
那我們借用 cs50 里的例子,比如要把一摞卷子排好序,那用并歸排序的思想是怎么做的呢?
首先把一摞卷子分成兩摞; 把每一摞排好序; 把排好序的兩摞再合并起來,
感覺啥都沒說?
那是因為上面的程序里省略了很多細節,我們一個個來看,
首先分成兩摞的程序,均分,奇偶數無所謂,也就是多一個少一個的問題;
那每一摞是怎么排好序的?
答案是用同樣的方法排好序,

排好序的兩摞是怎么合并起來的?
這里需要借助兩個指標和額外的空間,然后左邊畫一個彩虹??右邊畫個龍??,不是,是左邊拿一個數,右邊拿一個數,兩個比較大小之后排好序放回到陣列里(至于放回原陣列還是新陣列稍后再說),
這其實就是分治法 divide-and-conquer 的思想, 歸并排序是一個非常典型的例子,
分治法
顧名思義:分而治之,
就是把一個大問題分解成相似的小問題,通過解決這些小問題,再用小問題的解構造大問題的解,
聽起來是不是和之前講遞回的時候很像?
沒錯,分治法基本都是可以用遞回來實作的,
在之前,我們沒有加以區分,當然現在我也認為不需要加以區分,但你如果非要問它們之間是什么區別,我的理解是:
遞回是一種編程技巧,一個函式自己呼叫自己就是遞回; 分治法是一種解決問題的思想: 把大的問題分解成小問題的這個程序就叫“分”, 解決小問題的程序就叫“治”, 解決小問題的方法往往是遞回,
所以分治法的三大步驟是:
「分」:大問題分解成小問題;
「治」:用同樣的方法解決小問題;
「合」:用小問題的解構造大問題的解,
那回到我們的歸并排序上來:
「分」:把一個陣列拆成兩個;
「治」:用歸并排序去排這兩個小陣列;
「合」:把兩個排好序的小陣列合并成大陣列,
這里還有個問題,就是什么時候能夠解決小問題了?
答:當只剩一個元素的時候,直接回傳就好了,分解不了了, 這就是遞回的 base case,是要直接給出答案的,
老例子:{5, 2, 1, 0}
暗示著齊姐對你們的愛啊~??
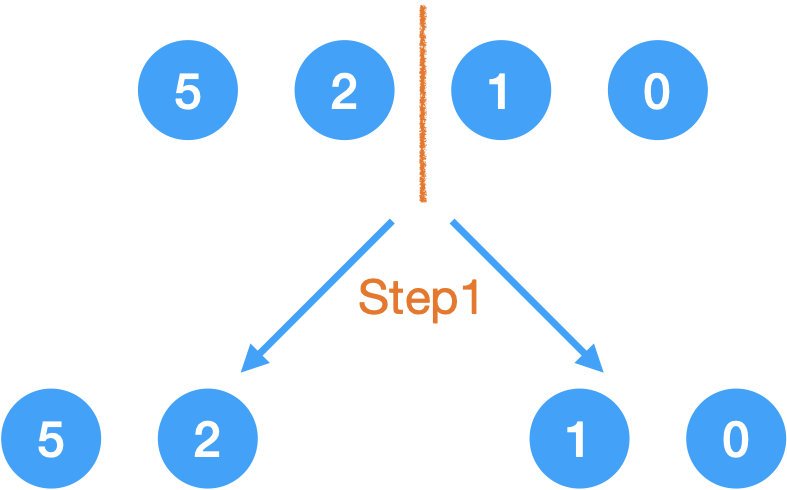
Step1.
先拆成兩半,
分成兩個陣列:{5, 2} 和 {1, 0}
Step2.
