作者|Renu Khandelwal
編譯|VK
來源|Towards Data Science
在本文中,你將學習如何加載自定義資料和創建影像序列和測驗資料集,作為深度學習模型的輸入,
- Open CV2
- PIL
這里使用的資料集是來自Kaggle的Intel影像分類,
資料集鏈接:https://www.kaggle.com/puneet6060/intel-image-classification/version/2
“Intel影像分類”資料集已分為train、test和Val,我們將僅使用訓練資料集學習如何使用不同的庫加載資料集,
為深度學習模型加載自定義資料集的典型步驟
-
打開影像檔案,檔案的格式可以是JPEG、PNG、BMP等,
-
調整影像大小以匹配深度學習模型的輸入層的輸入大小,
-
將影像像素轉換為浮點資料型別,
-
將影像標準化,使像素值在0到1之間,
-
深度學習模型的影像資料應該是一個numpy陣列或一個張量物件,
自定義影像資料的檔案夾結構
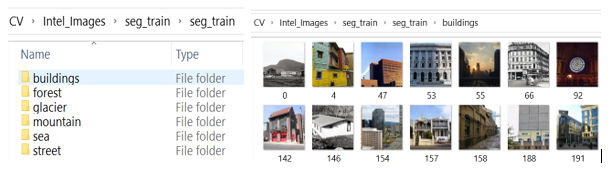
每個類都是一個檔案夾,其中包含該特定類的影像,
使用CV2加載影像資料
匯入所需的庫
import pandas as pd
import numpy as np
import os
import tensorflow as tf
import cv2
from tensorflow import keras
from tensorflow.keras import layers, Dense, Input, InputLayer, Flatten
from tensorflow.keras.models import Sequential, Model
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
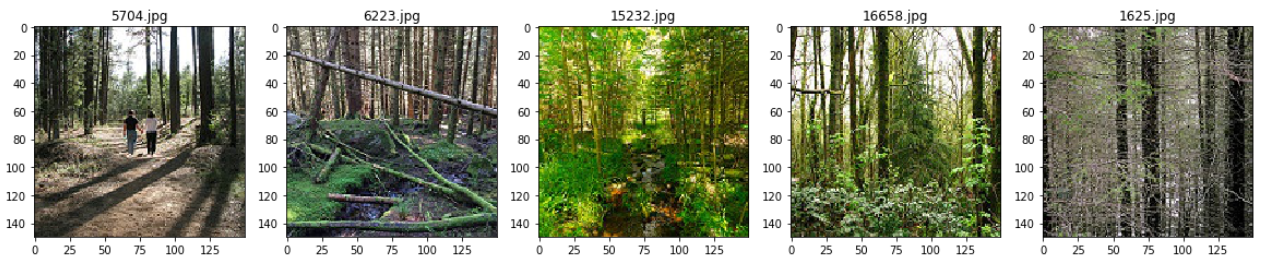
從其中一個檔案夾中隨機輸出五張影像
plt.figure(figsize=(20,20))
test_folder=r'CV\Intel_Images\seg_train\seg_train\forest'
for i in range(5):
file = random.choice(os.listdir(img_folder))
image_path= os.path.join(img_folder, file)
img=mpimg.imread(image_path)
ax=plt.subplot(1,5,i+1)
ax.title.set_text(file)
plt.imshow(img)
設定用于加載資料集的影像維度和源檔案夾
IMG_WIDTH=200
IMG_HEIGHT=200
img_folder=r'CV\Intel_Images\seg_train\seg_train\'
從檔案夾中的影像創建影像資料和標簽
在下面的函式中
-
source檔案夾是包含不同類的影像的輸入引數,
-
從檔案夾中讀取影像檔案并將其轉換為正確的顏色格式,
-
根據模型所需的輸入尺寸調整影像大小
-
將影像轉換為資料型別為float32的Numpy陣列
-
將影像陣列標準化,使值在0和1之間,這有助于更快地收斂,
def create_dataset(img_folder):
img_data_array=[]
class_name=[]
for dir1 in os.listdir(img_folder):
for file in os.listdir(os.path.join(img_folder, dir1)):
image_path= os.path.join(img_folder, dir1, file)
image= cv2.imread( image_path, cv2.COLOR_BGR2RGB)
image=cv2.resize(image, (IMG_HEIGHT, IMG_WIDTH),interpolation = cv2.INTER_AREA)
image=np.array(image)
image = image.astype('float32')
image /= 255
img_data_array.append(image)
class_name.append(dir1)
return img_data_array, class_name
# extract the image array and class name
img_data, class_name =create_dataset(r'CV\Intel_Images\seg_train\seg_train')
將文本標簽轉換為數字編碼
為類的所有唯一值創建字典
target_dict={k: v for v, k in enumerate(np.unique(class_name))}
target_dict

根據字典將類名稱轉換為各自的數值
target_val= [target_dict[class_name[i]] for i in range(len(class_name))]
創建一個簡單的深度學習模型并編譯它
