基于Fabric+IPFS大規模資料上鏈方案
更多區塊鏈技術與應用分類:
區塊鏈應用 區塊鏈開發
以太坊 | Fabric | BCOS | 密碼技術 | 共識演算法 | 位元幣 | 其他鏈
通證經濟 | 傳統金融場景 | 去中心化金融 | 防偽溯源 | 資料共享 | 可信存證
第一章 系統綜述
??區塊鏈是創造信任的機器,但是資料存盤與讀取的效率十分低下,兩者不可兼得的情況下,一種新的方式,既彌補區塊鏈的效率,又能利用其“信任”與“不可篡改”特性,該方案使用區塊鏈+分布式存盤,
??Fabric簡介、適用場景:Hyperledger Fabric的出現是對傳統區塊鏈模型的一種革新,在某種程度上允許創建授權和非授權的區塊鏈,Hyperledger還通過提供一個針對身份識別,可審計、隱私安全和健壯的模型,使得縮短計算周期、提高規模效率和回應各個行業的應用需求成為可能,
??IPFS簡介、適用場景:分布式存盤,
??Fabric+IPFS優點、適用場景:無需全部資料上鏈即可產生信任,
??本系統以后臺服務開發為核心,作為鏈接客戶端、IPFS及Fabric區塊鏈的服務部件,如圖1所示,當大量資料需要可靠實時地存盤,并且在未來需要得到驗證時,必須將資料以某種形式存入區塊鏈,而傳統區塊鏈系統為了“安全”而犧牲“效率”,因此其資料存盤的容量與速率非常低下,因此不能存放大規模資料,基于這種考慮,我們可以利用區塊鏈+分布式存盤的方式解決大規模資料上鏈的問題,將原始資料存于類似IPFS等分布式系統中,并將源檔案的地址存盤于區塊鏈永久保存,用戶可以通過區塊鏈上檔案的地址資訊隨時去獲取這些資料,同時為了保證IPFS上資料不被篡改,必須將檔案的指紋(Hash演算法結果)也一并存入區塊鏈,這樣用戶可以將得到的鏈上資料進行驗證,以確定資料的完整性與可靠性,
