YOLO的全稱是You Only Look Once,是最早出現的單階段目標檢測方法,也是第一個實作了實時目標檢測的方法,計算機視覺領域主要包括兩大方面:影像分類、目標檢測,影像分類是指根據影像的語意資訊將不同類別的影像區分開來,比如人臉識別,即模型輸入一張圖片,判斷該圖片屬于某個類別,

YOLO是一個國外開源的目標檢測演算法,目前流行的YOLO演算法分為三個版本,即YOLOv1、YOLOv2、YOLOv3,YOLO的核心思想就是利用整張圖作為網路的輸入,直接在輸出層回歸bounding box(邊界)的位置及所屬類別,
YOLO的整體結構如下:
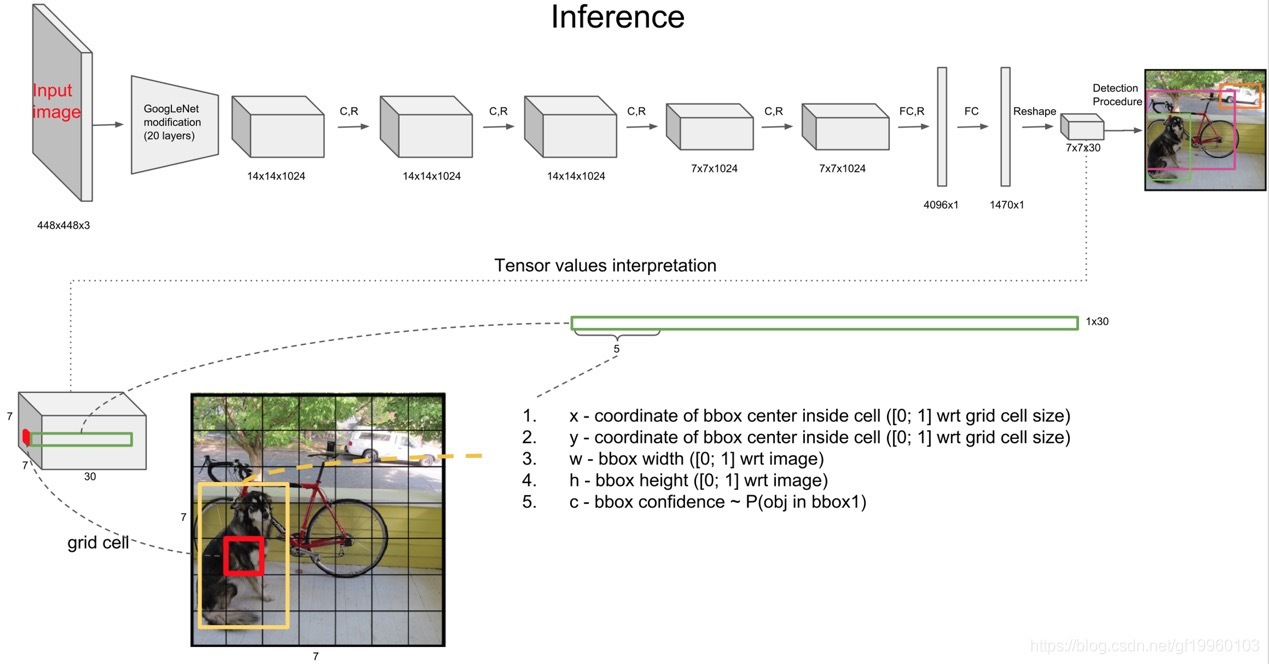
該網路是根據GoogLeNet改進的,輸入圖片為448*448大小,輸出為7×7×(2×5+20),將原始圖片分為S×S個單元格,之后的輸出是以單元格為單位進行的,如果一個object的中心落在某個單元格上,那么這個單元格負責預測這個物體,每個單元格需要預測B個box值(box值包括坐標和寬高),同時為每個box值預測一個置信度(confidence scores),也就是每個單元格需要預測B×(4+1)個值,每個單元格需要預測C(物體種類個數)個條件概率值,所以,最后網路的輸出維度為S×S×(B×5+C),這里雖然每個單元格負責預測一種物體,但是每個單元格可以預測多個box值,
那么如何利用YOLOv3訓練自己的模型呢?
