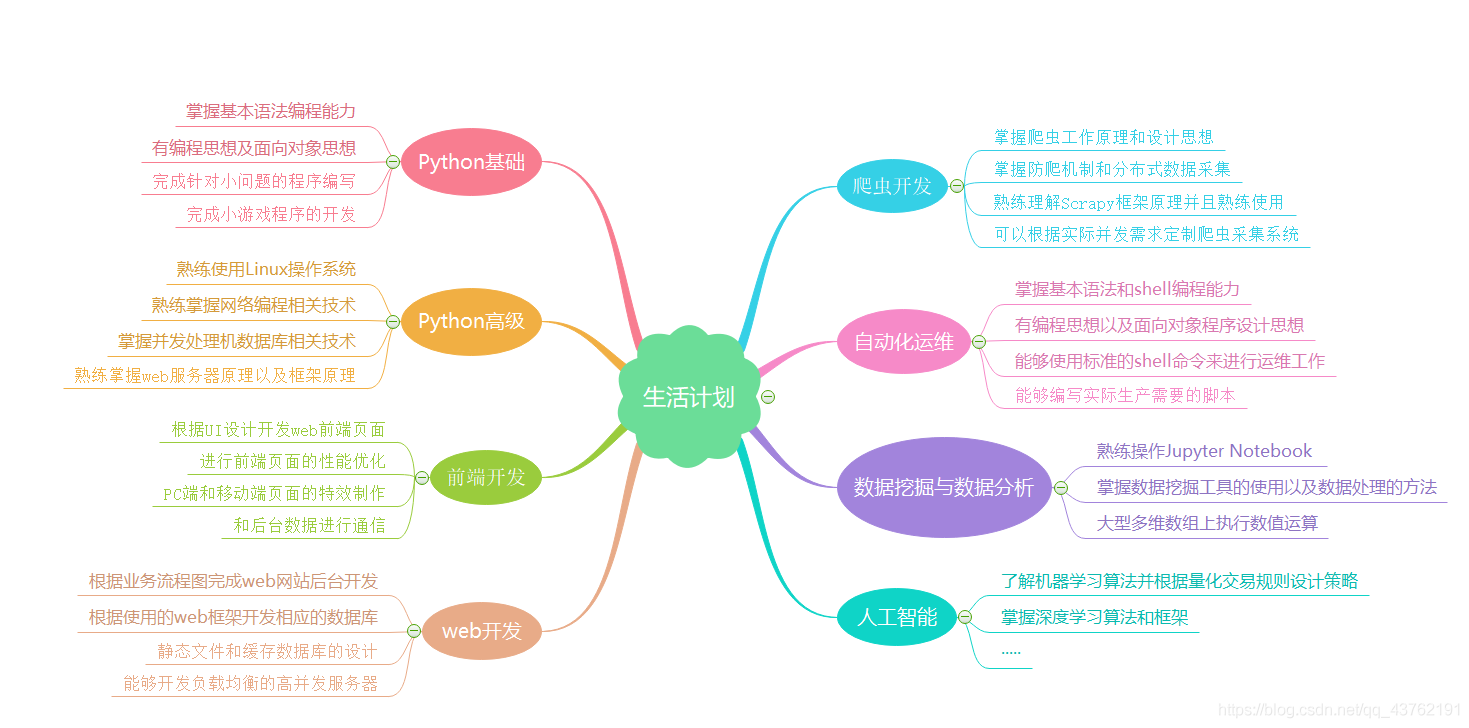
標題無意冒犯,就是覺得這個廣告挺好玩的
上面這張思維導圖喜歡就拿走,反正我也學不了這么多
文章目錄
- 前言
- 什么是模塊?
- 跟我一起動手匯入自己的模塊
- 第一步:新建一個模塊
- 第二步:呼叫模塊
- 呼叫模塊不同方法,
- `if __name__ == '__main__'`
- csv模塊操作Excel圖表
- 我要用什么模塊?
- 這個模塊里有哪些東西?
- 使用csv模塊
- 讀
- 寫
- 我畫了個圈,歡迎大家來我們的小圈子
前言
前期回顧:我要偷偷學Python,然后驚呆所有人(第三天)
上面這篇里面寫了python的一些知識基礎,主要是Python對于檔案的讀寫操作,可能是字數比較少吧,每次我自己點開都覺得有點尷尬,
但是也是因為檔案讀寫相對于前面兩篇會比較難一點吧
那么今天,我們就看一下能讓Python成為‘萬金油’的東西,模塊!如果對基礎還不是很熟練的話可以再扎實一下基礎,畢竟萬丈高樓平地起嘛,基礎不老實是很危險的,
本系列文默認各位有一定的C或C++基礎,因為我是學了點C++的皮毛之后入手的Python,這里也要感謝齊鋒學長送來的支持,
本系列文默認各位會百度,學習‘模塊’這個模塊的話,還是建議大家有自己的編輯器和編譯器的,上一篇已經給大家做了推薦啦?
