作者|Ramya Vidiyala
編譯|VK
來源|Towards Data Science
深度學習改善了我們生活的許多方面,無論是明顯的還是微妙的,深度學習在電影推薦系統、垃圾郵件檢測和計算機視覺等程序中起著關鍵作用,
盡管圍繞深度學習作為黑匣子和訓練難度的討論仍在進行,但在醫學、虛擬助理和電子商務等眾多領域都存在著巨大的潛力,
在藝術和技術的交叉點,深度學習可以發揮作用,為了進一步探討這一想法,在本文中,我們將研究通過深度學習程序生成機器學習音樂的程序,許多人認為這一領域超出了機器的范圍(也是另一個激烈辯論的有趣領域!),
目錄
-
機器學習模型的音樂表現
-
音樂資料集
-
資料處理
-
模型選擇
-
RNN
-
時間分布全連接層
-
狀態
-
Dropout層
-
Softmax層
-
優化器
-
音樂生成
-
摘要
機器學習模型的音樂表現
我們將使用ABC音樂符號,ABC記譜法是一種簡寫的樂譜法,它使用字母a到G來表示音符,并使用其他元素來放置附加值,這些附加值包括音符長度、鍵和裝飾,
這種形式的符號開始時是一種ASCII字符集代碼,以便于在線音樂共享,為軟體開發人員添加了一種新的簡單的語言,便于使用,以下是ABC音樂符號,
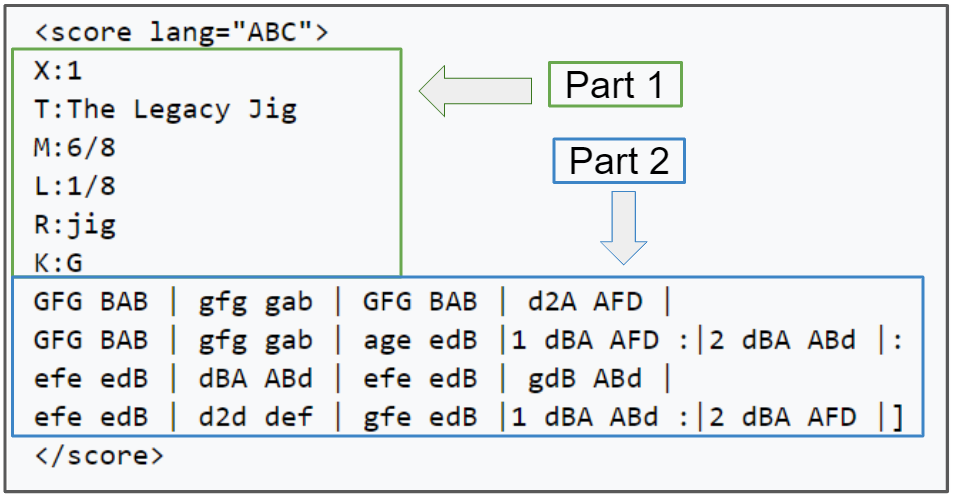
樂譜記譜法第1部分中的行顯示一個字母后跟一個冒號,這些表示曲調的各個方面,例如當檔案中有多個曲調時的索引(X:)、標題(T:)、時間簽名(M:)、默認音符長度(L:)、曲調型別(R:)和鍵(K:),鍵名稱后面代表旋律,
音樂資料集
在本文中,我們將使用諾丁漢音樂資料庫ABC版上提供的開源資料,它包含了1000多首民謠曲調,其中絕大多數已被轉換成ABC符號:http://abc.sourceforge.net/NMD/
資料處理
資料當前是基于字符的分類格式,在資料處理階段,我們需要將資料轉換成基于整數的數值格式,為神經網路的作業做好準備,
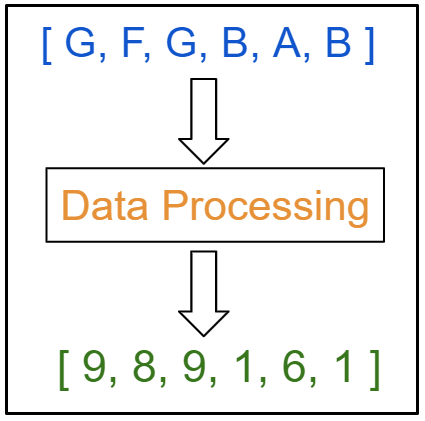
這里每個字符都映射到一個唯一的整數,這可以通過使用一行代碼來實作,“text”變數是輸入資料,
char_to_idx = { ch: i for (i, ch) in enumerate(sorted(list(set(text)))) }
為了訓練模型,我們使用vocab將整個文本資料轉換成數字格式,
T = np.asarray([char_to_idx[c] for c in text], dtype=np.int32)
機器學習音樂生成的模型選擇
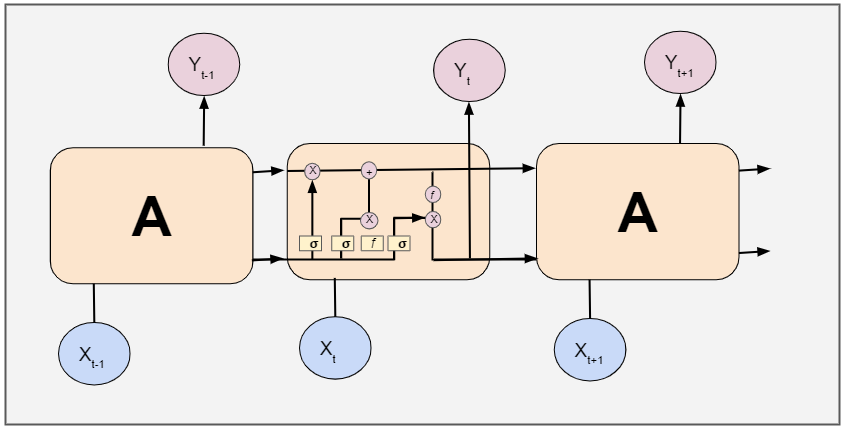
在傳統的機器學習模型中,我們無法存盤模型的前一階段,然而,我們可以用回圈神經網路(通常稱為RNN)來存盤之前的階段,