沒到 base case,所以繼續把大問題分解成小問題:
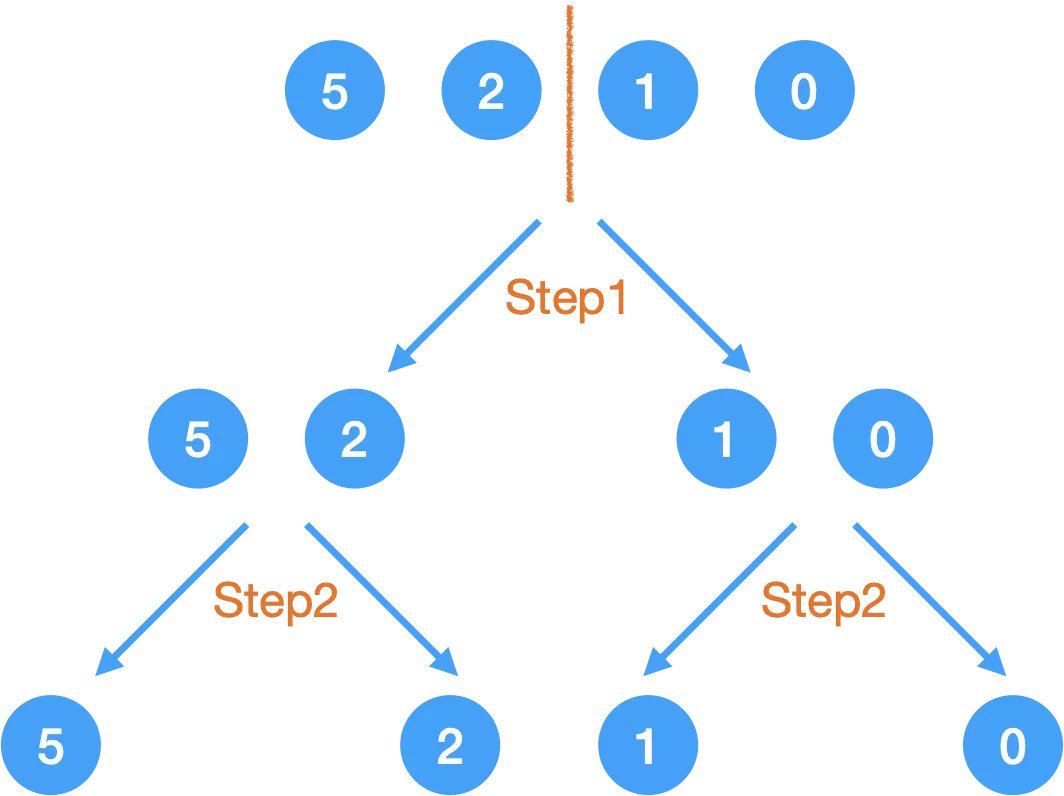
當然了,雖然左右兩邊的拆分我都叫它 Step2,但是它們并不是同時發生的,我在遞回那篇文章里有說原因,本質上是由馮諾伊曼體系造成的,一個 CPU 在某一時間只能處理一件事,但我之所以都寫成 Step2,是因為它們發生在同一層 call stack,這里就不在 IDE 里演示了,不明白的同學還是去看遞回那篇文章里的演示吧,
Step3.
這一層都是一個元素了,是 base case,可以回傳并合并了,
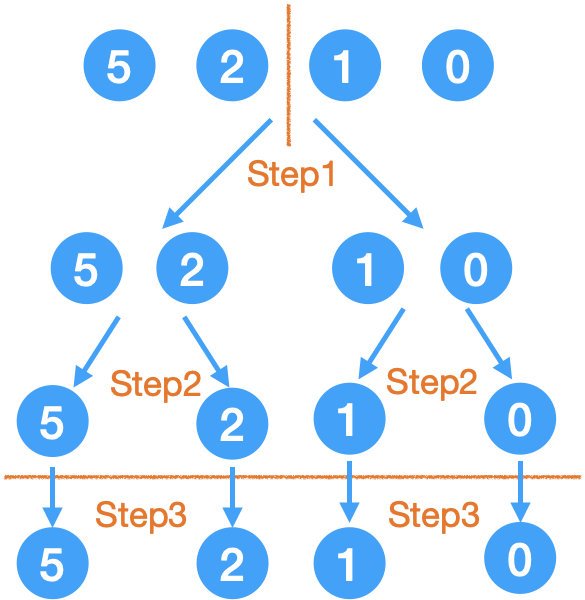
Step4.
