文章目錄
- 一、LaneNet 演算法詳解
- 1.1 LaneNet 簡介
- 1.2 整體結構分析
- 1.3 LaneNet 網路結構
- 1.4 H-Net 網路結構
- 1.5 LaneNet 性能優點
- 二、手把手帶你實作 LaneNet
- 2.1 專案介紹
- 2.2 環境搭建
- 2.3 準備作業
- 2.4 模型測驗
- 1024,祝大家節日快樂!喜歡就給我點個贊吧,您的支持是我創作的最大動力!
資源匯總:
論文下載地址:https://arxiv.org/abs/1802.05591
github專案地址:https://github.com/MaybeShewill-CV/lanenet-lane-detection
LanNet資料合集:https://pan.baidu.com/s/17dy1oaYKj5XruxAL38ggRw 提取碼:1024
LanNet論文翻譯:車道線檢測網路之LaneNet
一、LaneNet 演算法詳解
1.1 LaneNet 簡介
傳統的車道線檢測方法依賴于手工提取的特征來識別,如顏色的特征、結構張量、輪廓等,這些特征還可能與霍夫變換、各種算子或卡爾曼濾波器相結合,在識別車道線之后,采用后處理技術來過濾錯誤檢測并將其分組在一起以形成最終車道,然而,由于道路場景的變化,這些傳統的方法容易出現魯棒性問題!
更新的方法利用深度學習模型,這些模型被訓練用于像素級車道分割,但這些方法僅限于檢測預定義的固定數量的車道,例如當前車道,并且不能應對車道改變,
基于此,2018年Davy Neven等人提出一種新的車道線檢測網路LaneNet,LaneNet主要做出了如下兩個貢獻:
- 將車道檢測問題歸結為一個實體分割問題,其中每條車道都形成了自己的實體,可以端到端地進行訓練,
- 構建了一個新的網路H-Net,用于學習給定輸入影像的透視變換引數,該透視變換能夠對坡度道路上的車道線進行良好地擬合,克服了魯棒性不好的問題,
1.2 整體結構分析
作者提出了一個多分支的網路結構,包含一個二值化分割網路(lane segmentation)和一個實體分割網路(lane embedding),從而實作端到端、任意數量的車道線檢測,具體來說,二值分割網路輸出所有的車道線像素,而實體分割網路將輸出的車道線像素分配到不同的車道線實體中,整體的網路結構圖如下:
