文章目錄
- 為什么要有MHA
- 什么是MHA
- MHA的組成
- MHA的實驗目的
- 實驗拓撲圖
- 實驗步驟
- 搭建線網源與底層環境
- Mysql 5.7安裝程序
- 主從復制
- 安裝 MHA 軟體
- 驗證配置
- 修復主機后如何再次上線
為什么要有MHA
目前MySQL已經成為市場上主流資料庫之一,考慮到業務的重要性,MySQL資料庫單點問題已成為企業網站架構中最大的隱患,隨著技術的發展,MHA的出現就是解決MySQL單點的問題,另外隨著企業資料量越來越龐大,資料庫的壓力又成為企業的另一個瓶頸,MySQL 多主多從架構的出現可以減輕MySQL本身的壓力,本章將主要介紹MHA的搭建和模擬 MySQL故障自動切換的程序,
什么是MHA
MHA (MasterHigh Avalability)目前在 MySQL高可用方面是一個相對成熟的解決方案,它由日本 DeNA公司youshimaton(現就職于Facebook公司)開發,是一套優秀的MySQL高可用環境下故障切換和主從復制的軟體,在MySQL故障切換程序中,MHA能做到在030秒之內自動完成資料庫的故障切換操作,并且在進行故障切換的程序中,MHA能在最大程度上保證資料的一致性,以達到真正意義上的高可用,
MHA的組成
| MHA Manager(管理節點) |
|---|
| MHA Node(資料節點) |
MHA的實驗目的
| 自動故障切換程序中,MHA試圖從宕機的主服務器上保存二進制日志,最大程度的保證資料不丟失 |
|---|
| 使用半同步復制,可以大大降低資料丟失的風險 |
| 目前MHA支持一主多從架構,最少三臺服務,即一主兩從 |
實驗拓撲圖
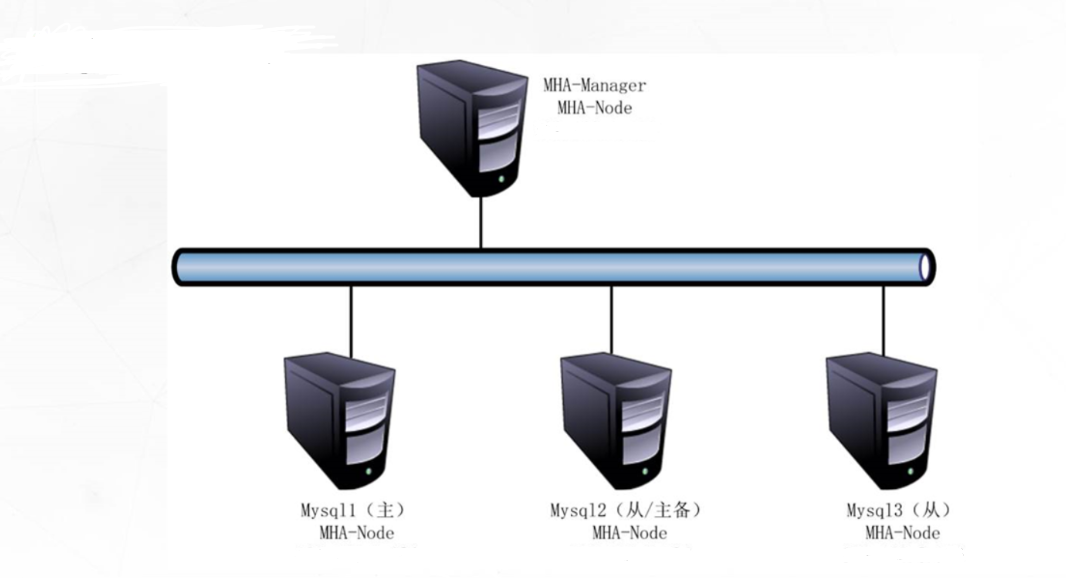
實驗步驟
| 20.0.0.23 | 主master |
|---|---|
| 20.0.0.24 | 備master |
| 20.0.0.25 | 從服務器 |
| 20.0.0.26 | MHA—manager節點 |
| 所有網關: | 20.0.0.1 |
| 其他環境: | 防火墻與系統內核全關 |
搭建線網源與底層環境
如果當時YUM倉庫安裝的是本地源的話,必須要創建現網源
##所有搭建yum倉庫的節點機器都要做
[root@mysql1 ~]# cd /etc/yum.repos.d/
[root@mysql1 yum.repos.d]# mv backup/CentOS-Base.repo ./
[root@mysql1 yum.repos.d]# ll
total 8
drwxr-xr-x. 2 root root 163 Oct 21 02:21 backup
-rw-r--r--. 1 root root 1664 Nov 23 2018 CentOS-Base.repo
-rw-r--r--. 1 root root 116 Sep 13 21:35 local.repo
[root@mysql1 yum.repos.d]# rm -rf local.repo
##以下兩步必須要做
[root@mysql1 yum.repos.d]# yum clean all
[root@mysql1 yum.repos.d]# yum makecache
##下面三步所有機器必須做
[root@mysql1 ~]# systemctl stop firewalld
[root@mysql1 ~]# iptables -F
[root@mysql1 ~]# setenforce 0
setenforce: SELinux is disabled
Mysql 5.7安裝程序
可以看我這篇博客
主從復制
#首先改下所有主機名
hostnamectl set-hostname mysql1 :20.0.0.23
hostnamectl set-hostname mysql2 :20.0.0.24
hostnamectl set-hostname mysql3 :20.0.0.25
hostnamectl set-hostname manager :20.0.0.21
#第二步去所有Mysql節點修該/etc/hosts檔案
20.0.0.23 mysql1
20.0.0.24 mysql2
20.0.0.25 mysql3
###記住所有的都需要####
#所有主機互相 ping mysql2/1/3 通了說明OK
[root@mysql1 ~]# ping mysql2
PING mysql2 (20.0.0.24) 56(84) bytes of data.
64 bytes from mysql2 (20.0.0.24): icmp_seq=1 ttl=64 time=1.24 ms
64 bytes from mysql2 (20.0.0.24): icmp_seq=2 ttl=64 time=0.894 ms
[root@mysql1 ~]# ping mysql3
PING mysql3 (20.0.0.25) 56(84) bytes of data.
64 bytes from mysql3 (20.0.0.25): icmp_seq=1 ttl=64 time=0.596 ms
(2)開啟主從復制二進制檔案
#修改 Master 的主組態檔/etc/my.cnf 檔案,三臺服務器的 server-id 不能一樣
[root@Mysql1 ~]# cat /etc/my.cnf
[client]
#default-character-set=utf8 ## 這句話注釋掉,不然健康檢查過不去
[mysqld]
server-id = 1
log_bin = master-bin
log-slave-updates = true
[root@mysql1 ~]# systemctl restart mysqld