合并的程序就是按大小順序來排好,這里借助兩個指標來比較,以及一個額外的陣列來輔助完成,

比如在最后一步時,陣列已經變成了:
{2, 5, 0, 1},
那么通過兩個指標 i 和 j,比較指標所指向元素的大小,把小的那個放到一個新的陣列?里,然后指標相應的向右移動,
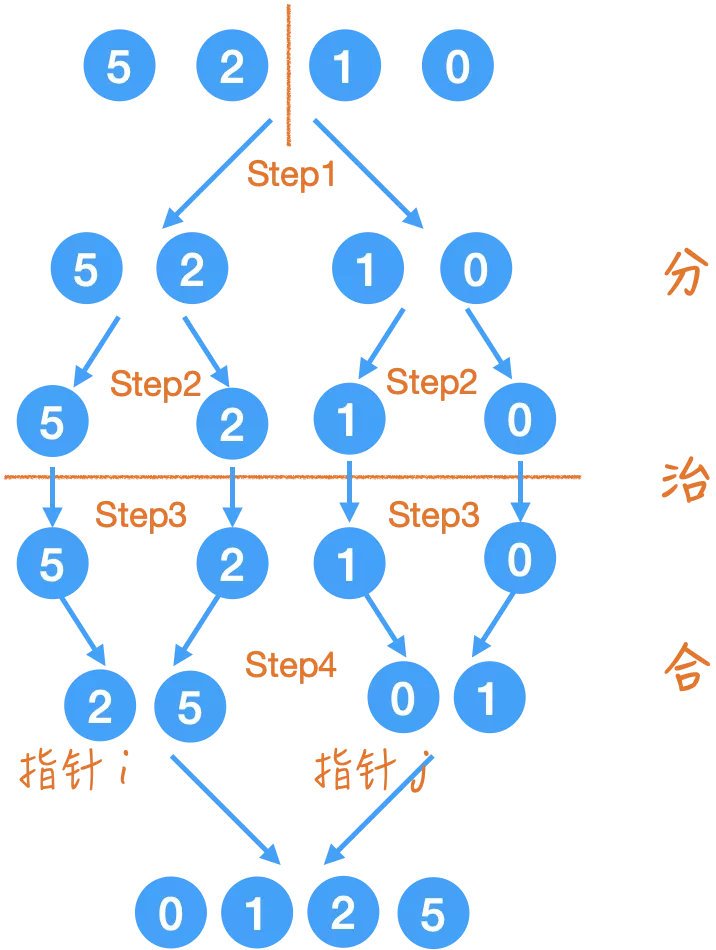
其實這里我們有兩個選擇:
一種是從新陣列往原陣列合并, 另一種就是從原陣列往新陣列里合并,
這個取決于題目要求的回傳值型別是什么;以及在實際作業中,我們往往是希望改變當前的這個陣列,把當前的這個陣列排好序,而不是回傳一個新的陣列,所以我們采取從新陣列往原陣列合并的方式,而不是把結果存在一個新的陣列里,
那具體怎么合并的,大家可以看下15秒的小影片:
擋板左右兩邊是分別排好序的,那么合并的程序就是利用兩個指標,誰指的數字小,就把這個數放到結果里,然后移動指標,直到一方到頭(出界),


public class MergeSort {
public void mergeSort(int[] array) {
if(array == null || array.length <= 1) {
return;
}
int[] newArray = new int[array.length];
mergeSort(array, 0, array.length-1, newArray);
}
private void mergeSort(int[] array, int left, int right, int[] newArray) {
// base case
if(left >= right) {
return;
}
// 「分」
int mid = left + (right - left)/2;
// 「治」
mergeSort(array, left, mid, newArray);
mergeSort(array, mid + 1, right, newArray);
// 輔助的 array
for(int i = left; i <= right; i++) {
newArray[i] = array[i];
}
// 「合」
int i = left;
int j = mid + 1;
int k = left;
while(i <= mid && j <= right) {
if(newArray[i] <= newArray[j]) { // 等號會影響演算法的穩定性
array[k++] = newArray[i++];
} else {
array[k++] = newArray[j++];
}
}
if(i <= mid) {
array[k++] = newArray[i++];
}
}
}
寫的不錯,我再來講一下:
首先定義 base case,否則就會成無限遞回死回圈,那么這里是當未排序區間里只剩一個元素的時候回傳,即左右擋板重合的時候,或者沒有元素的時候回傳,
「分」
然后定義小問題,先找到中點,
那這里能不能寫成 (left+right)/2 呢? 注意??,是不可以的哦,
雖然數學上是一樣的, 但是這樣寫, 有可能出現 integer overflow.
