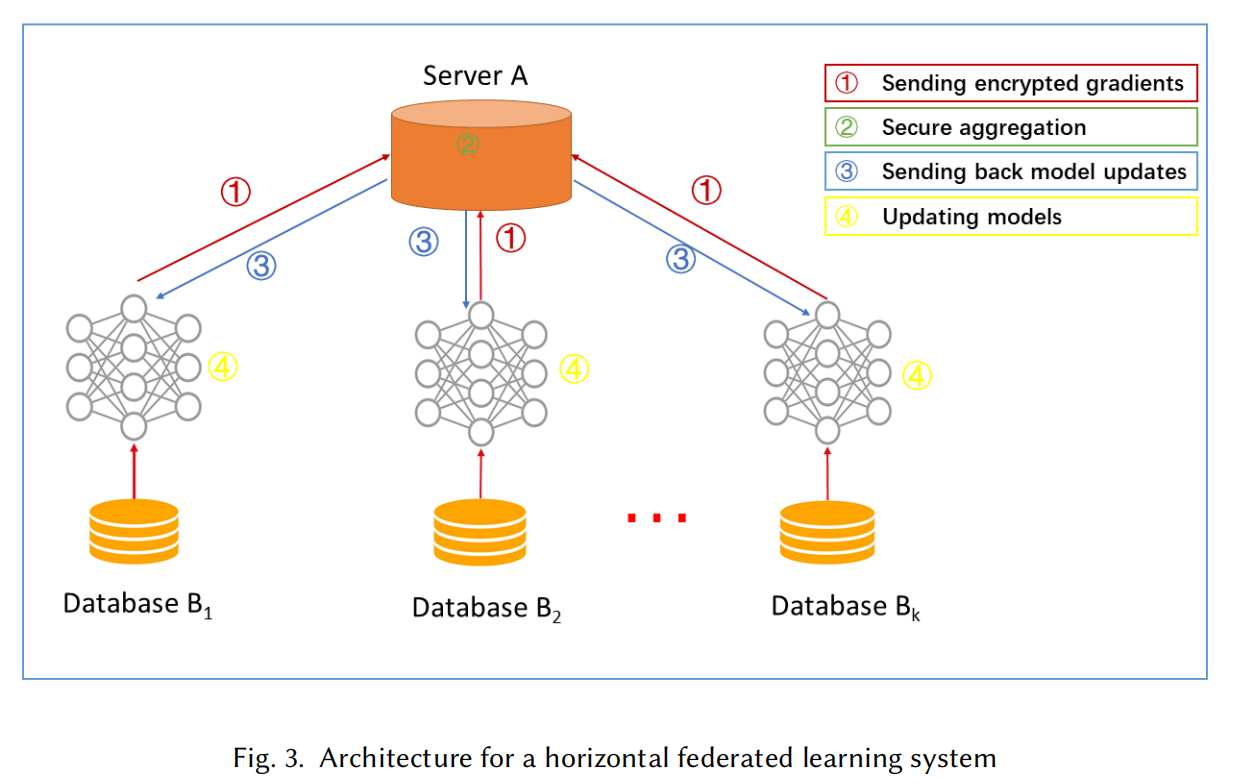
這個構架不依賴特殊的機器學習演算法(如 logistic regression 和 DNN 等),并且所有的參與方都能分享最終模型的引數,
安全分析:如果采用了 SMC 或者同態加密來聚集梯度,這種架構就可以用來預防半誠實(semi-honest)的服務器引起的資料泄露,但是在其他安全模式的聯合訓練程序中,水平聯邦學習系統的架構很容易遭到惡意參與方的攻擊,通過訓練一個生成對抗性網路(Generative Aderversarial Network, GAN)
垂直聯邦學習系統的架構
假設公司 A 和 B 共同訓練一個模型,它們的商務系統有各自的資料,此外,公司B持有模型需要預測的標簽,出于資料隱私和安全的考慮,A 和 B 之間不能直接交換資料,為了確保在訓練程序中資料的機密性,可以引入一個第三方合作者 C,假設 C 是誠實的,且不與 A 或 B 串通,而 A、B 之間相互是 honest-but-curious,這樣一個可信任的第三方 C 通常由權威機構來充當,比如政府,或者安全計算結點(如Intel Software Guard Extension, SGX),垂直聯邦學習系統通常由兩部分構成:
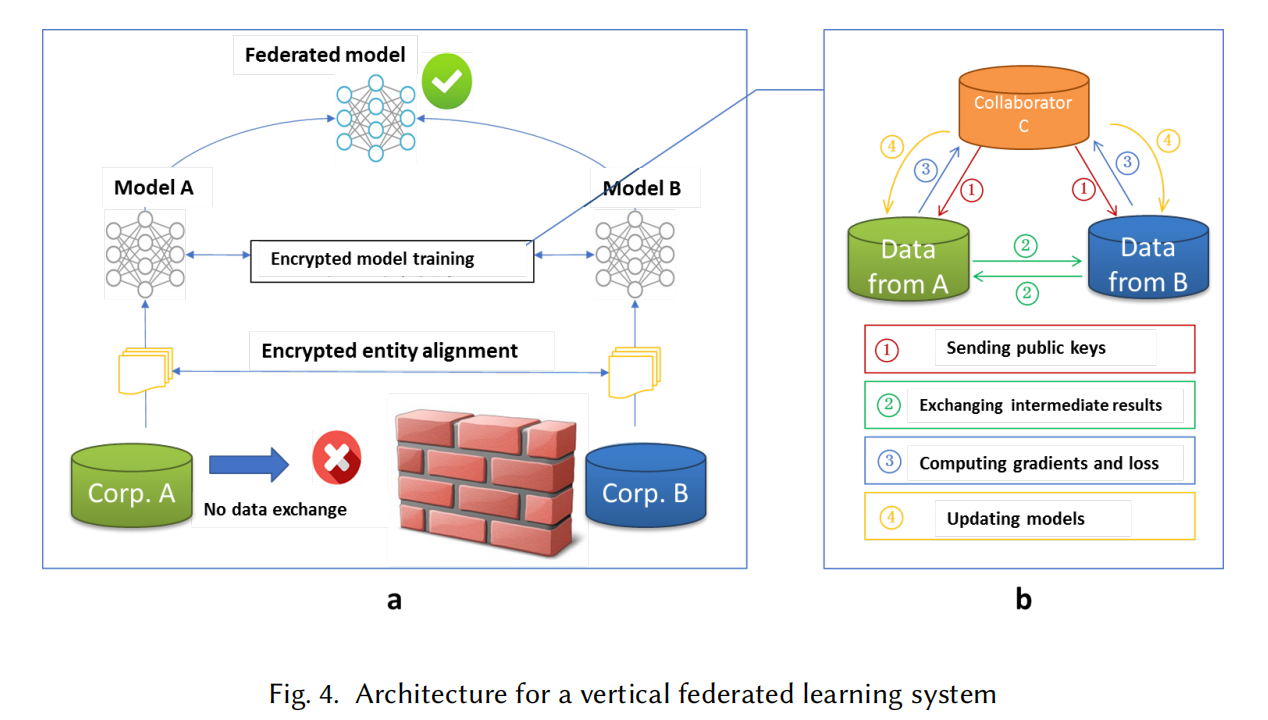
-
加密物體對齊(encrypted entity alignment),由于兩個公司的用戶群體并不相同,系統使用了基于加密的用戶 ID 對齊技術來確保雙方公共的用戶集合中不會暴露各自的資料,在物體對齊程序中,系統不會暴露各自除了重疊部分的用戶資料,
-
加密模型訓練(encrypted entity alignment),決定好公共物體后,我們就可以用這些物體的資料來訓練一個機器學習模型,訓練程序可以分為以下4步:
- 合作者 C 創造加密對(encryption pairs),把公鑰分發別發送給 A 和 B
- A 和 B 互相交換梯度和損失的中間計算結果
- A 和 B 分別計算加密后的梯度并添加額外的掩碼,且 B 也需要計算加密后的損失,然后 A 和 B 將它們加密后的值傳送給 C
- C 進行解碼且將解碼后的梯度和損失返還給 A 和 B,A 和 B 去除梯度上的屏蔽(unmask)并相應地更新模型引數
在物體對齊和模型訓練的程序中,A 和 B 的資料都被保存在本地,且資料參與訓練的交集部分也不會導致資料隱私泄漏,C 引起的資料泄露可能或不可能(may or may not)被認為是隱私泄露(privacy violation),在這個情境中為了進一步預防 C 學習來自 A 和 B 的資訊,A 和 B 會添加加密的隨機掩碼(encrypted random mask)來向 C 隱藏它們的資訊,因此,兩個參與方都到達了它們的目的:通過聯邦學習來聯合訓練一個公共模型,
因為在整個訓練程序中,每個參與方接收到的損失值和梯度,與在資料被收集在同一個地方且沒有隱私約束的情況下訓練模型而得到的損失值和梯度是一樣的,所以,這個模型是無損失的,其效率取決于交流的成本和加密資料計算的成本,
在每次迭代程序中,A 和 B 之間傳輸資料的規模取決于重疊樣本的多少,因此,可以采用分布式并行計算技術來進一步提高演算法的效率,
安全分析:訓練協議不會泄漏任何資訊給 C,因為 C 學習到的都是添加掩碼后的梯度,并且添加掩碼后的矩陣,其隨機性和安全性都得到了保證,在這樣的協議中,參與方 A 在每一步都能學習到自身的梯度,但這并不足夠讓其學習到 B 的任何資訊,因為標量積協議的安全性建立于這樣一個基本事實:不能從 n 個等式中求解出超過 n 個未知量,