首先需要一批圖片資料,比如以下資料:
圖片包括100張貓狗兩種型別的圖片,其次需要對這批圖片進行label的制作,即某張圖片的貓在哪里、狗在哪里、利用Labellmg等工具進行label的制作,

點擊save后會生成以xml結尾的label檔案,內容如下:
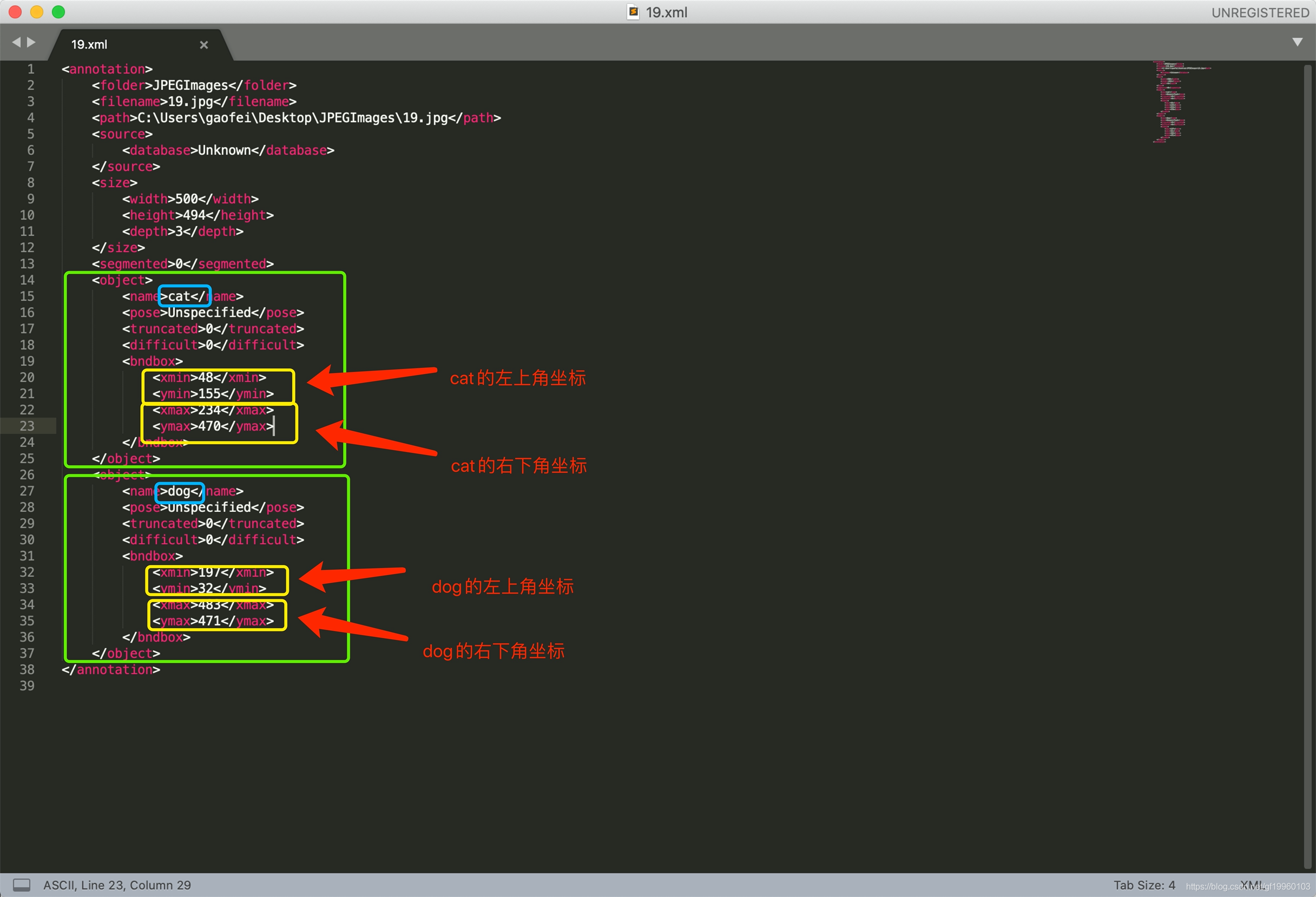