我要的不多,點個關注就好啦
然后呢,本系列的目錄嘛,說實話我個人比較傾向于那兩本 Primer Plus,所以就跟著它們的目錄結構吧,
本系列也會著重培養各位的自主動手能力,畢竟我不可能把所有知識點都給你講到,所以自己解決需求的能力就尤為重要,所以我在文中埋得坑請不要把它們看成坑,那是我留給你們的鍛煉機會,請各顯神通,自行解決,
好,接下來切入正題,
什么是模塊?
如果有學過其他高級語言的朋友就會知道,在C/C++的源檔案開頭,一般都會有一大堆的‘include’,這是參考頭檔案,一個頭檔案當中會有一些比方說類、函式、變數等等,而你要使用這些東西,你就要事先做一個宣告,
這樣講實在是太空泛了,

假設現在有個QQ群,群里有成員,有檔案資料,有聊天記錄,你要獲取這些東西并使用,你是不是得加群?
掉用模塊就是這個道理,模塊里面有類、有函式、有變數,你要使用這些東西,你就得匯入模塊,
這樣講就通暢多了嘛,
emmm,總覺得還是少了點什么,對,我們來掃描一個模塊,瞟一眼就好啊,不求看懂,大概知道里面是啥,咱心里有點數:
以下是一塊 random 模塊中的截取:
from warnings import warn as _warn
from types import MethodType as _MethodType, BuiltinMethodType as _BuiltinMethodType
from math import log as _log, exp as _exp, pi as _pi, e as _e, ceil as _ceil
from math import sqrt as _sqrt, acos as _acos, cos as _cos, sin as _sin