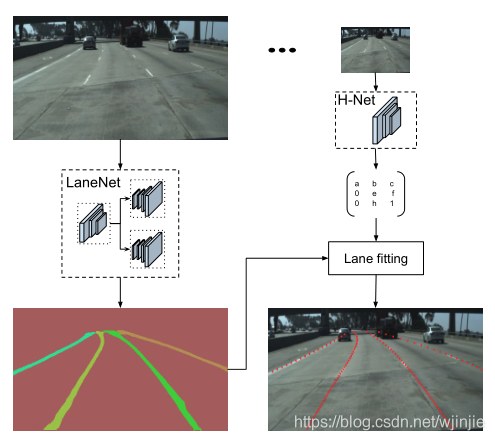
另一方面,資料集輸入到H-Net網路中,學習到透視變換引數H矩陣,用于不同車道線實體的像素,進行車道線擬合,從而得到上圖所示連續點狀的車道線,
1.3 LaneNet 網路結構
LaneNet的整體網路結構如下:
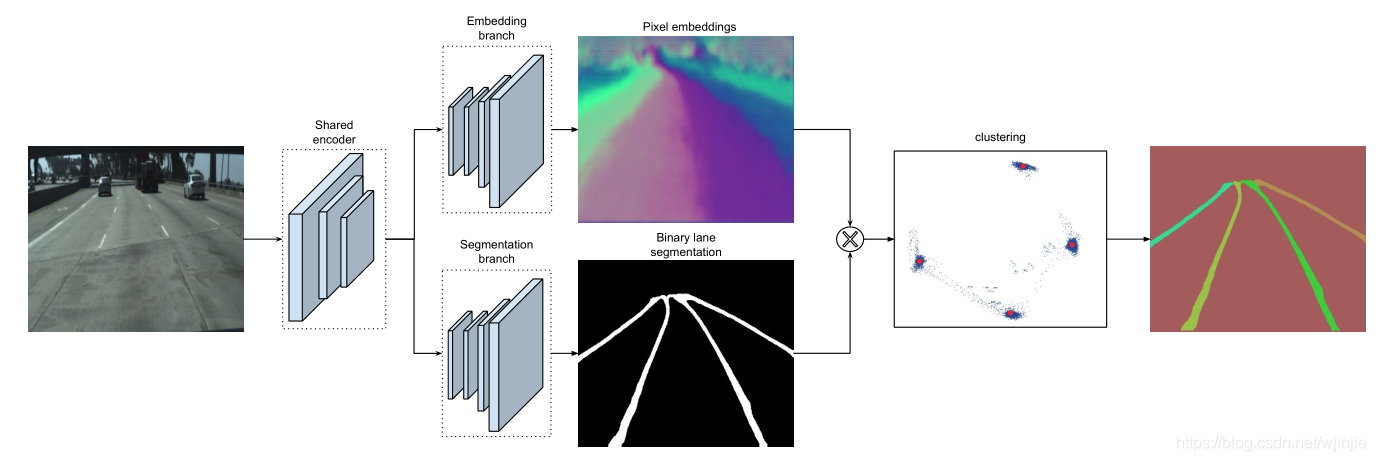
二值化分割網路
Lanenet的一個分支為二值化分割網路,該網路將車道線像素與背景區分開,由于目標類別是2類(車道/背景),并且高度不平衡,因此參考了ENet,損失函式使用的是標準的交叉熵損失函式,
實體分割網路
該分支網路參考了《Semantic Instance Segmentation with a Discriminative Loss Function》,使用基于one-shot的方法做距離度量學習,將該方法集成在標準的前饋神經網路中,可用于實時處理,該分支網路訓練后輸出一個車道線像素點距離,基于歸屬同一車道的像素點距離近,不同車道線像素點距離遠的基本思想,利用聚類損失函式聚類得到各條車道線,
聚類損失函式
損失函式如下:
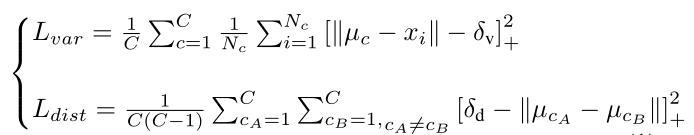
?? ?
[
x
]
+
=
m
a
x
(
0
,
x
)
[x]_+=max(0, x)
[x]+?=max(0,x)
?? ? L t o t a l = L v a r + L d i s t L_{total}=L_{var}+L_{dist} Ltotal?=Lvar?+Ldist?
其中,各個引數表示如下:
- C——表示車道線實體個數;
- N c N_c Nc?——每個車道線實體中像素的個數;
- u c u_c uc?——每個車道線實體的像素中心;
- L v a r L_{var} Lvar?是方差損失,他的目的是為了降低類內距離;
- L d i s t L_{dist} Ldist?是距離損失,它的目的是增大類間距離 (不同車道線之間的距離);
網路結構圖
LaneNet的架構基于編碼器-解碼器網路ENet,該網路是由5個階段組成,前3個階段是編碼器網路,進行了兩次下采樣;后兩個階段是解碼器網路,進行了兩次上采樣,
