
AI 在各大領域的發展有目共睹,而作為人工智能皇冠上的明珠--自然語言處理卻成果了了,大多實作或者以半成品的形式躺在實驗室中,或者僅僅作為某個產品的輔助功能,
而這一情況在 BERT 出現后出現了很大的改善,
本文就是通過一款工具的介紹,帶大家了解下 BERT 對 NLP 實際效果帶來的巨大改變,
(目前工具還在內測中,評測君暗中觀察到,每隔段時間都會有非常大的更新)
話不多說,先上截圖:
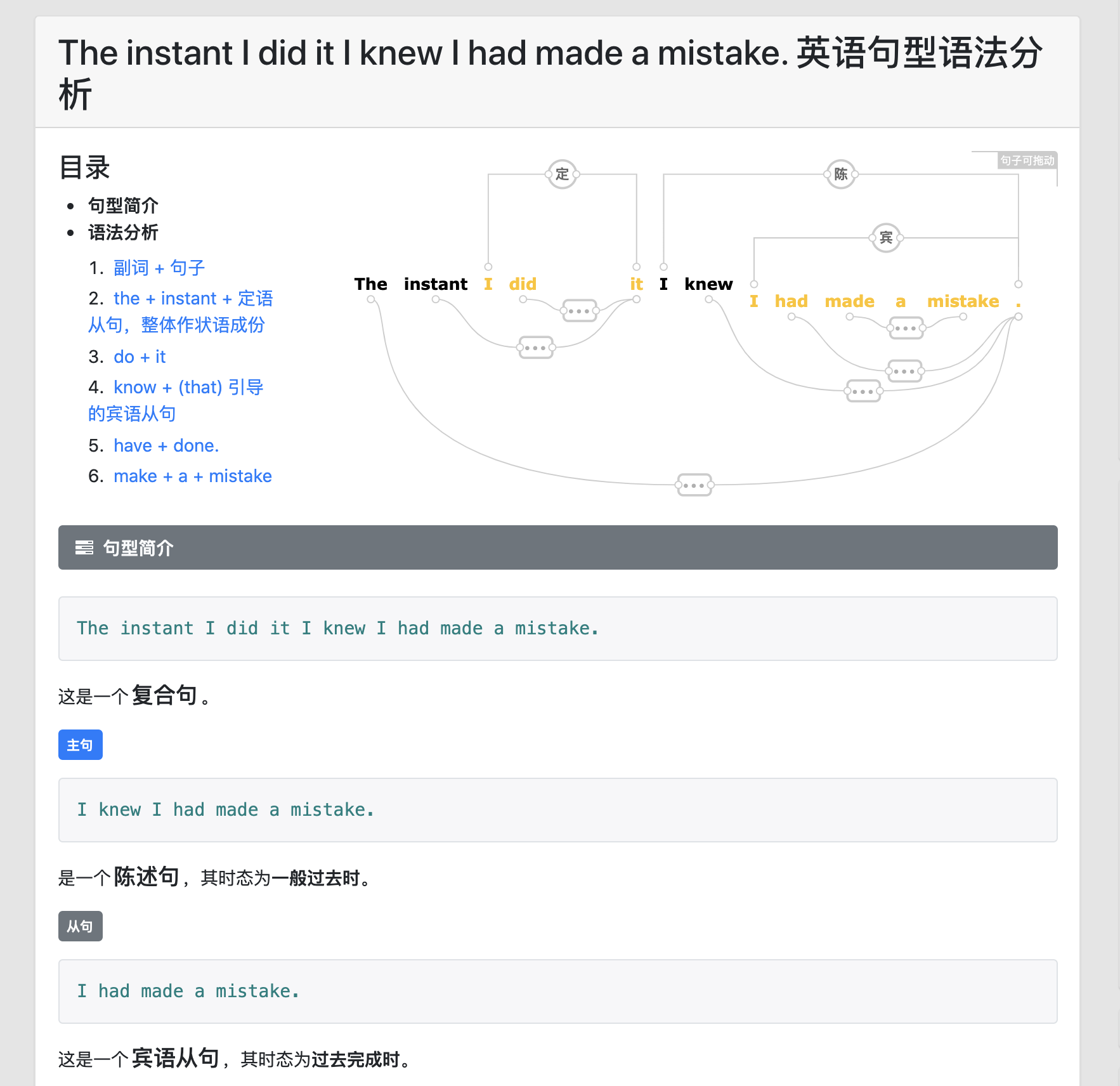
真的是讓人驚訝!