由于該圖片中只包含兩個關鍵目標,即只有兩個object,并存盤相對應的object的坐標,到此已經初步生成了圖片的label,
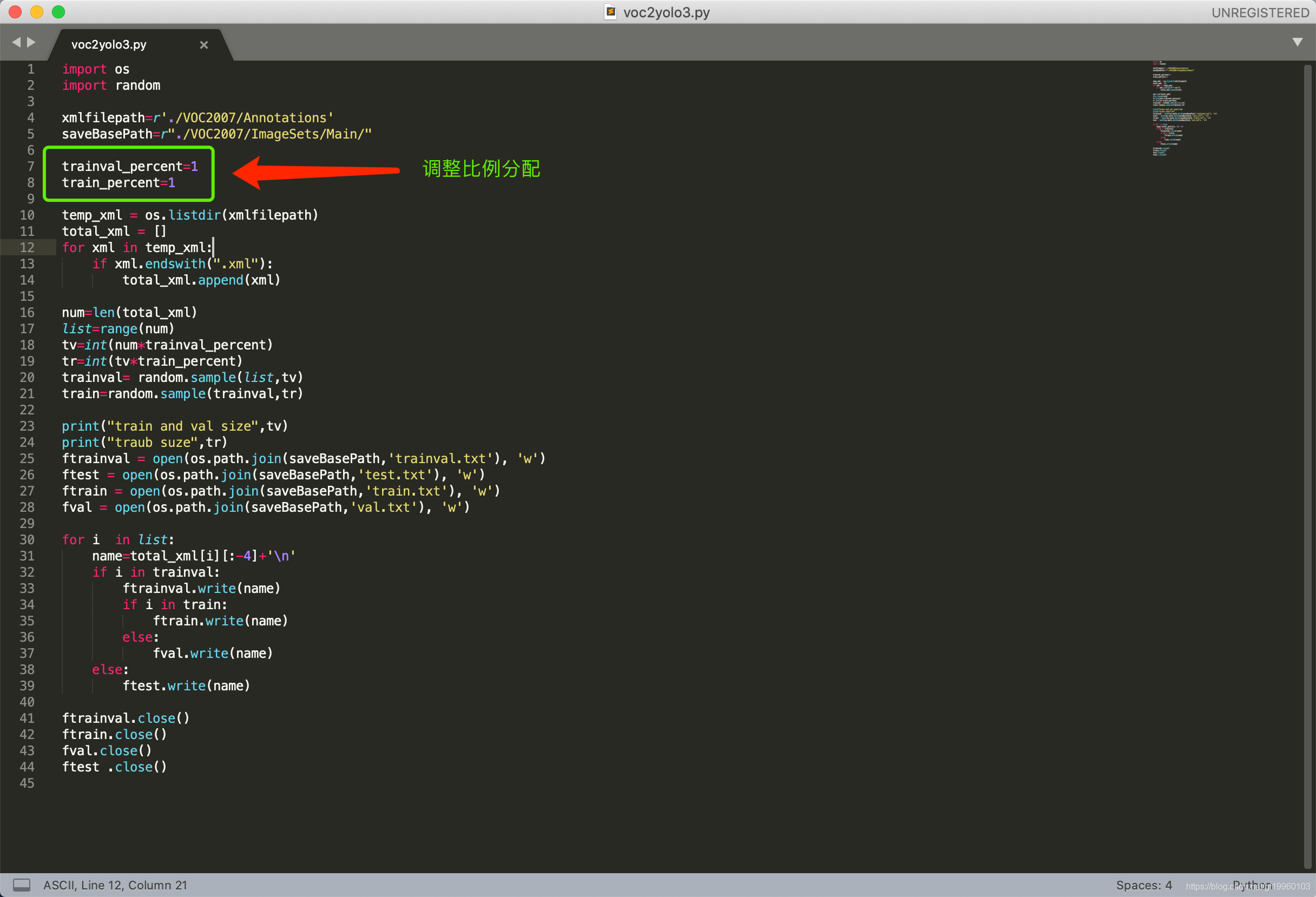
其次,將資料劃分為訓練集、測驗集、驗證集,執行以下腳本:
最后,將.xml資料轉化為YOLO需要的VOC資料,執行以下腳本:
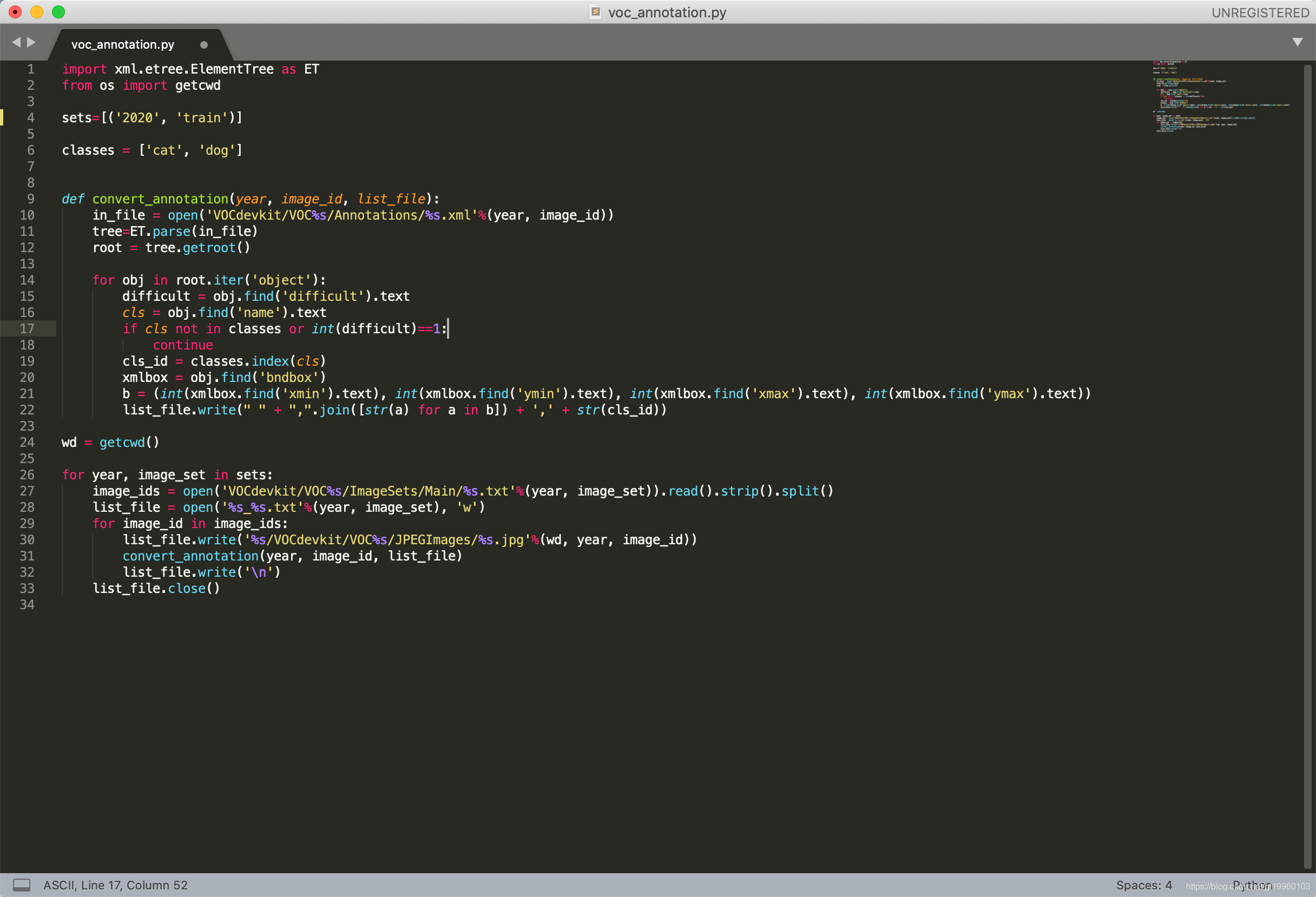
在資料準備完成后,即可進行模型訓練,
作業系統:MacOS 10.15.6
Python:3.7.6
Tensorflow:1.13
Keras:2.15