「治」
這樣我們拆好了左右兩個小問題,然后用“同樣的方法”解決這兩個自問題,這樣左右兩邊就都排好序了~
為什么敢說這兩邊都排好序了呢? 因為有數學歸納法在后面撐著~
那在這里,能不能把它寫成:
mergeSort(array, left, mid-1, newArray);
mergeSort(array, mid, right, newArray);
也就是說,
左邊是 [left, mid-1], 右邊是 [mid, right],
這樣對不對呢?
答案是否定的,
因為會造成無限遞回,
最簡單的,舉個兩個數的例子,比如陣列為{1, 2}.
那么 left = 0, right = 1, mid = 0.
用這個方法拆分的陣列就是:
[0, -1], [0, 1] 即: 空集,{1, 2}
所以這樣來分并沒有縮小問題,沒有把大問題拆解成小問題,這樣的“分”是錯誤的,會出現 stack overflow.
再深一層,究其根本原因,是因為 Java 中的小數是「向零取整」,
所以這里必須要寫成:
左邊是 [left, mid], 右邊是 [mid + 1, right],
「合」
接下來就是合并的程序了,
在這里我們剛才說過了,要新開一個陣列用來幫助合并,那么最好是在上面的函式里開,然后把參考往下傳,開一個,反復用,這樣節省空間,
我們用兩個指標:i 和 j 指向新陣列,指標 k 指向原陣列,開始剛才影片里的移動程序,
要注意,這里的等于號跟哪邊,會影響這個排序演算法的穩定性,不清楚穩定性的同學快去翻一下上一篇文章啦~
那像我代碼中這種寫法,指標 i 指的是左邊的元素,遇到相等的元素也會先拷貝下來,所以左邊的元素一直在左邊,維持了相對順序,所以就是穩定的,
最后我們來分析下時空復雜度:
時間復雜度
歸并排序的程序涉及到遞回,所以時空復雜度的分析稍微有點復雜,在之前「遞回」的那篇文章里我有提到,求解大問題的時間就是把所有求解子問題的時間加起來,再加上合并的時間,
我們在遞回樹中具體來看:
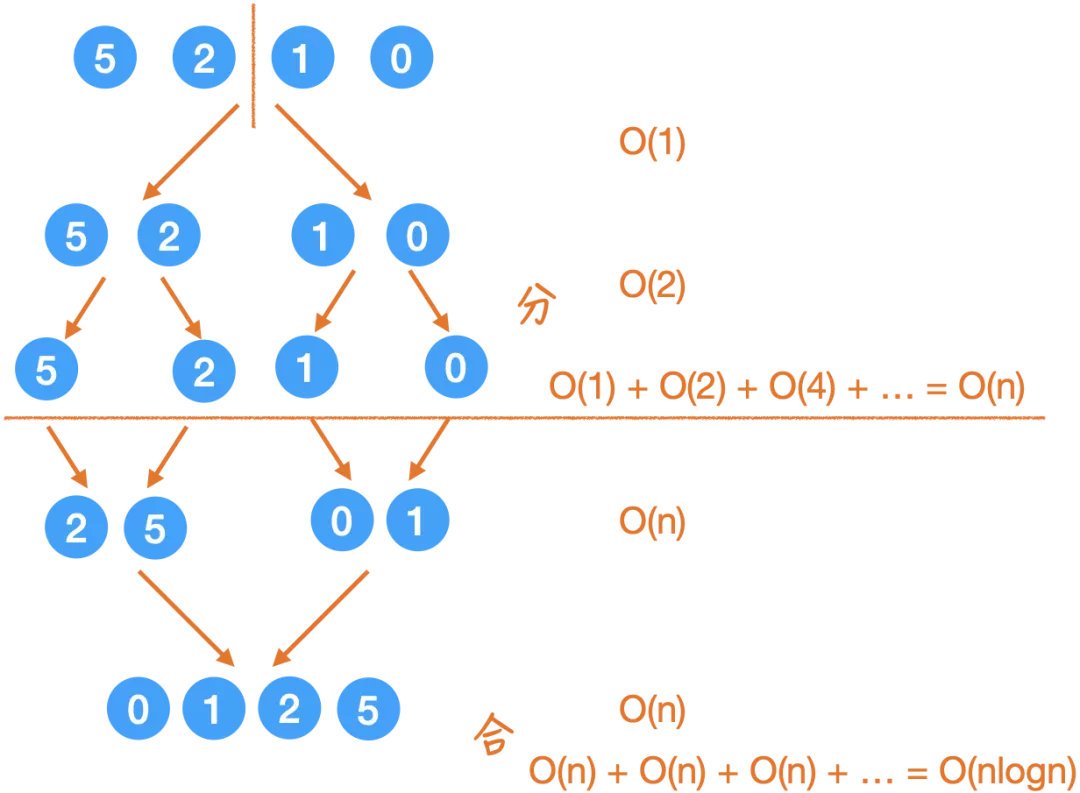
這里我右邊已經寫出來了:
「分」的程序,每次的時間取決于有多少個小問題,可以看出來是
1,2,4,8...這樣遞增的,
那么加起來就是O(n).