RNN有一個重復模塊,它從前一級獲取輸入,并將其輸出作為下一級的輸入,然而,RNN只能保留最近階段的資訊,因此我們的網路需要更多的記憶體來學習長期依賴關系,這就是長短期記憶網路(LSTMs),
LSTMs是RNNs的一個特例,具有與RNNs相同的鏈狀結構,但有不同的重復模塊結構,
這里使用RNN是因為:
-
資料的長度不需要固定,對于每一個輸入,資料長度可能會有所不同,
-
可以存盤序列,
-
可以使用輸入和輸出序列長度的各種組合,
除了一般的RNN,我們還將通過添加一些調整來定制它以適應我們的用例,我們將使用“字符級RNN”,在字符RNNs中,輸入、輸出和轉換輸出都是以字符的形式出現的,

RNN
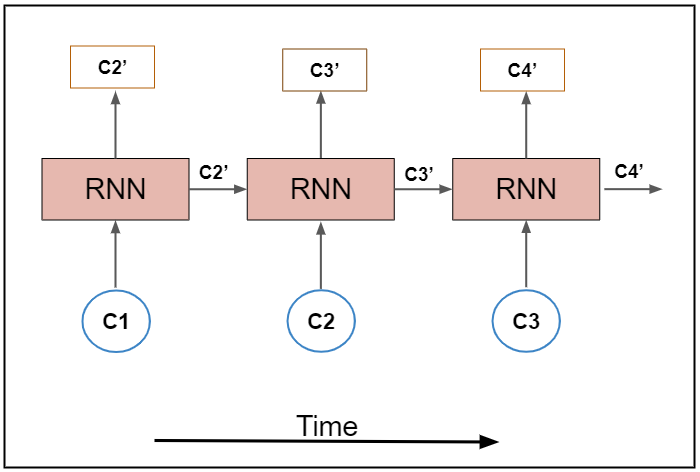
由于我們需要在每個時間戳上生成輸出,所以我們將使用許多RNN,為了實作多個RNN,我們需要將引數“return_sequences”設定為true,以便在每個時間戳上生成每個字符,通過查看下面的圖5,你可以更好地理解它,
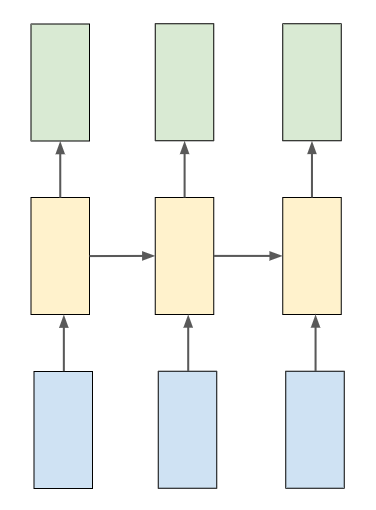
在上圖中,藍色單位是輸入單位,黃色單位是隱藏單位,綠色單位是輸出單位,這是許多RNN的簡單概述,為了更詳細地了解RNN序列,這里有一個有用的資源:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
時間分布全連接層
為了處理每個時間戳的輸出,我們創建了一個時間分布的全連接層,為了實作這一點,我們在每個時間戳生成的輸出之上創建了一個時間分布全連接層,
狀態
通過將引數stateful設定為true,批處理的輸出將作為輸入傳遞給下一批,在組合了所有特征之后,我們的模型將如下面圖6所示的概述,
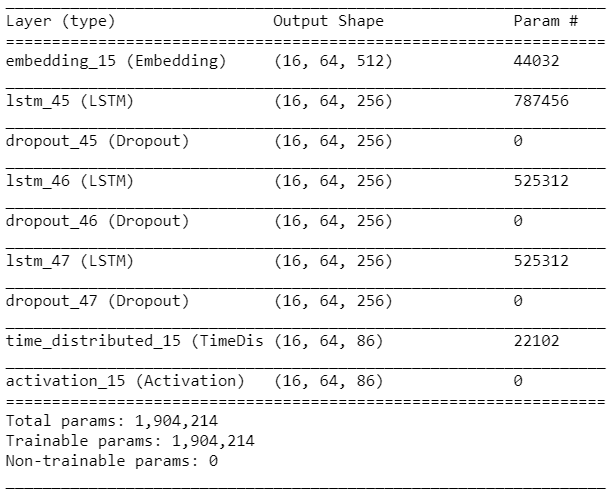
模型體系結構的代碼片段如下:
model = Sequential()
model.add(Embedding(vocab_size, 512, batch_input_shape=(BATCH_SIZE, SEQ_LENGTH)))
for i in range(3):
model.add(LSTM(256, return_sequences=True, stateful=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(vocab_size)))
model.add(Activation('softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