聯邦遷移學習系統的架構
在上面垂直聯邦學習的例子中,A 和 B 只有很小的樣本交集,我們希望學習到參與方 A 所有資料集的標簽,垂直聯邦學習框架只操作了資料的重疊部分,為了將其覆寫范圍拓展到整個樣本空間,我們引入了遷移學習,這并沒有改變垂直聯邦學習整體的框架,但是參與方 A 和 B 之間交換中間計算結果的細節改變了,
遷移學習涉及了 A 和 B 的特征之間公共表示(common representation)的學習程序,以及利用原始域方(source-domain party)標簽來預測目標域方(target-domain party)標簽程序中的誤差最小化,因此,A 和 B 的梯度計算程序與在垂直聯邦學習中是不一樣的,在推理時,仍然需要每個參與方去計算其預測結果,
獎勵機制
為了將不同組織間的聯邦學習充分商業化,就需要去開發一個公平的平臺和激勵機制,模型建立后,其性能可以在具體的應用中表現,并且可以記錄在一個永久的資料記錄機制中(如區塊鏈),機構能更加寬裕的提供更多資料,而模型的效果取決于資料提供者對系統的貢獻,模型的效能惠及聯邦機制的各個參與者,這又繼續激勵更多的機構參與到資料聯合中,
這種架構的實作不止考慮了隱私保護和多機構間協作建模的效果,還顧及了如何獎勵貢獻了更多資料的機構以及如何通過共識機制(consensus mechanism)來執行獎勵措施,因此,聯邦學習是一種倍訓的學習機制,
Related Work
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| originality | n. 創意 | devote | vt. 致力于 |
| garbled | adj. 篡改的,混亂的 | follow-up | 后續的 |
| allocate | vt. 分配 | autonomy | n. 自治 |
| cope | vi. 處理,對付 | stringent | adj. 嚴格的,緊縮的 |
| regulatory | adj. 管理的,控制的 | IID | Independent Identically Distributed,獨立相似分布 |
| coordination | n. 協調性 | convergence bound | 收斂約束 |
| manage | vt. 管理,控制 | interoperability | n. 互操作性 |
| heterogeneous | adj. 多種多樣的,參差的 | premise | n. 前提,假定 |
{% endhideToggle %}
聯邦學習使得多個參與方能協作構建一個機器學習模型,且其私人訓練資料仍然保持私密性,作為一門新興的技術,聯邦學習有幾條有創意的路線,其中一些根植于已存在的領域,
Privacy-preserving machine learning
聯邦機器學習可以看作是保護隱私的分散協作機器學習(privacy-preserving decentralized collaborative machine learning),與多方保密的機器學習(multi-party privacy mechine learning)密切相關,
Federated Learning vs Distributed Machine Learning
