文章目錄
- 1. 讀入文本
- 2. 分詞
- 3. 計數
- 4. 排序
- 5. 添加用戶字典
以《神雕俠侶》為例:
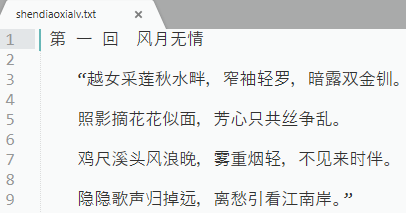
使用 jieba.posseg獲取詞性,人名的詞性為 nr
1. 讀入文本
import jieba.posseg as psg
with open('shendiaoxialv.txt',encoding='utf-8') as f:
text = f.readlines()
print(text[:10])
輸出:
['\ufeff 第 一 回\u3000風月無情\n', '\n', ' “越女采蓮秋水畔,窄袖輕羅,暗露雙金釧,\n', '\n', ' 照影摘花花似面,芳心只共絲爭亂,\n', '\n', ' 雞尺溪頭風浪晚,霧重煙輕,不見來時伴,\n', '\n', ' 隱隱歌聲歸掉遠,離愁引看江南岸,”\n', '\n']
len(text)
輸出:16741,文本有1萬6千多行
2. 分詞
for t in text:
res = psg.cut(t)
print([(item.word, item.flag) for item in res])
輸出:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\computer~1\AppData\Local\Temp\jieba.cache
Loading model cost 1.023 seconds.
Prefix dict has been built succesfully.
[('\ufeff', 'x'), (' ', 'x'), ('第', 'm'), (' ', 'x'), ('一', 'm'), (' ', 'x'), ('回', 'v'), ('\u3000', 'x'), ('風月', 'n'), ('無情', 'n'), ('\n', 'x')]
[('\n', 'x')]
[(' ', 'x'), (' ', 'x'), (' ', 'x'), (' ', 'x'), ('“', 'x'), ('越女', 'nr'), ('采蓮', 'nr'), ('秋水', 'nr'), ('畔', 'ng'), (',', 'x'), ('窄', 'a'), ('袖輕羅', 'i'), (',', 'x'), ('暗露', 'v'), ('雙金釧', 'nr'), (',', 'x'), ('\n', 'x')]
[('\n', 'x')]
[(' ', 'x'), (' ', 'x'), (' ', 'x'), (' ', 'x'), ('照影', 'n'), ('摘花', 'n'), ('花', 'v'), ('似面', 'd'), (',', 'x'), ('芳心', 'n'), ('只', 'm'), ('共絲', 'n'), ('爭亂', 'v'), (',', 'x'), ('\n', 'x')]
[('\n', 'x')]
[(' ', 'x'), (' ', 'x'), (' ', 'x'), (' ', 'x'), ('雞尺', 'n'), ('溪頭', 'n'), ('風浪', 'n'), ('晚', 'tg'), (',', 'x'), ('霧', 'n'), ('重煙', 'n'), ('輕', 'd'), (',', 'x'), ('不見', 'v'), ('來時', 't'), ('伴', 'v'), (',', 'x'), ('\n', 'x')]
3. 計數
dict = {}
for t in text:
res = psg.cut(t)
for item in res:
if item.flag == 'nr' and item.word in dict:
dict[item.word] += 1
elif item.flag == 'nr' and item.word not in dict:
dict[item.word] = 1
print(dict)
輸出:
{'越女': 1, '采蓮': 3, '秋水': 3, '雙金釧': 1, '水蒙蒙': 1, '歐陽修': 2, ..省略.. '杜': 1, '須髯戟': 1, '掌力直': 1, '后平飛': 1, '古語云': 1, '秦失其鹿': 1, '冷森森': 1, '子雙掌': 1, '掌力擊': 1, '齊口': 1, '蒼猿': 2, '葉': 1, '秋風': 1, '秋月明': 1, '屠龍記': 1}
4. 排序
name_count = sorted(dict.items(), key=lambda x : x[1], reverse=True)
print(name_count[:30])
輸出:頻次最高的前30位人物
[('楊', 4749), ('小龍女', 2003), ('郭靖', 972), ('李莫愁', 938), ('武功', 932),
('黃蓉', 871), ('陸無雙', 574), ('周伯通', 554), ('趙志敬', 482), ('郭襄', 386),
('郭芙', 366), ('裘千尺', 325), ('郭', 283), ('耶律齊', 272), ('尹志平', 259),
('歐陽鋒', 251), ('武三通', 240), ('黃藥師', 239), ('楊過心', 239), ('公孫止', 234),
('尼摩星', 229), ('程英', 226), ('武修文', 226), ('武氏兄弟', 206), ('朱子柳', 203),
('尹克西', 201), ('楊過見', 188), ('洪七公', 186), ('孫婆婆', 185), ('明白', 173)]
發現第一的人名是 楊,而不是楊過
5. 添加用戶字典
import jieba
jieba.load_userdict('mydict.txt')
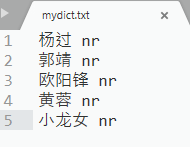
再次運行程式
最后輸出結果:
[('楊過', 4586), ('小龍女', 2010), ('郭靖', 982), ('李莫愁', 938), ('武功', 932),
('黃蓉', 932), ('陸無雙', 574), ('周伯通', 554), ('趙志敬', 482), ('郭襄', 386),
('郭芙', 366), ('裘千尺', 325), ('郭', 282), ('耶律齊', 272), ('尹志平', 259),
('歐陽鋒', 251), ('武三通', 240), ('黃藥師', 239), ('楊過心', 239), ('公孫止', 234),
('尼摩星', 229), ('程英', 226), ('武修文', 226), ('武氏兄弟', 206), ('朱子柳', 203),
('尹克西', 201), ('楊過見', 188), ('洪七公', 186), ('孫婆婆', 185), ('明白', 173)]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/195300.html
標籤:其他