OpenCV:4.3.0
部分訓練代碼如下:
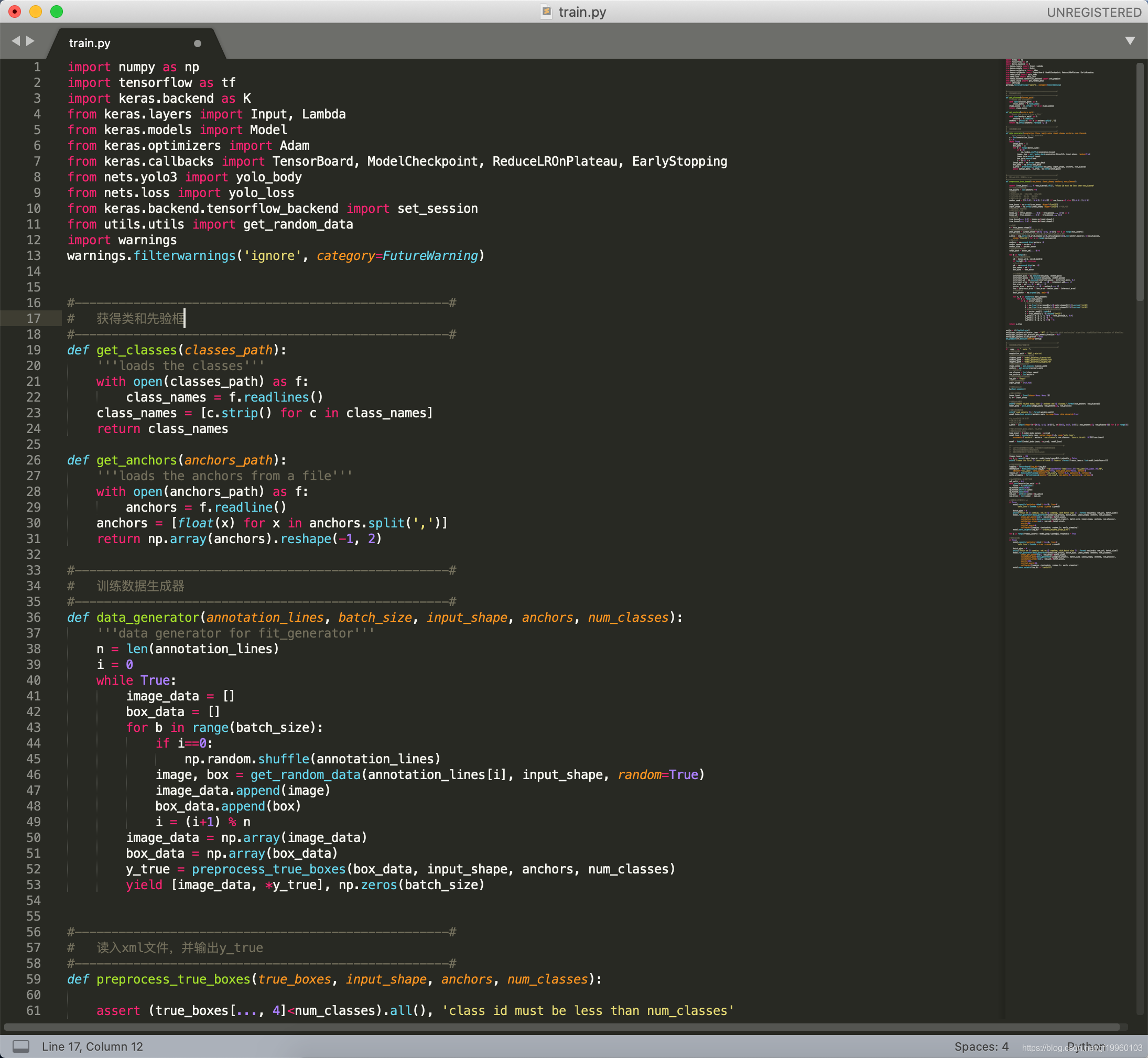
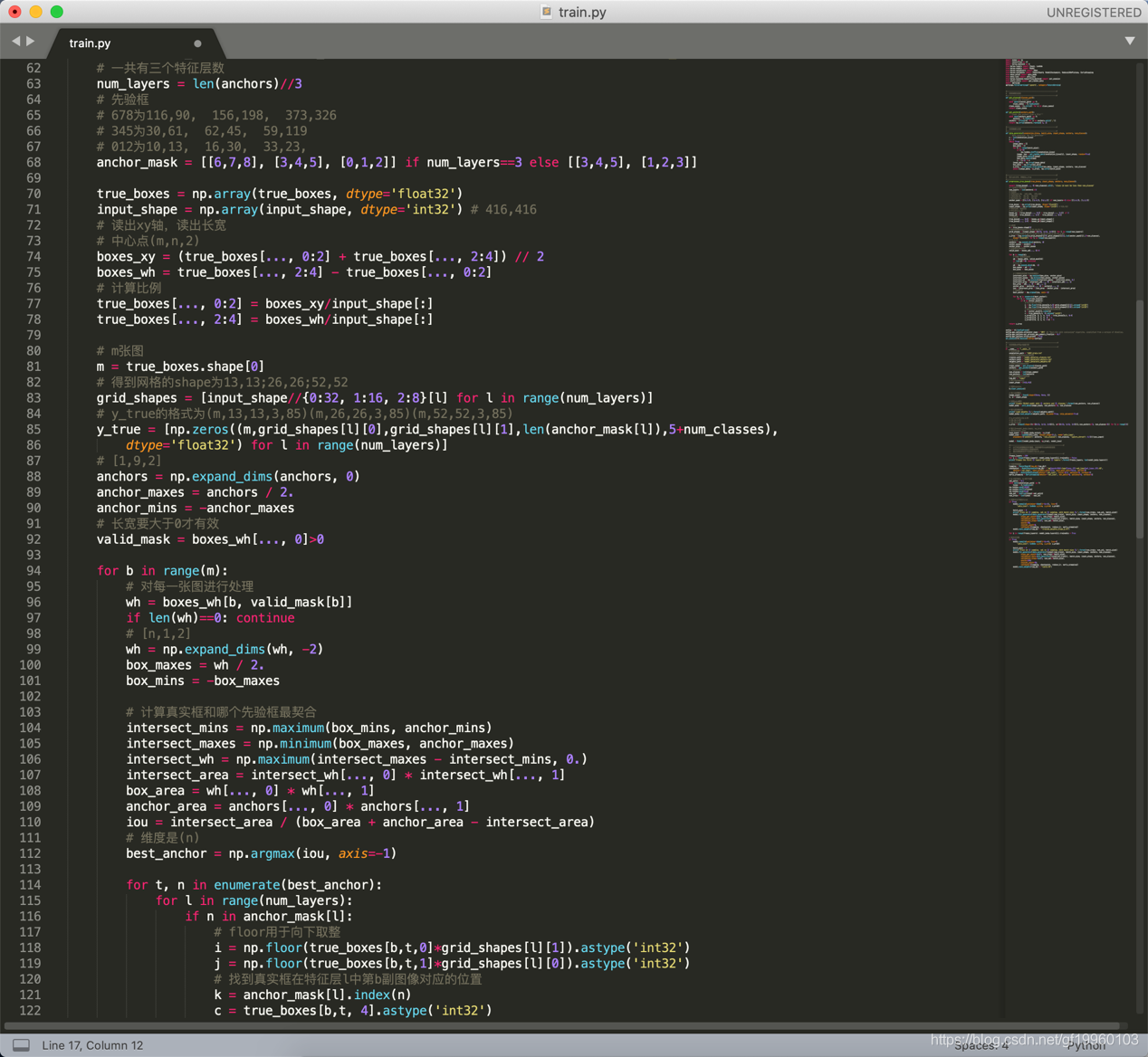
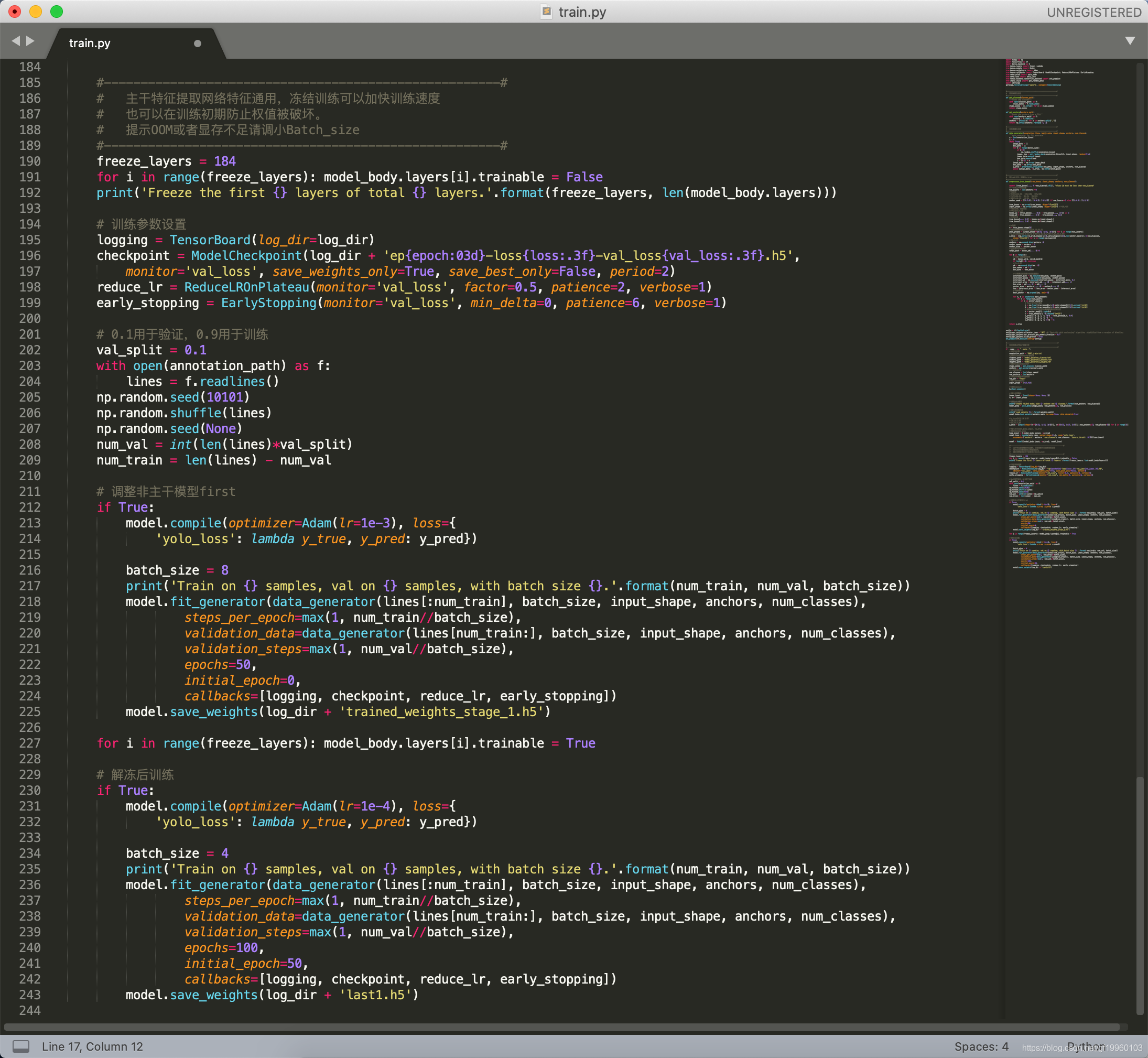 