作者|James Loy
編譯|VK
來源|Towards Data Science
傳統的推薦系統基于聚類、最近鄰和矩陣分解等方法,然而,近年來,深度學習在從影像識別到自然語言處理等多個領域取得了巨大的成功,推薦系統也得益于深度學習的成功,事實上,如今最先進的推薦系統,比如Youtube和Amazon的推薦系統,都是由復雜的深度學習系統驅動的,而不是傳統方法,
本教程
在閱讀了許多有用的教程,這些教程介紹了使用諸如矩陣分解等傳統方法的推薦系統的基礎知識,但我注意到,缺乏介紹基于深度學習的推薦系統的教程,在本教程中,我們將介紹以下內容:
-
如何使用PyTorch Lightning創建自己的基于深度學習的推薦系統
-
推薦系統中隱式反饋與顯式反饋的區別
-
如何在不引入偏差和資料泄漏的情況下訓練測驗分割資料集以訓練推薦系統
-
評估推薦系統的指標(提示:準確度或RMSE不合適!)
資料集
本教程使用MovieLens 20M資料集提供的電影評論,這是一個流行的電影評分資料集,包含1995年至2015年收集的2000萬部電影評論,
如果你想查看本教程中的代碼,可以查看我的Kaggle Notebook,在這里你可以運行代碼,并在本教程中查看輸出:https://www.kaggle.com/jamesloy/deep-learning-based-recommender-systems
利用隱式反饋構建推薦系統
在我們建立模型之前,重要的是要理解隱式反饋和顯式反饋之間的區別,以及為什么現代推薦系統是建立在隱式反饋的基礎上的,
顯式反饋
在推薦系統中,顯式反饋是從用戶那里收集的直接的、定量的資料,例如,亞馬遜允許用戶對購買的商品進行1-10的評分,這些評分是直接由用戶提供的,這個評分標準允許亞馬遜量化用戶的偏好,另一個明確反饋的例子包括YouTube上的贊/踩按鈕,它捕捉用戶對特定視頻的明確偏好(即喜歡或不喜歡),
然而,顯式反饋的問題是它們很少,如果你仔細想想,你上一次點擊YouTube視頻上的“喜歡”按鈕,或者對你的網上購物進行評級是什么時候?很可能你在YouTube上觀看的視頻數量遠遠大于你明確評級的視頻數量,
隱性反饋
另一方面,隱式反饋是從用戶互動中間接收集的,它們充當用戶偏好的代理,例如,你在YouTube上觀看的視頻被用作隱式反饋,為你量身定做推薦,即使你沒有明確地給視頻打分,另一個隱含反饋的例子包括你在亞馬遜上瀏覽過的商品,這些商品用來為你推薦其他類似的專案,
隱性反的優點在于它是豐富的,使用隱式反饋構建的推薦系統還允許我們通過每次點擊和互動實時定制推薦,今天,在線推薦系統是使用隱式反饋構建的,它允許系統在每次用戶互動時實時調整其推薦,
資料預處理
在開始構建和訓練我們的模型之前,讓我們做一些預處理,以獲得所需格式的MovieLens資料,
為了保持30%的資料在用戶可管理的范圍內使用,我們將只使用30%的資料集,讓我們隨機選擇30%的用戶,并且只使用所選用戶的資料,
import pandas as pd
import numpy as np
np.random.seed(123)
ratings = pd.read_csv('rating.csv', parse_dates=['timestamp'])
rand_userIds = np.random.choice(ratings['userId'].unique(),
size=int(len(ratings['userId'].unique())*0.3),
replace=False)
ratings = ratings.loc[ratings['userId'].isin(rand_userIds)]
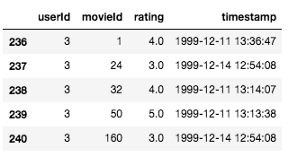
過濾資料集之后,現在有來自41547個用戶的6027314行資料(這仍然是大量資料!),資料幀中的每一行都對應于單個用戶的電影評論,如下所示,
訓練測驗拆分
除了評級之外,還有一個時間戳列,顯示提交評審的日期和時間,使用timestamp列,我們將使用留一法實作我們的訓練測驗分割策略,對于每個用戶,最新的評分被用作測驗集(即,測驗集樣本數為1),而其余的將用作訓練資料,