在目前的工業 NLP 中,數個類似 詞性標注、命名物體識別、物體關系抽取、內容理解、意圖識別等任務雖然處于不斷進步中,但依然距離實際應用有較大距離,主要是 Bad case 太多、結果太不可預測、人工干預乏力,很難相信,在這樣的技術屏障下,通過使用 BERT 演算法,這個工具依然實作了巨大的突破,
大家可以自行前往體驗:
http://enpuz.com/The-instant-I-did-it-I-knew-I-had-made-a-mistake.=
這里提醒下,目前這個工具限制所輸入的英陳述句子長度,經過評測君體驗,不算標點差不多是 12 個單詞左右,雖然足夠滿足學生的需求,但在現實環境中,不得不說是一個較大的限制,比較令人遺憾,希望未來會放開限制!
如下是轉自 Standford Parser 的演算法截圖:
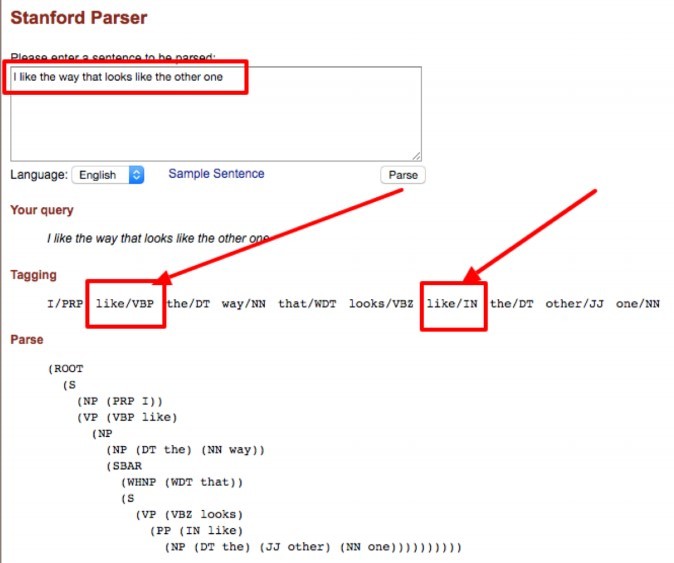
這里可以對應的看下使用 BERT 演算法帶來的變化:
能力提升:
1. 支持識別句子型別,如陳述句、疑問句、祈使句,
2. 支持分析復雜句的句子結構,如主語從句、賓語從句、定語從句、表語從句、狀語從句,
3. 支持分析并列句的句子結構,如并列句、轉折句、讓步句,
4. 支持分析主句、從句的時態,
5. 支持分析句子中包含的核心語法、固定搭配、動詞短語,
6. 支持疑問句、倒裝句、省略句等特殊句子的內在結構,
7. 支持識別人名、地名,
8. 能有效處理未登錄詞,
9. 能給出重點短語、固定搭配的翻譯
10. 能給出重點短語、固定搭配的例子、用法、語法擴展
11. 能給出重點短語、固定搭配對應的相似短語
12. 具有較強的命名物體識別能力,
13. 具有較強的關系提取能力,
14. 具有完整的意圖識別能力,
15. 具有較強的推理能力,
16. 具有一定的自學習能力,
可能的不足:
1. 長度限制,只支持 12 個單詞,
2. 不支持成分缺失較多的口語,
3. 單詞、短語翻譯覆寫率不足,
4. 缺少反義詞、近義詞等常見詞典工具具備的資料,
5. 內容表現單一,
當然3、4、5跟演算法本身關系不是特別大,
總結
作為少有的以 nlp 能力為主打的產品,盡管有諸如長度、不支持口語等限制,評測君還是比較期待這款工具未來的變化,
大家也可以去體驗:http://enpuz.com/
如果評測內容不實不準,歡迎私信,
碼字不易,求贊求推薦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/194797.html
標籤:其他
上一篇:用PyTorch對Leela Zero進行神經網路訓練
下一篇:PYTHON替代MATLAB在線性代數學習中的應用(使用Python輔助MIT 18.06 Linear Algebra學習)