「合」的程序,每次都要用兩個指標走完全程,每一層的 call stack 加起來用時是 O(n),總共有 logn 層,所以是 O(nlogn).
那么總的時間,就是 O(nlogn).
空間復雜度
其實歸并排序的空間復雜度和代碼怎么寫的有很大的關系,所以我這里分析的空間復雜度是針對我上面這種寫法的,
要注意的是,遞回的空間復雜度的分析并不能像時間復雜度那樣直接累加,因為空間復雜度的定義是在程式運行程序中的使用空間的峰值,本身就是一個峰值而非累加值的概念,
那也就是 call stack 中,所使用空間最高的時刻,其實就是遞回樹中最右邊的這條路線:它既要存著左邊排好序的那半邊結果,還要把右邊這半邊繼續排,總共是 O(n).
那有同學說 call stack 有 logn 層,為什么不是 O(logn),因為每層的使用的空間不是 O(1) 呀,
擴展:外排序
這兩節介紹的排序演算法都屬于內部排序演算法,也就是排序的程序都是在記憶體中完成,
但在實際作業中,當資料量特別大時,或者說比記憶體容量還要大時,資料就無法一次性放入記憶體中,只能放在硬碟等外存盤器上,這就需要用到外部排序演算法演算法來完成,一個典型的外排序演算法就是外歸并排序(External Merge Sort),
這才是一道有意思的面試題,在經典演算法的基礎上,加上實際作業中的限制條件,和面試官探討的程序中,就能看出 candidate 的功力,
要解決這個問題,其實是要明確這里的限制條件是什么:
首先是記憶體不夠,那除此之外,我們還想盡量少的進行硬碟的讀寫,因為很慢啊,
比如就拿wiki[1]上的例子,要對 900MB 的資料進行排序,但是記憶體只有 100MB,那么怎么排呢?
wiki 中給出的是讀 100MB 資料至記憶體中,我并不贊同,因為無論是歸并排序還是快排都是要費空間的,剛說的空間復雜度 O(n) 不是,那資料把記憶體都占滿了,還怎么運行程式?那我建議比如就讀取 10MB 的資料,那就相當于把 900MB 的資料分成了 90 份; 在記憶體中排序完成后寫入磁盤; 把這 90 份資料都排好序,那就會產生 90 個臨時檔案; 用 k-way merge 對著 90 個檔案進行合并,比如每次讀取每個檔案中的 1MB 拿到記憶體里來 merge,保證加起來是小于記憶體容量且能保證程式能夠運行的,
那這是在一臺機器上的,如果資料量再大,比如在一個分布式系統,那就需要用到 Map-Reduced 去做歸并排序,感興趣的同學就繼續關注我吧~


如果你喜歡這篇文章,記得給我點贊留言哦~你們的支持和認可,就是我創作的最大動力,我們下篇文章見!
我是小齊,紐約程式媛,終生學習者,每天晚上 9 點,云自習室里不見不散!
更多干貨文章見我的 Github: https://github.com/xiaoqi6666/NYCSDE
參考資料
外排序: https://zh.wikipedia.org/wiki/%E5%A4%96%E6%8E%92%E5%BA%8F
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/196001.html
標籤:其他