為了說明這一點,用戶39849審查的電影如下所示,用戶評論的最后一部電影是2014年熱映的《銀河守護者》,我們將使用這部電影作為該用戶的測驗資料,并將其余已審查的影片用作訓練資料,

在訓練和評估推薦系統時,經常使用這種訓練-測驗分割策略,做一個隨機的分割是不公平的,因為我們可能會使用用戶最近的評論進行訓練,而使用早期的評論進行測驗,這就引入了具有前瞻性偏差的資料泄漏,并且訓練后的模型的性能不能概括為真實世界的性能,
下面的代碼將使用留一法將我們的評分資料集分割為一個訓練和測驗集,
ratings['rank_latest'] = ratings.groupby(['userId'])['timestamp'].rank(method='first', ascending=False)
train_ratings = ratings[ratings['rank_latest'] != 1]
test_ratings = ratings[ratings['rank_latest'] == 1]
# 洗掉我們不再需要的列
train_ratings = train_ratings[['userId', 'movieId', 'rating']]
test_ratings = test_ratings[['userId', 'movieId', 'rating']]
將資料集轉換為隱式反饋資料集
如前所述,我們將使用隱式反饋來訓練推薦系統,然而,我們使用的MovieLens資料集是基于顯式反饋的,要將此資料集轉換為隱式反饋資料集,我們只需將評級進行二進制化并將其轉換為“1”(即正類),值“1”表示用戶已與該項互動,
需要注意的是,使用隱式反饋可以重新定義我們的推薦者試圖解決的問題,我們不是試圖在使用顯時反饋時預測電影收視率,而是試圖預測用戶是否會與每部電影互動(即點擊/購買/觀看),目的是向用戶展示具有最高互動可能性的電影,
train_ratings.loc[:, 'rating'] = 1
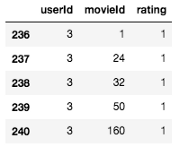
不過,我們現在確實有問題,在對資料集進行二進制化之后,我們看到資料集中的每個樣本現在都屬于正類,我們假設其余的電影是那些用戶不感興趣的電影-即使這是一個廣泛的假設,可能不是真的,它通常是相當好的實踐,
下面的代碼為每行資料生成4個負樣本,換句話說,陰性樣本與陽性樣本的比率是4:1,這個比例是任意選擇的,但我發現它在實踐中運行得相當好(你可以自己找到最好的比率!),
# 獲取所有電影id的串列
all_movieIds = ratings['movieId'].unique()
# 用于保存訓練資料的占位符
users, items, labels = [], [], []
# 這是每個用戶都與之互動的專案集
user_item_set = set(zip(train_ratings['userId'], train_ratings['movieId']))
# 4:1
num_negatives = 4
for (u, i) in user_item_set:
users.append(u)
items.append(i)
labels.append(1) # 用戶與專案有互動
for _ in range(num_negatives):
# 隨機選擇一個專案
negative_item = np.random.choice(all_movieIds)
# 檢查用戶是否與該專案進行了互動
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_movieIds)
users.append(u)
items.append(negative_item)
labels.append(0) # 代表沒有互動
太好了!我們現在有了模型所需格式的資料,在繼續之前,讓我們定義一個PyTorch資料集,以便于訓練,下面的類簡單地將上面撰寫的代碼封裝到PyTorch資料集類中,
import torch
from torch.utils.data import Dataset