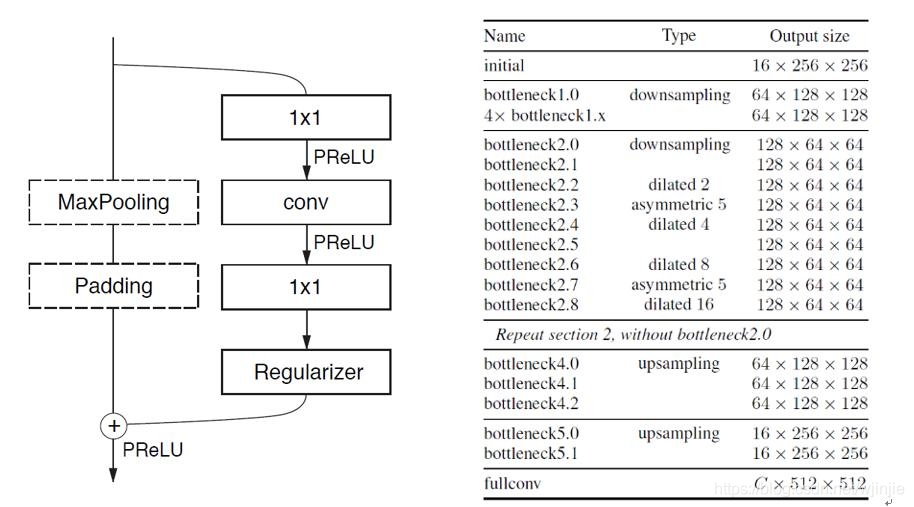
LaneNet在該網路的基礎上修改成了雙分支網路,由于ENet的編碼器比解碼器包含更多的引數,完全在兩個任務之間共享完整的編碼器將導致不令人滿意的結果,因此,LaneNet只在兩個分支之間共享前兩個階段(1和2),留下ENet編碼器的階段3和完整的ENet解碼器作為每個單獨分支的主干,分割分支的最后一層輸出單通道影像,用于二值化分割;而實體分割分支的最后一層輸出N通道影像,其中N是實體維度,每個分支的損失項都是相等加權的,并通過網路反向傳播,
1.4 H-Net 網路結構
LaneNet網路輸出的是每條車道線的像素集合,常規的處理是將影像轉為鳥瞰圖,然后用二次或三次多項式擬合出彎曲的車道線,然而,目前所使用的透視變換矩陣的引數通常是預先設定、不會改變的,在面對水平線波動的影響(如上下坡)等情況下的車道線擬合并不準確,魯棒性不強,因此,作者提出了H-net模型,用來學習透視變換矩陣的引數H,
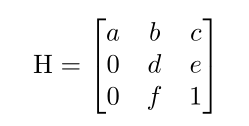
H有6個自由度,放置零是為了強制約束,即在變換下水平線保持水平,
H-NET的網路體系結構較小,由3x3卷積、BN層 和 Relu 的連續塊構成,使用最大池化層來降低維度,并在最后添加2個全連接層,完整的網路結構如下圖所示:
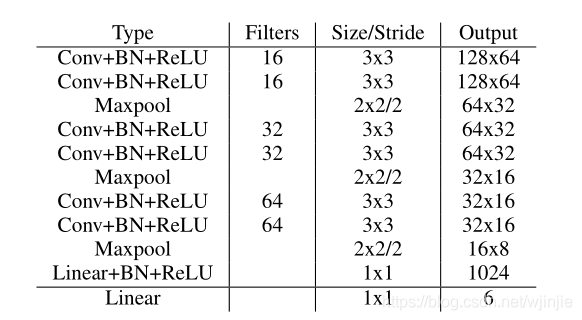
最后一個全連接層的結點數是6,對應的就是H矩陣中的6個引數,
1.5 LaneNet 性能優點
檢測速度,在英偉達1080Ti顯卡上進行測驗,檢測一幀大小為512x512的彩色圖片,耗時19ms,因此每秒可處理50幀左右,

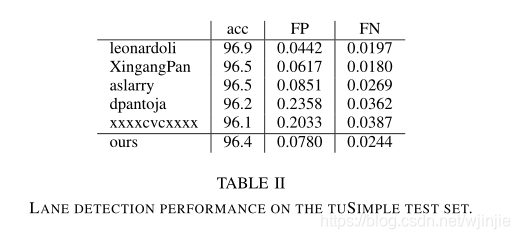
檢測精度, 通過使用LaneNet結合三階多項式擬合和H-Net的變換矩陣,在tuSimple挑戰中檢測精度達到96.4%,獲得了第四名,與第一名相比只有0.5%的差異,結果可以在下表中看到,
二、手把手帶你實作 LaneNet
2.1 專案介紹