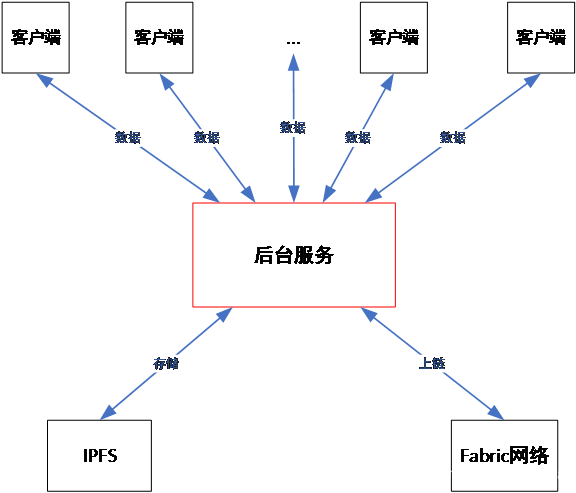
圖1-后臺服務架構
后臺服務采用nodejs撰寫,總體功能可分為兩部分:
- 資料存盤:后臺可將資料打包成塊并向IPFS發送,所有資料存盤在IPFS上,然后將IPFS上檔案存盤地址以及檔案指紋存在Fabric區塊鏈網路上,這樣可公開驗證資料,
- 資料查詢:客戶端可以通過查詢內容的方式,即基于內容檢索得到Fabric以及IPFS上具體資訊,
1.3 運行環境
-
硬體支持:
- 本后臺服務需要Fabric區塊鏈網路以及IPFS節點的支持,
- Fabric若以偽集群的方式運行,則推薦配置為四核cpu記憶體8G,作業系統centos7 /Windows10配置或以上,
- IPFS運行單節點,推薦配置為單核cpu記憶體2G作業系統centos7 /Windows10配置或以上,
- Nodejs服務推薦配置為雙核cpu記憶體2G作業系統centos7 /Windows10配置或以上,
-
軟體支持:
- go-ipfs version: 0.4.18
- nodejs version: 8.1.0
- go version :go1.9.2 windows/amd64
- docke version: 18.09.2
- docker-compose version: 1.23.2
- Hyperledger Fabric version: 1.1.0
