作者|Devyanshu Shukla
編譯|Flin
來源|medium

在這篇文章中,我們將討論關于語言模型(LM)的所有內容
- 什么是LM
- LM的應用
- 如何生成LM
- LM的評估
介紹
NLP中的語言模型是計算句子(單詞序列)的概率或序列中下一個單詞的概率的模型,即
句子的概率:
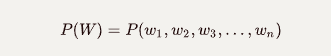
下一個單詞的概率:
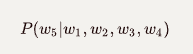
語言模型 v/s 字嵌入
語言模型常常與單詞嵌入混淆,主要的區別在于,在語言模型中,單詞順序很重要,因為它試圖捕捉單詞之間的背景關系,而在單詞嵌入的情況下,只捕捉語意相似度(https://en.wikipedia.org/wiki/Semantic_similarity) ,因為它是通過預測視窗中的單詞來訓練的,而不管順序如何,
語言模型的應用
語言是NLP的主要組成部分,在很多地方都有使用,比如,
- 情感分析
- 問答
- 總結
- 機器翻譯
- 語音識別
生成語言模型
有不同的方法來生成語言模型,讓我們逐一查看它們,
使用N-grams
N-grams(https://en.wikipedia.org/wiki/N-gram) 是給定語料庫中N個單詞的序列,對于“I like pizza very much”這句話,bigram將是 ‘I like’, ‘like pizza’, ‘pizza very’ 和 ‘very much’,
比方說,我們有一個句子‘students opened their’,我們想找到它的下一個單詞,比如w,使用4-gram,我們可以用下面的方程來表示上面的問題,這個方程回傳‘w’是下一個單詞的概率,
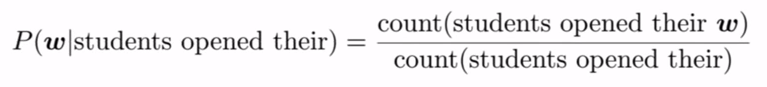
這里,count(X)表示X出現在語料庫中的時間,
對于我們的LM,我們必須計算并存盤整個語料庫中的所有n-grams,隨著語料庫越來越大,這需要大量的存盤空間,假設,我們的LM給出了一個單詞串列,以及它們成為下一個單詞的概率,現在,我們可以抽樣從給定串列中選擇一個單詞,
