雖然我們可以通過各種手段來提升存盤系統的性能,但在某些復雜的業務場景下,單純依靠存盤系統的性能提升不夠的,典型的場景如下:
- 需要經過復雜運算后得出的資料,存盤系統無能為力,例如,一個論壇需要在首頁展示當前有多少用戶同時在線,如果使用 MySQL來存盤當前用戶狀態, 則每次獲取這個總數都要“ count(*)”大量資料,這樣的操作無論怎么優化 MySQL, 性能都不會太高,如果要實時展示用戶同時在線數,則 MySQL 性能無法支撐
- 讀多寫少的資料,存盤系統有心無力,絕大部分在線業務都是讀多寫少,例如,微博、淘寶、微信這類互聯網業務,讀業務占了整體業務量的90%以上,比如: 一個明星發一條微博 ,可能幾千萬人來瀏覽 ,如果使用 MySQL 來存盤微博,用戶寫微博只有一條insert陳述句,但每個用戶瀏覽時都要select一次 ,即使有索引,幾千萬條select 陳述句對 MyS QL 資料庫的壓力也會非常大
快取就是為了彌補存盤系統在這些復雜業務場景下的不足,快取的基本原理就是將可能重復使用的資料放到記憶體中一次生成,多次使用,避免每次使用都去訪問存盤系統,以使用最廣泛的 Memcache 為例,其基本的架構如下圖所示 ,
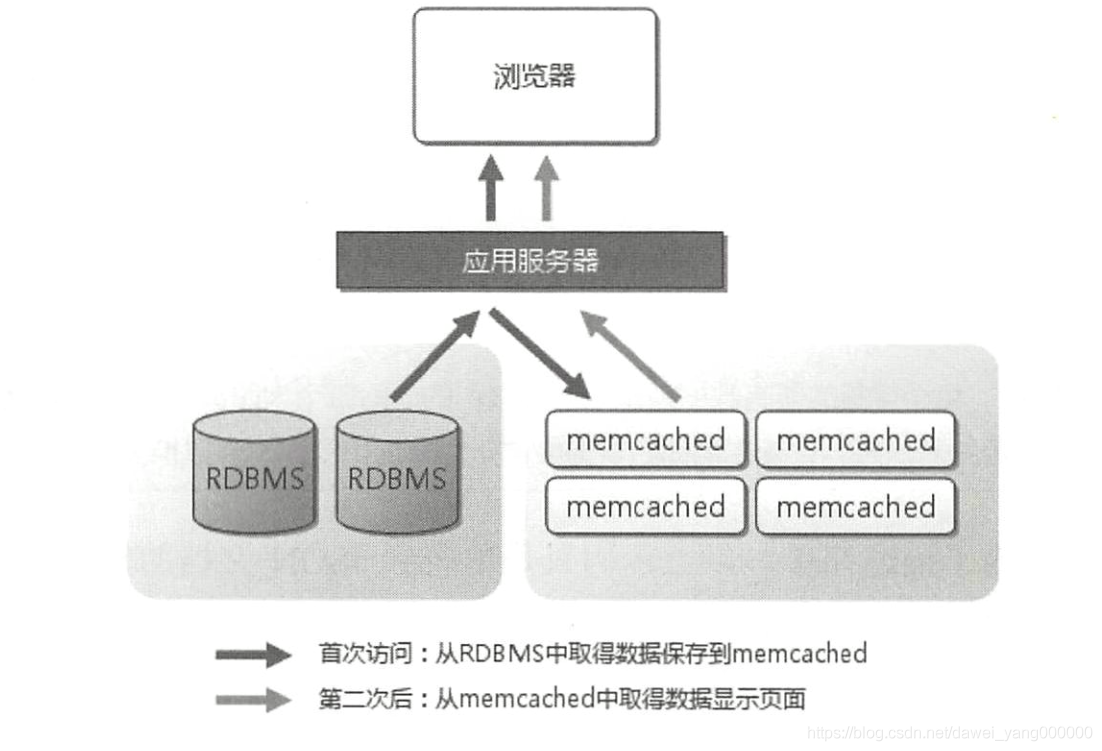
快取能夠帶來性能的大幅提升,以 Memcache 為例,單臺 Memcache 服務器簡單的 key-value 查詢能夠達到 5 萬以上的TPS快取雖然能夠大大減輕存盤系統的壓力,但同時也給架構引入了更多復雜性 ,架構設計時如果沒有針對快取的復雜性進行處理,某些場景下甚至會導致整個系統崩潰
快取穿透
快取穿透是指快取沒有發揮作用,業務系統雖然去快取中查詢資料,但快取中沒有資料,業務系統需要再次去存盤系統中查詢資料,通常情況下有兩種情況
- 存盤資料不存在
- 生成快取資料需要耗費大量時間或資源,
存盤資料不存在
第一種情況是被訪問的資料確實不存在 ,一般情況下,如果存盤系統中沒有某個資料,則不會在快取中存盤相應的資料,這樣就導致用戶查詢的時候,在快取中找不到對應的資料,每次都要去存盤系統中再查詢一遍,然后回傳資料不存在 ,快取在這個場景中并沒有起到分擔存盤系統訪問壓力的作用
通常情況下,業務上讀取不存在的資料的請求量并不會太大,如果出現一些例外情況,例如,被黑客攻擊,故意大量訪問某些不存在資料 的業務,有可能會將存盤系統拖垮
這種情況的解決辦法比較簡單,如果查詢存盤系統的資料沒有找到,則直接設定一個默認值(可以是空值,也可以是具體的值)并存到快取中,這樣第二次讀取快取時就會獲取默認值,而不會繼續訪問存盤系統
快取資料生成耗費大量時間或資源
第二種情況是存盤系統中存在資料,但生成快取資料需要耗費較長時間或耗費大量資源,如果剛好在業務訪 問 的時候快取失效了,那么也會出現快取沒有發揮作用,訪問壓力全部集中在存盤系統上的情況,
典型的就是電商的商品分頁,假設我們在某個電商平臺上選擇“手機”這個類別進行查看, 由于資料巨大,不能把所有資料都快取起來,只能按照分頁進行快取 , 由于難以預測用戶到底會訪問哪些分頁,因此業務上最簡單的就是每次點擊分頁的時候按分頁 計算和生成快取,通常情況下這樣實作是基本滿足要求的,但如果被競爭對手用爬蟲來遍歷的時候,系統性能就可能出現問題
具體的場景如下 :
- 分頁快取的有效期設定為1天,因為設定太長時間,快取不能反映真實的資料
- 通常情況下,用戶不會從第1頁到最后1頁全部看完,一般用戶訪問集中在前10頁, 因此第10頁以后的快取過期失效的可能性很大
- 競爭對手每周來爬取資料 ,爬蟲會將所有分類的所有資料全部遍歷 ,從第 1 頁到最后1頁都會讀取,此時很多分頁快取可能都失效了
- 由于很多分頁都沒有快取資料 , 從資料庫中生成快取資料又非常耗費性能(order by limit操作),因此爬蟲會將整個資料庫全部拖慢
