作者|Alvira Swalin
編譯|VK
來源|Medium
第一部分主要討論回歸度量

在后現代主義的世界里,相對主義以各種各樣的形式,一直是最受歡迎和最受詬病的哲學學說之一,相對主義認為,沒有普遍和客觀的真理,而是每個觀點都有自己的真理,
在這篇文章中,我將根據目標和我們試圖解決的問題來討論每個錯誤度量的用處,當有人告訴你“美國是最好的國家”時,你應該問的第一個問題是,這種說法是基于什么,我們是根據每個國家的經濟狀況,還是根據它們的衛生設施等來判斷它們?
類似地,每個機器學習模型都試圖使用不同的資料集來解決目標不同的問題,因此,在選擇度量標準之前了解背景是很重要的,
最常用的度量
在第一篇博客中,我們將只討論回歸中的度量,
回歸度量
大多數博客都關注分類指標,比如精確性、召回率、AUC等,為了改變這一點,我想探索各種指標,包括回歸中使用的指標,MAE和RMSE是連續變數最常用的兩種度量方法,
RMSE(均方根誤差)
它表示預測值和觀測值之間差異的樣本標準差(稱為殘差),從數學上講,它是使用以下公式計算的:
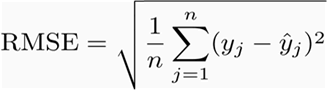
MAE
MAE是預測值和觀測值之間絕對差的平均值,MAE是一個線性分數,這意味著所有的個體差異在平均值中的權重相等,例如,10和0之間的差是5和0之間的差的兩倍,然而,RMSE的情況并非如此,我們將進一步詳細討論,從數學上講,MAE是使用以下公式計算的:
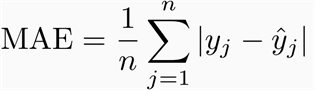
你應該選哪一個?為什么?
好吧,理解和解釋MAE是很容易的,因為它直接取偏移量的平均值,與此對比,RMSE比MAE懲罰更高的差異,
讓我們用兩個例子來理解上面的陳述:
案例1:實際值=[2,4,6,8],預測值=[4,6,8,10]
案例2:實際值=[2,4,6,8],預測值=[4,6,8,12]
案例1的MAE=2,案例1的RMSE=2
病例2的MAE=2.5,病例2的RMSE=2.65
從上面的例子中,我們可以看到RMSE比MAE對最后一個值預測的懲罰更重,通常,RMSE的懲罰高于或等于MAE,它等于MAE的唯一情況是當所有的差異都等于或為零(在情況1中,所有觀測值的實際和預測之間的差異都為2),
然而,即使在更為復雜和偏向于更高的偏差之后,RMSE仍然是許多模型的默認度量,因為用RMSE定義的損失函式是光滑可微的,并且更容易執行數學運算,
雖然這聽起來不太令人愉快,但這是一個非常重要的原因,使它非常受歡迎,我將試著用數學的方法解釋上面的邏輯,
讓我們在一個變數中建立一個簡單的線性模型:y=mx+b
在這里,我們試圖找到“m”和“b”,我們有資料(x,y),
如果我們用RMSE定義損失函式(J):那么我們可以很容易得到m和b的梯度(使用梯度下降的作業原理)
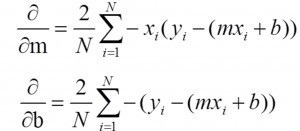
上述方程的求解比較簡單,但是卻不適用于MAE,
然而,如果你只想從解釋的角度比較兩個模型,那么我認為MAE是一個更好的選擇,需要注意的是,RMSE和MAE的單位都與y值相同,因為RMSE的公式進行了開根操作,RMSE和MAE的范圍是從0到無窮大,
注意:MAE和RMSE之間的一個重要區別是,最小化一組數字上的平方誤差會得到平均值,最小化絕對誤差會得到中值,這就是為什么MAE對例外值是健壯的,而RMSE不是,
R方(R^2)與調整R方
R方與調整R方通常用于解釋目的,并解釋所選自變數如何很好地解釋因變數的可變性,
從數學上講,R方由以下公式給出:
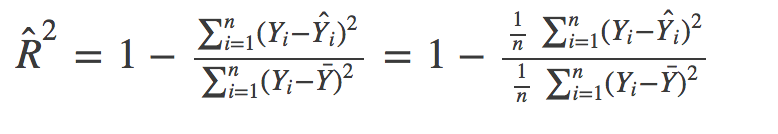
分子是MSE(殘差平方的平均值),分母是Y值的方差,MSE越高,R方越小,模型越差,
調整R方
與R方一樣,調整R方還顯示了曲線或直線的擬合程度,但會根據模型中項的變化進行調整,公式如下:
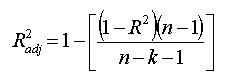
其中n是樣本總數,k是變數數,調整R方始終小于或等于R方
為什么要選擇調整R方而不是R方
常規的R方存在一些問題,可以通過調整R方來解決,調整R方將考慮模型中附加項所增加的邊際改進,所以如果你加上有用的資料,它會增加,如果你加上不那么有用的變數,它會減少,
然而,R方會隨著資料的增加而增加,但是模型并沒有任何改進,用一個例子來理解這一點會更容易,