- ipfs version: 0.4.18
第二章 功能詳述
2.1 軟體功能流程圖
??該后臺軟體主要處理大規模資料上鏈,因此重在資料存盤和資料查詢兩部分邏輯,整個流程圖如圖2所示,當資料存盤時,后臺服務不斷收到來自客戶端的資料時,每接受一條資料需要先判斷是否是正確的傳輸格式,并統計該客戶端發送資料條數,每個不同的客戶端有唯一ID,資料以ID作為索引鍵值,故以“天”為單位進行資料塊打包,即一天的資料作為一個獨立資料塊,這樣方便管理和查詢,在達到預定義區塊大小(一日的資料量)時對客戶端資料進行分塊打包,每次打包完塊后立即存入IPFS,并獲取IPFS存盤塊的地址,然后,將該資料塊的IPFS地址以及檔案指紋存入Fabric區塊鏈進行保存,
當資料查詢時,客戶端發起請求獲取原始資料,服務啟動Fabric鏈,然后查詢鏈碼是否存在該ID、日期下的IPFS地址資訊,若不存在,這說明不存在資料,否則繼續查詢IPFS,根據IPFS上對應資料塊檔案的Hash地址從IPFS上拿到原始資料,并可以利用Fabric上檔案指紋與IPFS上原始資料進行比對驗證,若兩者一致則可以確定該資料塊未被篡改,

圖2-軟體流程圖
2.2 功能設計詳細描述
1 資料存盤
資料存盤功能實作流程圖如圖3所示,下面是詳細步驟:
(1) 客戶端通過http-post方式以特定資料格式(Json)向后臺服務發送資料
該后端服務會記錄每一個連接的客戶端處發來資料數目,并更新其資料檔案指紋,當達到預設值時,進行打包操作,并使用流的方式向IPFS發送資料,
(2) 資料塊存盤在IPFS上,然后回傳存盤地址