#配置從服務器:
在/etc/my.cnf 中修改或者增加下面內容,
[root@Mysql2 ~]# vim /etc/my.cnf
[client]
#default-character-set=utf8 ## 這句話注釋掉,不然健康檢查過不去
[mysqld]
server-id = 2
log_bin = master-bin
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
[root@mysql2 ~]# systemctl restart mysqld
##配置從服務器:
在/etc/my.cnf 中修改或者增加下面內容,
[root@Mysql3 ~]# vim /etc/my.cnf
[client]
#default-character-set=utf8 ## 這句話注釋掉,不然健康檢查過不去
[mysqld]
server-id = 3
log_bin = master-bin
relay-log = relay-log-bin
relay-log-index = slave-relay-bin.index
[root@mysql3 ~]# systemctl restart mysqld
(3)Mysql1、Mysql2、Mysql3 都要去做兩個軟鏈接
[root@Mysql1 ~]# ln -s /usr/local/mysql/bin/mysql /usr/sbin/
[root@Mysql1 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
(4)在所有資料庫節點上授權兩個用戶,一個是從庫同步使用,另外一個是 manager 使用
mysql> grant replication slave on *.* to 'myslave'@'20.0.0.%' identified by 'abc123';
mysql> grant all privileges on *.* to 'mha'@'20.0.0.%' identified by 'manager';
mysql> flush privileges;
(5)在 Mysql1 主機上查看二進制檔案和同步點
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000001 | 889 | | | |
+-------------------+----------+--------------+------------------+-------------------+
##接下來在 Mysql2 和 Mysql3 都要執行以下幾步!##
mysql> change master to master_host='20.0.0.23',master_user='myslave',master_password='123',master_log_file='master-bin.000001',master_log_pos=889;
mysql> start slave;
##查看 IO 和 SQL 執行緒都是 yes 代表同步是否正常
mysql> show slave status\G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
(6)必須設定兩個從庫為只讀模式,注意是兩個
mysql> set global read_only=1;
(7)驗證主從復制
#在主master創建一個庫,去另外兩臺從服務器查看是否能夠看到這個庫,如果能夠看見說明成了
安裝 MHA 軟體
(1)所有服務器上都安裝 MHA 依賴的環境,首先安裝 epel 源
[root@MHA-manager ~]# yum install epel-release --nogpgcheck -y
yum install -y perl-DBD-MySQL \
perl-Config-Tiny \
perl-Log-Dispatch \
perl-Parallel-ForkManager \
perl-ExtUtils-CBuilder \
perl-ExtUtils-MakeMaker \
perl-CPAN
(2)MHA 軟體包對于每個作業系統版本不一樣Centos只能用0.57的版本
#<注意:所有服務器>上必須先安裝 node 組件,最后在 MHA-manager 節點上安裝 manager 組件,
#因為 manager 依賴 node 組件
#這里用主機mysql1演示步驟
[root@Mysql1 ~]# tar zxvf mha4mysql-node-0.57.tar.gz
[root@Mysql1 ~]# cd mha4mysql-node-0.57
[root@Mysql1 mha4mysql-node-0.57]# perl Makefile.PL
[root@Mysql1 mha4mysql-node-0.57]# make
[root@Mysql1 mha4mysql-node-0.57]# make install
(3) 在 MHA-manager 上安裝 manager 組件(!注意:一定要先安裝node 組件才能安裝manager 組件)
[root@MHA-manager ~]# tar zxvf mha4mysql-manager-0.57.tar.gz
[root@MHA-manager ~]# cd mha4mysql-manager-0.57/
[root@MHA-manager mha4MHA-manager-0.57]# perl Makefile.PL
[root@MHA-manager mha4MHA-manager-0.57]# make