class MovieLensTrainDataset(Dataset):
"""MovieLens PyTorch資料集用于訓練
Args:
ratings (pd.DataFrame): 包含電影評級的DataFrame
all_movieIds (list): 包含所有電影id的串列
"""
def __init__(self, ratings, all_movieIds):
self.users, self.items, self.labels = self.get_dataset(ratings, all_movieIds)
def __len__(self):
return len(self.users)
def __getitem__(self, idx):
return self.users[idx], self.items[idx], self.labels[idx]
def get_dataset(self, ratings, all_movieIds):
users, items, labels = [], [], []
user_item_set = set(zip(ratings['userId'], ratings['movieId']))
num_negatives = 4
for u, i in user_item_set:
users.append(u)
items.append(i)
labels.append(1)
for _ in range(num_negatives):
negative_item = np.random.choice(all_movieIds)
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_movieIds)
users.append(u)
items.append(negative_item)
labels.append(0)
return torch.tensor(users), torch.tensor(items), torch.tensor(labels)
我們的模型-神經協同過濾(NCF)
雖然有許多基于深度學習的推薦系統架構,但是我發現由He等人(https://arxiv.org/abs/1708.05031)提出的框架,是最直接的,它非常簡單,可以在這樣的教程中實作,
用戶嵌入
在深入研究模型的體系結構之前,讓我們先熟悉一下嵌入的概念,嵌入是一個低維空間,它從高維空間捕獲向量之間的關系,為了更好地理解這個概念,讓我們更仔細地研究一下用戶嵌入,
假設我們想根據用戶對兩種型別電影的偏好來代表他們——動作片和浪漫片,讓第一個維度是用戶對動作電影的喜愛程度,第二個維度是用戶對浪漫電影的喜愛程度,
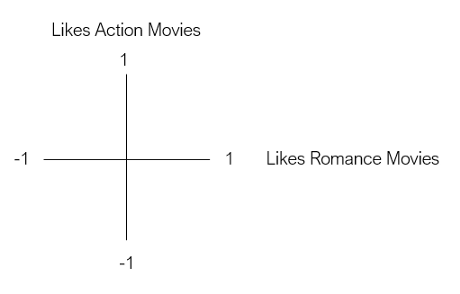
現在,假設Bob是我們的第一個用戶,鮑勃喜歡動作片,但不喜歡愛情片,為了將Bob表示為二維向量,我們根據Bob的偏好將其放置在圖中,
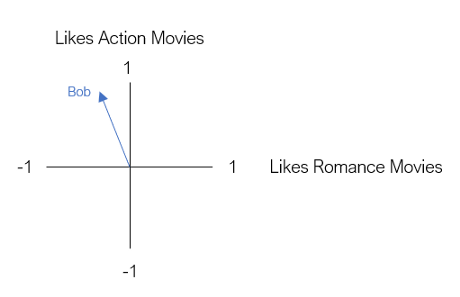
我們的下一個用戶是喬,喬是動作片和愛情片的超級粉絲,我們用一個二維向量來表示Joe,就像Bob一樣,
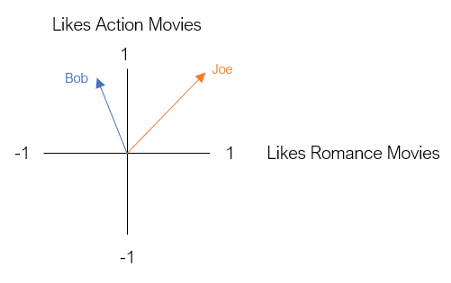
這個二維空間被稱為嵌入,本質上,嵌入減少了我們的用戶,使他們可以在一個低維空間中以有意義的方式表示,在這種嵌入中,具有相似電影偏好的用戶彼此靠近,反之亦然,
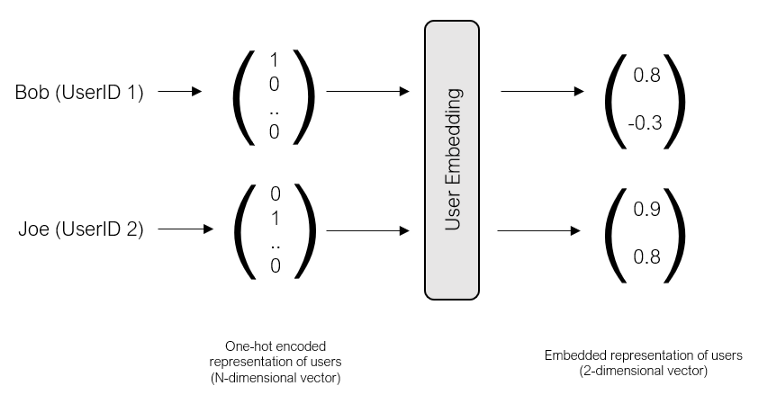
當然,我們并不局限于僅使用二維來表示我們的用戶,我們可以使用任意數量的維度來表示我們的用戶,更大數量的維度將允許我們更準確地捕捉每個用戶的特征,而代價是模型的復雜性,在我們的代碼中,我們將使用8個維度(稍后將看到),
學習嵌入
類似地,我們將使用一個單獨的專案嵌入層來表示專案(即電影)在低維空間中的特征,
你可能會想知道,我們如何了解嵌入層的權重,以便它提供用戶和專案的準確表示?在前面的示例中,我們使用了Bob和Joe對動作和浪漫電影的偏好來手動創建嵌入,有沒有辦法自動學習這種嵌入?
