GINet:Graph Interaction Network for Scene Parsing
論文地址:https://arxiv.org/pdf/2009.06160.pdf
一、背景
Scene Parsing 任務屬于語意分割的一個分支,也是把每個像素點分成一個具體的語意類別,它和常見的語意分割的區別在于 Scene Parsing 任務的資料集里的類別分為 Object 和 Stuff 兩種類別,Stuff 類別是背景類別,比如天空、草地這種形狀不太固定的類別,而且這種資料集的類別一般也會比較多,比如 ADE20K 資料集有 150 個類別,

在 Scene Parsing 任務里很重要的一件事情是怎么去構造背景關系的資訊,因為想從 RGB 值過渡到語意類別上的話,怎么去獲得它想要的一些其他像素點的資訊是特別重要的,常見的一種簡單的方式是用 FCN(上圖)去堆疊卷積層和池化層,但這種方式有兩點問題:
- 在每一個像素點上它的感受野都是一致的,
- 理論的感受野和實際的感受野是不一致的,
也就是說感受野缺乏了多樣性,
在 FCN 之后有一些作業提出來嘗試把 multi-level 的資訊加入到背景關系建模里面,比如說 PSPNet 是把特征 pooling 成不同的大小,然后再把它們 concat 在一起,這樣每一個特征位置上都能夠捕捉到多尺度的資訊;deeplab 中的 ASPP 模塊嘗試用不同空洞率的空洞卷積去捕捉不同尺度,這類方法的問題是它的 multi-level 的尺度是手工定義的,
那有沒有一種更好的方法是針對每個像素它都有自己的一個獨特的 context 資訊,Non-local 就是這種方式,針對每一個像素都去求這個像素和其他周圍像素點之間的關系,在語意分割任務里 DANet 和 OCNet 都是這方面的作業,
