點贊再看,養成習慣,微信搜一搜【程式員一凡】關注這個喜歡寫情懷的程式員,
本文 公眾號程式員一凡 已收錄,有一線大廠面試完整考點、資料以及我的系列文章,
但凡有職場經驗的兄弟都知道,大廠的面試真是一言難盡,不光看你面試時的臨場發揮能力,還要分N次考你對公司業務核心技術的熟悉度,
你要沒有扎實的基本功,想忽悠住面試官可太難了,你去翻翻大廠那些20、30K的崗位就懂了:
關于資料庫,我認為是軟體測驗工程師第一個要學的技術也是最重要的基礎,
不僅你做功能測驗要用到資料庫;介面測驗、很多介面的回傳值它是動態的,那么你要去資料庫拿資料來校驗;還有自動化,怎么去做一些資料驅動,都要從資料庫里去拿,你做性能測驗是不是也和資料庫有關,比如慢查詢,都和資料庫有關,
所以說,你要去面試軟體測驗工程師,資料庫這一關你得要有底,
掌握sql查詢增刪改查、子查詢、關聯查詢、分組查詢、分組過濾
1.說一下你常用的sql優化方式?為什么select*效率低?
2.什么是索引?索引為什么能增加查詢效率
3.索引是建的越多越好嗎?
4.什么是ORM?為什么要用ORM?
5.如何將查詢的資料匯總到excel,txt檔案?6.關系型資料庫和非關系型資料庫的區別?
首先如果你要去面試,你得首先保證你掌握了sql的基本查詢
增刪改查
第一部分:軟體測驗基礎理論、流程還有專案管理
增刪改查大家基本都會吧,Select、Delete、Update、還有一個子查詢、關聯查詢、分組查詢、分組過濾,
子查詢:就是一個嵌套在查詢陳述句中的查詢
關聯查詢:內連接、外連接(左連接、右連接)
我相信每次去面試的時候很多小伙伴都會去百度,搜素什么是什么子查詢?什么是關聯、分組查詢?什么是分組過濾……經過熬夜看完了幾篇“深度好文”可能面試官問,你也會胸有成竹,
如果以上的內容都不熟悉,就不要在簡歷中寫:“我熟悉資料庫的陳述句”
大家可能比較陌生的可能是分組查詢( group by)和分組過濾(having)
分組查詢( group by)是一個按照表中一個或者多個欄位,將資料進行分組,一般用于資料進行分類匯總,
如果讀這一塊還不是很熟悉的伙伴,可以去觀看我錄制的分組查詢教學視頻,
第二部分:資料庫
1.說一下你常用的sql優化方式?為什么select效率低?
優化方式比如說你用到了select,那么我就會問你為什么select*效率低?
可能你會說因為*是查詢所有的,
面試官:那還有呢?還有什么要補充的嗎?
我:(抓抓頭發,手兒無處安放)面試官,你干脆把簡歷還給我吧,我都不想再說下去了,
有很多時候是這樣子的 ,當面試官問到你一個問題,如果你只知道一點點,你說出來一點點,面試官問你還有沒有其他要補充的……
select*為什么效率低?
第一個你需要根據你理解的原理,具體分析,有時候做測驗你會去看一些Mysql的書籍,它會告訴你,一律不要用*作為查詢的欄位的串列,
為什么呢?