我強烈建議你使用層來提高性能,
Dropout層
Dropout層是一種正則化技術,在訓練程序中,每次更新時將輸入單元的一小部分歸零,以防止過擬合,
Softmax層
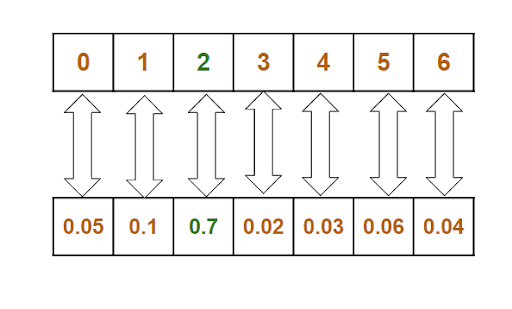
音樂的生成是一個多類分類問題,每個類都是輸入資料中唯一的字符,因此,我們在我們的模型上使用了一個softmax層,并將分類交叉熵作為一個損失函式,
這一層給出了每個類的概率,從概率串列中,我們選擇概率最大的一個,
優化器
為了優化我們的模型,我們使用自適應矩估計,也稱為Adam,因為它是RNN的一個很好的選擇,
生成音樂
到目前為止,我們創建了一個RNN模型,并根據我們的輸入資料對其進行訓練,該模型在訓練階段學習輸入資料的模式,我們把這個模型稱為“訓練模型”,
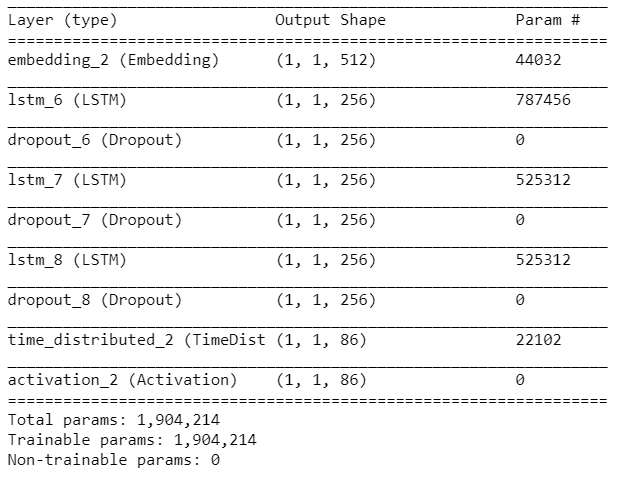
在訓練模型中使用的輸入大小是批大小,對于通過機器學習產生的音樂來說,輸入大小是單個字符,所以我們創建了一個新的模型,它和""訓練模型""相似,但是輸入一個字符的大小是(1,1),在這個新模型中,我們從訓練模型中加載權重來復制訓練模型的特征,
model2 = Sequential()
model2.add(Embedding(vocab_size, 512, batch_input_shape=(1,1)))
for i in range(3):
model2.add(LSTM(256, return_sequences=True, stateful=True))
model2.add(Dropout(0.2))
model2.add(TimeDistributed(Dense(vocab_size)))
model2.add(Activation(‘softmax’))
我們將訓練好的模型的權重加載到新模型中,這可以通過使用一行代碼來實作,
model2.load_weights(os.path.join(MODEL_DIR,‘weights.100.h5’.format(epoch)))
model2.summary()
在音樂生成程序中,從唯一的字符集中隨機選擇第一個字符,使用先前生成的字符生成下一個字符,依此類推,有了這個結構,我們就產生了音樂,

下面是幫助我們實作這一點的代碼片段,
sampled = []
for i in range(1024):
batch = np.zeros((1, 1))
if sampled:
batch[0, 0] = sampled[-1]
else:
batch[0, 0] = np.random.randint(vocab_size)
result = model2.predict_on_batch(batch).ravel()