(3) 后臺服務將先前計算的檔案指紋與IPFS檔案存盤地址組合且生成新的一條上鏈資料,然后通過呼叫Fabric鏈碼將資訊存盤在Peer節點賬本上,
(4) Fabric向服務端回傳本次存盤交易的Hash值,
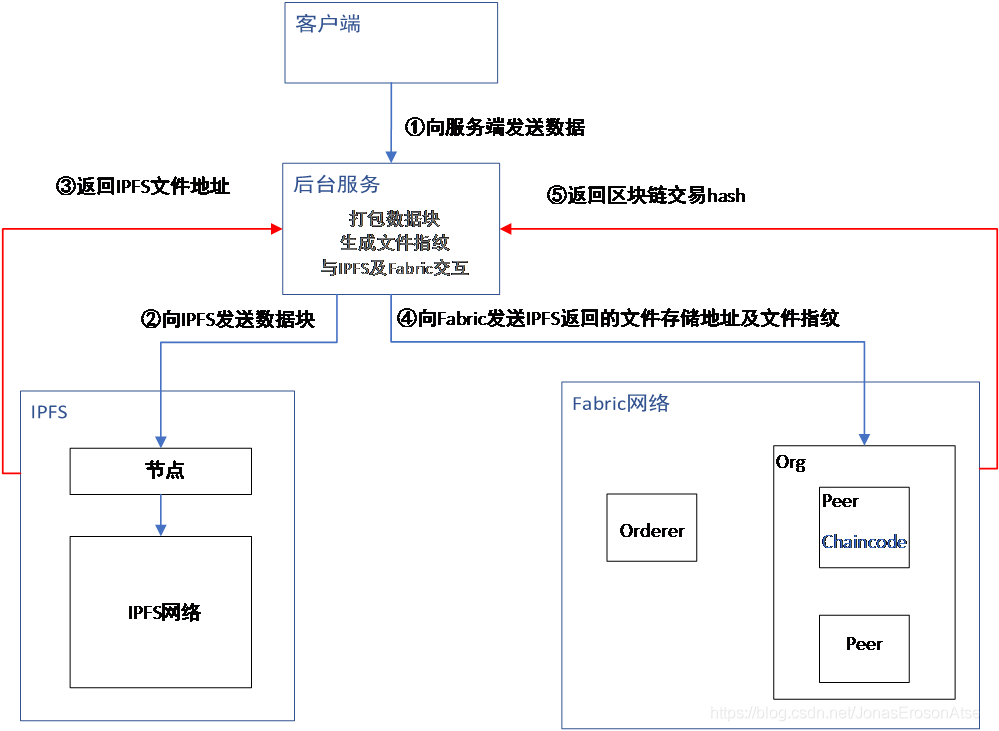 圖3 資料存盤功能實作流程圖
圖3 資料存盤功能實作流程圖
2 資料查詢
資料查詢功能實作流程圖如圖4所示,下面是詳細步驟:
(1) 客戶端通過唯一ID值和日期等內容查詢相關資訊,通過http-get方式向服務后臺請求資料,例如請求url:http://localhost:60003/querydata?obdid=X7777-S6665&date=2019-4-3 ,是用戶查詢的介面,意思是ID為X7777-S6665日期為2019-4-3這天的該日資料塊,
(2) 后臺將會自動啟動Fabric鏈碼容器,執行鏈碼中相應的查詢方法,
(3) Fabric將匹配正確的資料(包含IPFS檔案存盤地址以及檔案指紋)回傳,例如如下資訊:
{“obdid”:“X7777-S6665”,“dataDate”:“2019-4-3”,“ipfsAddr”:“QmfQJujeYWgX2Fn15nSLY7xApG7qQo3imz9S3UVxRcRiTi”,“fileFingerprint”:“21358B2F61C5B5DDD515F7046765BA43E8B643DCE26985BFD45A1BD02E9201A8”}
(4) 后臺通過Fabric資料中的IPFS檔案存盤地址去查詢IPFS網路,并回傳匹配的整個資料塊,