第一個,不需要的列會增加資料傳輸時間和網路開銷,有些資料庫和應用不在一臺服務器,
比如我的應用資料庫肯定是有一個服務器的,那你的后端前端可能不在同一臺服務器上,會有很多網路開銷,因為有時候我們在前端的操作都會用到資料庫,如果你都用select* 那么就大大增加了網路開銷,它會去決議很多的內容,特別一些select陳述句比較復雜決議比較多的時候,會給資料庫造成沉重的負擔,
特別有一些大型別的欄位,比如有一個叫做text 、 它是非常大的
varchar(字串型別)比如還有一些加密的、日之類的欄位,增加網路消耗是非常明顯的,即使這個Mysql服務器和客戶端在同一臺機器上,使用的協議tcp通信也需要額外的時間,所以說這個傳輸時間和網路開銷肯定會加大,
那么對于這些無用的大欄位,可能還會增加一些IO操作,(如果長度超過一定位元組,它會把一些超出的速率資料化到另一個地方,然后再去讀取這些記錄就會增加一次IO操作)
其實還有一個非常重要的點,Mysql有一個概念:覆寫索引(業界極為推崇的查詢優化方式)
如果你用到了select*,你將失去Mysql優化器覆寫索引策略優化的可能性,
2.什么是索引?索引為什么能增加查詢效率
索引是和性能息息相關的一個東西
如果我們把資料庫當做一本“新華字典”索引就是這個字典的目錄,一般會針對where(id等于多少)條件后面的欄位
索引既然是一個目錄,那么它就可以分為很多級,(目錄下面又有一個目錄)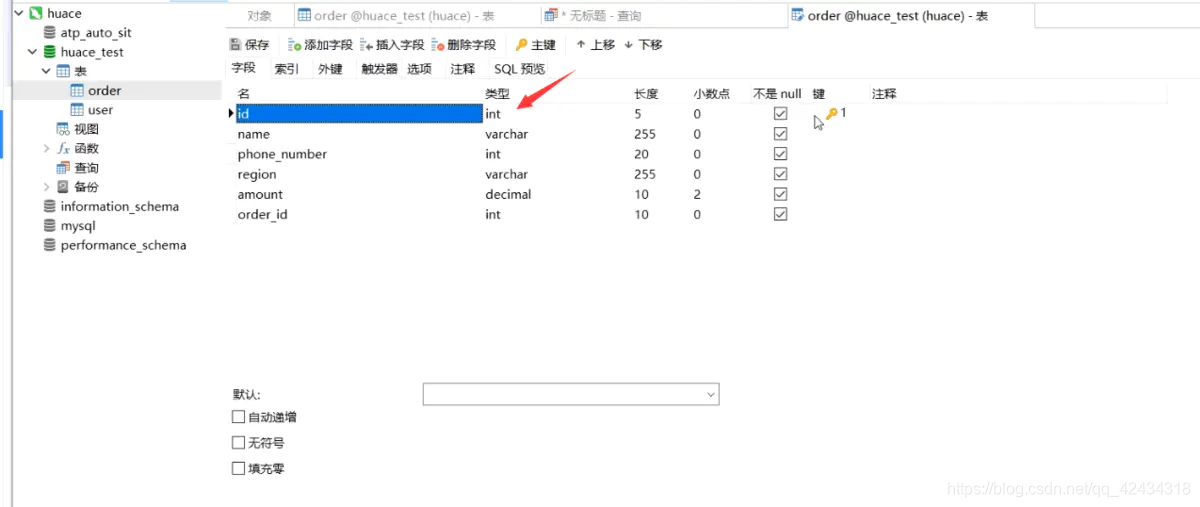
圖中的id是一個int型別,那么圖中的“鑰匙”代表什么?主鍵,所以說id可能是主鍵,其他的一些就是欄位名稱、欄位型別、欄位的長度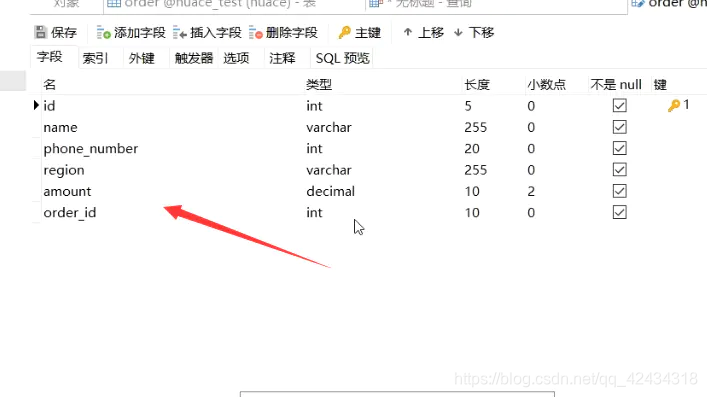
SHON INDEX from orderl (查詢某個表索引陳述句)
大家記住一個概念,主鍵本身就是一種唯一索引,
比如你要去查詢select * from where id=4 id等于多少,它就用到了一種索引,所以說索引就是這個字典的目錄,一般會針對where條件后面的欄位,
所以說這樣去查,如果你不是主鍵,那么會慢很多,如果你是主鍵是索引,就會快很多,
為什么索引能讓查詢變快?
