資料挖掘筆記-資料預處理部分(一)
- 資料預處理-年資料部分
- 設定索引與標記
- 例外值與缺失值處理
- 股票行為標記
- 歸一化
- onehot特征編碼
- 資料預處理-日資料部分
- 匯入資料與標記
- 缺失資料處理
- 資料簡化與使用方法參考
- 資料簡化
- 季度資料的幾個使用方法
- 年-日資料的匹配
- 后記與說明
注:
1.該筆記內容與資料來源于20年泰迪杯A題,以該題為例,此處僅涉及到到其年、日資料的部分預處理作業,工具為python3+jupyter,
2.此處筆記的代碼僅含比較通用的部分,即一部分個人認為比較重要的步驟的代碼塊兒,在實際做該題中需要考慮很多其他的因素與資料形式考量,而這些代碼此處未貼出(實際上是個人編程習慣太放飛自我,估計其他人看到難以理解),
3.由于時間過的較久,且當時自己代碼寫的十分凌亂,只能找時間慢慢整理,僅供參考,直接運行可能保錯,
原題為:基于資料挖掘的上市公司高送轉預測
資料預處理-年資料部分
首先將資料讀入,并匯入必備的庫:
######()、%、/三個符號利用excel全刪掉
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import imp
#from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestRegressor
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']#這東西好像可以很神奇的避免圖表文字亂碼
############
f=open(r'Adata/year1.csv',encoding='gbk')
data=pd.read_csv(f)
#data=pd.get_dummies(data)
#data=data.drop('行業分類',inplace=False)
#data= pd.get_dummies(data)
data.info()
設定索引與標記
將讀入資料設定索引,此處根據資料的特點,將‘股票編號’與‘年份年末’設計為索引,然后根據題目要求將高送轉進行定義:
data = data.set_index([data['股票編號'],data['年份年末']])###設定索引為股票編號
data.loc[data['是否高轉送']>0.49,'是否高轉送']=1
data.loc[data['是否高轉送']<0.49,'是否高轉送']=0
由于題目的特殊需求,是利用上一年資料去預測下一年是否高送轉,故此處將發生高送轉的上一年定義為即將高送轉(此處為個人做法):
##########即將高送轉標記
maxnum=max(data['股票編號'])
#print(maxnum)
jishu=np.zeros((maxnum*7,1))#將要高送轉
#print(jishu)
def jijiang(data):
for i1 in range(1,maxnum+1):
p_data=data.loc[i1]
for i2 in range(1,8):##確定了單個股票的年份數量
# print(p_data['是否高轉送'].iloc[i2-1]==1 and i2>1)
if p_data['是否高轉送'].iloc[i2-1]==1 and i2>1:
count=(i1-1)*(7)+i2-2
#print(count)
jishu[count]=1
return jishu
jishu=jijiang(data)
data['即將高送轉']=jishu
#print(data.head(15))
例外值與缺失值處理
首先對缺失的資料量進行統計,按照缺失資料的多少對資料進行排序:
df=data
missing_df = df.isnull().sum(axis=0).reset_index()
#賦予新列名
missing_df.columns = ['column_name', 'missing_count']
#將缺失值數量>0的列篩選出來
#missing_df = missing_df.iloc[missing_df['missing_count']>0]
missing_df = missing_df[missing_df['missing_count']>0]
#排序
missing_df = missing_df.sort_values(by='missing_count', ascending=False)
#將缺失值以圖形形式展示出來
ind = np.arange(missing_df.shape[0])
width = 0.9
fig, ax = plt.subplots(figsize=(16,8))
rects = ax.barh(ind[1:30], missing_df.missing_count.values[1:30],color='coral')
ax.set_yticks(ind[1:30])
ax.set_yticklabels(missing_df.column_name[1:30].values, rotation='horizontal')
ax.set_xlabel("缺失值數量")
ax.set_title("年資料-缺失量前30的標簽的缺失值數量圖",fontsize=20)
