1.一次性全部爬取省市區街道的資料代碼如下所示:
存在缺陷就是資料量太大容易導致爬取的時候出行丟失部分,補充比較麻煩
import urllib.request
import time
from bs4 import BeautifulSoup
class areaClass:
def fn(self):
indexs = 'index.html'
url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
txt = urllib.request.urlopen(url + indexs).read().decode('gbk')
soup = BeautifulSoup(txt, 'html.parser')
lista = soup.find_all('a')
lista.pop()
for a in lista:
#輸出省
print("s_"+a['href'][0:2] + " " + a.text)
time.sleep(1)
txt = urllib.request.urlopen(url + a['href'],timeout=5000).read().decode('gbk')
soup = BeautifulSoup(txt, 'html.parser')
listb = soup.find_all('a')
listb.pop()
bb = {}
l = len(listb)
#print("----->>>>> "+str(l/2)+" <<<<<<------")
strName = ''
for i in range(0,l-1):
if(listb[i].text == strName) :
continue
strIndex = listb[i]['href']
code = listb[i].text
codecity = code
strName = name = listb[i+1].text
#print(strIndex+","+code +"," + name)
#輸出市級
print(code + " " + name + " s_"+strIndex[0:2])
##街道url地址
url2 = url+strIndex[0:2]+'/'
time.sleep(1)
try:
ctxt = urllib.request.urlopen(url + strIndex,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
#print("----->>>>> " + str(lc / 2) + " <<<<<<------")
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codeArea = code
cstrName = name = listc[c + 1].text
#輸出區級
print(code + " " + name + " " + " "+codecity)
#街道
self.fn2(url2+strIndex,codeArea,url2+strIndex[0:2]+'/')
except:
print("")
continue
#居委會
def fn3(self,url,codejd):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('td')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(8, lc - 1):
#print(listc[c].text+"p======"+cstrName+"=======p")
if (listc[c].text == cstrName):
continue
code = listc[c].text
cstrName = name = listc[c + 2].text
#此處居委會資料還存在問題,暫時不研究了.根據你們自己需要進行配置
# 輸出居委會
print(code + "-" + name + " " + "-" + codejd+"br")
#街道
def fn2(self,url,codeArea,url2):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codejd = code
cstrName = name = listc[c + 1].text
# 輸出街道
print(code + " " + name + " " + " " + codeArea)
#self.fn3(url2 + strIndex, codejd)
areaBl = areaClass()#變數物件
areaBl.fn()
2.按省份方式爬取,以北京為例代碼如下:
網路請求不穩定的情況也會存在少數資料缺失,所以需要進行檢查再配合以3按城市的方式進行爬取.資料量越少越容易爬取
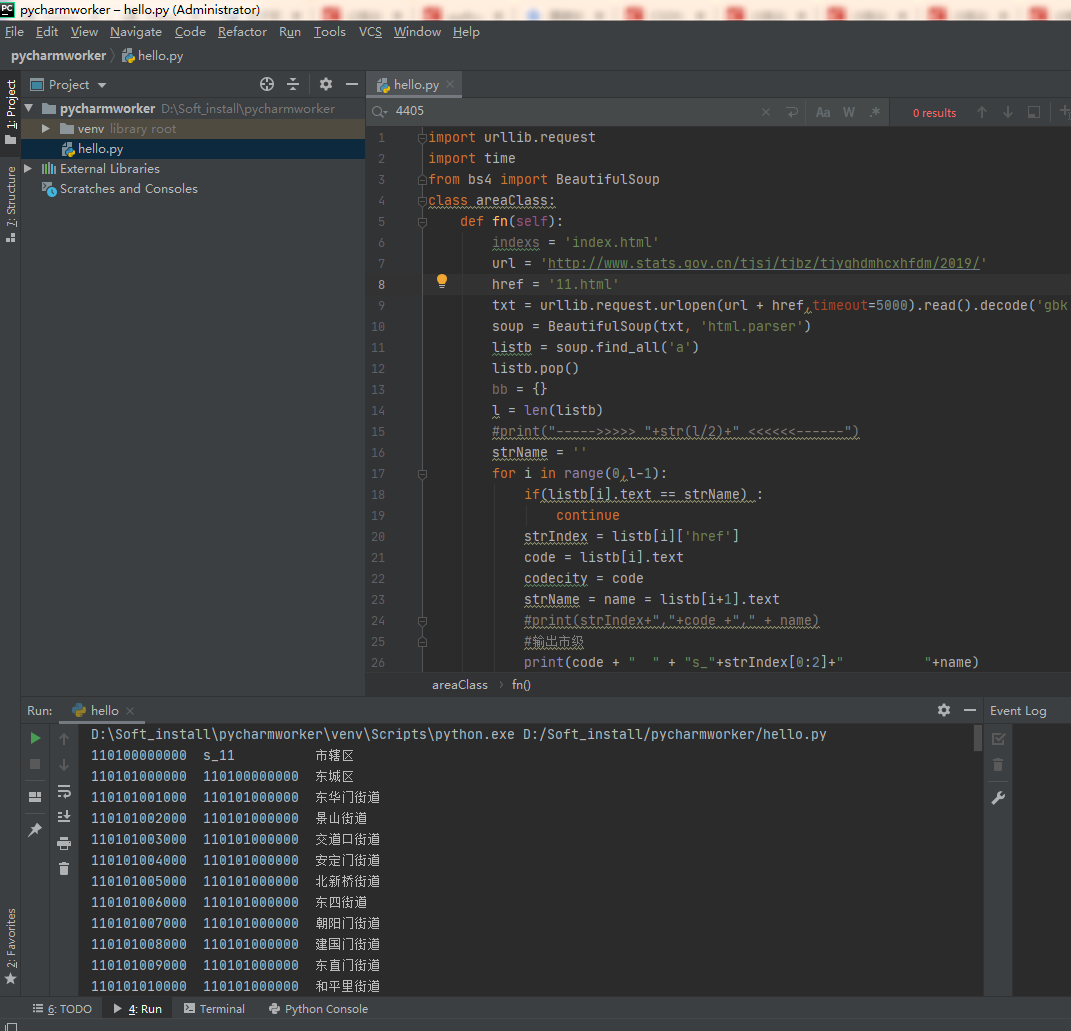
import urllib.request
import time
from bs4 import BeautifulSoup
class areaClass:
def fn(self):
indexs = 'index.html'
url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
href = '11.html'
txt = urllib.request.urlopen(url + href,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(txt, 'html.parser')
listb = soup.find_all('a')
listb.pop()
bb = {}
l = len(listb)
#print("----->>>>> "+str(l/2)+" <<<<<<------")
strName = ''
for i in range(0,l-1):
if(listb[i].text == strName) :
continue
strIndex = listb[i]['href']
code = listb[i].text
codecity = code
strName = name = listb[i+1].text
#print(strIndex+","+code +"," + name)
#輸出市級