sample = np.random.choice(range(vocab_size), p=result)
sampled.append(sample)
print("sampled")
print(sampled)
print(''.join(idx_to_char[c] for c in sampled))
以下是一些生成的音樂片段:
-
https://soundcloud.com/ramya-vidiyala-850882745/gen-music-1
-
https://soundcloud.com/ramya-vidiyala-850882745/gen-music-2
-
https://soundcloud.com/ramya-vidiyala-850882745/gen-music-3
-
https://soundcloud.com/ramya-vidiyala-850882745/gen-music-4
-
https://soundcloud.com/ramya-vidiyala-850882745/gen-music-5
我們使用被稱為LSTMs的機器學習神經網路生成這些令人愉快的音樂樣本,每一個片段都不同,但與訓練資料相似,這些旋律可用于多種用途:
-
通過靈感提升藝術家的創造力
-
作為開發新思想的生產力工具
-
作為藝術家作品的附加曲調
-
完成未完成的作業
-
作為一首獨立的音樂
但是,這個模型還有待改進,我們的訓練資料只有一種樂器,鋼琴,我們可以增強訓練資料的一種方法是添加來自多種樂器的音樂,另一種方法是增加音樂的體裁、節奏和節奏特征,
目前,我們的模式產生了一些假音符,音樂也不例外,我們可以通過增加訓練資料集來減少這些錯誤并提高音樂質量,
總結
在這篇文章中,我們研究了如何處理與神經網路一起使用的音樂,深度學習模型如RNN和LSTMs的作業原理,我們還探討了如何調整模型可以產生音樂,我們可以將這些概念應用到任何其他系統中,在這些系統中,我們可以生成其他形式的藝術,包括生成風景畫或人像,
謝謝你的閱讀!如果你想親自體驗這個定制資料集,可以在這里下載帶注釋的資料,并在Github上查看我的代碼:https://github.com/RamyaVidiyala/Generate-Music-Using-Neural-Networks
原文鏈接:https://towardsdatascience.com/music-generation-through-deep-neural-networks-21d7bd81496e
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/197186.html
標籤:其他
上一篇:車的換道檢測