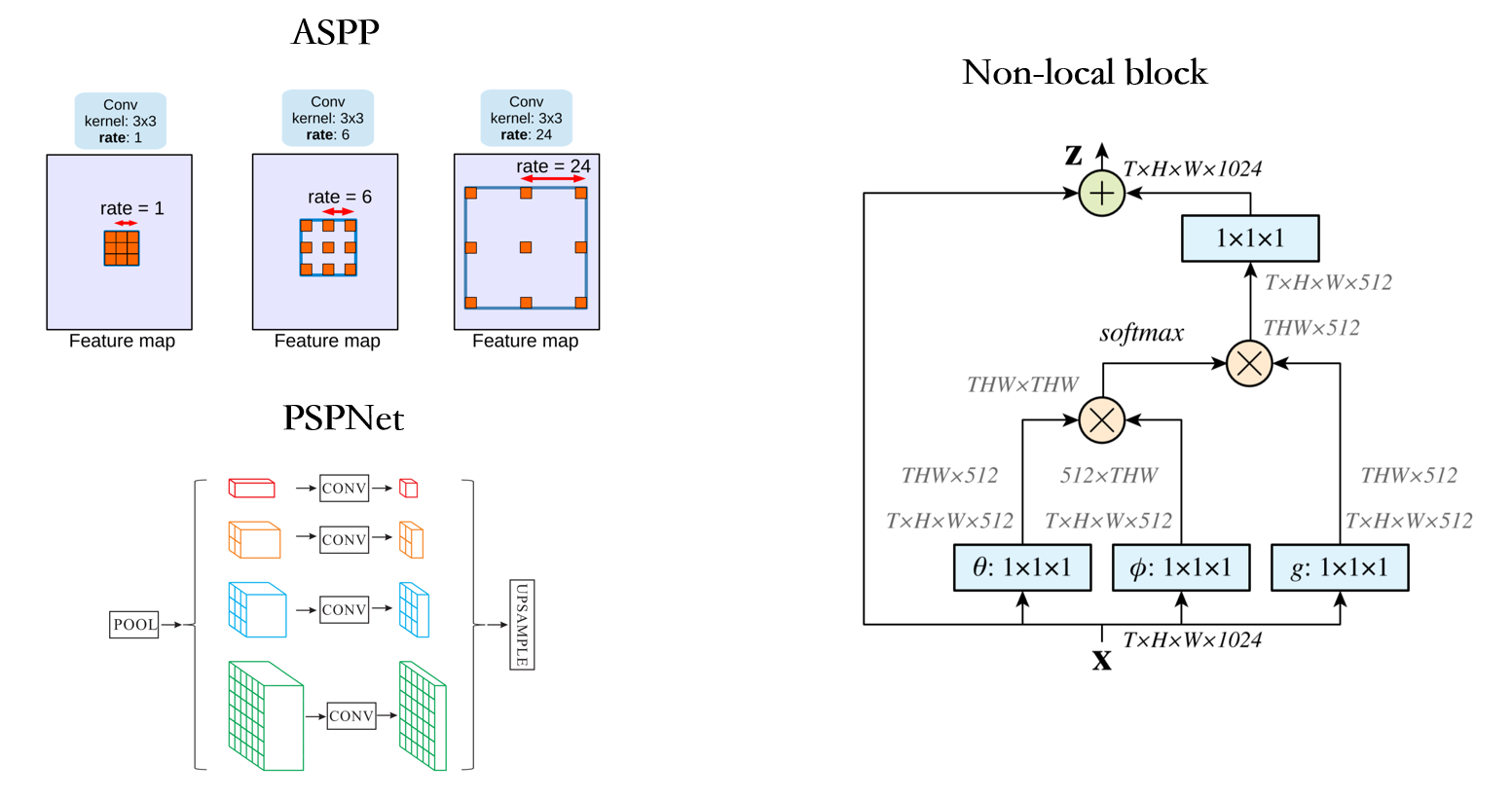
最近有一些作業嘗試去減少 Non-local 的計算復雜度,因為理論上來講其實不需要針對每一個像素都去求它的 context 資訊,對于某些相似的區域可以 share 一些 context ,所以有一些作業提出來把 GCN 放到分割任務里面,面向語意分割的 GCN 有一個共同的特點就是一共分三步,第一步是投射:把特征從特征空間投射到圖空間;第二步是圖推理:在圖空間上去做 GCN(在投射到圖空間的時候每一個結點實際上對應了影像上的一些區域,那么只要在這些結點之間去做 GCN 就代表在捕捉區域之間的關系);第三步是反投射:把這個特征從圖空間反投射到特征空間上,用這種方式去增強特征的分辨能力,
二、動機
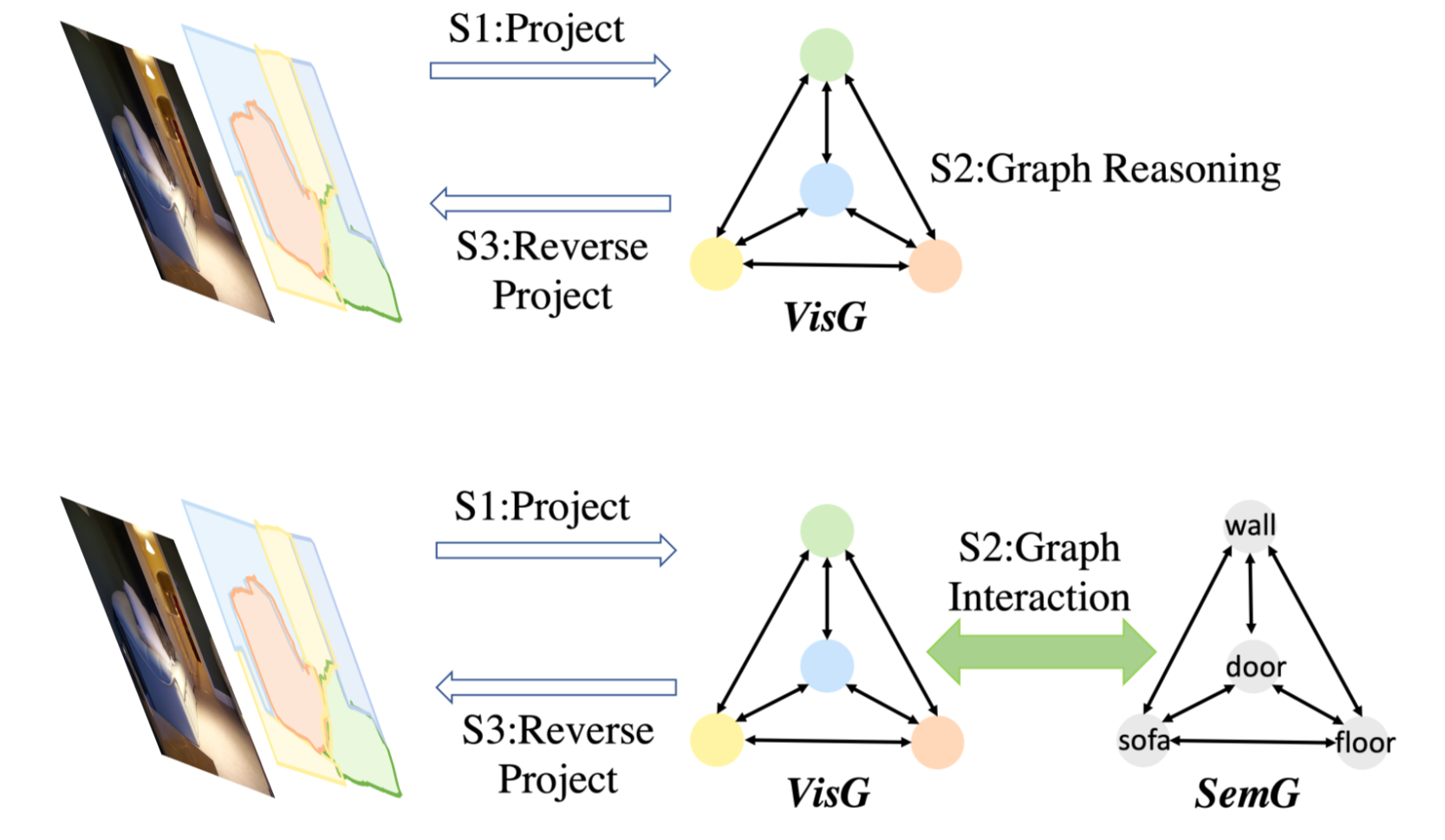
