第1章 時間語意
Flink里定義了三種時間語意:Event Time、Ingestion Time、Processing Time,
在整個流計算程序中,他們分別代表事件發生的時間、資料最早進入Flink的時間和資料被Flink算子處理時算子本地的時間,
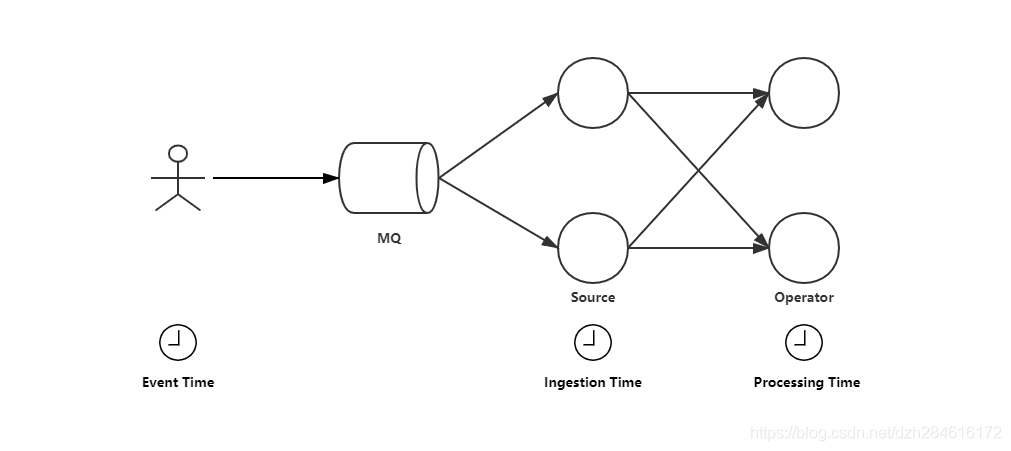
Event Time:事件發生時間,現實世界中資料真實產生的時間,無論資料流在傳輸和計算程序中花了多少時間EventTime是不會變的,它在時間發生時就已經確定,
Ingestion Time:資料最早進入Flink的時間,也就是資料到達Source的時間,Ingest Time同樣不受內部算子計算和資料傳輸效率所影響,
Processing Time:資料進入每個算子時,算子所在機器上的本地時間,Process Time只依賴當前算子所在機器的系統時鐘,
第2章 Timestamp
EventTime模式下,Flink從Source流入的所有資料都會包含Timestamp,這里的所指的Timestamp代表的是事件發生的時間,當然也可以是自定義的Timestamp,但是一定要保證時間戳的遞增性,
舉個例子,在業務上我們經常需要用到的視窗計算,計算某時間端內事件發生的次數:計算近兩周內各地區確診病例的數量,計算近一個小時各模塊的訪問量和用戶點擊量,等等……,這些都需要EventTIme模式下利用Timestamp做視窗計算,
在Flink里,Timestamp被定義為8位元組的long值,每個算子拿到資料時,默認以毫秒精度的Unix時間戳決議這個long值,也就是自1970-01-01 00:00:00.000以來的毫秒數,當然自定義的算子可以自己定義時間戳的決議方式,
但是基于時間的應用,由于每個計算單元的計算能力不同、網路傳輸的速率也不同,而且現今大資料系統都是分布式架構,因為這些種種原因,資料到達Source和每一個計算單元都會存在一定的不確定性,這就是時間亂序問題,接下來我們看看Flink如何解決這種資料的亂序問題:Watermark,
第3章 Watermark
Flink定義了Watermark,它是一種資料元素StreamElement,和普通資料一起在算子之間傳輸,本質上是一個long型別的Timestamp,是一個全域進度指標,
Watermark可以在Source位置發射,也可以在流傳輸的任何算子上產生,并通過拓撲中的運算子傳播,
在FLink流計算程序中,既然資料傳輸會有延遲,資料會產生亂序,那么在我們該在什么時候觸發視窗計算呢?換一個思路,可以這么說:我們該如何知道要等多久才能確定視窗計算的資料都已經全部到達算子了呢?
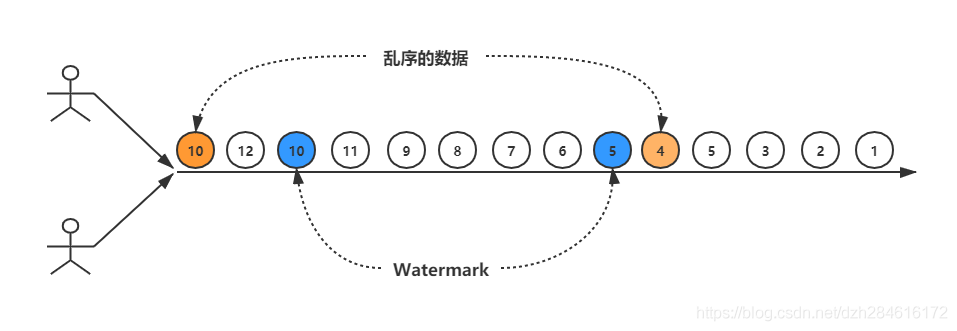
我們來看上面這張圖,Flink利用穿插在資料流當中的Watermark,Watermark讓算子確信不會再有延遲事件到來,從而觸發算子做視窗計算,那實際上在Watermark之后到底還會不會有該視窗的資料被遺漏呢?上面的示意圖就已經解答了這個問題:可能會有,如果Watermark定義的延遲越小,那么存在遺漏可能性就越大;Watermark延遲定義的延遲越大,遺漏的可能性就越小,但是這也意味著,視窗觸發的延遲越久,
所以Watermark在通常情況下,是需要自己根據自己的業務,去實際的測驗調整,達到一個均衡值,在有些情況下,用戶為了降低計算的延遲,又希望不直接舍棄那些被Watermark排除在外的資料,那么可以將這些資料寫入日志或者利用這些資料去修正之前的結果,
最后多一句嘴:基于Processing Time的視窗計算不需要Watermark,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/192879.html
標籤:其他