from os import urandom as _urandom
from _collections_abc import Set as _Set, Sequence as _Sequence
from hashlib import sha512 as _sha512
import _random
__all__ = ["Random","seed","random","uniform","randint","choice","sample",
"randrange","shuffle","normalvariate","lognormvariate",
"expovariate","vonmisesvariate","gammavariate","triangular",
"gauss","betavariate","paretovariate","weibullvariate",
"getstate","setstate", "getrandbits",
"SystemRandom"]
NV_MAGICCONST = 4 * _exp(-0.5)/_sqrt(2.0)
TWOPI = 2.0*_pi
LOG4 = _log(4.0)
SG_MAGICCONST = 1.0 + _log(4.5)
BPF = 53 # Number of bits in a float
RECIP_BPF = 2**-BPF
class Random(_random.Random):
VERSION = 3 # used by getstate/setstate
def __init__(self, x=None):
self.seed(x)
self.gauss_next = None
def seed(self, a=None, version=2):
if a is None:
try:
# Seed with enough bytes to span the 19937 bit
# state space for the Mersenne Twister
a = int.from_bytes(_urandom(2500), 'big')
except NotImplementedError:
import time
a = int(time.time() * 256) # use fractional seconds
if version == 2:
if isinstance(a, (str, bytes, bytearray)):
if isinstance(a, str):
a = a.encode()
a += _sha512(a).digest()
a = int.from_bytes(a, 'big')
super().seed(a)
self.gauss_next = None
……
可以看到,開頭那個它調了一堆的包(import…,現在看不懂沒關系),然后接下來時一些變數,接著是個類,類里面有函式,
好,大概瞟一眼就好啊,我們繼續
定義變數需要用賦值陳述句,封裝函式需要用def陳述句,封裝類需要用class陳述句,但封裝模塊不需要任何陳述句,
之所以不用任何陳述句,是因為每一份單獨的Python代碼檔案(后綴名是.py的檔案)就是一個單獨的模塊,
這個也不難理解吧,
封裝模塊的目的也是為了把程式代碼和資料存放起來以便再次利用,如果封裝成類和函式,主要還是便于自己呼叫,但封裝了模塊,我們不僅能自己使用,檔案的方式也很容易共享給其他人使用,