第一眼看上去,水平聯邦學習很像分布式機器學習(distributed machine learning),分布式機器學習包含了很多方面:訓練資料的分布存盤、計算任務的分布式操作以及模型結果的分布式分布(distributed distribution of model results),
引數服務器(parameter server)是一個分布式機器學習中的典型元素,可用來加速訓練程序,引數服務器存盤了分布式作業結點上的資料,并且通過中心調度結點來分配資料和計算資源,這提高了訓練的效率,
在水平聯邦學習中,作業結點就是資料持有者,其對本地資料擁有完全的自治權,可以決定何時以及如何加入聯邦學習,而在其引數服務器中,中心結點始終保有控制權,所以,聯邦學習面對著更加復雜的學習環境,此外,聯邦學習強調在訓練程序中保護資料持有者的資料隱私,有效的隱私保護方法可以在未來更好的處理日益嚴格的隱私保護和資料安全管理環境,
如同在分布式機器學習中,聯邦學習也需要去定位非獨立相似分布的資料(address Non-IID data),
Federated Learning vs Edge Computing
聯邦學習提供了關于協調性和安全性的學習協議,所以也可以看作是邊緣計算的作業系統,
Federated Learning vs Federated Database Systems
聯邦資料庫系統將多個資料庫單元集成起來,并且將集成系統作為一個整體來管理,聯邦資料庫的概念被提出來用以實作多個相互獨立的資料庫之間的互操作性(interoperability),其資料庫單元使用分布式存盤,而每個單元中對資料的操作是多樣的(heterogeneous),因此,聯邦資料庫系統與聯邦學習在資料的型別和存盤上有很多相似的地方,
但是聯邦資料庫系統在集成資料庫的程序中沒有涉及任何隱私保護機制,所有的資料庫單元對于管理系統來說都是完全可見的,也就是說,聯邦資料庫系統致力于資料的基本操作(如插入、洗掉、搜索和合并等),而聯邦學習是在保護資料隱私的前提下創建一個聯合模型,因此資料包含的各種價值和規律為我們提供了更好的服務,
Applications
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| innovative | adj. 創新的 | intellectual property rights | 知識產權 |
| personalized | adj. 個性化的 | personal preference | 個人喜好 |
| characteristic | n. 特征 | hinder | vt. 阻礙,打擾 |
| heterogeneity | n. 異質性 | mutual | adj. 共同的 |
| limitation | n. 限制,極限 | ecosphere | n. 生態圈 |
| borrowing | n. 借貸 | loan | n. 貸款 |
| collapse | v. 崩潰 | symptom | n. 臨床癥狀 |
| envisage | vt. 設想,想象 | vision | n. 想象,美景 |
| pivotal | adj. 關鍵的 |
{% endhideToggle %}
聯邦學習是一種創新的建模機制,能基于來自不同參與方的資料上訓練聯合模型,且不泄漏這些資料的隱私和安全,在銷售、金融以及其他(出于知識產權、隱私保護和資料安全的原因,資料不能直接聚集起來用以訓練機器學習模型的)行業上很有前途,
