簡介
最近,CCF大資料與計算智能大賽出了好幾個賽題,
CCF BDCI比賽鏈接:https://www.datafountain.cn/special/BDCI2020
比賽baseline匯總:https://github.com/datawhalechina/competition-baseline
我報名了這個《非結構化商業文本資訊中隱私資訊識別》,賽題詳情可見https://www.datafountain.cn/competitions/472,看到資料與評測說明時,這不就是NER嗎?然后我又想到了蘇大神的bert4keras(https://github.com/bojone/bert4keras),感覺bert4keras簡直就是NLP領域里baseline首選,
關于資料說明,官網已經列了,這里不在詳細,可看下圖
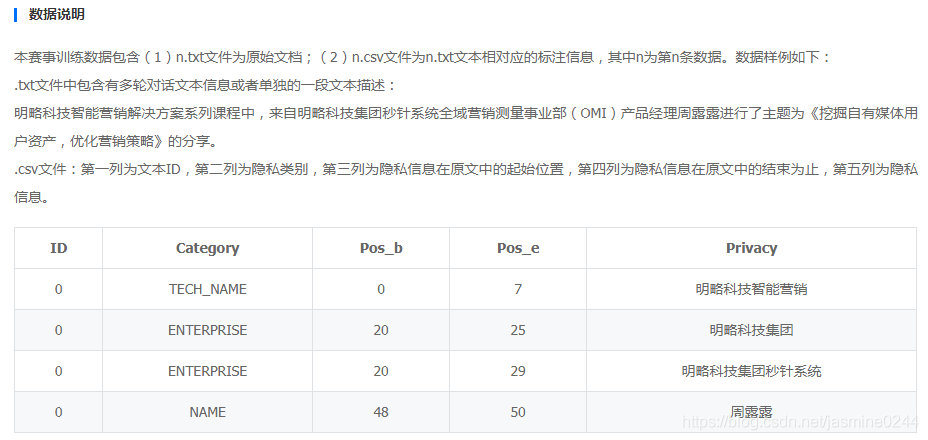
資料預處理
我們來看下文本長度分布:
import glob
import numpy as np
import matplotlib.pyplot as plt
file_list = glob.glob('./data/train/data/*.txt')
file_sizes = []
for file in file_list:
with open(file,"r") as f:
file_sizes.append(len(f.read()))
plt.hist(x = file_sizes, bins = 20, color = 'steelblue', edgecolor = 'black', rwidth=0.7)
plt.show()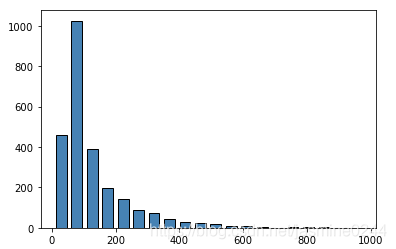
看上圖,大部分的文本長度在200以內,少數比較長,適當設定文本長度來截斷長文本
然后來看下標簽資料:
label_file_list = glob.glob('./data/train/label/*.csv')
import pandas as pd
labels = dict()
for label_file in label_file_list:
df = pd.read_csv(label_file, sep=",",encoding="utf-8")
count_df = df['Category'].value_counts()
for label in list(count_df.index):
if labels.get(label) is None:
labels[label] = count_df[label]
else:
labels[label] += count_df[label]
labels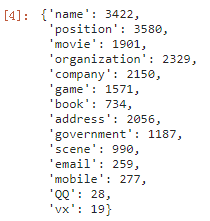
可以看到,標簽資料是嚴重不平衡的,position類別是最多的,有3580條,最少的vx只有19條,在標簽資料不平衡的情況下如何改進baseline是之后要放重點的地方,
我們需要把資料整理成以下格式:

所以一步步來,先將文本資料分句處理,再按文本長度閾值分割文本,按"字 標志屬性"統一寫入新的檔案中,我在這里將資料分了5折,用于后續交叉訓練:
def _cut(sentence):
"""
將一段文本切分成多個句子
:param sentence:
:return:
"""
new_sentence = []
sen = []
for i in sentence:
if i in [',', '!', '?', '?'] and len(sen) != 0:
sen.append(i)
new_sentence.append("".join(sen))
sen = []
continue
sen.append(i)
if len(new_sentence) <= 1: # 一句話超過max_seq_length且沒有句號的,用","分割,再長的不考慮了,
new_sentence = []
sen = []
for i in sentence:
if i.split(' ')[0] in [',', ','] and len(sen) != 0:
sen.append(i)
new_sentence.append("".join(sen))
sen = []
continue
sen.append(i)
if len(sen) > 0: # 若最后一句話無結尾標點,則加入這句話
new_sentence.append("".join(sen))
return new_sentencedef cut_test_set(text_list,len_treshold):
cut_text_list = []
cut_index_list = []
for text in text_list:
temp_cut_text_list = []
text_agg = ''
if len(text) < len_treshold:
temp_cut_text_list.append(text)
else:
sentence_list = _cut(text) # 一條資料被切分成多句話
for sentence in sentence_list:
if len(text_agg) + len(sentence) < len_treshold:
text_agg += sentence
else:
temp_cut_text_list.append(text_agg)
text_agg = sentence
temp_cut_text_list.append(text_agg) # 加上最后一個句子
cut_index_list.append(len(temp_cut_text_list))
cut_text_list += temp_cut_text_list
return cut_text_list, cut_index_listdef process_one(text_file, lable_file, w_path_, text_length):
with open(text_file,"r") as f:
text = f.read()