這里,情況1是一個簡單的情況,我們有5個(x,y)的觀測值,在案例2中,我們還有一個變數,它是變數1的兩倍(與var 1完全相關),在案例3中,我們在var2中產生了一個輕微的擾動,使得它不再與var1完全相關,
因此,如果我們為每一種情況擬合簡單的普通最小二乘(OLS)模型,那么在邏輯上,我們就不會為情況2和情況3提供關于情況1的任何額外或有用的資訊,因此,我們的度量值在這些模型上不應該增加,對于情況2和情況3,R方會增加或與之前相等,調整R方可以解決這個問題,在情況2和情況3調整R方會減少,讓我們給這些變數(x,y)一些數字,看看Python中得到的結果,
注:模型1和模型2的預測值都是相同的,因此,R方也將是相同的,因為它只取決于預測值和實際值,

從上表中,我們可以看到,盡管我們沒有在案例1和案例2中添加任何附加資訊,但R方仍在增加,而調整R方顯示出正確的趨勢(對更多變數的模型2進行懲罰)
調整R方與RMSE的比較
對于上一個示例,我們將看到案例1和案例2的RMSE與R方類似,在這種情況下,調整后的R方比RMSE做得更好,RMSE的范圍僅限于比較預測值和實際值,
此外,RMSE的絕對值實際上并不能說明模型有多糟糕,它只能用于兩個模型之間的比較,而調整R方很容易做到這一點,例如,如果一個模型的調整R方為0.05,那么它肯定很差,
然而,如果你只關心預測的準確性,那么RMSE是最好的,它計算簡單,易于微分,是大多數模型的默認度量,
常見的誤解是:我經常在網上看到R的范圍在0到1之間,這實際上不是真的,R方的最大值為1,但最小值可以為負無窮大,考慮這樣一種情況,即模型預測所有觀測值的高度負值,即使y的實際值為正值,在這種情況下,R方將小于0,這是極不可能的情況,但這種可能性仍然存在,
NLP中的一個度量
如果你對NLP感興趣,這里有一個有趣的度量,
BLEU
它主要用于衡量機器翻譯相對于人工翻譯的質量,它使用一種改進的精度度量形式,
計算BLEU分數的步驟:
-
將句子轉換成單元、雙元、三元和四元(unigrams, bigrams, trigrams, and 4-grams)
-
對于大小為1到4的n-gram計算精度
-
取所有這些精度值的加權平均值的指數
-
乘以簡短的懲罰(稍后解釋)
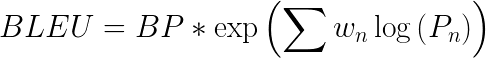
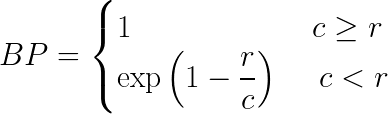
這里BP是簡潔性懲罰,r和c是參考詞和候選詞的個數,w是權重,P是精度值
例子:
參考翻譯:The cat is sitting on the mat
機器翻譯1:On the mat is a cat
機器翻譯2:There is cat sitting cat
讓我們把以上兩個譯文計算BLEU分數進行比較,
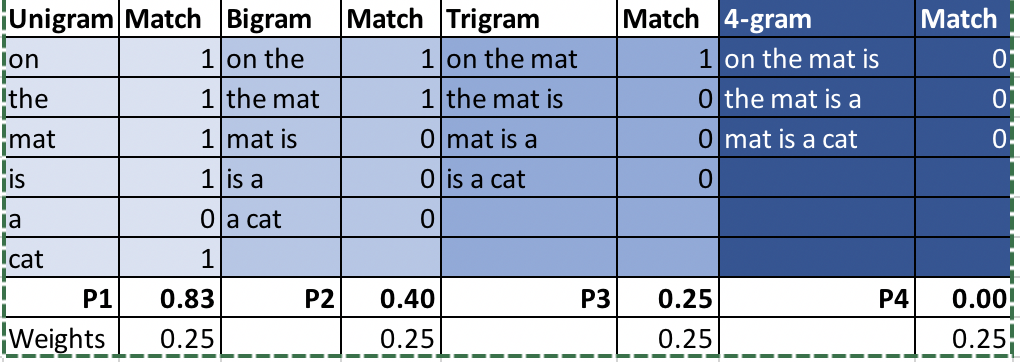
我用的是nltk.translate.bleu
最終結果:BLEU(MT1)=0.454,BLEU(MT2)=0.59
為什么我們要加上簡潔性懲罰?
簡潔性懲罰懲罰候選短于他們的參考翻譯,例如,如果候選是“The cat”,那么它對于unigram和bigram將具有高精度,因為這兩個詞在參考翻譯中也是以相同的順序出現,然而,長度太短,并沒有真正反映出實際意義,
有了這個簡短性懲罰,高分的候選譯文現在必須在長度、單詞和單詞順序方面與參考匹配,
原文鏈接:https://medium.com/usf-msds/choosing-the-right-metric-for-machine-learning-models-part-1-a99d7d7414e4
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/194790.html
標籤:其他