在訓練完成后,會在logs檔案下生產模型的權重檔案及神經網路模型結構可視化檔案等,部分模型結構如下:
在訓練完成后,會在logs檔案下生產模型的權重檔案及神經網路模型結構可視化檔案等,部分模型結構如下:
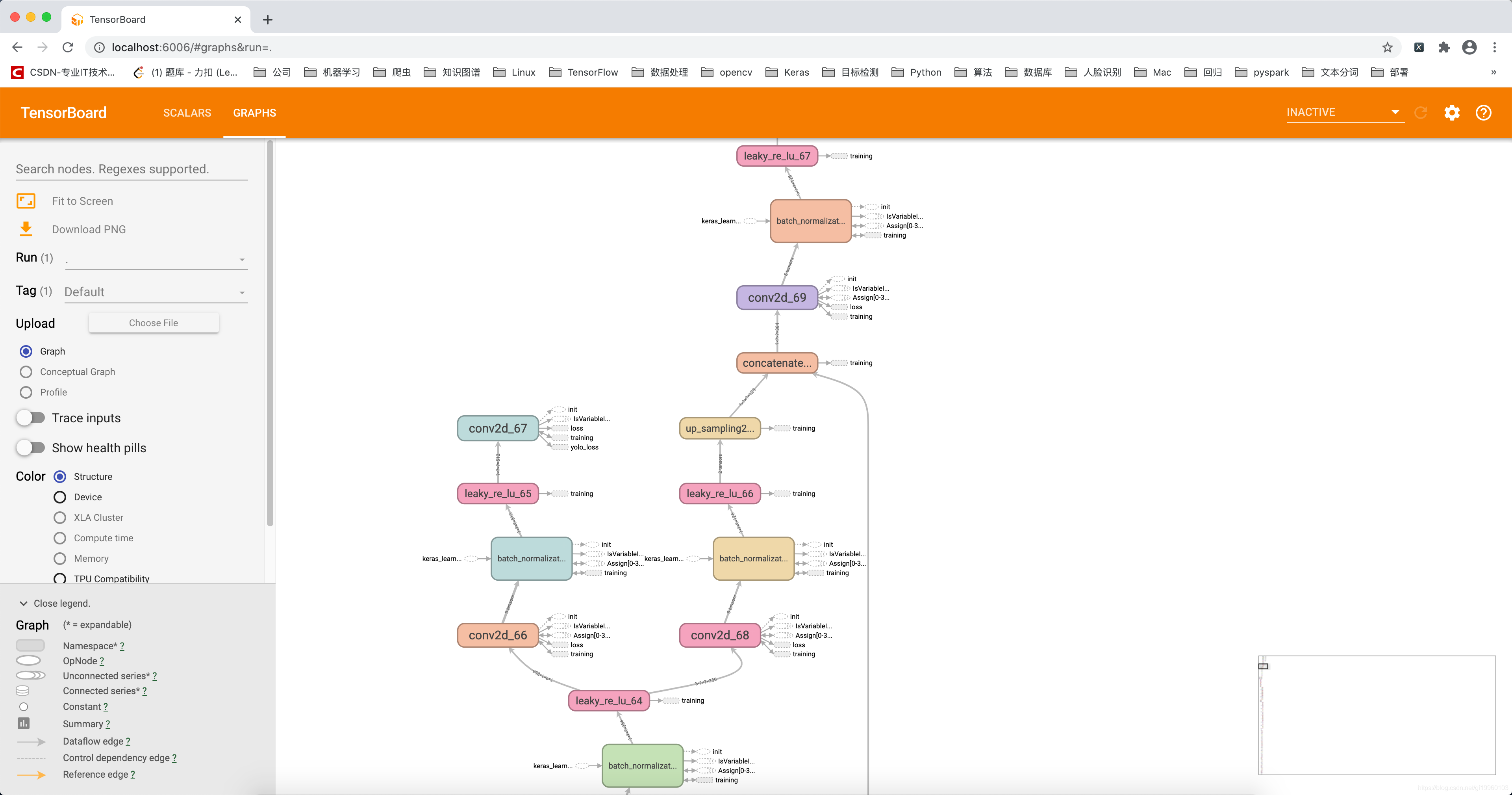