跟我一起動手匯入自己的模塊
怎么說呢,別人的模塊千千萬,但是學習的時候還是用自己寫的模塊比較得心應手,因為以后也少不了自己寫模塊的時候,
第一步:新建一個模塊
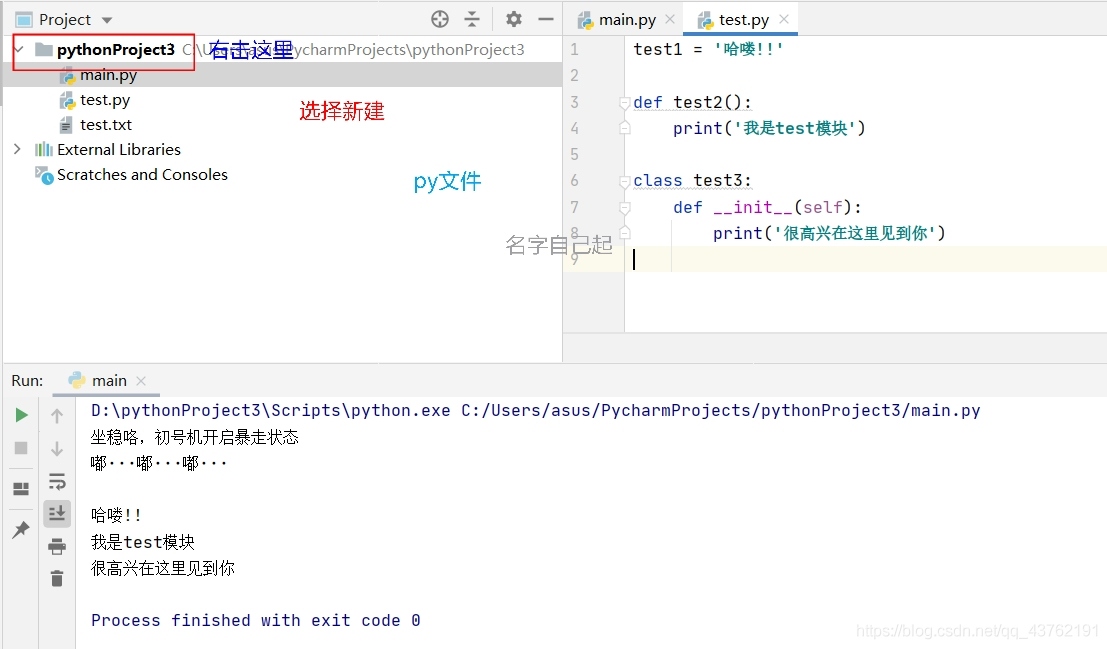
照圖中的順序,把模塊新建出來,然后把代碼寫上,
第二步:呼叫模塊
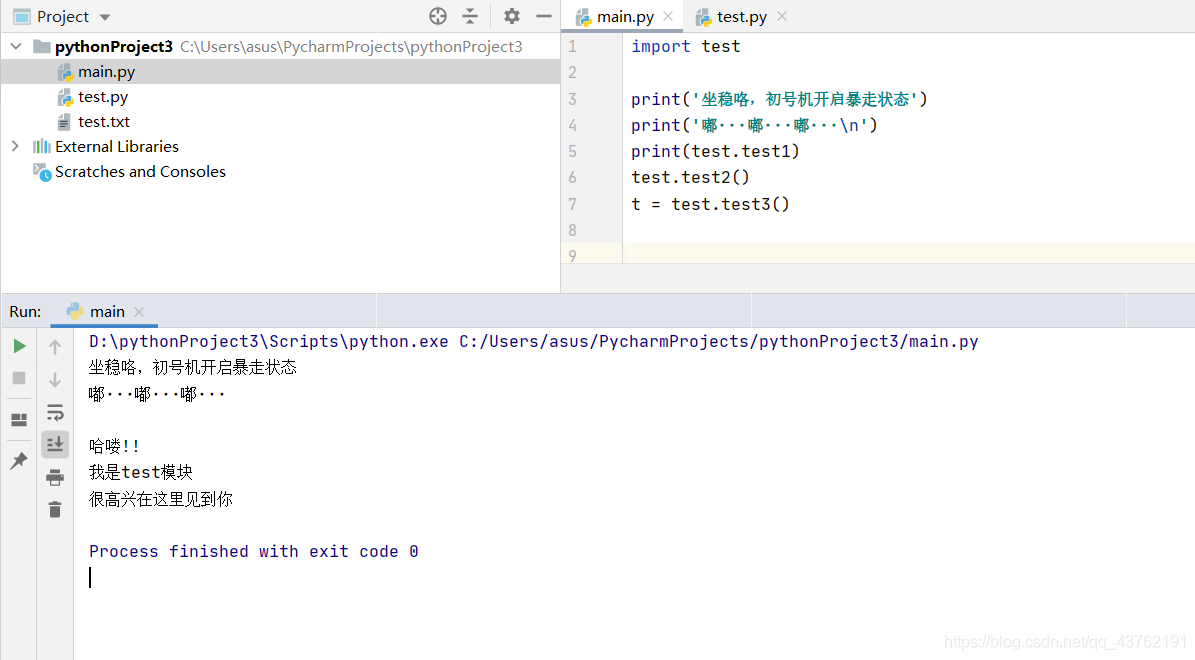
好,這是一個很簡單的小栗子,
呼叫模塊不同方法,
就像上一篇的檔案打開有兩種方法,一種直接了當的打開,另一種用別名,這里呼叫模塊也有不同的方法,
第一種直接import已經見過了,不過這里可以再說一點,如果模塊名過長,可以取個別名
比方說import test,你覺得test有點長,后面使用不方便,你可以這樣:import test as t
不過后面就只能用 t 來指代那個模塊,而不能再用 test 了,它已經被頂包了,
第二種方法,叫 from…import…
這種方法是什么,還是上面那個例子,我現在就想用test里面的那個test3類,其他的我不要,那我為什么要把其他的東西都導進來,那不是太龐大了嗎?這時候就可以用這種方法,精準定位,
看圖:
這是一個典型的錯誤寫法:既然你已經精準定位了,就不要再糾纏與以前的那個大水池了
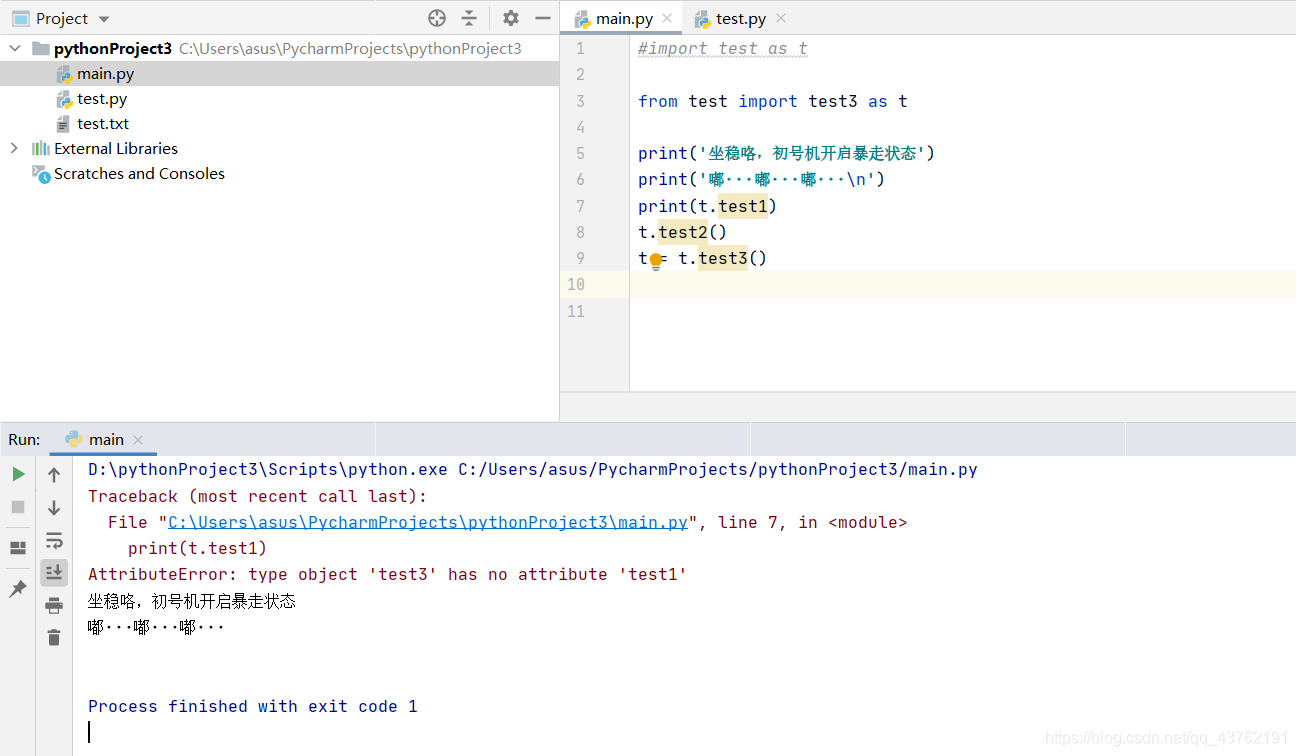
這里測驗了一下如果只匯入某部分,其余沒被匯入的部分被匯入部分應用會不會有沖突:
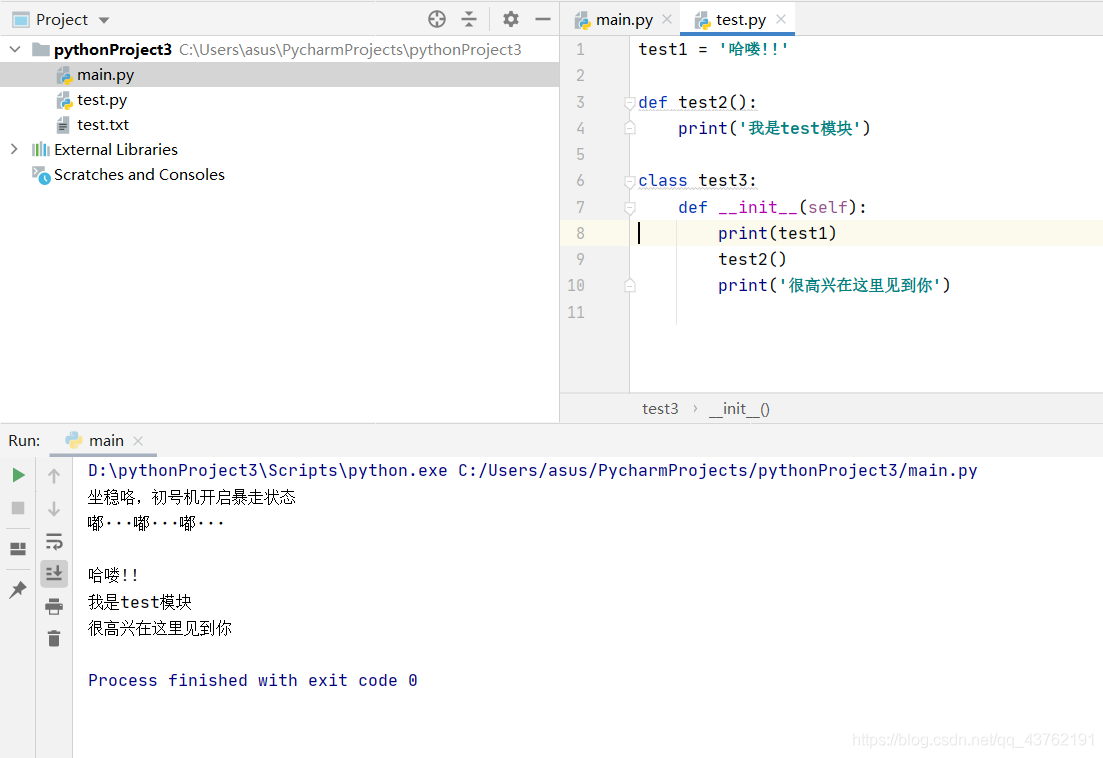
這是驗證結果:
