目錄
- 一、排列熵
- 1.概念
- 2.基本原理
- 3.MATLAB代碼
- 參考文獻
一、排列熵
1.概念
一種檢測動力學突變和時間序列隨機性的方法,能夠定量評估信號序列中含有的隨機噪聲,
2.基本原理
(1) 對一組長度為N的時間序列X進行相空間重構,得到矩陣Y為
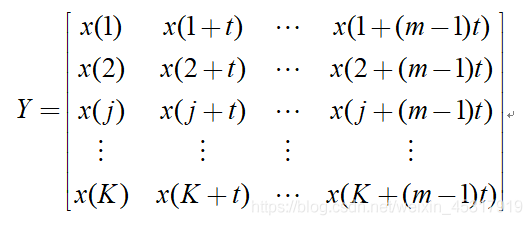
其中,m為嵌入維數,t為延遲時間,K=N-(m-1)t,
矩陣Y中的每一行都是一個重構分量,共有K個重構分量,
(2) 將每一個重構分量按照升序重新排列,得到向量中各元素位置的列索引構成一組符號序列,
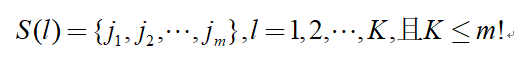 m維相空間映射不同的符號序列總共有m!種,
m維相空間映射不同的符號序列總共有m!種,
(3) 計算每一種符號序列出現的次數除以m!種不同的符號序列出現的總次數作為該重構分量的概率,
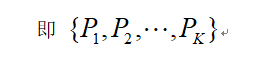 (4) 時間序列X的排列熵的計算公式為:
(4) 時間序列X的排列熵的計算公式為:
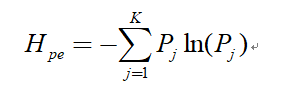
(5) 排列熵的最大值為ln(d!),將排列熵值進行歸一化處理,即:
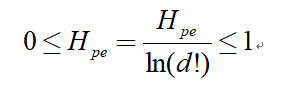 排列熵值的大小表示時間序列X的隨機程度:熵值越小,說明時間序列越簡單、規則;反之,熵值越大,則時間序列越復雜、隨機,
排列熵值的大小表示時間序列X的隨機程度:熵值越小,說明時間序列越簡單、規則;反之,熵值越大,則時間序列越復雜、隨機,
說明: 我之前看排列熵的理論一直看不懂,搞不清排列熵的計算程序,直到我認真閱讀排列熵演算法的代碼,并且結合理論,才終于搞清楚,建議讀者閱讀排列熵的代碼時,邊除錯邊思考,有助于理解,
3.MATLAB代碼
%% 主函式呼叫排列熵函式求時間序列的排列熵值
[m,n]=size(X); % X為時間序,一行為一個時間序列,
% 相空間重構:eDim為嵌入維數,eLag為延遲時間
% 當X具有多列和多行時,每列將被視為獨立的時間序列,該演算法對X的每一列假設相同的時間延遲和嵌入維度,并以標量回傳ESTDIM和ESTLAG,
[~,eLag,eDim] = phaseSpaceReconstruction(X);
% 求排列熵:pe為排列熵
pe=zeros(1,m);
for i=1:m
[pe(i),~] = pec(X(i,:),eDim,eLag);
end
%% 排列熵演算法
function [pe ,hist] = pec(y,m,t)
% Calculate the permutation entropy
% Input: y: time series;
% m: order of permuation entropy 嵌入維數
% t: delay time of permuation entropy,延遲時間
% Output:
% pe: permuation entropy
% hist: the histogram for the order distribution
ly = length(y);
permlist = perms(1:m);
c(1:length(permlist))=0;
for j=1:ly-t*(m-1)
[~,iv]=sort(y(j:t:j+t*(m-1)));
for jj=1:length(permlist)
if (abs(permlist(jj,:)-iv))==0
c(jj) = c(jj) + 1 ;
end
end
end
hist = c;
c=c(find(c~=0));
p = c/sum(c);
pe = -sum(p .* log(p));
參考文獻
[1]趙昕海,張術臣,李志深,等.基于VMD的故障特征信號提取方法[J].振動、測驗與診斷,2018,38(1):11-13.
[2]排列熵matlab實作
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/190408.html
標籤:AI