(5) IPFS根據Hash地址回傳對應的整個資料塊的檔案資訊,隨后在服務端可以進行對檔案的驗證,以檢驗存盤資料是否被篡改,
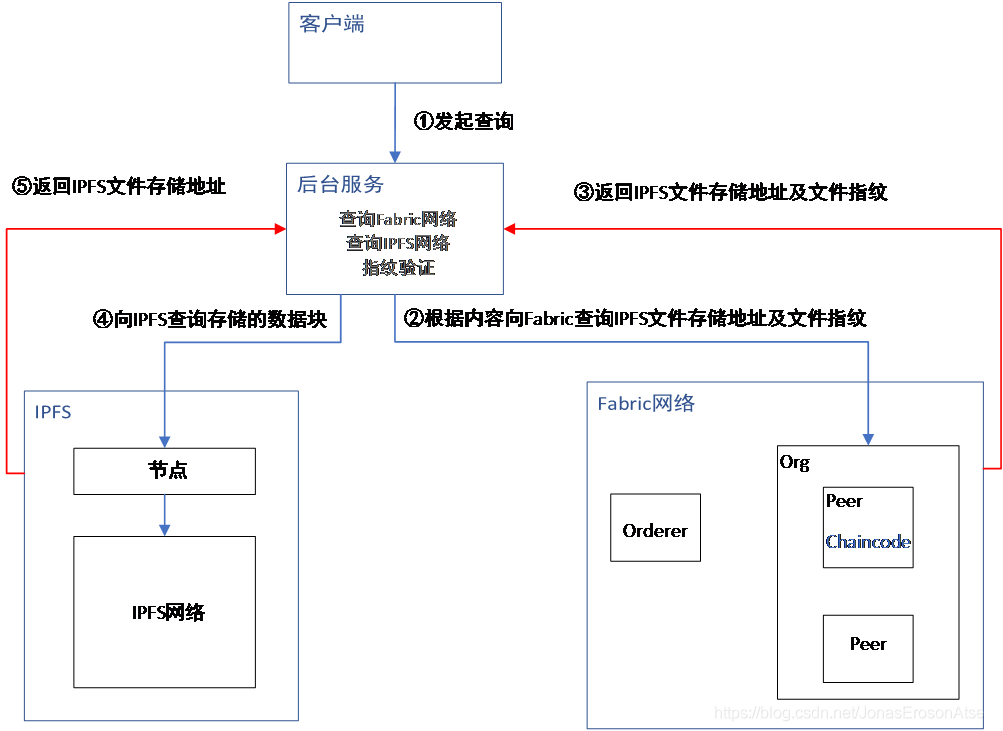
圖4 資料查詢功能實作流程圖
2.3 存盤結構
(1) Fabric賬本結構
Fabric賬本結構指的是Fabric網路中相應通道中Peer節點存盤資料的格式,如圖5所示,Fabric以<k,v>鍵值對的形式存盤及查詢資料,因此唯一ID作為主“鍵”,所有資訊存于該鍵下(采用Json嵌套格式),這樣,每個ID下存盤所有該ID相關的所有資訊,當查詢時,使用唯一ID值便可查出所有該ID下的值,
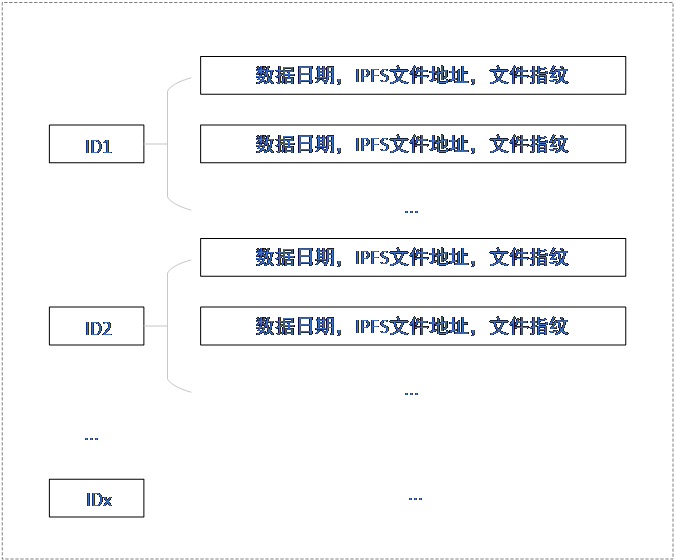
圖5 Fabric賬本結構
(2) IPFS存盤結構:
IPFS中存盤所有源資料的資料塊,資料塊存盤沒有順序,只是每個資料塊與hash地址的關系一一對應,如圖6所示,而hash地址與具體資訊的映射關系存盤于Fabric區塊鏈中,
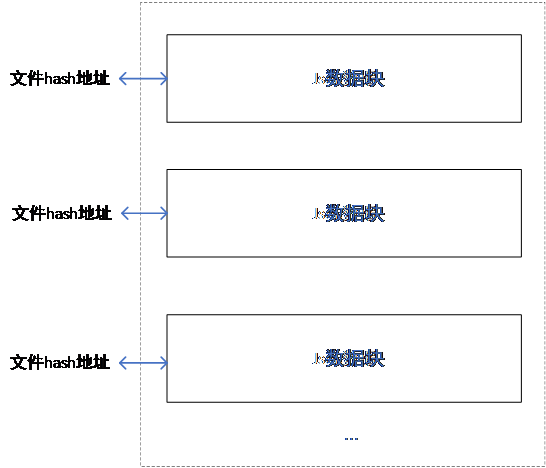
圖6 IPFS存盤結構
第三章 運行說明
3.1 運行說明
(1)客戶端上傳資料
用戶通過http-post方式向服務后臺傳輸Json資料,新客戶端向服務端不斷發送資料,啟動模擬資料服務(每秒向后臺發送一次資料),以車輛obd資料上鏈為例,列印日志如圖7所示:
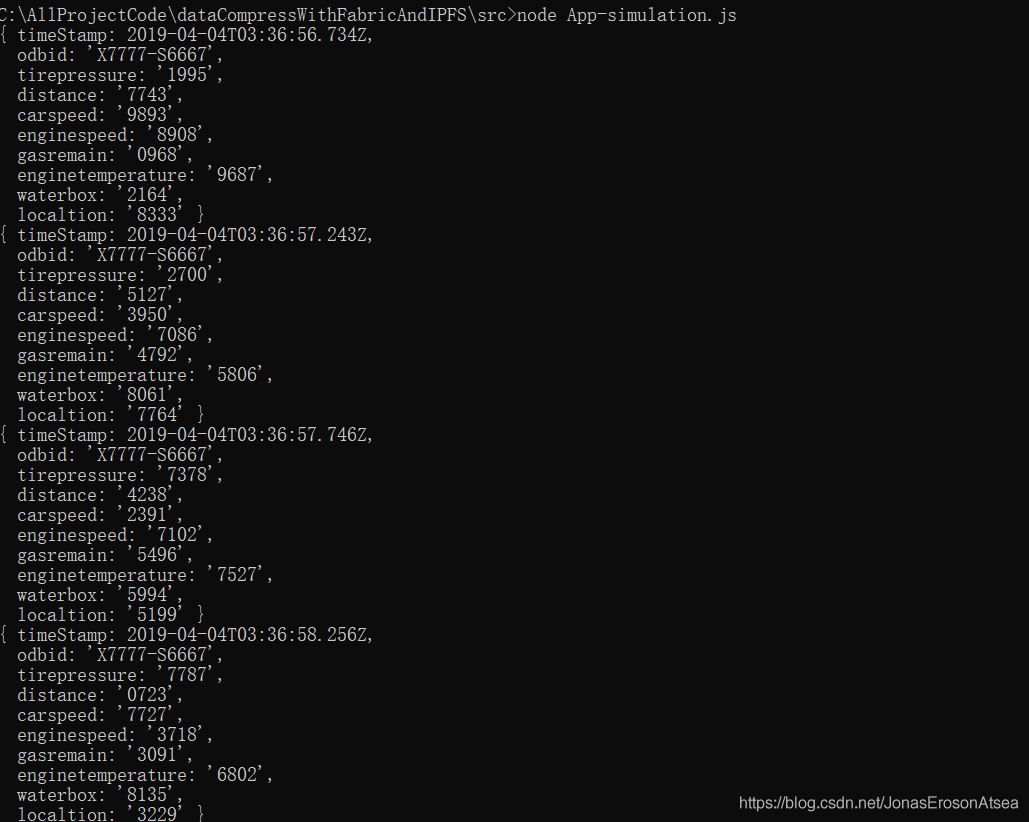
圖7 模擬資料發送日志
(2) 后端接受資料并處理