lines, line_len = cut_test_set([text],text_length)
df = pd.read_csv(lable_file, sep=",",encoding="utf-8")
q_dic = dict()
for index, row in df.iterrows():
cls = row[1]
start_index = row[2]
end_index = row[3]
length = end_index - start_index+1
for r in range(length):
if r == 0:
q_dic[start_index] = ("B-%s" % cls)
else:
q_dic[start_index + r] = ("I-%s" % cls)
i = 0
for idx, line in enumerate(lines):
with codecs.open(w_path_, "a+", encoding="utf-8") as w:
for str_ in line:
if str_ is " " or str_ == "" or str_ == "\n" or str_ == "\r":
pass
else:
if i in q_dic:
tag = q_dic[i]
else:
tag = "O" # 大寫字母O
w.write('%s %s\n' % (str_, tag))
i+=1
w.write('\n') import glob
import numpy as np
from sklearn.model_selection import train_test_split,KFold
import os
import pandas as pd
import codecs
file_list = glob.glob('./data/train/data/*.txt')
kf = KFold(n_splits=5, shuffle=True, random_state=999).split(file_list)
file_list = np.array(file_list)
#設定樣本長度
text_length = 250
for i, (train_fold, test_fold) in enumerate(kf):
print(len(file_list[train_fold]),len(file_list[test_fold]))
train_filelist = list(file_list[train_fold])
val_filelist = list(file_list[test_fold])
# train_file
train_w_path = f'./data/train_{i}.txt'
for file in train_filelist:
if not file.endswith('.txt'):
continue
file_name = file.split(os.sep)[-1].split('.')[0]
label_file = os.path.join("./data/train/label", "%s.csv" % file_name)
process_one(file, label_file, train_w_path, text_length)
# val_file
val_w_path = f'./data/val_{i}.txt'
for file in val_filelist:
if not file.endswith('.txt'):
continue
file_name = file.split(os.sep)[-1].split('.')[0]
label_file = os.path.join("./data/train/label", "%s.csv" % file_name)
process_one(file, label_file, val_w_path, text_length)模型構建與訓練
接下去就是建模和訓練了,
import os
import tensorflow as tf
import keras
import bert4keras
import numpy as np
from bert4keras.backend import keras, K
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.optimizers import Adam
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import open, ViterbiDecoder, to_array
from bert4keras.layers import ConditionalRandomField
from keras.layers import Dense,Bidirectional, LSTM,Dropout
from keras.models import Model
from tqdm import tqdm
maxlen = 250
epochs = 10
# batch_size = 8
bert_layers = 12
learing_rate = 3e-5 # bert_layers越小,學習率應該要越大
crf_lr_multiplier = 1500 # 必要時擴大CRF層的學習率 #500,1500
# bert配置
config_path = './publish/bert_config.json'
checkpoint_path = './publish/bert_model.ckpt'
dict_path = './publish/vocab.txt'
def load_data(filename):
D = []
with open(filename, encoding='utf-8') as f:
f = f.read()
for l in f.split('\n\n'):
if not l:
continue
d, last_flag = [], ''
for c in l.split('\n'):
try:
char, this_flag = c.split(' ')
except:
print(c)
continue
if this_flag == 'O' and last_flag == 'O':
d[-1][0] += char
elif this_flag == 'O' and last_flag != 'O':
d.append([char, 'O'])
elif this_flag[:1] == 'B':
d.append([char, this_flag[2:]])
else:
d[-1][0] += char
last_flag = this_flag
D.append(d)
return D
# 建立分詞器
tokenizer = Tokenizer(dict_path, do_lower_case=True)
# 類別映射
labels = ['name',
'movie',
'organization',
'position',
'company',
'game',
'book',
'address',
'government',
'scene',
'email',
'mobile',
'QQ',
'vx']
id2label = dict(enumerate(labels))
label2id = {j: i for i, j in id2label.items()}
num_labels = len(labels) * 2 + 1
class data_generator(DataGenerator):
"""資料生成器
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, item in self.sample(random):
token_ids, labels = [tokenizer._token_start_id], [0]
for w, l in item:
w_token_ids = tokenizer.encode(w)[0][1:-1]
if len(token_ids) + len(w_token_ids) < maxlen:
token_ids += w_token_ids
if l == 'O':
labels += [0] * len(w_token_ids)
else:
B = label2id[l] * 2 + 1
I = label2id[l] * 2 + 2
labels += ([B] + [I] * (len(w_token_ids) - 1))
else:
break
token_ids += [tokenizer._token_end_id]
labels += [0]
segment_ids = [0] * len(token_ids)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append(labels)
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
def bertmodel():
model = build_transformer_model(
config_path,
checkpoint_path,
)
output_layer = 'Transformer-%s-FeedForward-Norm' % (bert_layers -1)
output = model.get_layer(output_layer).output
output = Dense(num_labels)(output) # 27分類
CRF = ConditionalRandomField(lr_multiplier=crf_lr_multiplier)
output = CRF(output)
model = Model(model.input, output)
# model.summary()
model.compile(
loss=CRF.sparse_loss,
optimizer=Adam(learing_rate),
metrics=[CRF.sparse_accuracy]
)
return model,CRF
class NamedEntityRecognizer(ViterbiDecoder):
"""命名物體識別器
"""
def recognize(self, text):
tokens = tokenizer.tokenize(text)
mapping = tokenizer.rematch(text, tokens)
token_ids = tokenizer.tokens_to_ids(tokens)
segment_ids = [0] * len(token_ids)
token_ids, segment_ids = to_array([token_ids], [segment_ids])
nodes = model.predict([token_ids, segment_ids])[0]
labels = self.decode(nodes)
entities, starting = [], False
for i, label in enumerate(labels):
if label > 0:
if label % 2 == 1:
starting = True
entities.append([[i], id2label[(label - 1) // 2]])
elif starting:
entities[-1][0].append(i)
else:
starting = False
else:
starting = False
return [(text[mapping[w[0]][0]:mapping[w[-1]][-1] + 1], l)
for w, l in entities]
def evaluate(data):
"""評測函式
"""
X, Y, Z = 1e-10, 1e-10, 1e-10
for d in tqdm(data):
text = ''.join([i[0] for i in d])
R = set(NER.recognize(text)) # 預測