答案是協同過濾——通過使用分級資料集,我們可以識別相似的用戶和電影,創建從現有評級中學習到的用戶和專案嵌入,
模型體系結構
既然我們對嵌入有了更好的理解,我們就可以定義模型體系結構了,正如你將看到的,用戶和項嵌入是模型的關鍵,
讓我們使用以下訓練示例來瀏覽模型體系結構:

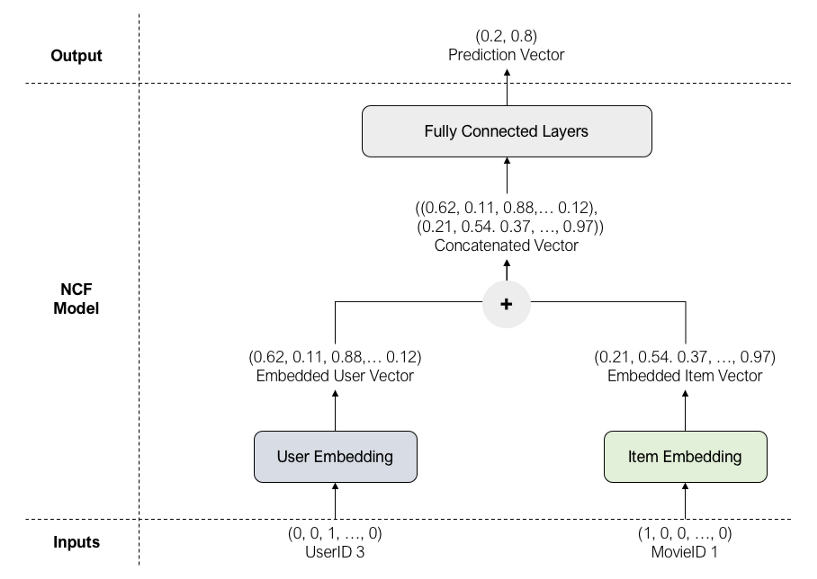
模型的輸入是userId=3和movieId=1的one-hot編碼用戶和項向量,因為這是一個正樣本(用戶實際評級的電影),所以標簽是1,
用戶向量和專案向量分別被輸入到用戶嵌入和專案嵌入中,從而得到更小、更密集的用戶和專案向量,
嵌入的用戶和專案向量在通過一系列完全連接的層之前被連接起來,這些層將連接的嵌入映射到一個預測向量中作為輸出,在輸出層,我們應用一個Sigmoid函式來獲得最可能類,在上面的例子中,由于0.8>0.2,最有可能的類是1(正類),
現在,讓我們用PyTorch Lightning來定義這個NCF模型!
import torch.nn as nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader
class NCF(pl.LightningModule):
""" 神經協同過濾(NCF)
Args:
num_users (int): 唯一用戶的數量
num_items (int): 唯一項的數量
ratings (pd.DataFrame): 包含用于訓練的電影評級
all_movieIds (list): 包含所有movieIds的串列(訓練+測驗)
"""
def __init__(self, num_users, num_items, ratings, all_movieIds):
super().__init__()
self.user_embedding = nn.Embedding(num_embeddings=num_users, embedding_dim=8)
self.item_embedding = nn.Embedding(num_embeddings=num_items, embedding_dim=8)
self.fc1 = nn.Linear(in_features=16, out_features=64)
self.fc2 = nn.Linear(in_features=64, out_features=32)
self.output = nn.Linear(in_features=32, out_features=1)
self.ratings = ratings
self.all_movieIds = all_movieIds
def forward(self, user_input, item_input):
# 通過嵌入層
user_embedded = self.user_embedding(user_input)
item_embedded = self.item_embedding(item_input)
# Concat兩個嵌入層
vector = torch.cat([user_embedded, item_embedded], dim=-1)
# 通過全連接層
vector = nn.ReLU()(self.fc1(vector))
vector = nn.ReLU()(self.fc2(vector))
# 輸出層
pred = nn.Sigmoid()(self.output(vector))
return pred
def training_step(self, batch, batch_idx):
user_input, item_input, labels = batch
predicted_labels = self(user_input, item_input)
loss = nn.BCELoss()(predicted_labels, labels.view(-1, 1).float())
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
def train_dataloader(self):
return DataLoader(MovieLensTrainDataset(self.ratings, self.all_movieIds),
batch_size=512, num_workers=4)
讓我們用GPU訓練我們的NCF模型,epoch=5
注意:PyTorch Lightning與vanilla PyTorch相比的一個優勢是,你不需要撰寫自己的訓練代碼,注意Trainer類是如何讓我們只需要幾行代碼就可以訓練我們的模型,
num_users = ratings['userId'].max()+1
num_items = ratings['movieId'].max()+1
all_movieIds = ratings['movieId'].unique()
