作者|Kiprono Elijah Koech
編譯|VK
來源|Towards Data Science

在本文中,我們將討論一個分類問題,該問題涉及到將評論分為正面或負面,這里使用的評論是客戶在ABC服務上所做的評論,
資料收集和預處理
在這個專案中使用的資料是從網上爬來的,資料清理在這個Notebook上完成:https://github.com/kipronokoech/Reviews-Classification/blob/master/data_collection.ipynb
在我們抓取資料后被保存到一個.txt檔案中,下面是一行檔案的例子(代表一個資料點)
{'socialShareUrl': 'https://www.abc.com/reviews/5ed0251025e5d20a88a2057d', 'businessUnitId': '5090eace00006400051ded85', 'businessUnitDisplayName': 'ABC', 'consumerId': '5ed0250fdfdf8632f9ee7ab6', 'consumerName': 'May', 'reviewId': '5ed0251025e5d20a88a2057d', 'reviewHeader': 'Wow - Great Service', 'reviewBody': 'Wow. Great Service with no issues. Money was available same day in no time.', 'stars': 5}
資料點是一個字典,我們對reviewBody和stars感興趣,
我們將把評論分類如下
1 and 2 - Negative
3 - Neutral
4 and 5 - Positive
在收集資料時,網站上有36456條評論,資料高度不平衡:94%的評論是正面的,4%是負面的,2%是中性的,在這個專案中,我們將在不平衡的資料和平衡的資料上擬合不同的Sklearn模型(我們去掉一些正面評論,這樣我們就有相同數量的正面和負面評論,)
下圖顯示了資料的組成:
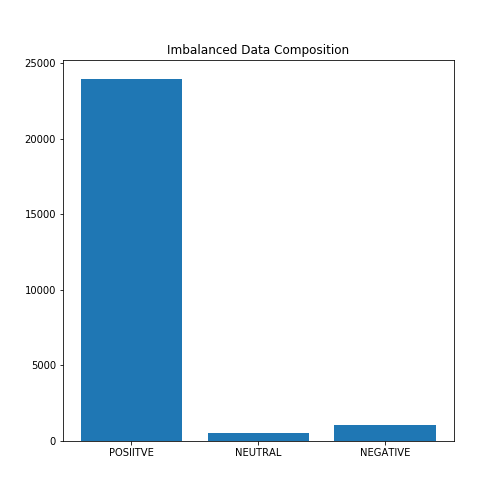
在上圖中,我們可以看到資料是高度不平衡的,
讓我們從匯入必要的包開始,并定義將用于對給定的評論進行分類的類Review
#匯入包
import numpy as np
import random
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics import f1_score #f1分數,一種評價指標
import ast #將字串轉換為字典
from IPython.display import clear_output
from sklearn import svm #支持向量機分類器
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression #匯入 logistic regression
from sklearn.tree import DecisionTreeClassifier #匯入 Decision tree
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import seaborn as sb
# 將評論分為正面、負面或中性
class Review:
def __init__(self, text, score):
self.text = text
self.score = score
self.sentiment = self.get_sentiment()
def get_sentiment(self):
if self.score <= 2:
return "NEGATIVE"
elif self.score == 3:
return "NEUTRAL"
else: #4或5分
return "POSITIVE"
在這里,我們將加載資料并使用Review類將評論分類為正面、反面或中性
# 大部分清理是在資料web爬取期間完成的
# Notebook 鏈接
# https://github.com/kipronokoech/Reviews-Classification/blob/master/data_collection.ipynb
reviews = []
with open("./data/reviews.txt") as fp:
for index,line in enumerate(fp):
# 轉換為字典
review = ast.literal_eval(line)
#對評論進行分類并將其附加到reviews中
reviews.append(Review(review['reviewBody'], review['stars']))
# 列印出reviews[0]的情緒類別和文本
print(reviews[0].text)
print(reviews[0].sentiment)
Wow. Great Service with no issues. Money was available same day in no time.
POSITIVE
將資料拆分為訓練集和測驗集
# 70%用于訓練,30%用于測驗
training, test = train_test_split(reviews, test_size=0.30, random_state=42)
# 定義X和Y
train_x,train_y = [x.text for x in training],[x.sentiment for x in training]
test_x,test_y = [x.text for x in test],[x.sentiment for x in test]
print("Size of train set: ",len(training))
print("Size of train set: ",len(test))
Size of train set: 25519
Size of train set: 10937
在我們繼續下一步之前,我們需要理解詞袋的概念,
詞袋
正如我們所知,一臺計算機只理解數字,因此我們需要使用詞袋模型將我們收到的評論資訊轉換成一個數字串列,
詞袋是一種文本表示形式,它包括兩個方面:已知單詞的詞匯與已知單詞存在程度的度量,
詞袋模型是一種用于檔案分類的支持模型,其中每個詞的出現頻率作為訓練分類器的特征,
例子:
考慮這兩個評論
- Excellent Services by the ABC remit team.Recommend.