print(code + " " + "s_"+strIndex[0:2]+" "+name)
##街道url地址
url2 = url+strIndex[0:2]+'/'
time.sleep(1)
try:
ctxt = urllib.request.urlopen(url + strIndex,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
#print("----->>>>> " + str(lc / 2) + " <<<<<<------")
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codeArea = code
cstrName = name = listc[c + 1].text
#輸出區級
print(code + " " + codecity + " " + name)
#街道
self.fn2(url2+strIndex,codeArea,url2+strIndex[0:2]+'/')
except:
print("")
continue
#居委會
def fn3(self,url,codejd):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('td')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(8, lc - 1):
#print(listc[c].text+"p======"+cstrName+"=======p")
if (listc[c].text == cstrName):
continue
code = listc[c].text
cstrName = name = listc[c + 2].text
#此處居委會資料還存在問題,暫時不研究了.根據你們自己需要進行配置
# 輸出居委會
print(code + "-" + name + " " + "-" + codejd+"br")
#街道
def fn2(self,url,codeArea,url2):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codejd = code
cstrName = name = listc[c + 1].text
# 輸出街道
print(code + " " + codeArea + " " + name)
#self.fn3(url2 + strIndex, codejd)
areaBl = areaClass()#變數物件
areaBl.fn()
3.按市爬取資料代碼如下:
這種方式爬取的資料一般而言都是不會存在問題的,除了個別市可能資料量大或者網路請求不穩定.也可以重新請求一次進行重新編譯
import urllib.request
import time
from bs4 import BeautifulSoup
class areaClass:
def fn(self):
indexs = 'index.html'
url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
strIndex = '13/1301.html'
url2 = url+strIndex[0:2]+'/'
try:
ctxt = urllib.request.urlopen(url + strIndex,timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
#print("----->>>>> " + str(lc / 2) + " <<<<<<------")
cstrName = ''
codecity = '130600000000'
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codeArea = code
cstrName = name = listc[c + 1].text
#輸出區級
print(code + " " + codecity + " " + name)
#街道
self.fn2(url2+strIndex,codeArea,url2+strIndex[0:2]+'/')
except:
print("錯誤")
#居委會
def fn3(self,url,codejd):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('td')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(8, lc - 1):
#print(listc[c].text+"p======"+cstrName+"=======p")
if (listc[c].text == cstrName):
continue
code = listc[c].text
cstrName = name = listc[c + 2].text
#此處居委會資料還存在問題,暫時不研究了.根據你們自己需要進行配置
# 輸出居委會
print(code + "-" + name + " " + "-" + codejd+"br")
#街道
def fn2(self,url,codeArea,url2):
ctxt = urllib.request.urlopen(url, timeout=5000).read().decode('gbk')
soup = BeautifulSoup(ctxt, 'html.parser')
listc = soup.find_all('a')
listc.pop()
lc = len(listc)
cstrName = ''
for c in range(0, lc - 1):
if (listc[c].text == cstrName):
continue
strIndex = listc[c]['href']
code = listc[c].text
codejd = code
cstrName = name = listc[c + 1].text
# 輸出街道
print(code + " " + codeArea + " " + name)
#self.fn3(url2 + strIndex, codejd)
areaBl = areaClass()#變數物件
areaBl.fn()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/19801.html