[root@MHA-manager mha4MHA-manager-0.57]# make install
1:manager 安裝后在/usr/local/bin 下面會生成幾個工具,主要包括以下幾個:
masterha_check_ssh 檢查 MHA 的 SSH 配置狀況
masterha_check_repl 檢查 MySQL 復制狀況
masterha_manger 啟動 manager的腳本
masterha_check_status 檢測當前 MHA 運行狀態
masterha_master_monitor 檢測 master 是否宕機
masterha_master_switch 控制故障轉移(自動或者手動)
masterha_conf_host 添加或洗掉配置的 server 資訊
masterha_stop 關閉manager
2:node 安裝后也會在/usr/local/bin 下面會生成幾個腳本(這些工具通常由 MHA
Manager 的腳本觸發,無需人為操作)主要如下:
save_binary_logs 保存和復制 master 的二進制日志
apply_diff_relay_logs 識別差異的中繼日志事件并將其差異的事件應用于其他的 slave
filter_mysqlbinlog 去除不必要的 ROLLBACK 事件(MHA 已不再使用這個工具)
purge_relay_logs 清除中繼日志(不會阻塞 SQL 執行緒)
(4)配置無密碼認證
1. 在 manager 上配置到所有資料庫節點的無密碼認證
[root@MHA-manager ~]# ssh-keygen -t rsa //一路按回車鍵
[root@MHA-manager ~]# ssh-copy-id 20.0.0.23 #yes 輸入對方的root登錄密碼
[root@MHA-manager ~]# ssh-copy-id 20.0.0.24
[root@MHA-manager ~]# ssh-copy-id 20.0.0.25
2. 在 Mysql1 上配置到資料庫節點Mysql2和Mysql3的無密碼認證
[root@Mysql1 ~]# ssh-keygen -t rsa
[root@Mysql1 ~]# ssh-copy-id 20.0.0.24 #yes 輸入對方的root登錄密碼
[root@Mysql1 ~]# ssh-copy-id 20.0.0.25
3. 在 Mysql2 上配置到資料庫節點Mysql1和Mysql3的無密碼認證
[root@Mysql2 ~]# ssh-keygen -t rsa
[root@Mysql2 ~]# ssh-copy-id 20.0.0.23 #yes 輸入對方的root登錄密碼
[root@Mysql2 ~]# ssh-copy-id 20.0.0.25
4. 在 Mysql3 上配置到資料庫節點Mysql1和Mysql2的無密碼認證
[root@Mysql3 ~]# ssh-keygen -t rsa
[root@Mysql3 ~]# ssh-copy-id 20.0.0.23 #yes 輸入對方的root登錄密碼
[root@Mysql3 ~]# ssh-copy-id 20.0.0.24
(5)在 manager 節點上復制相關腳本到/usr/local/bin 目錄
[root@MHA-manager ~]# cp -ra /opt/mha4mysql-manager-0.57/samples/scripts /usr/local/bin
//拷貝后會有四個執行檔案
[root@atlas ~]# ll /usr/local/bin/scripts/
總用量 32
-rwxr-xr-x 1 mysql mysql 3648 5 月 31 2015 master_ip_failover #自動切換時 VIP 管理的腳本
-rwxr-xr-x 1 mysql mysql 9872 5 月 25 09:07 master_ip_online_change #在線切換時 vip 的管理
-rwxr-xr-x 1 mysql mysql 11867 5 月 31 2015 power_manager #故障發生后關閉主機的腳本
-rwxr-xr-x 1 mysql mysql 1360 5 月 31 2015 send_report #因故障切換后發送報警的腳本
(6) 復制上述的自動切換時 VIP 管理的腳本到/usr/local/bin 目錄,這里使用腳本管理 VIP
[root@MHA-manager ~]# cp /usr/local/bin/scripts/master_ip_failover /usr/local/bin
(7) 修改內容如下:(洗掉原有內容,直接復制)
[root@MHA-manager ~]#vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#############################添加內容部分#########################################
my $vip = '20.0.0.200';
my $brdc = '20.0.0.255';
my $ifdev = 'ens33';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";
my $exit_code = 0;
##################################################################################
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
###復制完后,還需進行以下操作
在末行模式下
:% s/^#//g 把所有的#洗掉