model = NCF(num_users, num_items, train_ratings, all_movieIds)
trainer = pl.Trainer(max_epochs=5, gpus=1, reload_dataloaders_every_epoch=True,
progress_bar_refresh_rate=50, logger=False, checkpoint_callback=False)
trainer.fit(model)
評估我們的推薦系統
現在我們已經訓練出了模型,我們準備使用測驗資料來評估它,在傳統的機器學習專案中,我們使用諸如準確性(對于分類問題)和RMSE(對于回歸問題)這樣的度量來評估我們的模型,然而,這樣的度量對于評估推薦系統來說過于簡單,
為了設計一個好的評價推薦系統的指標,我們首先需要了解現代推薦系統是如何使用的,
看看Netflix,我們可以看到如下推薦串列:

同樣,亞馬遜給出:
這里的關鍵是我們不需要用戶與推薦串列中的每一項進行互動,至少我們需要用戶與串列中的一個專案進行互動,至少我們需要與該專案進行互動,
為了模擬這一點,讓我們運行下面的評估協議,為每個用戶生成一個前10個推薦項的串列,
-
對于每個用戶,隨機選擇99個用戶沒有互動的專案,
-
將這99個專案與測驗專案(用戶最后一次互動的實際專案)結合起來,我們現在有100件,
-
對這100個專案運行模型,并根據它們的預測概率對它們進行排序,
-
從100個專案串列中選擇前10個專案,如果測驗項出現在前10項中,那么我們認為這是命中,
-
對所有用戶重復此程序,命中率就是平均命中率,
這種評估協議稱為命中率@10( Hit Ratio @ 10),通常用于評估推薦系統,
命中率@10
現在,讓我們使用所描述的協議來評估我們的模型,
# 用于測驗的用戶-專案對
test_user_item_set = set(zip(test_ratings['userId'], test_ratings['movieId']))
# 每個用戶與之互動的所有條目
user_interacted_items = ratings.groupby('userId')['movieId'].apply(list).to_dict()
hits = []
for (u,i) in test_user_item_set:
interacted_items = user_interacted_items[u]
not_interacted_items = set(all_movieIds) - set(interacted_items)
selected_not_interacted = list(np.random.choice(list(not_interacted_items), 99))
test_items = selected_not_interacted + [i]
predicted_labels = np.squeeze(model(torch.tensor([u]*100),
torch.tensor(test_items)).detach().numpy())
top10_items = [test_items[i] for i in np.argsort(predicted_labels)[::-1][0:10].tolist()]
if i in top10_items:
hits.append(1)
else:
hits.append(0)
print("The Hit Ratio @ 10 is {:.2f}".format(np.average(hits)))

我們有相當不錯的命中率@10!從背景關系來看,這意味著86%的用戶被推薦了他們最終互動的實際專案(在10個專案串列中),不錯!
下一步
我希望這是一個有用的介紹,以創建一個基于深度學習的推薦系統,要了解更多資訊,我建議使用以下資源:
- Wide & Deep Learning — Model introduced by Google for Recommender Systems(https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html)
- Recommenders library by Microsoft — Best practices for Recommender Systems(https://github.com/microsoft/recommenders)
- Deep Learning based Recommender Systems — Useful survey paper(https://arxiv.org/pdf/1707.07435.pdf)
原文鏈接:https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/198930.html
標籤:其他
上一篇:矩陣專題 矩陣加速 矩陣快速冪
下一篇:用Python構建和可視化決策樹