首先附上課程中程式,無法正常運行
把2016年的url更改為今年的url:http://www.shanghairanking.cn/rankings/bcur/2020
代碼如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","學校名稱","總分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
輸出結果:
報錯
AttributeError: ‘NoneType’ object has no attribute ‘children’
尋找問題原因
先輸出網站內容,代碼如下:
from bs4 import BeautifulSoup
import requests
r = requests.get('https://www.shanghairanking.cn/rankings/bcur/2020')
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
部分輸出結果:
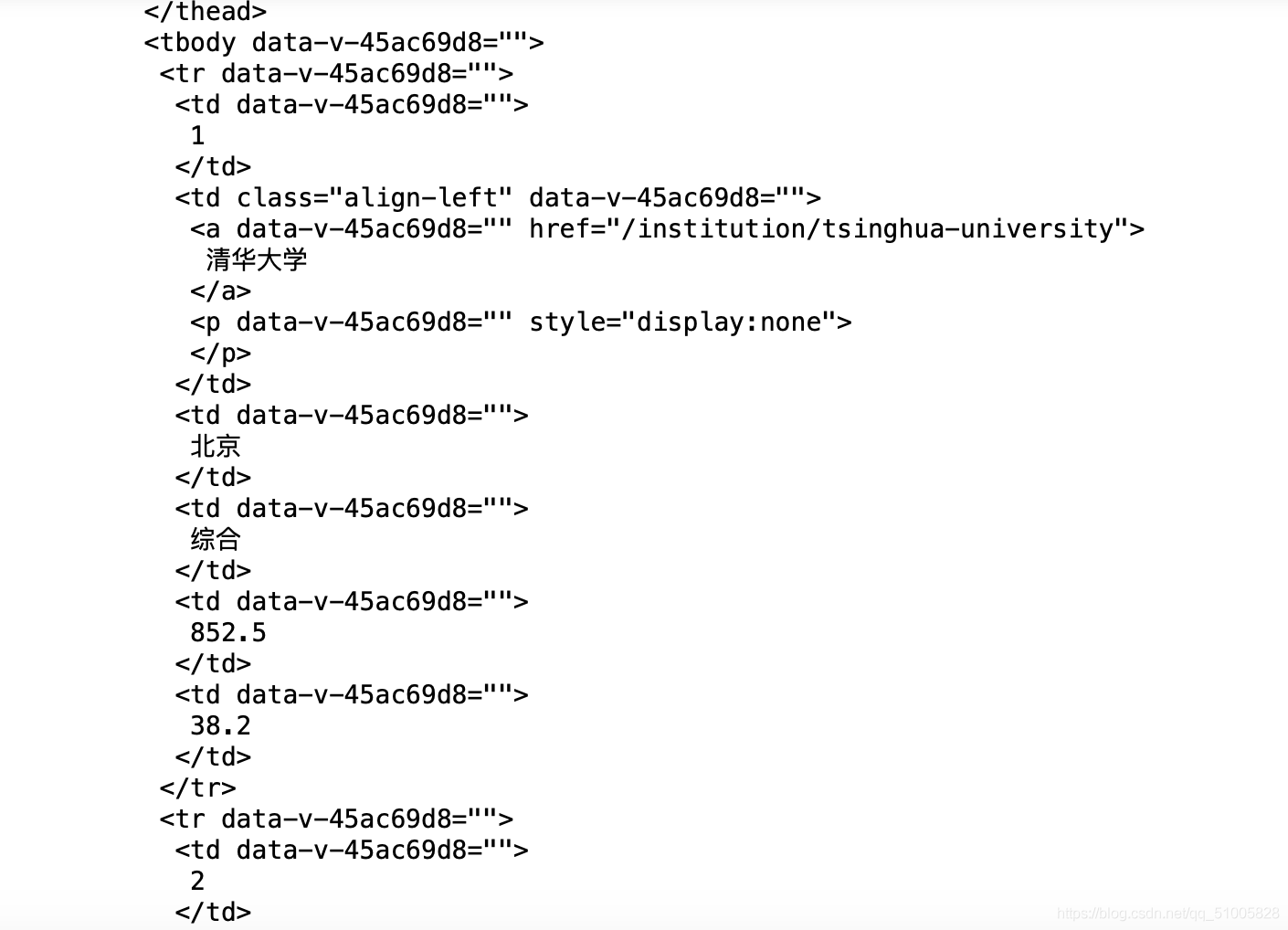
輸出結果中可以看到 tbody 標簽包含所有大學的資訊,tr 標簽包含一個大學的全部資訊,td 標簽下包含單個大學的每個資訊, 但是與嵩天老師的課件中不同的是包含大學名稱的標簽是 td 下的 a 標簽,
所以問題應該是出在獲取大學名稱部分,
將列印 ulist 的內容列印出來,
代碼如下:
將陳述句:
ulist.append([tds[0].string, tds[1].string, tds[4].string])
改為 :