可以看出,對于一個N-gram,下一個單詞總是取決于句子的最后N-1個單詞,因此,當我們添加更多的單詞時,句子的背景關系和依賴關系就會丟失,
“Today the price of gold per ton,while production of shoe lasts and shoe industry,the bank intervened just after it considered and rejected an IMF demand to rebuild depleted European stocks, sept 30th end primary 76 cts a share.’’
上面的文字是用商業和金融新聞語料庫中的N-grams(N=3)生成的,它符合語法知識但不連貫,因為我們只考慮最后兩個單詞來預測下一個單詞,
這種方法也容易受到稀疏性問題的影響,當單詞“w”在給定的句子之后從未出現,就會出現稀疏性問題,因此“w”的概率始終為0,
使用神經網路
為了使用神經網路生成LM,我們考慮使用一個固定的視窗,即每一次的單詞數都固定,如下圖所示,然后以獨熱向量的形式表示單詞,并與詞嵌入向量相乘,連接以創建矩陣e,然后將該矩陣展平并通過隱藏層,最后使用softmax函式輸出,
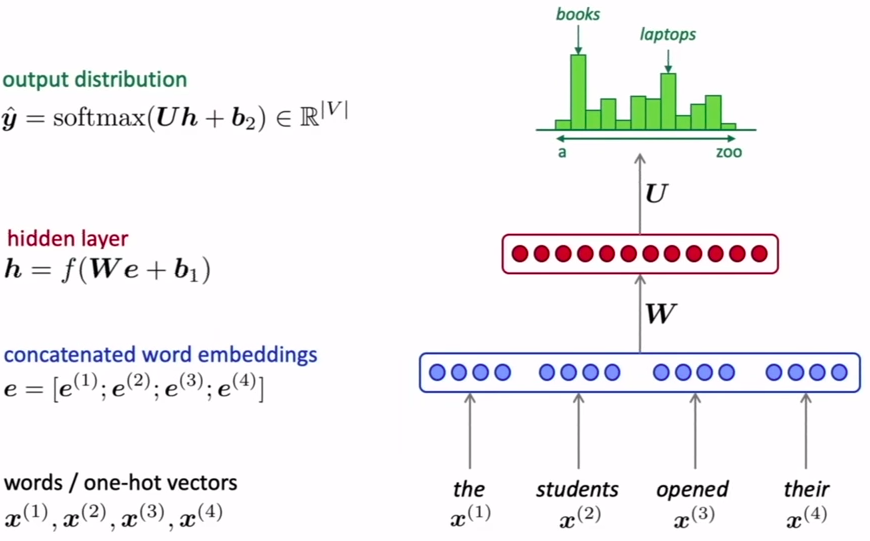
該方法解決了稀疏性問題,與N-grams相比不需要太多存盤空間,但也存在一些自身的問題,由于神經網路使用固定的輸入視窗,因此由該模型生成的文本長度是固定的,因此使用起來不太靈活,隨著視窗大小的增大,模型的大小也隨之增大,從而變得效率低下,
使用長-短期記憶網路(LSTM)
為了解決固定輸入長度問題,我們使用遞回神經網路(RNNs),正如我們在N-grams方法中看到的,N-grams方法缺少長期依賴,如果我們使用vanilla-RNNs(https://medium.com/@apiltamang/unmasking-a-vanilla-rnn-what-lies-beneath-912120f7e56c) ,由于RNNs中的梯度消失,我們仍然會有相同的長期依賴問題,然而,一種稱為LSTM的特殊RNN解決了上述問題,