資料結構
btree:二叉樹演算法
舉個例子: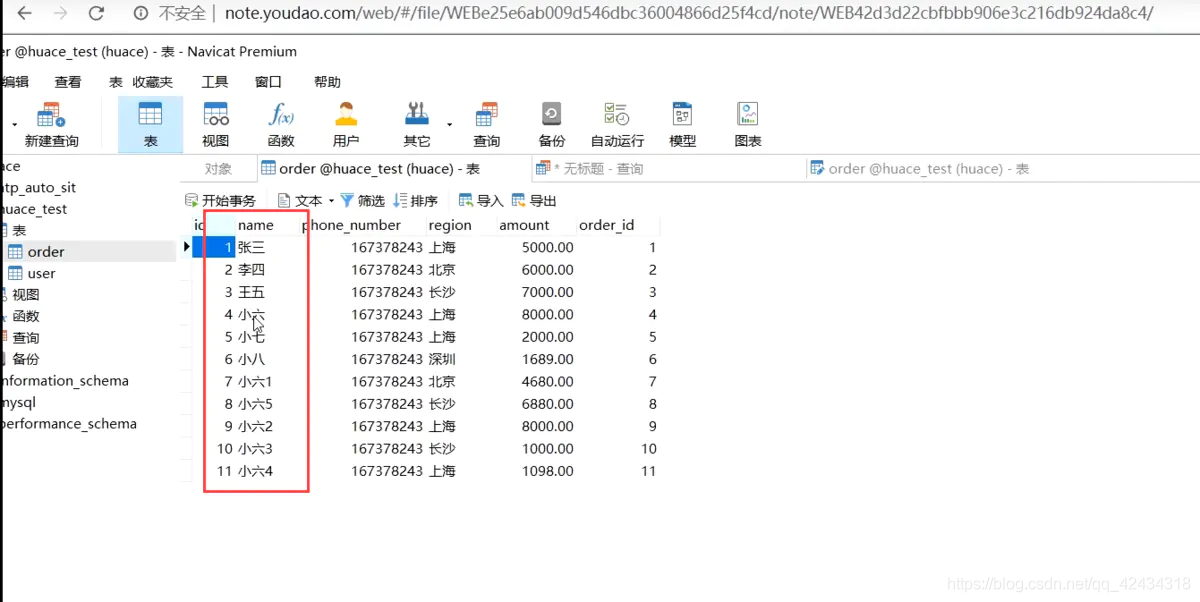
這個資料庫表剛好有11行,當我想查詢小六,比如說select * from where id=4 的時候,這個時候如果不加索引,執行這行陳述句做的什么動作?就是一個一個查下去,查到4的時候還會往下查詢,查11次,
如果一般的有百萬級的資料,它就會去查百萬次,
如果我們用二叉樹演算法(索引)它會去查詢多少次呢?
二叉樹的原理:取中間一個數,大于的右移,小于的左移,每次減半,
11個資料,二叉樹的一個經典的演算法,取中間的一個數,11最中間的一個數是什么?是6對吧,那么它會把小于6的12345放一邊,然后這里7891011也會放一邊,他就會這樣去進行,
我們來看一看如果它加了索引,它會查詢幾次,比如它第一次查id等于4,它會取中間一個數等于6,我們要的不是等于6,根據原理,它就又會去取中間一個值,大于的右移,小于的左移6的中間值是3,12放左邊,45放右邊,

那么它可能查三到四次就可以查到了,這就是索引的效率,是不是會快很多?資料量大的時候提高效率可想而知,
更多測驗教學視瞥澩可以來群里找我,備注公眾號,
還有很多問題,比如什么是ORM?為什么要用ORM?(難度四顆星)大家不僅僅要說出這個概念,你要把它們的底層原理理解透徹,
面試中高級測驗,往往三顆星的面試問題就刷了一大批人,
如果你這樣從底層原理開始講,面試官對你豎大拇指!你開一個工資吧,什么時候來上班?
聽說點贊的人都拿了大廠offer
絮叨
另外,一凡把自己的面試文章整理成了一本電子書,共 216頁!目錄如下,還有我復習時總結的面試題以及簡歷模板
現在免費送給大家,鏈接: https://pan.baidu.com/s/10w3q4agGVh4R–HOvEYV-w 提取碼: 3y8t
文章首發于公眾號:程式員一凡
絮叨
如果你想去一家不錯的公司,但是目前的硬實力又不到,我覺得還是有必要去努力一下的,技術能力的高低能決定你走多遠,平臺的高低,能決定你的高度,
如果你通過努力成功進入到了心儀的公司,一定不要懈怠放松,職場成長和新技術學習一樣,不進則退,
一凡發現在作業中發現我身邊的人真的就是實力越強的越努力,最高級的自律,享受孤獨
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/195970.html
標籤:其他
上一篇:【翻譯】威脅捕捉成熟度模型