plt.tick_params(labelsize=14)
fig.savefig('年資料缺失.png')
#fig.imsave('年資料缺失值')
生成示例圖如下:
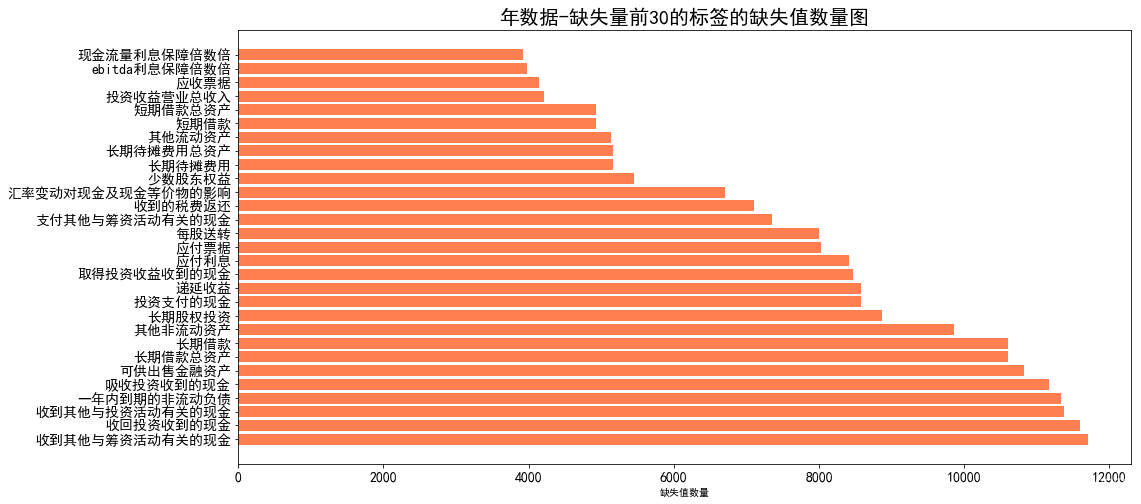
然后,個人做法為,對缺失較多(超過40%)與例外的資料,將該年整行進行洗掉,缺失較少的資料利用線性回歸進行填補:
洗掉缺失較多的資料:
#######沒有資料的年份洗掉
data=data[~data.固定資產合計.isnull()]
data.info()
#data.to_csv('nu.csv',encoding='gbk')
###########缺失值大于10000的值洗掉
df=data
missing_df = df.isnull().sum(axis=0).reset_index()
#賦予新列名
missing_df.columns = ['column_name', 'missing_count']
#將缺失值數量>0的列篩選出來
#missing_df = missing_df.iloc[missing_df['missing_count']>0]
missing_df = missing_df[missing_df['missing_count']>12313]
for i in range(0,len(missing_df.values[:,0])):
data.pop(missing_df.values[i,0])
#data.info()
缺失較少的利用線性回歸進行填補:
#######找出沒有缺失的資料,并找出需要用線性回歸填補的資料
data=data[~data.固定資產合計.isnull()]
data.info()
#data.to_csv('nu.csv',encoding='gbk')
df=data
missing_df = df.isnull().sum(axis=0).reset_index()
#賦予新列名
missing_df.columns = ['column_name', 'missing_count']
#將缺失值數量>0的列篩選出來
no_missing = missing_df[missing_df['missing_count']<1]
missing_data = missing_df[missing_df['missing_count']<2000]
missing_data = missing_data[missing_data['missing_count']>1]
####缺失值填補程式,線性回歸
from sklearn.linear_model import LinearRegression
def miss_data(data):
for i in range(0,len(missing_data)):
#print(i)
#print('\n')
str1=missing_data['column_name'].iloc[i]
#df.loc[(df.工程物資=='NAN'),'工程物資']=='0'
yinshou_df=data[np.r_[np.array([str1]),np.array(no_missing['column_name'])]]
# print(yinshou_df)
known=yinshou_df[yinshou_df[str1].notnull()].as_matrix()
unknown=yinshou_df[yinshou_df[str1].isnull()].as_matrix()
#print(unknown)
y = known[:, 0]
x = known[:, 1:]
rfr = LinearRegression()
rfr.fit(x, y)
predictedyinshou = rfr.predict(unknown[:,1::])
data.loc[(df[str1].isnull()), str1] = predictedyinshou
return df
get_data=miss_data(data)
股票行為標記
?由于股票可能有發生高送轉,即將高送轉,連續高送轉等行為,可以進行標記;可能會有用;我這里考慮到發生高送轉的那一年股票各項數值突出,可能誤判,也做了標記(具體原因涉及到經濟學方面意義了,這里可以忽略):
##########進行篩選,篩除高送發生的行和避免篩除年份為7的行,將第七年標記為
df=get_data
#datak=get_data
df.loc[(df['是否高轉送']==1)&(df['年份年末']==7) ,'是否高轉送']=2
#k['是否高轉送']=2
df.loc[(df['是否高轉送']==1)&(df['即將高送轉']==1) ,'是否高轉送']=3
df=df[df['是否高轉送']!=1]
data=df
歸一化
?在附件的年資料中,由于不同量綱的資料取值與變換率差異較大,若直接將這些資料直接進行建模會產生極大的誤差,故此處先將資料進行標準化處理,此處采用均值方差標準化的方法,使得處理后的資料均值為0,標準差為1,其計算公式如下:
x
i
?
=
x
i
?
μ
σ
,
(
i
=
1
,
2...