后臺系統網路全部啟動完畢之后(Fabric網路啟動,IPFS啟動),使用命令運行nodejs后臺程式:node server.js
當資料塊打包完成時,后臺日志如圖8所示:
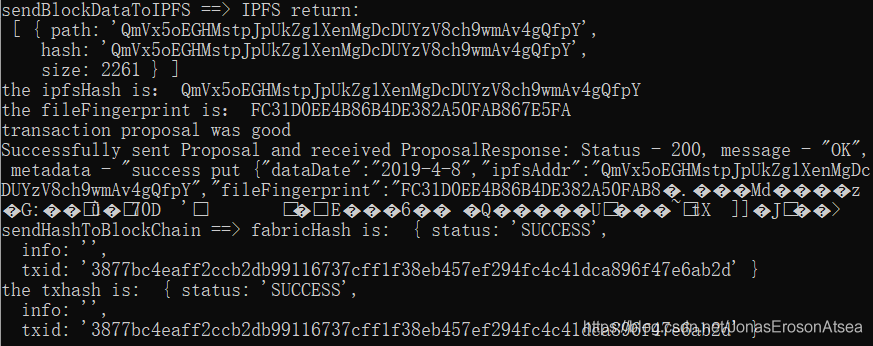
圖8 后臺服務打包區塊時日志
(3) 客戶端查詢/驗證資料
查詢fabric區塊鏈網路上相關資料:通過唯一ID(obdid)以及日期來查詢fabric上檔案存盤記錄,可以得到IPFS上檔案存盤地址ipfsAddr,檔案的指紋哈希fileFingerprint,http-get獲取資料結果如圖9所示:
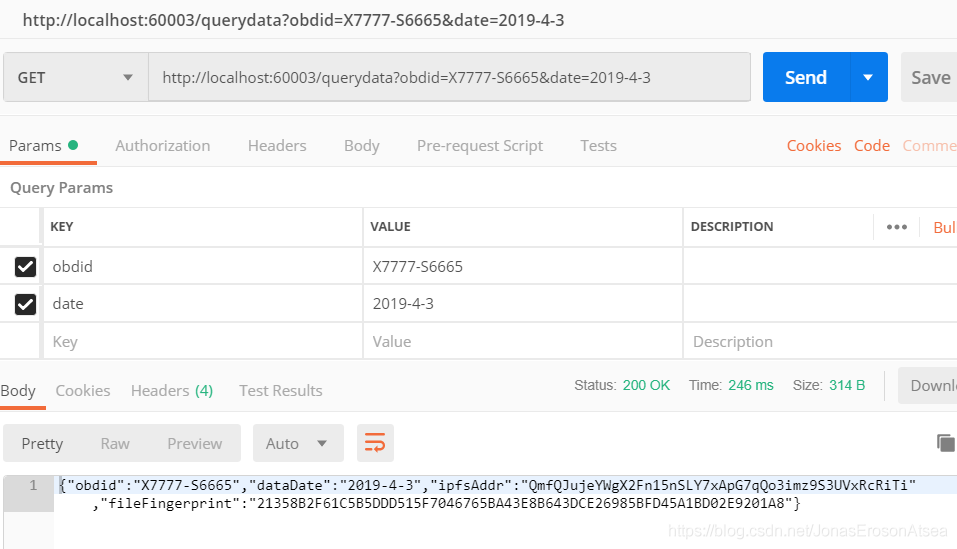
圖9 用戶通過內容獲取Fabric資料
??查詢IPFS上相關資料:將ipfsAddr作為http-post的引數傳給服務器,通過該ipfsAddr可以再次查詢到IPFS上整個資料塊,如圖10所示,客戶端可以對整個資料塊進行指紋驗證,計算資料塊指紋與fileFingerprint引數比較,若一致,則證明資料完整未被篡改,
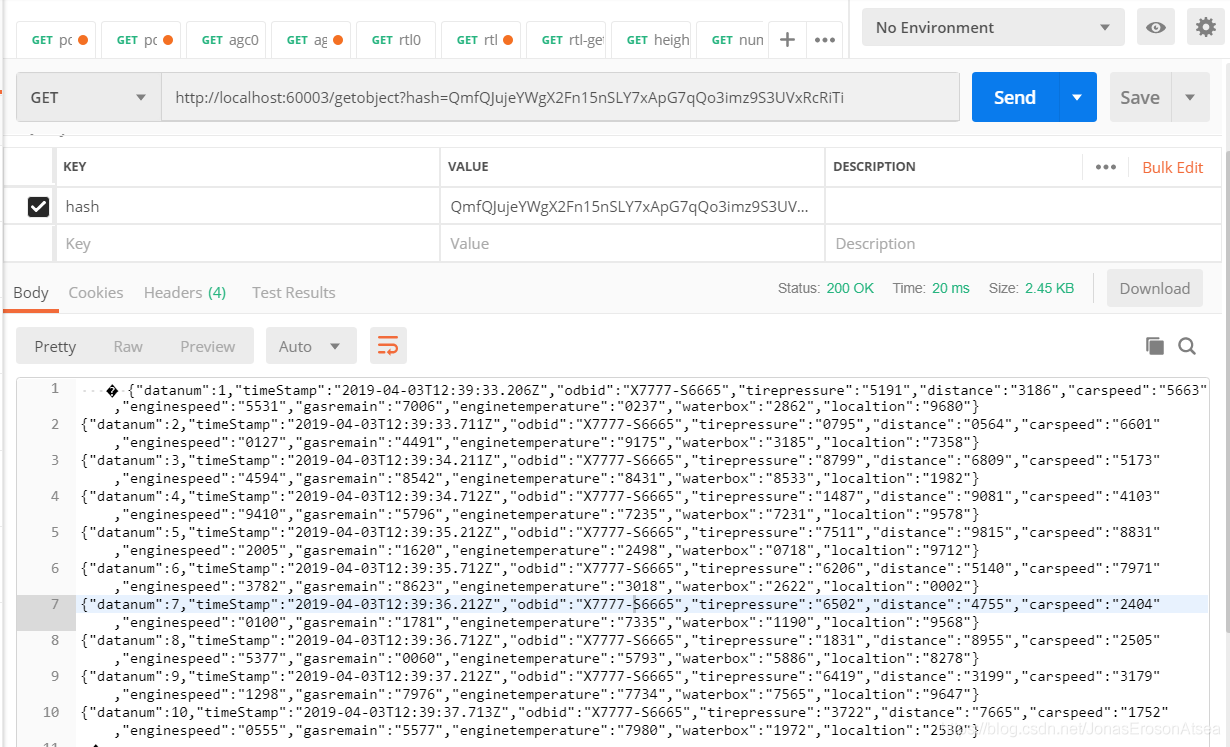
圖10 用戶通過Hash獲取IPFS資料
代碼庫可進行驗證測驗:
https://github.com/wanghaoyi1/dataCompressWithFabricAndIPFS.git
原文鏈接:基于Fabric+IPFS大規模資料上鏈方案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/192524.html
標籤:其他
上一篇:solidity筆記——第一篇