針對以上背景和前人作業,這篇文章考慮的問題是 context 只是去捕捉其他像素點的資訊可能不夠,是不是可以把一些語意的背景關系概念加進來,作者嘗試在第二步圖推理時將語意概念加進來,也就是說,作者希望能夠不僅去推理視覺區域之間的關系,而且把語意概念和它們之間的關系加到推理程序中來,
三、主要貢獻
-
提出了用于背景關系建模的新型“圖形互動單元”(GI單元),該單元結合了基于資料集的語意知識,以促進視覺圖上的背景關系推理,
-
提出了語意背景關系損失(SC-loss)來規范訓練程序,該方法強調了出現在場景中的類別,并抑制了沒有出現在場景中的類別,
四、方法
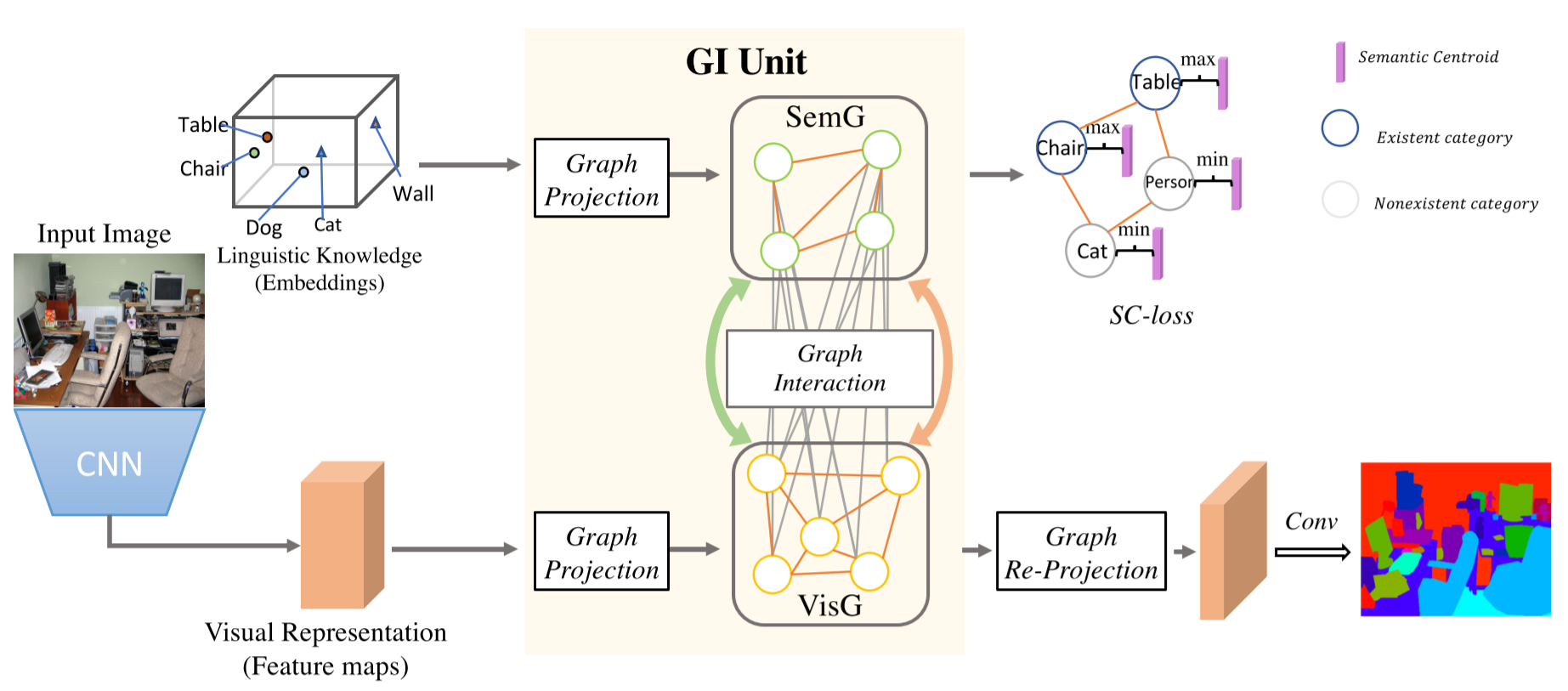
下圖是這篇文章的整體框架,
首先,采用經過預訓練的 ResNet 作為 backbone,在給定輸入 2D 影像的情況下,可以提取視覺特征(視覺表示);同時,可以以分類實體(類)的形式提取基于資料集的語意知識,并將其輸入 Word Embedding 以實作語意表示,