該專案在github上已經開源,獲得了1.3k的星標,想試試的同學可克隆下來:https://github.com/MaybeShewill-CV/lanenet-lane-detection,如果打不開,也可以從我的百度云網盤下載:LaneNet資料合集 ,提取碼:1024
代碼結構和各部分功能如下:
lanenet-lane-detection
├── config //組態檔
├── data //一些樣例圖片和曲線擬合引數檔案
├── data_provider // 用于加載資料以及制作 tfrecords
├── lanenet_model
│ ├── lanenet.py //網路布局 inference/compute_loss/compute_acc
│ ├── lanenet_front_end.py // backbone 布局
│ ├── lanenet_back_end.py // 網路任務和Loss計算 inference/compute_loss
│ ├── lanenet_discriminative_loss.py //discriminative_loss實作
│ ├── lanenet_postprocess.py // 后處理操作,包括聚類和曲線擬合
├── model //保存模型的目錄semantic_segmentation_zoo
├── semantic_segmentation_zoo // backbone 網路定義
│ ├── __init__.py
│ ├── vgg16_based_fcn.py //VGG backbone
│ └─+ mobilenet_v2_based_fcn.py //mobilenet_v2 backbone
│ └── cnn_basenet.py // 基礎 block
├── tools //訓練、測驗主函式
│ ├── train_lanenet.py //訓練
│ ├── test_lanenet.py //測驗
│ └──+ evaluate_dataset.py // 資料集評測 accuracy
│ └── evaluate_lanenet_on_tusimple.py // 資料集檢測結果保存