這種情況并沒有太好的解決方案,因為爬蟲會遍歷所有的資料,而且什么時候來爬取也是不確定的,可能每天都來,也可能每周來一次,還可能一個月來一次,我們也不可能為了應對爬蟲而將所有資料永久快取,通常的應對方案要么就是識別爬蟲,然后禁止訪問,但這可能影響SEO和推廣;要么就是做好監控,發現問題后及時處理,因為爬蟲不是攻擊,不會進行暴力破壞,對系統的影響是逐步的,監控發現問題后有時間進行處理
快取雪崩
快取雪崩是指當快取失效(過期)后引起系統性能急劇下降的情況, 當快取過期被清除后, 業務系統需要重新生成快取,因此需要再次訪問存盤系統,再次進行運算,這個處理步驟耗時幾十毫秒甚至上百毫秒,而對于一個高并發 的業務系統來說,幾百毫秒 內 可能會接到幾百上千 個請求,由于舊的快取己經被清除,新的快取還未生成,并且處理這些請求的執行緒都不知道另 外有一個執行緒正在生成快取,因此所有的請求都會去重新生成快取,都會去訪問存盤系統,從 而對存盤系統造成巨大的性能壓力,這些壓力又會拖慢整個系統 , 嚴重的會造成資料庫右機,從而形成一系列連鎖反應,造成整個系統崩潰
快取雪崩的常見解決方法有兩種:
- 更新鎖機制
- 后臺更新機制
更新鎖機制
對快取更新操作進行加鎖保護,保證只有一個執行緒能夠進行快取更新,未能獲取更新鎖的 執行緒要么等待鎖釋放后重新讀取快取,要么就回傳空值或默認值,
對于采用分布式集群的業務系統,由于存在幾十上百臺服務器,即使單臺服務器只有一個執行緒更新快取,但幾十上百臺服務器一起算下來也會有幾十上百個執行緒同時來更新快取,同樣 存在雪崩 的問 題,因此分布式集群的業務系統要完美實作更新鎖機制,需要用到分布式鎖,如ZooKeeper
后臺更新機制
由后臺執行緒來更新快取,而不是由業務執行緒來更新快取,快取本身的有效期設定為永久, 后臺執行緒定時更新快取,
后臺定時機制需要考慮一種特殊的場景,當快取系統記憶體不夠時,會“踢掉” 一些快取資料,從快取被“踢掉”到下一次定時更新快取的這段時間內,業務執行緒讀取快取回傳空值,而業務執行緒本身又不會去更新快取,因此業務上看到的現象就是資料丟了,解決的方式有兩種:
- 定時讀取
后臺執行緒除了定時更新快取,還要頻繁地去讀取快取(例如1秒或100毫秒讀取一次),如果發現快取被“踢了”就立刻更新快取 ,這種方式實作簡單,但讀取時間間隔不能設定得太 長,因為如果快取被踢了,快取讀取間隔時間又太長,則這段時間內業務訪問都拿不到真正 的 資料而是一個空 的快取值,用戶體驗一般 - 訊息佇列通知,
業務執行緒發現快取失效后 ,通過訊息佇列發送一條訊息通知后臺執行緒更新快取,可能會出現多個業務執行緒都發送了 快取更新訊息,但其實對后臺執行緒沒有影響,后臺執行緒收到訊息后更新快取前可以判斷快取是否存在,存在就不執行更新操作,這種方式實作依賴訊息佇列,復雜度會高一些,但快取更新更及時,用戶體驗更好
后臺更新既適應單機多執行緒的場景,也適合分布式集群的場景,相比更新鎖機制要簡單一些,后臺更新機制還適合業務剛上線的時候進行快取預熱,快取預熱指系統上線后,將相關的 快取資料直接加載到快取系統,而不是等待用戶訪問才來觸發快取加載,
快取熱點
雖然快取系統本身的性能比較高,但對于一些特別熱點的資料,如果大部分甚至所有的業務請求都命中同一份快取資料,則這份資料所在的快取服務器的壓力也很大
快取熱點的解決方案就是復制多份快取,將請求分散到多個快取服務器上,減輕快取熱點導致的單臺快取服務器壓力,例如對于粉絲數超過100萬的明星,每條微博都可以生成100份快取,快取的資料是一樣的,通過在快取的key里面加上編號進行區分,每次讀快取時都隨機讀取其中某份快取
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/19177.html
標籤:其他