ulist.append([tds[0].string, tds[1], tds[4].string])
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1], tds[4].string])
print(ulist)
輸出結果:

可以看到我們想要的內容被列印出來了,但是還有一下我們不想要的內容,
可以看到我們想要的內容在 a 標簽下,可以用 .find() 方法檢索出我們想要的內容,
代碼如下:
for a in tr.find('a'):
print('a')
輸出結果為:

這正是我們想要的內容,并把它賦給 tds,
代碼如下:
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# ulist.append([tds[0].string, tds[1], tds[4].string])
for a in tr.find('a'):
# print(a)
ulist.append([tds[0].string, a, tds[4].string])
輸出結果為:

內容正是我們想要的,但是排版不夠整齊,原因是 ulist 的內容里面含有換行符,
把ulist里面的換行符用 .replace() 方法替換掉,就不會有換行的問題了,
代碼如下:
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","學校名稱","總分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0].replace('\n',''), u[1].replace('\n',''), u[2].replace('\n','')))
輸出結果:
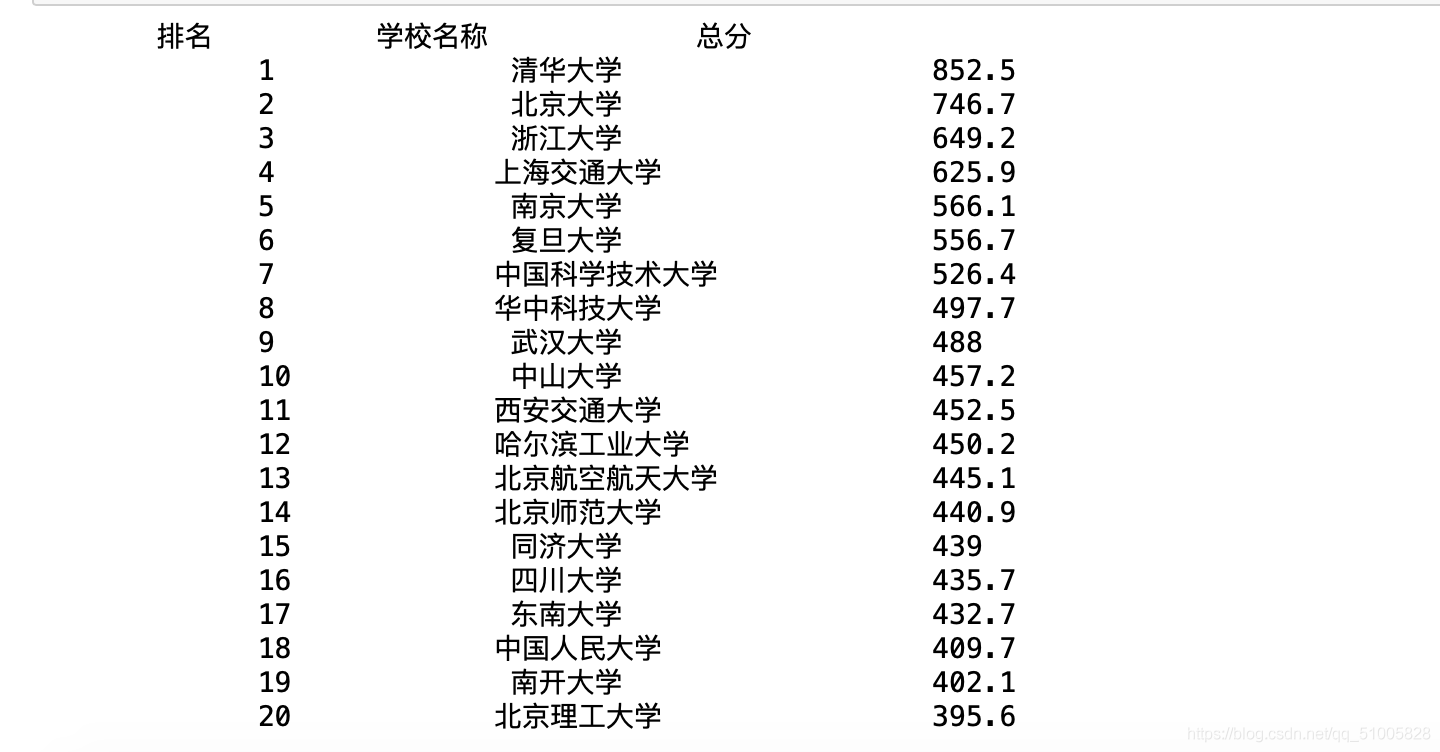
這正是我們想要的排版和內容,修改一下print() 列印出來的格式就能得到比較整齊的排版了,
程式整體代碼如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# ulist.append([tds[0].string, tds[1], tds[4].string])
for a in tr.find('a'):
# print(a)
ulist.append([tds[0].string, a, tds[4].string])
def printUnivList(ulist, num):
print(" {:^10}\t{:^6}\t {:^10}".format("排名","學校名稱","總分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0].replace('\n',''), u[1].replace('\n',''), u[2].replace('\n','')))
def main():
uinfo = []
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
輸出結果為:
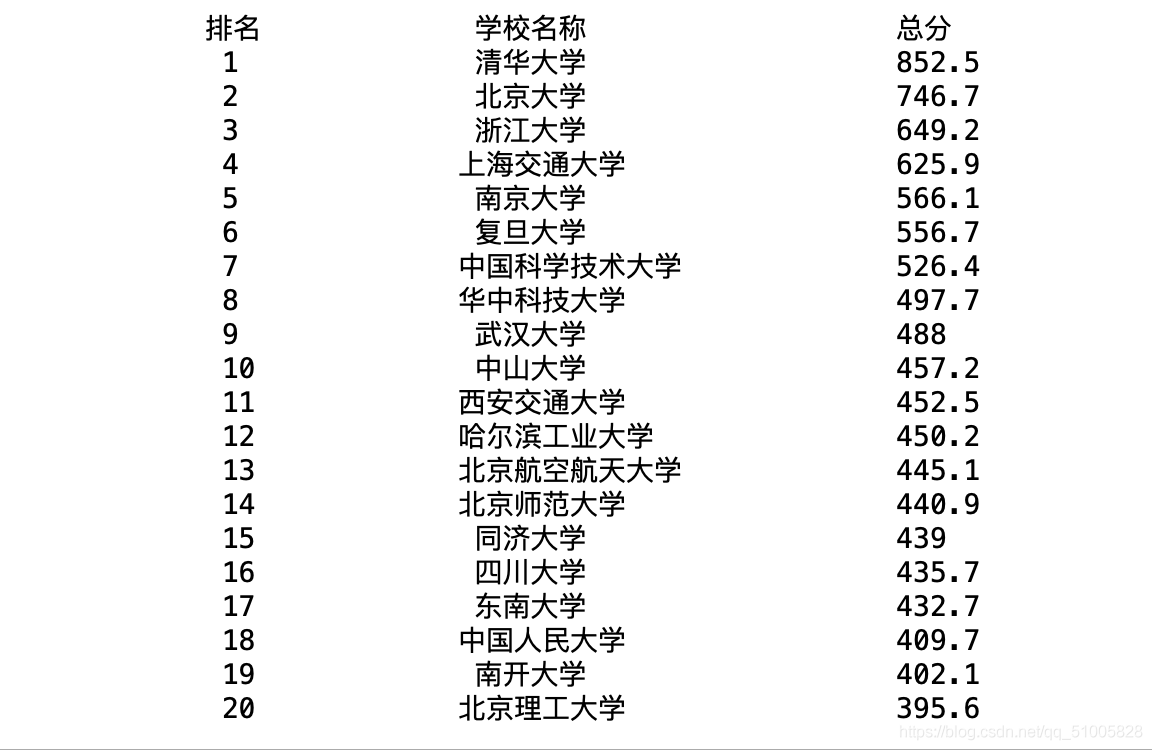
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/198899.html
標籤:其他
上一篇:爬蟲入門經典(十四) | 使用selenium嘗試爬取豆瓣圖書
下一篇:Python串列和字典的區別