其次,視覺特征和語意表示由所提出的 GI 單元進行投射操作,以分別構造兩個圖(視覺圖和語意圖):在視覺特征上建立了一個編碼視覺區域之間依賴關系的圖,其中節點表示視覺區域,邊表示區域之間的相似性或關系;另一個圖是建立在與資料集相關的類別(由 word embedding 表示)之上的,該類別對語意相關性和標簽相關性進行編碼,
接下來,在GI單元中進行圖互動操作,其中語意圖用于在視覺圖上促進背景關系推理,并指導從視覺圖提取基于示例的語意圖,(互動的結果是:VisG 上的每個節點得到了一些它需要的語意背景關系資訊;SemG 上的每個節點在從 Embedding 抽取出來的時候是一個General的表征,但在經過圖互動之后它實際上是對于當前圖片的每一個語意類別的表征了,)
然后,由GI單元生成的演化后的視覺圖通過反投射操作,把特征從圖空間反投射到特征空間上,以增強每個區域視覺表示的判別能力;語意圖則在訓練階段受到語意背景關系損失(SC-loss)的更新和約束,(約束語意圖上每一個類別的有無,SC-loss在文章實驗當中顯示可以有效地提高小物體類別的識別率,)
最后,采用 1×1 卷積,然后進行簡單的雙線性上采樣獲得決議結果,
五、實驗
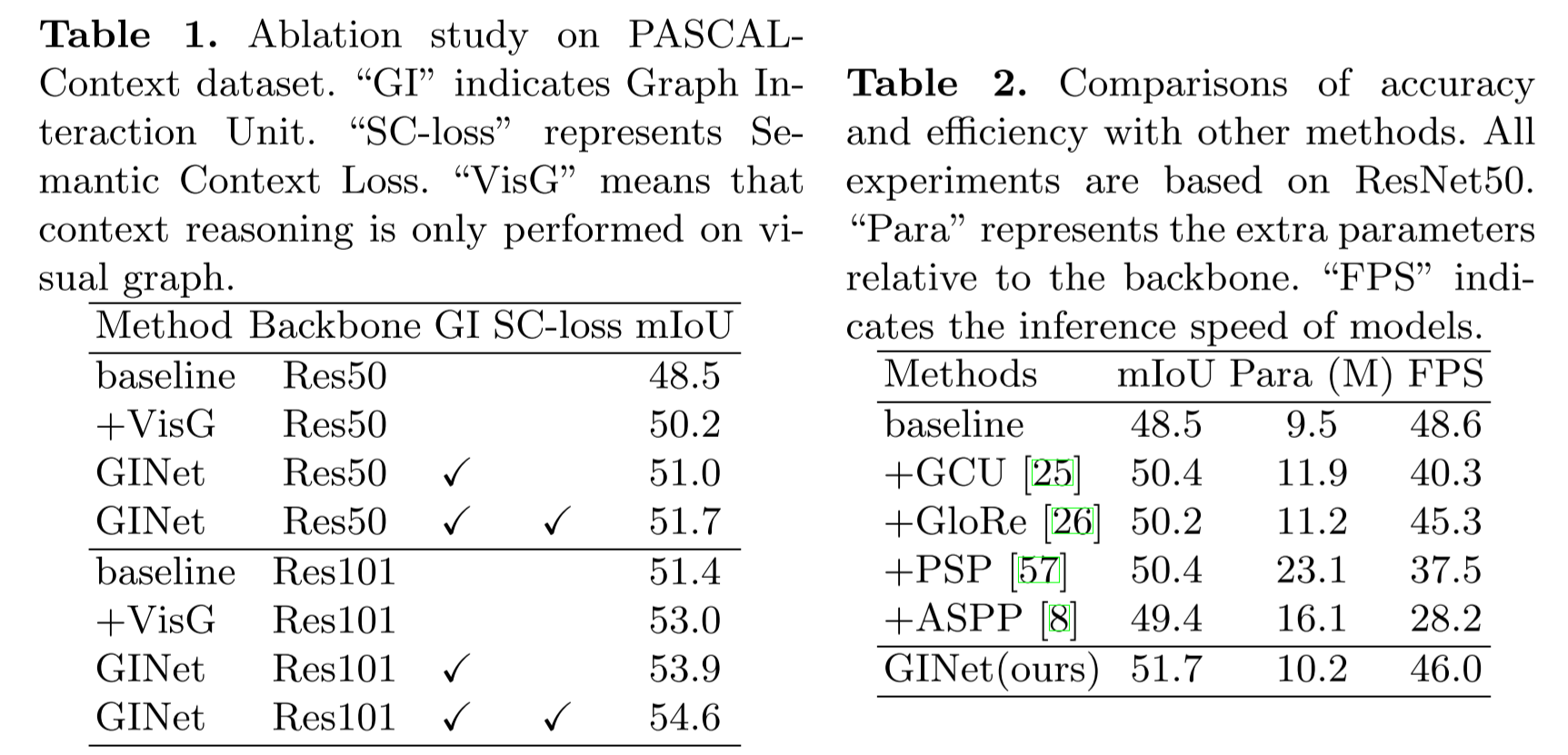
下面兩個表是作者做的 Ablation Study,
從表1可以看到在 VisG 之后添加 GINet 模塊,把語意資訊加進來之后可以提高 0.8 個點,進一步地用 SC-loss 去約束全域的語義概念又可以得到 0.7 個點的提升,
表2是和常見的一些 context 建模方法的比較,可以看本文提出的 GINet 顯示出了比較高的性能和比較快的速度,