T = set([tuple(i) for i in d if i[1] != 'O']) #真實
X += len(R & T)
Y += len(R)
Z += len(T)
precision, recall = X / Y, X / Z
f1 = 2*precision*recall/(precision+recall)
return f1, precision, recall
class Evaluator(keras.callbacks.Callback):
def __init__(self,valid_data, mode=0):
self.best_val_f1 = 0
self.valid_data = valid_data
self.mode=mode # k折的時候記錄第幾折
def on_epoch_end(self, epoch, logs=None):
trans = K.eval(CRF.trans)
NER.trans = trans
# print(NER.trans)
f1, precision, recall = evaluate(self.valid_data)
# 保存最優
if f1 >= self.best_val_f1:
self.best_val_f1 = f1
model.save_weights('./best_bilstm_model_{}.weights'.format(self.mode))
logger.info(
'valid: f1: %.5f, precision: %.5f, recall: %.5f, best f1: %.5f\n' %
(f1, precision, recall, self.best_val_f1)
)
batch_size = 12
train_data = load_data(f'./data/train_0.txt')
valid_data = load_data(f'./data/val_0.txt')
model,CRF = bertmodel()
NER = NamedEntityRecognizer(trans=K.eval(CRF.trans), starts=[0], ends=[0])
evaluator = Evaluator(valid_data)
train_generator = data_generator(train_data, batch_size)
model.fit_generator(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=epochs,
callbacks=[evaluator]
)
預測
這里要注意一下,
1.屬性要小寫,官網上列舉的樣例是大寫,我一開始也改成大寫了,然后提交的時候老是報錯,后來還是網友指點才改成小寫的,
2.預測end的時候,要記得-1,第一次成功提交的時候,分數只有0.003...,看到這個分數,肯定是起始/終止位置搞錯了,很快就發現了,
3.df.to_csv()的時候,encoding要設定為utf-8-sig,我一開始設定的utf-8,報錯,網上查了說要加-sig
def test_predict(data, NER_):
test_ner =[]
for text in tqdm(data):
cut_text_list, cut_index_list = cut_test_set([text],maxlen)
posit = 0
item_ner = []
index =1
for str_ in cut_text_list:
ner_res = NER_.recognize(str_)
for tn in ner_res:
ans = {}
ans["label_type"] = tn[1]
ans['overlap'] = "T" + str(index)
ans["start_pos"] = text.find(tn[0],posit)
ans["end_pos"] = ans["start_pos"] + len(tn[0])-1
posit = ans["end_pos"]
ans["res"] = tn[0]
item_ner.append(ans)
index +=1
test_ner.append(item_ner)
return test_ner
test_files = os.listdir("./data/test")
ids = []
starts = []
ends = []
labels=[]
ress = []
for file in test_files:
if not file.endswith(".txt"):
continue
id_ = file.split('.')[0]
with codecs.open("./data/test/"+file, "r", encoding="utf-8") as f:
line = f.readlines()
aa = test_predict(line, NER)
for line in aa[0]:
ids.append(id_)
labels.append(line['label_type'])
starts.append(line['start_pos'])
ends.append(line['end_pos'])
ress.append(line['res'])
df=pd.DataFrame({"ID":ids, "Category":labels,"Pos_b":starts,"Pos_e":ends,"Privacy":ress})
df.to_csv("predict.csv", encoding="utf-8-sig", sep=',',index=False)其實這個baseline是深度之眼中醫藥說明書物體識別賽道指導班的導師GAuss老師提供的初版,我針對《非結構化商業文本資訊中隱私資訊識別》這個賽題,做了些改動,主要就是資料處理方面的改動,
OK,接下去的提升就要靠自己了,加油!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/198901.html
標籤:其他
上一篇:Python串列和字典的區別