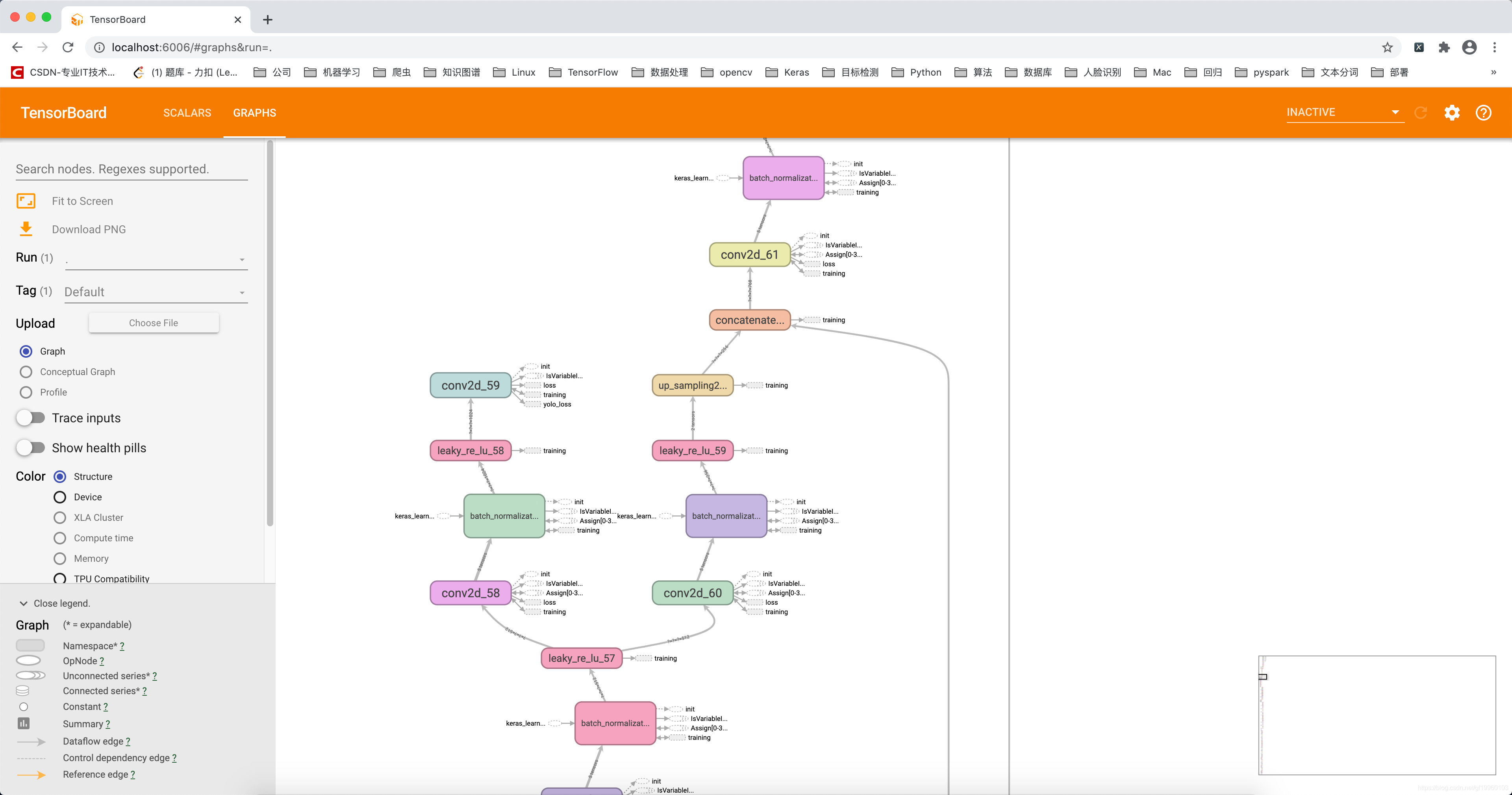
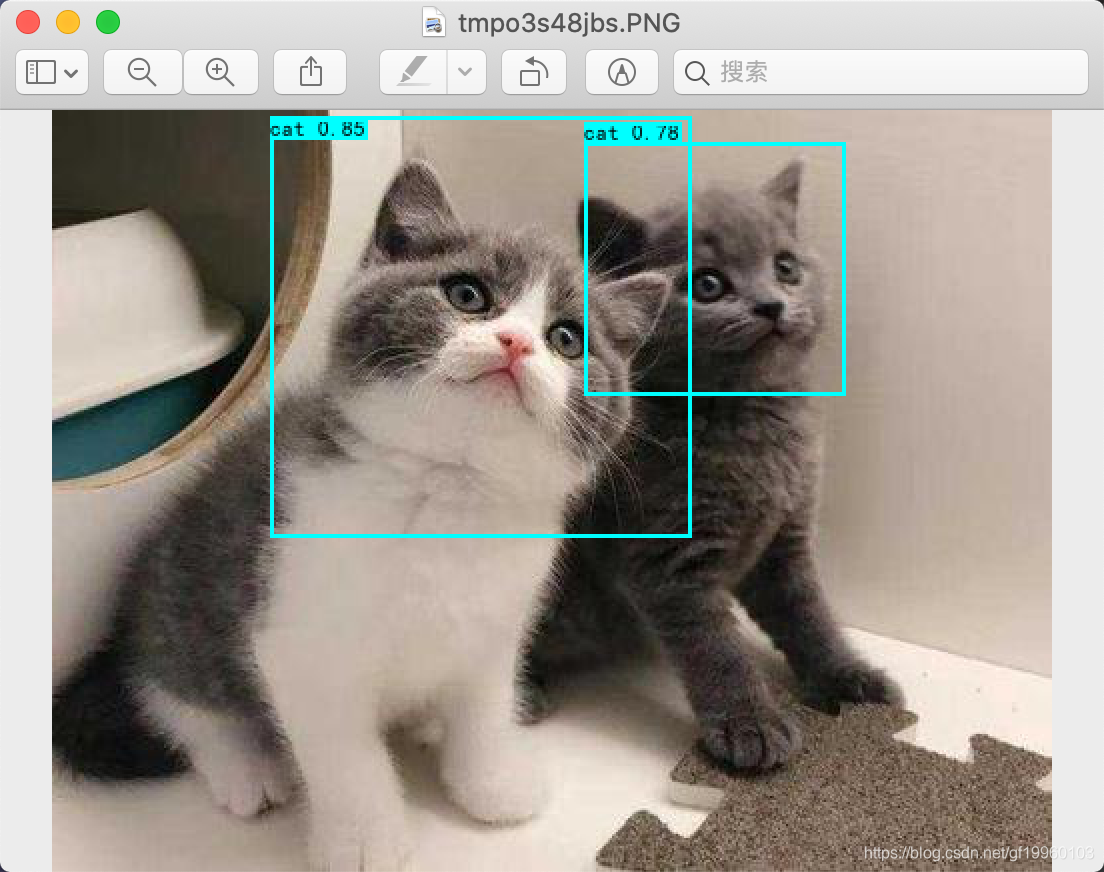
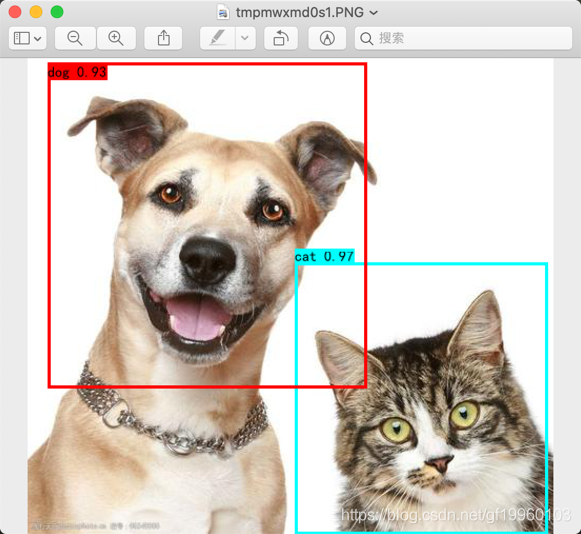
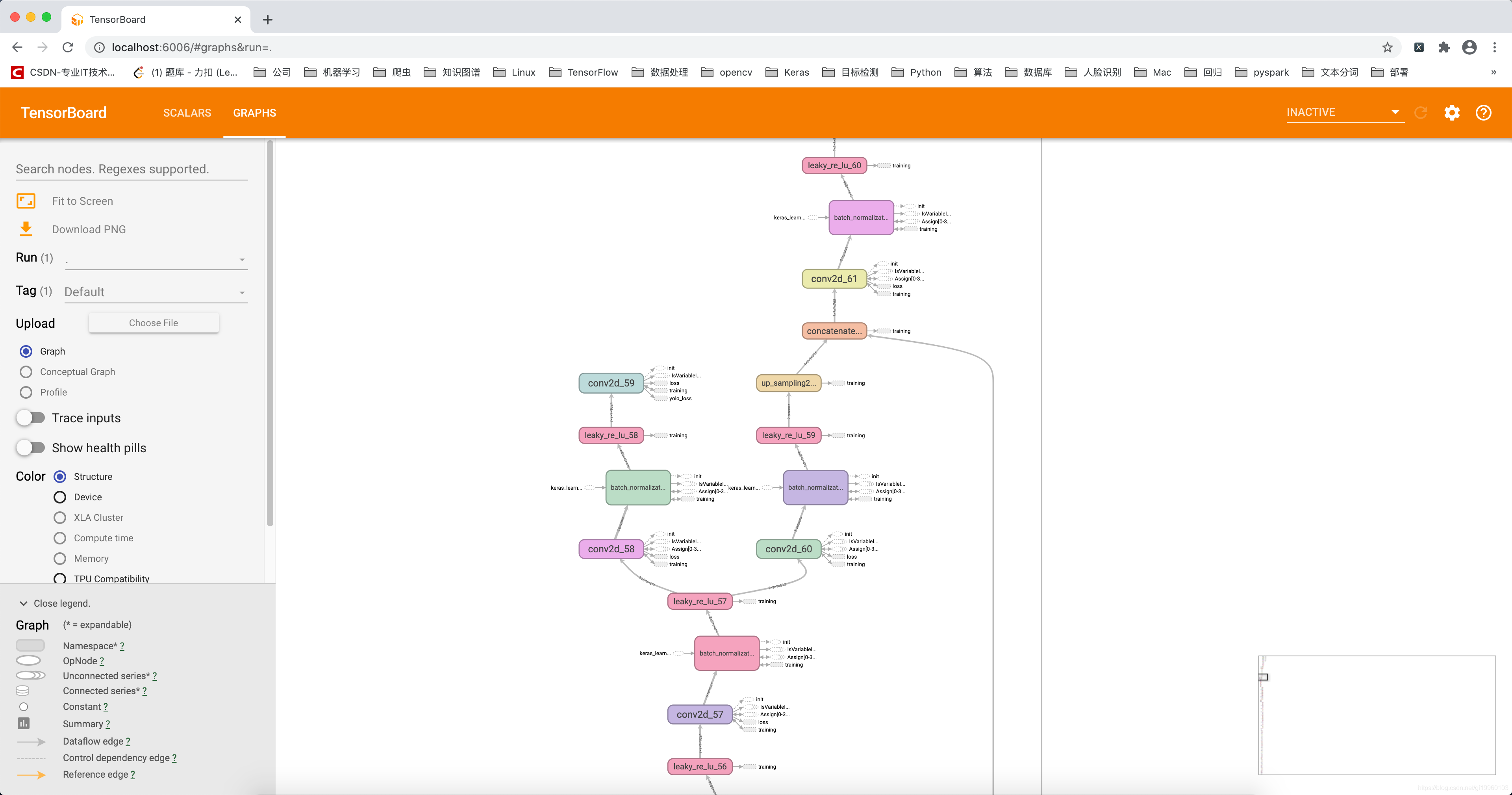 模型測驗效果如下:
模型測驗效果如下:






轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/196729.html
標籤:其他
上一篇:C/C++初學者的第四次筆記(基本運算子/算數運算式)
下一篇:快速推匯出等比數列的求和公式