,
n
)
x_i^* = \frac{{{x_i} - \mu }}{\sigma },(i = 1,2...,n)
xi??=σxi??μ?,(i=1,2...,n)
? 均值方差標準化能消除資料的數值與度量不同帶來的計算誤差,
?另注,在歸一化中,由于年資料各個股票的資料以股票為單位進行排列,此處歸一化時也應該按照股票編號對各個股票單獨歸一化,
代碼如下:
#歸一化
import numpy as np
shang=2##此處shang與xia分別為需要歸一化的資料標簽范圍,可自行調節
xia=244
a=data['股票編號'].values
a=np.unique(a)
maxnum=len(a)
def guiyihua(data1):
for j in range(1,maxnum+1):
# num = data.index[data['股票編號'] == j].tolist()
pre_data = data1.loc[a[j-1]][np.r_[np.array(data.columns[2:xia].values)]]
df=pre_data
#print(a[j-1])
df_norm = (df - df.mean()) / (df.std())
#print(df_norm)
data1.loc[a[j-1]][np.r_[np.array(data.columns[2:xia].values)]]=df_norm
#print(data1)
return data1
datachuli=data[np.r_[np.array(data.columns[2:xia].values)]]
data_norm=guiyihua(datachuli)
data[np.r_[np.array(data.columns[2:xia].values)]]=data_norm
data=data.fillna(0)
data.to_csv('years1.csv', encoding='gbk')#輸出為檔案
onehot特征編碼
?在基礎資料中,存在多種文字描述的股票型別描述,利用文本資訊提取,可 以獲取到”次新股”,”國家隊”,”*ST”等關鍵詞,此處需要將這些類別型的變數轉化 為二分類可處理的離散變數
import pandas as pd
import numpy as np
nianxian=pd.read_csv('war/basic.csv',encoding='gbk')
nianxian=nianxian.set_index([nianxian['股票編號']])
nianxian_hangye=pd.get_dummies(nianxian['所屬行業'])
key=data['股票編號'].values
key1=nianxian_hangye.columns.values
for i in range(0,len(data['股票編號'].values)):
data.loc[key[i]]['分類']=nianxian.loc[key[i]]['所屬行業']
onehot_data=pd.get_dummies(data['分類'])
資料預處理-日資料部分
1.這一部分就放個人認為比較重要的幾個操作的代碼
2.日資料較大,約4個g左右,初學者可以拿這個練練,我也是初學,
匯入資料與標記
? 首先匯入資料,并按照年-月-日對資料進行索引標記
import numpy as np
import pandas as pd
from datetime import datetime
from datetime import timedelta
from matplotlib import pyplot as plt
import matplotlib
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
#data.isnull().sum(axis=0).reset_index()
####資料匯入與編號
data=pd.read_csv('Adata/day.csv',encoding='gbk')
#data=pd.read_csv('test1.csv',encoding='gbk')
periods = pd.PeriodIndex(year=data["年"], month=data["月"], day=data["日"],freq='D')
#periods=pd.PeriodIndex(data['股票編號'])
data = data.set_index([data['股票編號'],periods])####
#df1=data.set_index(data['股票編號'],append=True)
缺失資料處理
? 首先對缺失較多的進行洗掉
########去除資料用這個
df=data
missing_df = df.isnull().sum(axis=0).reset_index()
#賦予新列名
missing_df.columns = ['column_name', 'missing_count']
#將缺失值數量>0的列篩選出來
#missing_df = missing_df.iloc[missing_df['missing_count']>0]
missing_df = missing_df[missing_df['missing_count']>2353130]
for i in range(0,len(missing_df.values[:,0])):
data.pop(missing_df.values[i,0])
?可以對缺失的資料量多少與分布做一個可視化:
# 缺失數量分布繪圖
df=data
missing_df = df.isnull().sum(axis=0).reset_index()
#賦予新列名
missing_df.columns = ['column_name', 'missing_count']
#將缺失值數量>0的列篩選出來
#missing_df = missing_df.iloc[missing_df['missing_count']>0]
missing_df = missing_df[missing_df['missing_count']>0]
#排序
missing_df = missing_df.sort_values(by='missing_count', ascending=False)
#將缺失值以圖形形式展示出來
ind = np.arange(missing_df.shape[0])
width = 0.9
fig, ax = plt.subplots(figsize=(16,9))