聯邦學學習可用于智慧零售(smart retail),智慧零售的目的是使用機器學習技術來給消費者提供個性化服務,主要包括商品推薦和銷售服務,其業務的資料特征主要有:
- 用戶購買力——可從銀行存款上推測得出
- 用戶個人喜好——從用戶的社交網中分析得到
- 商品特性——通常在網店中留有記錄
這些資料通常存盤在三個不同的部門或者企業中,
這樣的話,我們就面臨了兩個問題:
- 出于對資料隱私和安全的保護,很難去打破銀行、社交網站和網購站點之間的資料壁壘,因此資料不能直接聚合起來以訓練模型,
- 存盤在三個地方的資料通常都是參差不齊的,而傳統的機器學習不能直接處理這種異構資料(heterogeneous data),
而使用聯邦學習和遷移學習時,這些問題迎刃而解,
- 利用聯邦學習,我們可以在不暴露企業資料的前提下,就建立好機器學習模型,這不僅完全保護了資料隱私和資料安全,而且給用戶提供了個性化服務和針對性服務,并且由此實作了諸多好處,
- 同時,我們可以利用遷移學習來定位資料異質性問題(data heterogeneity problems),并且打破傳統人工智能技術的局限性,
因此,聯邦學習為我們提供了很好的技術支持,讓我們能為大資料和人工智能構建跨企業、跨資料、跨領域的生態圈,
聯邦學習框架可用于不暴露資料的多方資料庫查詢(multi-party database querying without exposing the data),在金融的應用中,我們對探測多方借貸(detecting multi-party borrowing)很感興趣,這通常是銀行行業的一個主要風險因素,往往發生在有某些惡意用戶從一個銀行中借錢來支付另一家銀行的貸款時,多方借貸對金融穩定來說是一個威脅,大量的這種非法行為可能會導致整個金融系統崩潰,
銀行 A 和銀行 B 為了找到這種用戶且不將自身的用戶名單泄漏給對方,可以利用聯邦學習框架,特別是,我們可以采用加密機制來加密每個參與方的用戶名單,并且把加密名單的交集加入聯邦中,最終結果的譯碼給出了多方借貸者的名單,而且這并不會將參與方自身的“好”用戶暴露給其他參與方,我們可以看到,這種操作與垂直聯邦學習有關,
聯邦學習還可以用于智慧健康護理(smart healthcare),
Federated Learning and Data Alliance of Enterprises
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| alliance | n. 聯盟 | paradigm | n. 范例 |
| equitable | adj. 公平的,公正的 | regardless of | 不管,不顧 |
| carry out | 實作 |
{% endhideToggle %}
借助區塊鏈技術中的共識機制(consensus mechanism),聯邦學習形成了公平分配利益的規則(profits allocation),
Conclusions and Prospects
{% hideToggle 詞匯 %}
| 詞匯 | 解釋 | 詞匯 | 解釋 |
|---|---|---|---|
| bonus | n. 紅利 |
{% endhideToggle %}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/189510.html
標籤:其他
上一篇:API即服務
下一篇:TF2目標檢測API