LSTMs能夠學習長期依賴關系,它們是由Hochreiter&Schmidhuber(1997)(http://www.bioinf.jku.at/publications/older/2604.pdf) 提出的,并在隨后的作業中被許多人改進和推廣,
所有的RNNs都是由一系列重復的神經網路模塊組成的,在標準RNN中,這個重復模塊將有一個非常簡單的結構,比如一個單一的tanh層,在LSTMs中,重復模塊具有不同的結構,不是只有一個神經網路層,而是有四個,以一種非常特殊的方式相互作用,請在此處詳細閱讀LSTMs(https://colah.github.io/posts/2015-08-Understanding-LSTMs/),
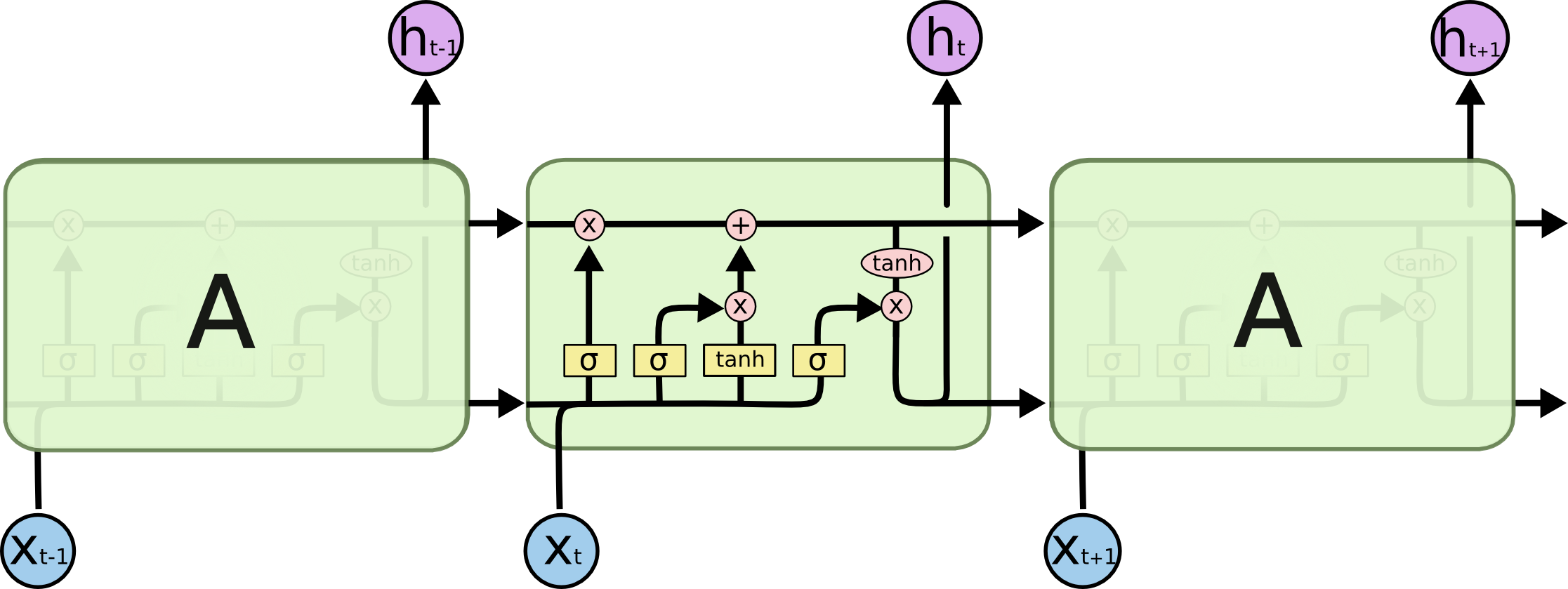
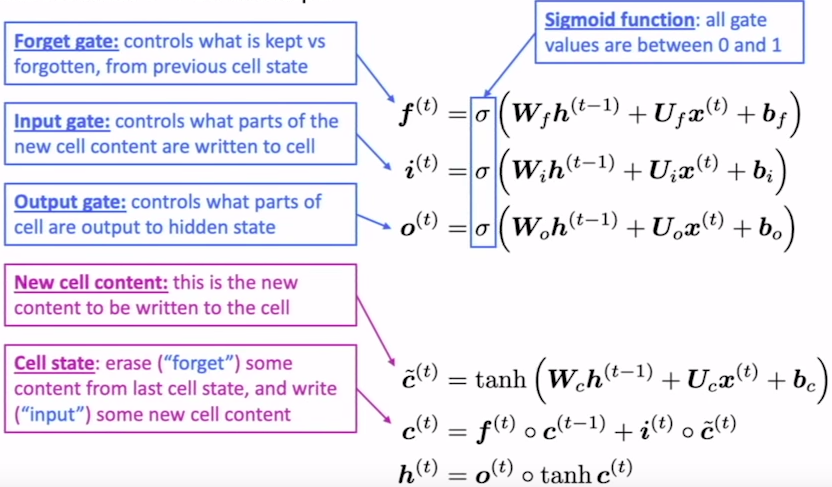
語言模型的評估
我們需要對模型進行評估,以改進它或將其與其他模型進行比較,困惑度被用來評估語言模型,它是一種測量概率模型預測測驗資料的能力,
我們衡量我們的模型有多低的困惑度,低困惑度意味著模型生成了連貫、結構良好的句子,而高困惑度則表示不連貫和混亂的句子,因此,低困惑度是好的,高困惑度是壞的,
從數學上講,困惑度是測驗集的反概率,由單詞數規范化,
LM的困惑度:
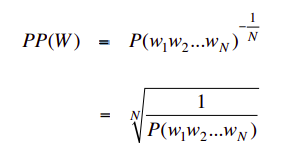
結論
語言模型是NLP的重要組成部分,可以用于許多NLP任務,我們看到了如何創建自己的語言模型,以及每種方法都會出現什么問題,我們得出的結論是,LSTM是制作語言模型的最佳方法,因為它考慮并處理了長期依賴問題,
原文鏈接:https://medium.com/@devyanshu/a-quick-introduction-to-language-models-in-natural-language-processing-1bffc5e74af4
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/195345.html
標籤:其他