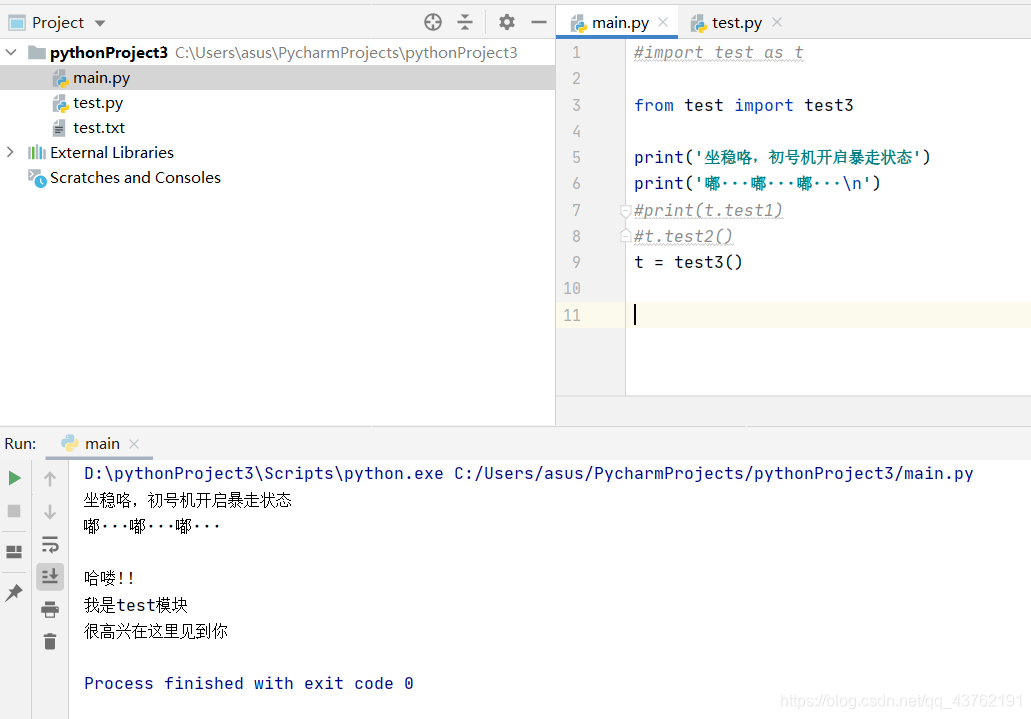
這是別名的使用,照樣是可以使用的:
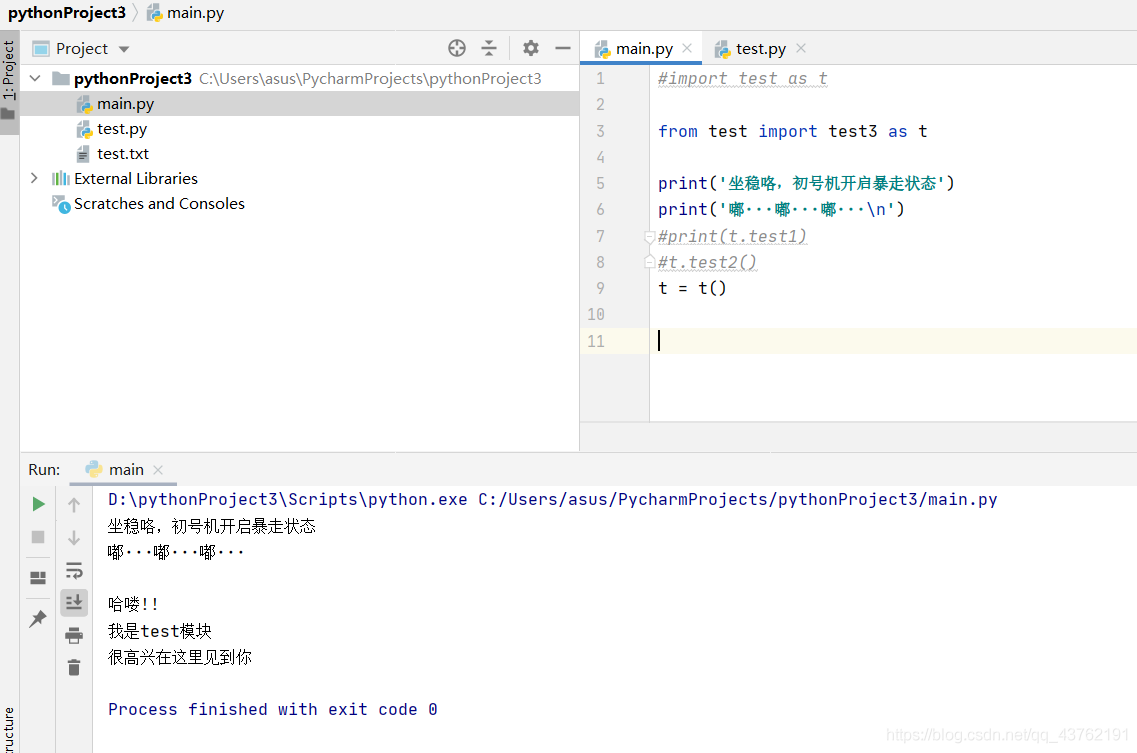
這里再提一點,如果想要匯入多個模塊呢?也是可以的,不同模塊之間用逗號割開即可,大家動起來,自己嘗試一下,
if __name__ == '__main__'
對于Python和其他許多編程語言來說,程式都要有一個運行入口,
在Python中,當我們在運行某一個py檔案,就能啟動程式 ——— 這個py檔案就是程式的運行入口,
但是,當我們有了一大堆py檔案組成一個程式的時候:
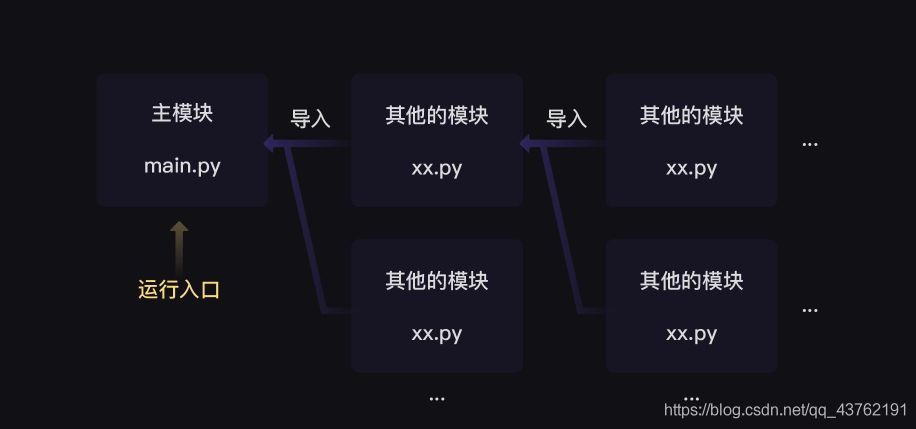
為了【指明】某個py檔案是程式的運行入口,我們可以在該py檔案中寫出這樣的代碼:
# 【檔案:xx.py】
代碼塊 ①……
if __name__ == '__main__':
代碼塊 ②……
這句話的意思是這樣的:

這里的【if name == ‘main’】就相當于是 Python 模擬的程式入口,Python 本身并沒有規定這么寫,這是一種程式員達成共識的編碼習慣,
csv模塊操作Excel圖表
首先我們要明確的知道,這是在使用別人的模塊,其次我們只知道我們要實作的功能是簡單操作Excel表格,
那么我們的順序就應該是:
我要用什么模塊?
這個模塊里有哪些功能?
這些具體功能該怎么使用?
好的,我去用了,
我要用什么模塊?
這個其實很好辦,也很不好辦,
說好辦嘛,你問度娘就好啦:
是吧,一搜全都有,
說不好辦吧,很多前人的經驗你是搜不到的,你得去問,
比如說我們今天就使用csv模塊,因為它簡單易上手,
這個模塊里有哪些東西?