model=tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(IMG_HEIGHT,IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6)
])
encoder.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
我們最終調整資料集來訓練模型,我們可以使用Numpy陣列作為輸入
history = model.fit(x=np.array(img_data, np.float32), y=np.array(list(map(int,target_val)), np.float32), epochs=5)
我們還可以使用tf.cast()將輸入資料轉換為張量來訓練模型,
history = model.fit(x=tf.cast(np.array(img_data), tf.float64), y=tf.cast(list(map(int,target_val)),tf.int32), epochs=5)
我們使用不同的庫加載影像資料集但是我們使用相同的模型來進行進一步的訓練
用PIL加載影像資料
添加附加庫以使用PIL加載影像資料集
from PIL import Image
使用PIL從檔案夾中的影像創建影像資料和標簽
在下面的函式中
-
source檔案夾是包含不同類的影像的輸入引數,
-
使用PIL從檔案夾中打開影像檔案,
-
根據模型所需的輸入尺寸調整影像大小
-
將影像轉換為資料型別為float32的Numpy陣列
-
標準化影像陣列以加快收斂,
def create_dataset_PIL(img_folder):
img_data_array=[]
class_name=[]
for dir1 in os.listdir(img_folder):
for file in os.listdir(os.path.join(img_folder, dir1)):
image_path= os.path.join(img_folder, dir1, file)
image= np.array(Image.open(image_path))
image= np.resize(image,(IMG_HEIGHT,IMG_WIDTH,3))
image = image.astype('float32')
image /= 255
img_data_array.append(image)
class_name.append(dir1)
return img_data_array , class_name
PIL_img_data, class_name=create_dataset_PIL(img_folder)
將文本標簽轉換為數字編碼
下面是我們在CV2中使用的代碼
target_dict={k: v for v, k in enumerate(np.unique(class_name))}
target_val= [target_dict[class_name[i]] for i in range(len(class_name))]
創建和編譯一個簡單的深度學習模型
model=tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(IMG_HEIGHT,IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6)
])
encoder.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
我們最終調整資料集來訓練模型,我們可以使用Numpy陣列作為輸入
history = model.fit(x=np.array(PIL_img_data, np.float32), y=np.array(list(map(int,target_val)), np.float32), epochs=5)
我們還可以使用tf.cast()將輸入資料轉換為張量來訓練模型,
history = model.fit(x=tf.cast(np.array(PIL_img_data), tf.float64), y=tf.cast(list(map(int,target_val)),tf.int32), epochs=5)
除了幾個步驟外,使用CV2和PIL加載資料集的程序是相同的,
現在這將幫助你使用CV2和PIL庫加載資料集,
這里提供了使用CV2和PIL加載資料集的代碼:https://github.com/arshren/Load_Dataset
在下一篇文章中,我們將使用以下的庫來加載資料集,
- Keras
- tf.data
原文鏈接:https://towardsdatascience.com/loading-custom-image-dataset-for-deep-learning-models-part-1-d64fa7aaeca6
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/194452.html
標籤:其他