- Bad Services. Transaction delayed for three days.Don’t recommend.
從以上兩句話中,我們可以得出以下詞典
[Excellent, Services, by, the, ABC, remit, team, recommend, bad, transaction, delayed, for, three, days, don’t]
我們現在將這個字典標記化以生成以下兩個資料點,這些資料點現在可以用來訓練分類器

在python中,標記化的實作如下
# 匯入用于向量化的庫
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# sklearn上的向量化——簡單的例子
corpus = [
"Excellent Services by the ABC remit team.Recommend.",
"Bad Services. Transaction delayed for three days.Don't recommend."]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
#print(X) #這是一個矩陣
print(vectorizer.get_feature_names()) # 字典
print(X.toarray())#顯然是一個矩陣,每一行都是每個句子的標記值
['abc', 'bad', 'by', 'days', 'delayed', 'don', 'excellent', 'for', 'recommend', 'remit', 'services', 'team', 'the', 'three', 'transaction']
[[1 0 1 0 0 0 1 0 1 1 1 1 1 0 0]
[0 1 0 1 1 1 0 1 1 0 1 0 0 1 1]]
現在我們已經理解了詞袋的概念,現在讓我們將這些知識應用到我們的訓練和測驗中
vectorizer = TfidfVectorizer()
train_x_vectors = vectorizer.fit_transform(train_x)
test_x_vectors = vectorizer.transform(test_x)
在不平衡資料中訓練模型
現在,我們擁有了向量,我們可以用來擬合模型,我們可以這樣做
支持向量機
#訓練支持向量機分類器
clf_svm = svm.SVC(kernel='linear')
clf_svm.fit(train_x_vectors, train_y)
#基于SVM的隨機預測
i = np.random.randint(0,len(test_x))
print("Review Message: ",test_x[i])
print("Actual: ",test_y[i])
print("Prediction: ",clf_svm.predict(test_x_vectors[i]))
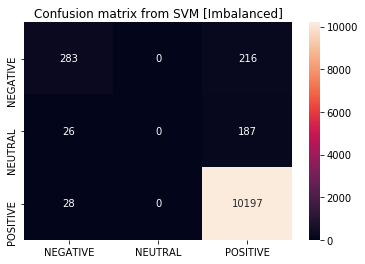
#支持向量機的混淆矩陣——你可以有其他分類器的混淆矩陣
labels = ["NEGATIVE","NEUTRAL","POSITIVE"]
pred_svm = clf_svm.predict(test_x_vectors)
cm =confusion_matrix(test_y,pred_svm)
df_cm = pd.DataFrame(cm, index=labels, columns=labels)
sb.heatmap(df_cm, annot=True, fmt='d')
plt.title("Confusion matrix from SVM [Imbalanced]")
plt.savefig("./plots/confusion.png")
Review Message: easy efficient first class
Actual: POSITIVE
Prediction: ['POSITIVE']
訓練的其他模型包括隨機森林、樸素貝葉斯、決策樹和Logistic回歸,
完整代碼的鏈接:https://github.com/kipronokoech/Reviews-Classification
基于不平衡資料的模型性能評估
- 準確度
利用準確度對模型進行了評估,結果如下
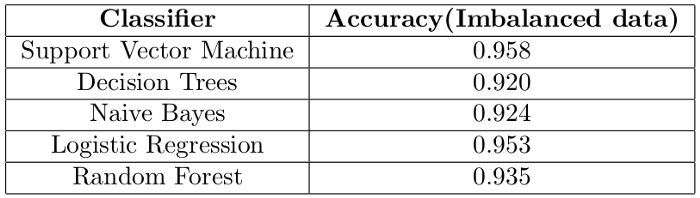
我們得到了90%的準確率,是正確還是有問題?答案是,出了點問題,
資料是不平衡的,使用準確度作為評估指標不是一個好主意,以下是各類別的分布情況
----------TRAIN SET ---------------
Positive reviews on train set: 23961 (93.89%)
Negative reviews on train set: 1055 (4.13%)
Neutral reviews on train set: 503 (1.97%)
----------TEST SET ---------------
Positive reviews on test set: 10225 (93.48%)
Negative reviews on test set: 499 (4.56%)
Neutral reviews on test set: 213 (1.95%)
如果分類器正確地預測了測驗集中所有的正面評價,而沒有預測到負面和中性評論,會發生什么?該分類器的準確率可達93.48%!!!!!!