那這個問題也很好辦嘛,如果覺得自己英語沒問題,或者想鍛煉一下英語的朋友,可以去官網,因為官網是有更新到最新版的,
中文翻譯版嘛,有時候不能很有效的找到最新版,
嘿嘿,開個玩笑,中文版也有
Python手冊(官方中文版)
好,我們找到csv模塊(有搜索框的):CSV
有興趣的話可以連中文帶英文一起看,趕時間的話就直接看它的示例代碼即可啦,
使用csv模塊
首先我們建個表:
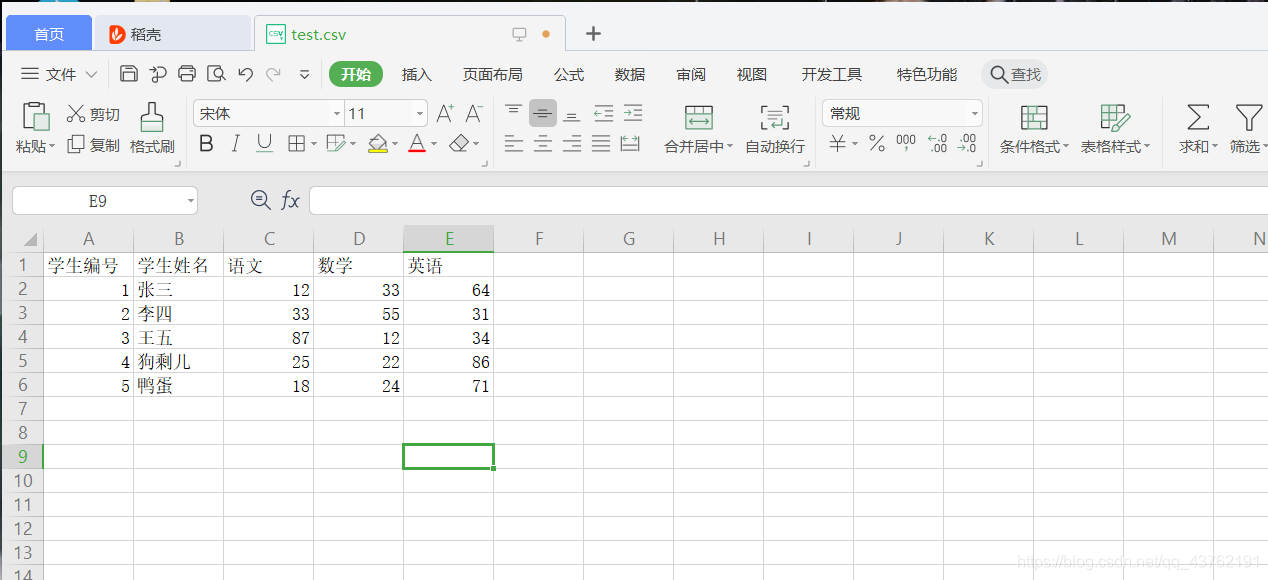
然后打開這個表,就像打開檔案一樣,如果檔案操作還不熟練的朋友可以回到這篇溫習一下:
我要偷偷學Python(3)
讀
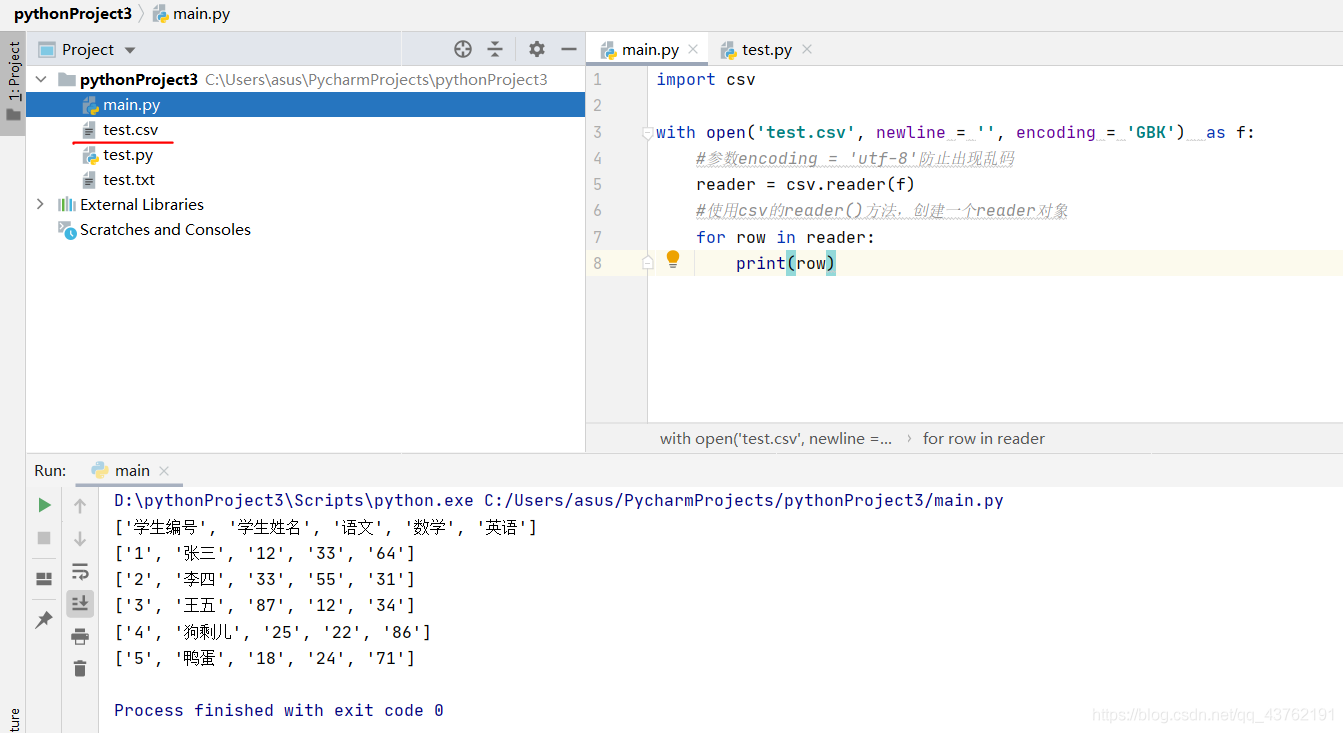
import csv
with open('test.csv', newline = '', encoding = 'GBK') as f:
#引數encoding = 'utf-8'防止出現亂碼
reader = csv.reader(f)
#使用csv的reader()方法,創建一個reader物件
for row in reader:
print(row)
寫
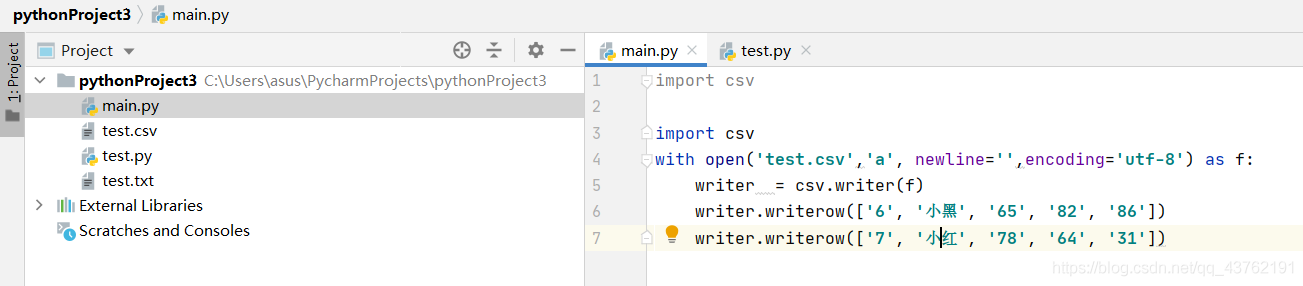