rects = ax.barh(ind[1:30], missing_df.missing_count.values[1:30], color='coral')
ax.set_yticks(ind[1:30])
ax.set_yticklabels(missing_df.column_name.values[1:30], rotation='horizontal')
ax.set_xlabel("缺失值數量")
ax.set_title("日資料-每個標簽的缺失值數量圖",fontsize=18)
plt.tick_params(labelsize=12)
#fig.savefig('日資料缺失.png')
#fig.imsave('年資料缺失值')
plt.show()
?考慮到原資料較大,用擬合去填補缺失值耗時太久,可以直接給填個0,把缺失值填補了
data.fillna(0)
資料簡化與使用方法參考
資料簡化
?如果考慮到自己電腦吃不消,可以將這約4000個股票,7年,每年200多天的資料,按照季度去取平均,按季度統計,以縮小資料量,當然,這樣做肯定會造成部分資訊遺漏,也有其它更好的辦法去處理:
#data.loc[1].index.quarter.max().plot()
datachuli=data[np.r_[np.array(data.columns[1:60].values)]]
maxnum=max(data['股票編號'])
maxyear=max(data['年'])
df=pd.DataFrame()
for i1 in range(1,maxnum+1):
for i2 in range(1,maxyear+1):
# print(i2)
#datachuli=datachuli.loc[1].loc[data['年']==1]
pre_data=datachuli.loc[i1]
pre_data=pre_data.loc[pre_data['年']==i2]
#pre_data=datachuli.loc[data['年']==i2]
#pre_data=pre_data.loc[i1]
#pre_data.pop('年')
pre_data.pop('月')
pre_data.pop('日')
jilu=pre_data.groupby(pre_data.index.quarter).mean()
jilu=jilu.set_index([[i1,i1,i1,i1],[1,2,3,4]])###1,2,3,4.共四個季度;
df=df.append(jilu)
#print(jilu)
#df.to_csv('result/dayyy.csv',encoding='gbk')##資料匯出
季度資料的幾個使用方法
資料的形式: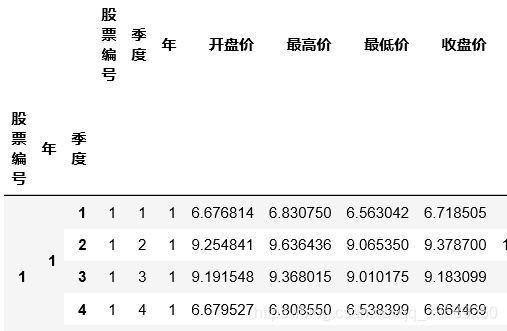
?通過經濟學意義,如果判斷一個公司經營情況,可以通過計算季度增長率去判斷,比如求四季度相對一季度的各項指標增長率:
data.fillna(0)
a=data['股票編號'].values
a=np.unique(a)
maxnum=len(a)
def get_jidu(data):
df=pd.DataFrame()
for i1 in range(0,maxnum):
# for i2 in range(1,num_gu+1):
for i3 in range(1,8):
new=(data.loc[a[i1]].loc[i3].loc[4]-data.loc[a[i1]].loc[i3].loc[1])/data.loc[a[i1]].loc[i3].loc[1]
df=df.append(new,ignore_index=True)
return df
df1=get_jidu(data[np.r_[np.array(data.columns[3:48].values)]])
a3=np.array([])
for i2 in range(1,3467):
a=np.arange(1,8)
a3=np.append(a3,a)
a2=np.array([])
for i in range(1,3467):
a1=np.array([i,i,i,i,i,i,i])
a2=np.append(a2,a1)
df1['股票編號']=a2
df1['年']=a3
?或者結合高送轉經濟學定義,考慮到前一年三、四季度的經營資料對其后一年的是否高送轉影響最大,將其進行提取:
#num_gu=max(data['股票編號'])
data.fillna(0)
a=data['股票編號'].values
a=np.unique(a)
maxnum=len(a)
def get_jidu(data):
df=pd.DataFrame()
for i1 in range(0,maxnum):
# for i2 in range(1,num_gu+1):
for i3 in range(1,8):
new=(data.loc[a[i1]].loc[i3].loc[3]+data.loc[a[i1]].loc[i3].loc[4])/2
df=df.append(new,ignore_index=True)
return df
df2=get_jidu(data[np.r_[np.array(data.columns[0:48].values)]
a3=np.array([])
for i2 in range(1,3467):
a=np.arange(1,8)
a3=np.append(a3,a)
a2=np.array([])
for i in range(1,3467):
a1=np.array([i,i,i,i,i,i,i])
a2=np.append(a2,a1)
df2['股票編號']=a2
df2['年']=a3])
?得到的資料同樣最好以股票代碼為一個單獨的部分,進行歸一化處理,這里就不列歸一化的代碼了,跟上面的一樣,
年-日資料的匹配
?為了方便后續計算,最好將年-日資料進行結合,按照年份與股票代碼對兩種資料進行拼接
后記與說明
? 過了這么久,想抽時間把當時比賽寫的代碼整理一下,看能不能寫成博客,結果沒想到當時代碼寫的如此凌亂,在jupyter里的寫的邏輯和運行順序都有點兒忘了,估計只有當時的自己看的懂,現在看著令人頭大,確實編程習慣也很重要啊,
?如果有人看到這博客,就當參考參考,直接運行八成會報錯,我后序看有沒有時間繼續整理糾錯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/198887.html
標籤:其他