這意味著我們的模型將是93.48%的準確率,我們會認為模型是好的,但實際上,模型“只知道”如何預測一類(正面評價),事實上,根據我們的結果,我們的支持向量機預測根本沒有中性評論
為了進一步理解這個問題,讓我們引入另一個指標:F1分數,并用它來評估我們的模型,
- F1分數
F1分數是精確和召回率的調和平均值,
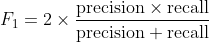
精確性和召回率衡量模型正確區分正面案例和負面案例的程度,
當我們根據這個指標評估我們的模型時,結果如下
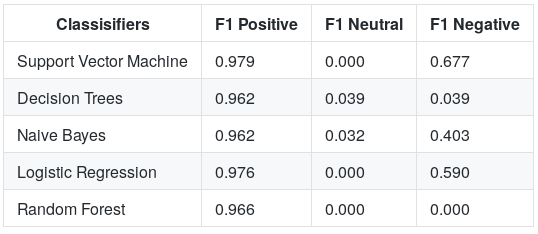
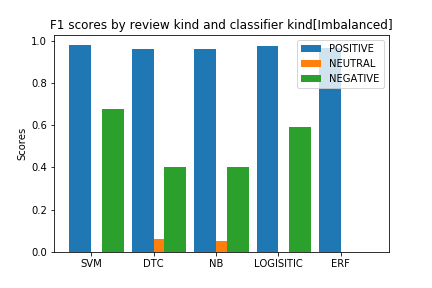
從圖中,我們現在知道這些模型在對正面評論進行分類時非常好,而在預測負面評論和中性評論方面則很差,
使用平衡資料
作為平衡資料的一種方法,我們決定隨機洗掉一些正面評論,以便我們在訓練模型時使用均勻分布的評論,這一次,我們正在訓練1055個正面評論和1055個負面評論的模型,我們放棄中性評論,
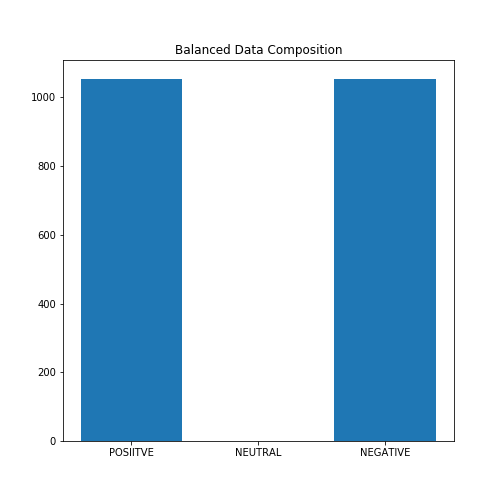
(你也可以考慮使用過采樣技術來解決資料不平衡的問題)
在訓練了模型之后,我們得到了以下結果
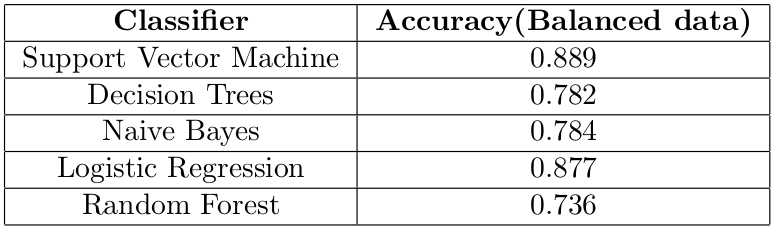
支持向量機的最佳結果是88.9%的準確率,在檢查F1分數(如下)后,我們現在可以意識到模型預測負面評價和正面評價一樣好,
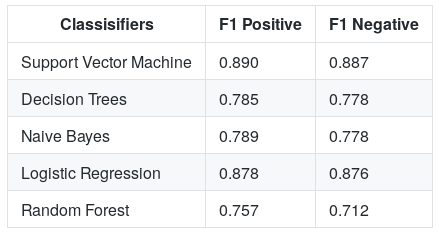
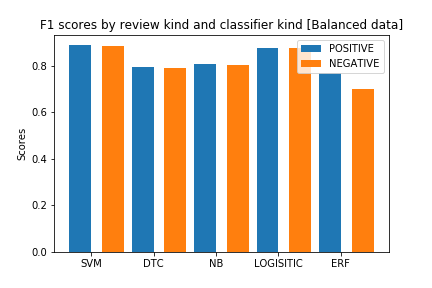
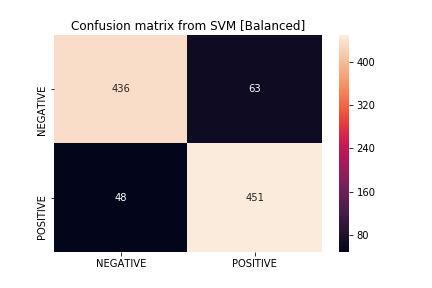
如果我們看一下顯示支持向量機結果的混淆矩陣,我們會注意到該模型在預測兩個類方面都很好
在這里找到完整的代碼:https://github.com/kipronokoech/Reviews-Classification
結論
在完成這個專案后,我希望你能夠了解到:
-
在不平衡的資料上擬合一個或多個模型可能(在大多數情況下確實如此)會導致不良結果,
-
在處理不平衡資料時,準確度不是一個好的衡量標準,
-
大部分作業是在預處理階段完成的,
感謝閱讀
原文鏈接:https://towardsdatascience.com/end-to-end-machine-learning-project-reviews-classification-60666d90ec19
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/196022.html
標籤:其他