│ └── evaluate_model_utils.py // 評測相關函式 calculate_model_precision/calculate_model_fp/calculate_model_fn
│ └── generate_tusimple_dataset.py // 原始資料轉換格式
├─+ showname.py //模型變數名查看
├─+ change_name.py //模型變數名修改
├─+ freeze_graph.py//生成pb檔案
├─+ convert_weights.py//對權重進行轉換,為了模型的預訓練
└─+ convert_pb.py //生成pb文
2.2 環境搭建
根據開源作者描述,其測驗的環境為:
- ubuntu 16.04
- python3.5
- cuda-9.0
- cudnn-7.0
- GTX-1070 GPU
- tensorflow 1.12.0
我使用的環境與配置為:
- ubuntu16.04系統
- PyCharm 2020
- python3.6
- tensorflow1.13.1-gpu
- cuda-10.0
- cudnn7.6.4
- opencv4.0.0
- RTX 2070 GPU
想嘗試的朋友,可以參考上面兩種配置,也可以自行嘗試其他的版本,
2.3 準備作業
如果想要自行訓練的同學,可以下載TuSimple資料集,進行訓練,同樣,我們也可以直接使用官方訓練好的模型,來輸入圖片,看看測驗效果,為了方便,下面我們直接加載已經訓練好的模型,進行本地測驗,
(1) 下載TuSimple資料集,如果不訓練可以跳過這一步,
(2) 下載訓練好的模型,下載鏈接:LaneNet資料合集 ,提取碼:1024
下載完后,我們將模型檔案tusimple_lanenet放在工程目錄下的model檔案中,如下圖所示:
2.4 模型測驗
完成環境配置和模型部署后,我們就可以進行測驗了!
(1) 先對TusSample資料集中的圖片進行測驗
- 第一步,在原工程目錄下的data檔案中新建一個Mytest檔案夾,然后任意選取TusSample資料集中的一張圖片放入其中,例如1.jpg,如下圖所示:

- 第二步,使用PyCharm打開下載好的專案工程,配置好環境后,打開終端,如下圖所示:
- 第三步,在終端輸入以下命令,執行程式:
python tools/test_lanenet.py --weights_path model/tusimple_lanenet/tusimple_lanenet.ckpt --image_path data/Mytest/1.jpg
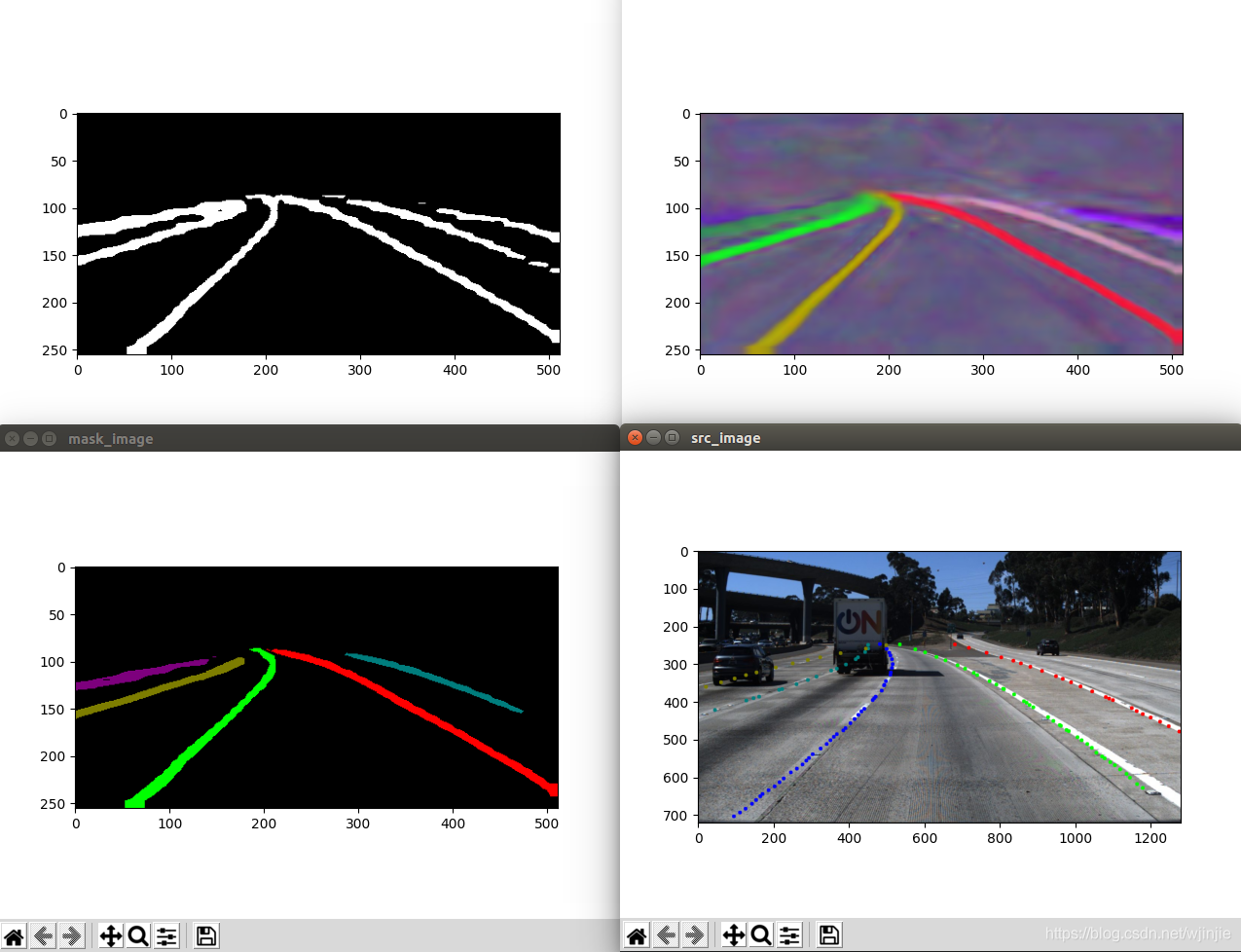
最后車道線檢測效果如下:
(2)對自己的圖片進行測驗
- 第一步,選擇自己拍攝的一張車道線圖片2.jpg,放入剛才新建好的Mytest檔案夾下,如下圖所示:

第二步,打開終端,輸入命令,執行程式:
python tools/test_lanenet.py --weights_path model/tusimple_lanenet/tusimple_lanenet.ckpt --image_path data/Mytest/2.jpg
對自己的拍攝的圖片檢測效果如下:
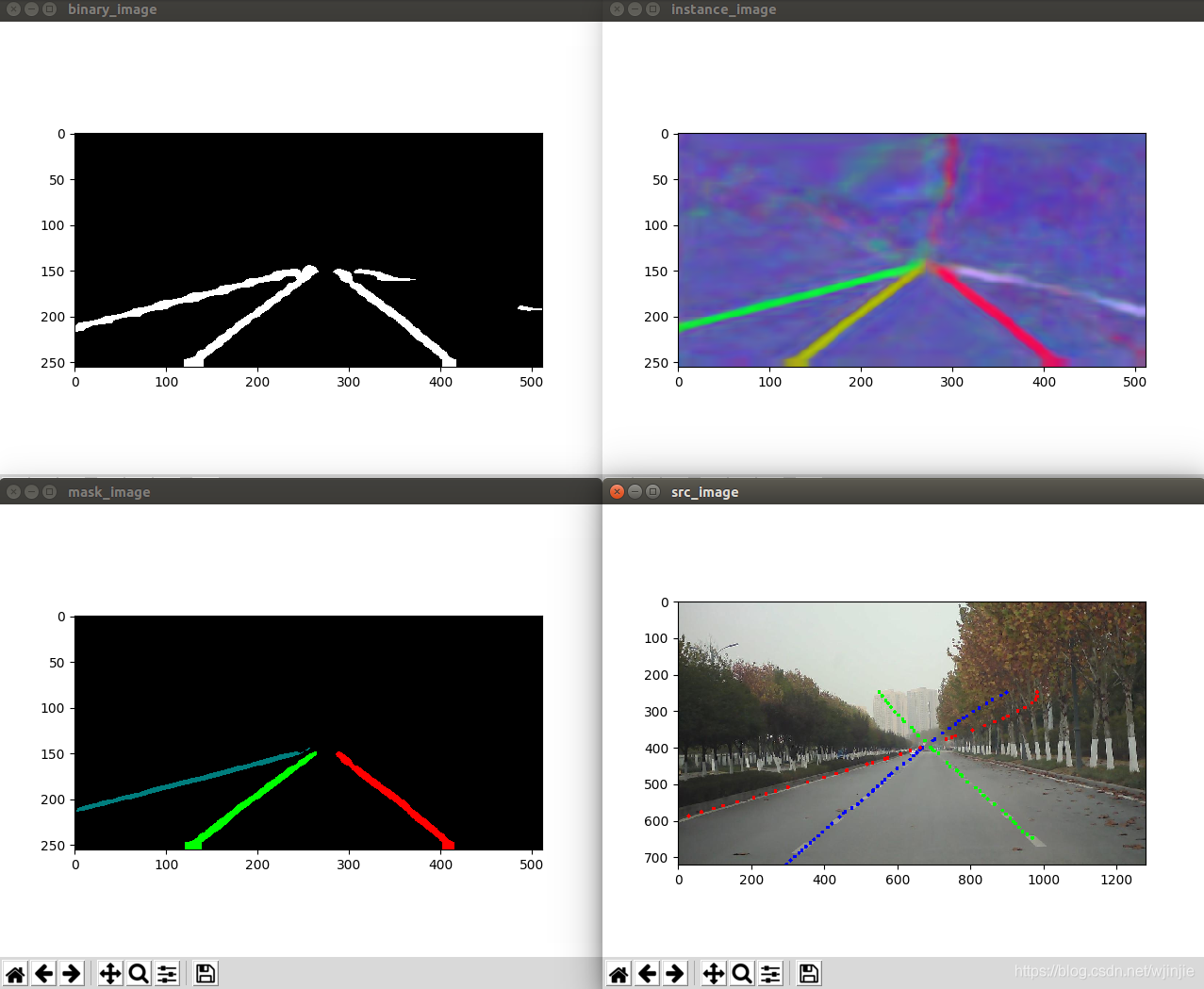
測驗分析:
從圖中可以看出,對自己的圖片進行檢測時,最終的檢測結果雖然能夠完美地與實際車道線重合,但是延伸至了空中,
產生這種情況最主要的原因是:沒有自己制作資料集進行訓練,從而得到更有針對性的模型造成的,由于這里我使用的測驗模型是在TuSimple資料集下訓練得到的,所以我們對TuSimple中的圖片測驗效果會很好,比如前面的1.jpg,
如果我們想要對自己的圖片進行測驗,得到更好的效果,那么就需要自己的資料集,比較好的辦法是:
- 首先在TuSimple資料集下進行訓練,得到的訓練模型作為預訓練模型,這一部分作業其實已經做好了,大家直接下載預訓練模型即可
- 然后,在預訓練模型的基礎上,加載自己制作的資料集,再進行訓練,直到達到預期的效果,
采用這種遷移學習的思想,往往能夠事半功倍!
1024,祝大家節日快樂!喜歡就給我點個贊吧,您的支持是我創作的最大動力!
 CSDN認證博客專家
CSDN博客專家
演算法實習生
計算機視覺
CSDN認證博客專家
CSDN博客專家
演算法實習生
計算機視覺
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/190418.html
標籤:AI