注意,要去第一行把#加上,不然會報錯 2:0
(5)創建 MHA 軟體目錄并拷貝組態檔
[root@MHA-manager ~]# mkdir /etc/masterha
[root@MHA-manager ~]# cp /opt/mha4mysql-manager-0.57/samples/conf/app1.cnf /etc/masterha/
##這個檔案配置很重要,相當于健康檢查,里面的路徑和賬號密碼以及IP一定不能出錯
##尤其賬號密碼,如果錯了
[root@MHA-manager ~]# vim /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1
master_binlog_dir=/usr/local/mysql/data
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
password=manager
ping_interval=1
remote_workdir=/tmp
repl_password=abc123
repl_user=myslave
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 20.0.0.24 -s 20.0.0.25
shutdown_script=""
ssh_user=root
user=mha
[server1]
hostname=20.0.0.23
port=3306
[server2]
candidate_master=1
check_repl_delay=0
hostname=20.0.0.24
port=3306
[server3]
hostname=20.0.0.25
port=3306
##組態檔決議
[server default]
manager_workdir=/var/log/masterha/app1.log ##manager作業目錄
manager_log=/var/log/masterha/app1/manager.log #manager日志
master_binlog_dir=/usr/local/mysql/data/ #master保存binlog的位置,這里的路徑要與master里配置的binlog的路徑一致,以便mha能找到
#master_ip_failover_script= /usr/local/bin/master_ip_failover #設定自動failover時候的切換腳本,也就是上邊的哪個腳本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change #設定手動切換時候的切換腳本
password=manager #設定mysql中root用戶的密碼,這個密碼是前文中創建監控用戶的那個密碼
user=mha #設定監控用戶root
ping_interval=1 #設定監控主庫,發送ping包的時間間隔,默認是3秒,嘗試三次沒有回應的時候自動進行railover
remote_workdir=/tmp #設定遠端mysql在發生切換時binlog的保存位置
repl_password=123 #設定復制用戶的密碼
repl_user=myslave #設定復制用戶的用戶
report_script=/usr/local/send_report //設定發生切換后發送的報警的腳本
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.195.130 -s 192.168.195.131
shutdown_script="" #設定故障發生后關閉故障主機腳本(該腳本的主要作用是關閉主機放在發生腦裂,這里沒有使用)
ssh_user=root #設定ssh的登錄用戶名
[server1]
hostname=192.168.195.129
port=3306
[server2]
hostname=192.168.195.130
port=3306
candidate_master=1 #//設定為候選master,如果設定該引數以后,發生主從切換以后將會將此從庫提升為主庫,即使這個主庫不是集群中事件最新的slave
check_repl_delay=0 #默認情況下如果一個slave落后master 100M的relay logs的話,MHA將不會選擇該slave作為一個新的master,因為對于這個slave的恢復需要花費很長時間,通過設定check_repl_delay=0,MHA觸發切換在選擇一個新的master的時候將會忽略復制延時,這個引數對于設定了candidate_master=1的主機非常有用,因為這個候選主在切換的程序中一定是新的master
[server3]
hostname=192.168.195.131
port=3306
驗證配置
(1)測驗 ssh 無密碼認證,如果正常最后會輸出 successfully
[root@MHA-manager ~]# masterha_check_ssh -conf=/etc/masterha/app1.cnf
Tue Nov 26 23:09:45 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Nov 26 23:09:45 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Tue Nov 26 23:09:45 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Tue Nov 26 23:09:45 2019 - [info] Starting SSH connection tests..