先創建一個變數名為writer(也可以是其他名字)的實體,創建方式是writer = csv.writer(x),然后使用writer.writerow(串列)就可以給csv檔案寫入一行串列中的內容,

import csv
with open('test.csv','a', newline='',encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['6', '小黑', '65', '82', '86'])
writer.writerow(['7', '小紅', '78', '64', '31'])
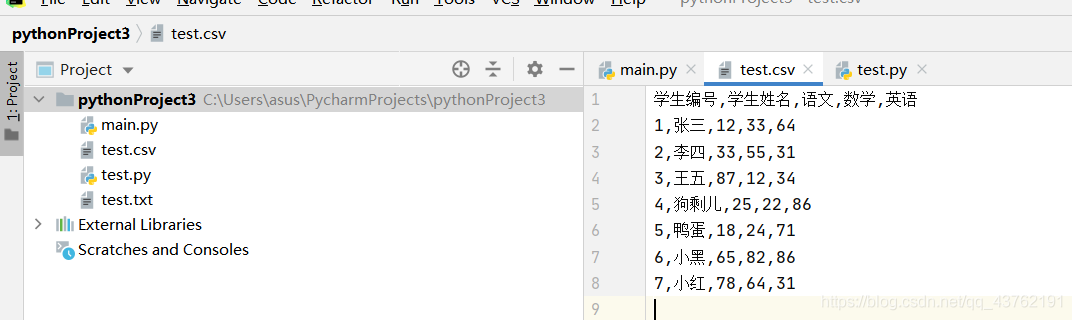
到這里,最基本的csv表格讀取和錄入方法我們就已經學會了,
今日份任務:
大家嘗試一下將多個csv檔案合并到一個csv檔案中吧,這個說難其實也不難,說簡單也不是那么的直觀啦,
下一篇我會放上我的代碼,
然后呢,我平均三四天更一篇“偷偷學Python”系列文咯,所以大家不要著急,一切都會如期而至,
下一篇是實操文,帶大家從頭回顧這些天的學習內容,練習會比較多哦,
我畫了個圈,歡迎大家來我們的小圈子
我建了一個Python學習答疑群,有興趣的朋友可以了解一下:這是個什么群
直通群的傳送門:傳送門


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/189673.html
標籤:其他