文章目錄
- 1.爬取原頁面
- 2.易錯點分析
- 3.完整代碼
- 參考源自
1.爬取原頁面
??參考的原頁面如下圖,是亞馬遜的一個商品
2.易錯點分析
??由于亞馬遜設定了來源審查,所以想要爬取上面的內容需要更改代碼,即更改頭部資訊也就是headers,使用字典構造鍵值對即可,
kv = {'user-agent':'Mozilla/5.0'}
??具體詳解可看我之前寫過的這邊文章(自己撈一下自己,嘿嘿)
鏈接: https://blog.csdn.net/weixin_44578172/article/details/109302571
3.完整代碼
import requests
url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
#使用字典構造鍵值對,用Mozilla/5.0代替之前發送請求的header中的user-agent
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失敗")
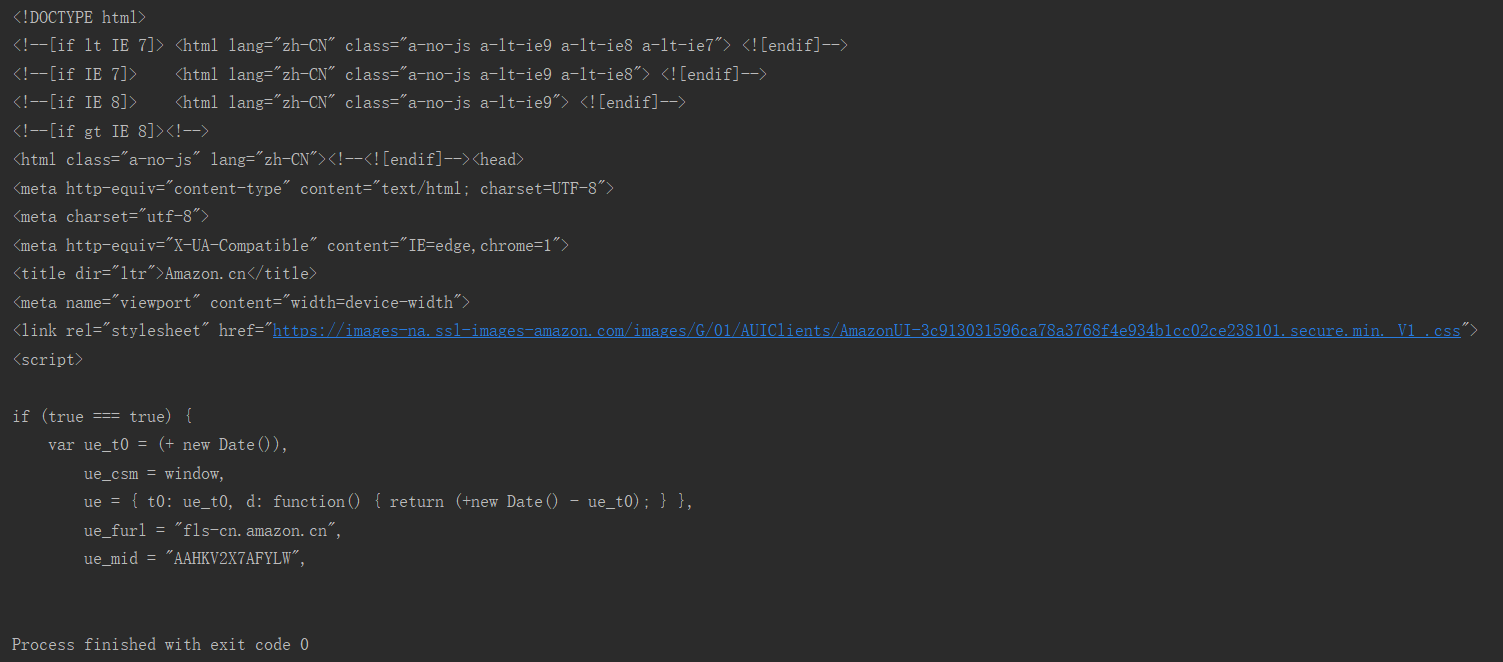
爬取結果如下圖:
??本篇完,如有錯誤歡迎指出~
參考源自
中國大學MOOC Python網路爬蟲與資訊提取
https://www.icourse163.org/course/BIT-1001870001
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/195813.html
標籤:其他
上一篇:戲劇性的繞過網頁付費后復制
下一篇:MAP基礎