Tue Nov 26 23:09:46 2019 - [debug]
Tue Nov 26 23:09:45 2019 - [debug] Connecting via SSH from
Tue Nov 26 23:09:46 2019 - [debug] ok.
Tue Nov 26 23:09:47 2019 - [debug]
Tue Nov 26 23:09:46 2019 - [debug] Connecting via SSH from
Tue Nov 26 23:09:47 2019 - [debug] ok.
Tue Nov 26 23:09:47 2019 - [info] All SSH connection tests passed successfully.
----------------------------mysql5.7注意--------------------------------------
請注釋/etc/my.cnf 中 【client】下 #default-character-set=utf8
在所有資料庫中建立以下指令軟連接
ln -s /usr/local/mysql/bin/mysql /usr/sbin/
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
--------------------------------------------------------------------------------------
##前面我有寫過,如果你沒做,一定要回Msql所有的節點上去做一遍
(2)組態檔健康檢查,因為Mha檢查的東西很多,包括網路,路徑,賬號密碼,監聽埠等所以app1.cnf的內容一定核實好
[root@MHA-manager ~]# masterha_check_repl -conf=/etc/masterha/app1.cnf
Checking the Status of the script.. OK
Tue Nov 26 23:10:29 2019 - [info] OK.
#.........##
##........##
Tue Nov 26 23:10:29 2019 - [warning] shutdown_script is not defined.
Tue Nov 26 23:10:29 2019 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
##看到 is ok## 說明成功了
(3)第一次配置需要去master上手動開啟虛擬IP :20.0.0.23主機
[root@Mysql1 ~]# /sbin/ifconfig ens33:1 20.0.0.200/24
[root@Mysql1 ~]# ifconfig 查看一下
如果是最小化安裝需要先安裝網路組件
[root@mysql1 ~]# yum -y install net-tools
[root@Mysql1 ~]# ifconfig
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 20.0.0.200 netmask 255.0.0.0 broadcast 20.255.255.255
ether 00:ec:29:a4:3e:cc txqueuelen 1000 (Ethernet)
(4)啟動 MHA,在manager服務器上
[root@MHA-manager ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
[1] 77985
[root@localhost ~]# jobs ## 查看后臺運行的任務
[1]+ Running nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
(5)查看 MHA 狀態,可以看到當前的 master 是 Mysql1 節點
[root@MHA-manager ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:32493) is running(0:PING_OK), master:20.0.0.23
#### master是20.0.0.23,沒問題
(6)驗證VIP地址漂移
## 監控日志記錄
[root@MHA-manager ~]#tailf /var/log/masterha/app1/manager.log
##把主服務區20.0.0.23的mysql停用
[root@mysql1 ~]# systemctl stop mysqld
這時候監控日志看到,重置成功

(7)檢查漂移地址是否在20.0.0.24主機上
#查看一下mysql 1的網卡配置資訊
[root@mysql2 ~]# ifconfig
#VIP地址已經消失
我們現在去mysql2查看一下網卡配置資訊,漂移地址已經漂移成功!
[root@mysql2 ~]# ifconfig
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 20.0.0.200 netmask 255.0.0.0 broadcast 20.255.255.255
ether 00:0c:29:a4:3e:ec txqueuelen 1000 (Ethernet)
修復主機后如何再次上線
故障修復步驟:
1.修復db
systemctl start mysqld
#去當前master主機查看二進制檔案以及節點
在 Mysql2 主機上查看二進制檔案和同步點
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000002 | 1215 | | | |
+-------------------+----------+--------------+------------------+-------------------+
2.修復主從
>change master to master_host='20.0.0.24',master_user='myslave',master_password='abc123',master_log_file='master-bin.000002',master_log_pos=1215;
>start slave;
查看 IO 和 SQL 執行緒都是 yes 代表同步是否正常,
mysql> show slave status\G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
3.修改組態檔(再把這個記錄添加進去,因為它檢測掉失效時候會自動消失)
vi /etc/masterha/app1.cnf
[server1]
hostname=192.168.195.129
port=3306
4.啟動manager(在manager那臺機器上)
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/189782.html
標籤:其他
上一篇:資料庫面試常問的一些基本概念