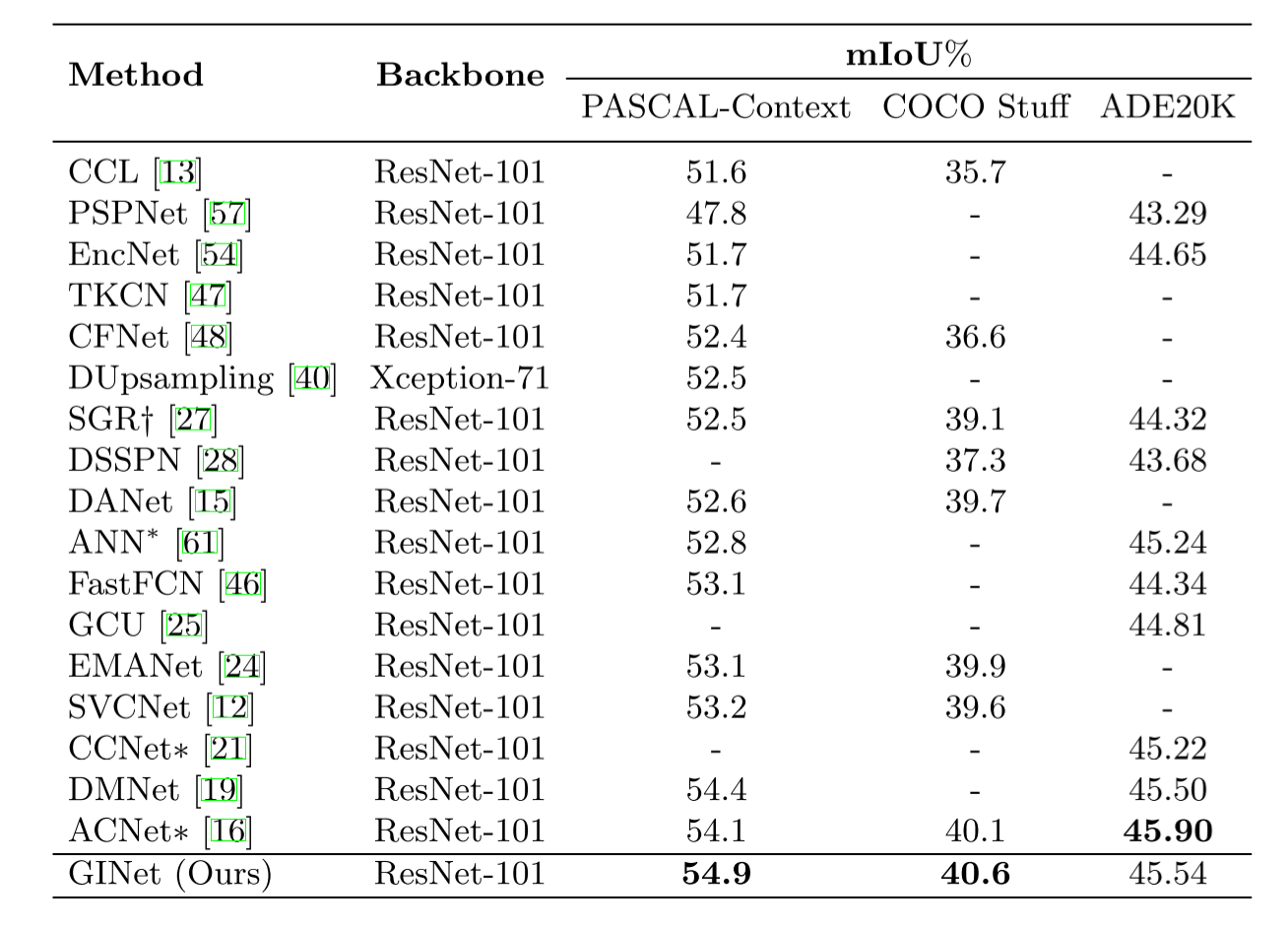
下表是和一些 state-of-the-art 的方法比較,可以看出本文提出的 GINet 在 PASCAL-Context、COCO Stuff 和 ADE20K 資料集上均獲得了不錯的性能,
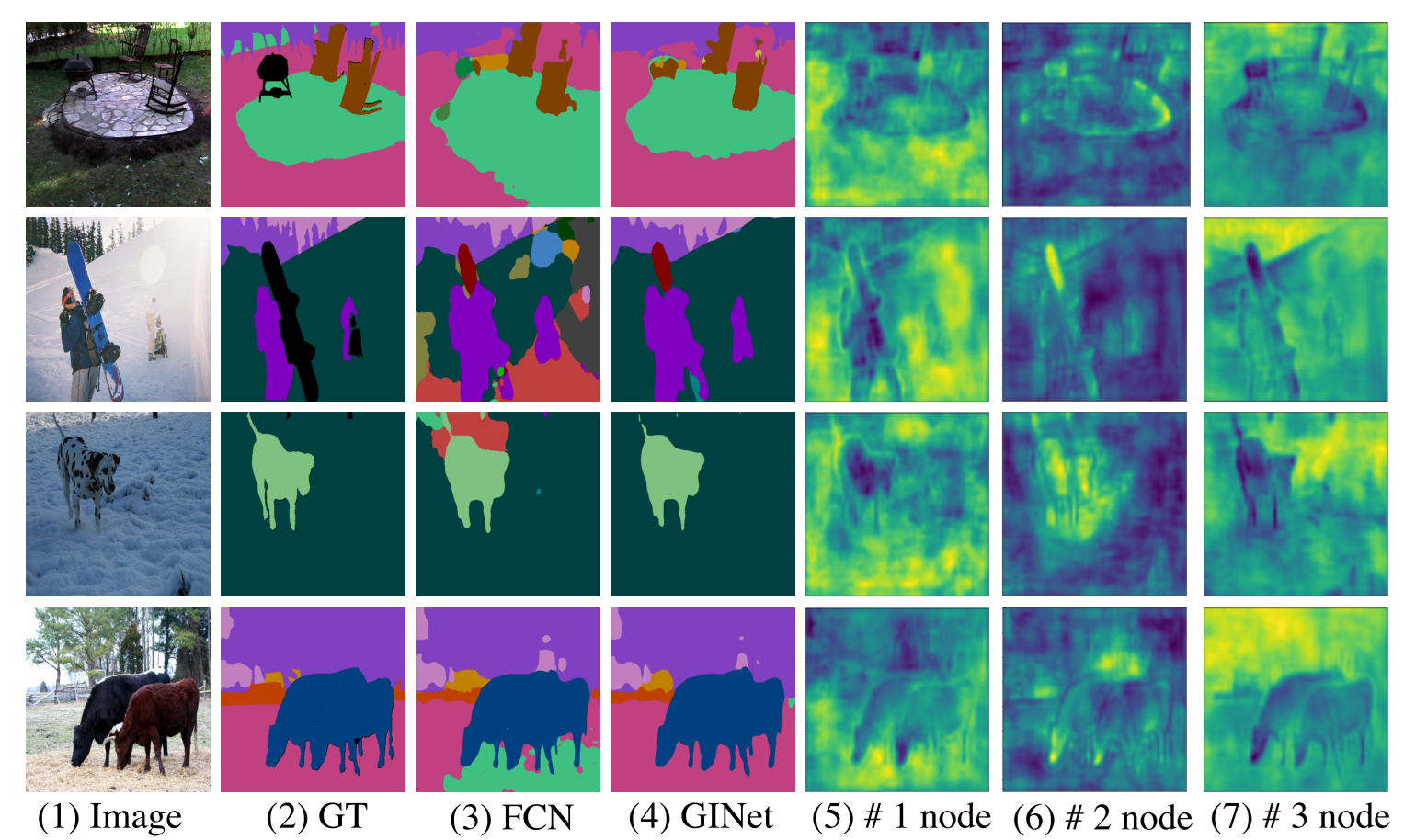
下圖是一些結果的可視化,重點其實是作者嘗試隨機選了三個節點初始化了出來,可以看到不同的節點其實對應圖片中不同的區域,也就是說只要在這些節點之間去做互動就可以得到區域之間的關系,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/196025.html
標籤:其他
上一篇:一個二分類下沒有免費午餐定理的題
下一篇:電子郵件分類的最佳機器學習演算法