著作權申明:本文為博主窗戶(Colin Cai)原創,歡迎轉帖,如要轉貼,必須注明原文網址 http://www.cnblogs.com/Colin-Cai/p/12664044.html 作者:窗戶 QQ/微信:6679072 E-mail:[email protected]
所謂眾數,源于這樣的一個題目:一個長度為len的陣列,其中有個數出現的次數大于len/2,如何找出這個數,
基于排序
排序是第一感覺,就是把這個陣列排序一下,再遍歷一遍得到結果,
C語言來寫基本如下:
int find(int a, int len) { sort(a, len); return traverse(a, len); }
排序有時間復雜度為O(nlogn)的演算法,比如快速排序、歸并排序、堆排序,而遍歷一遍排序后的陣列得到結果是時間線性復雜度,也就是O(n),所以整個演算法時間復雜度是O(nlogn),
尋找更好的演算法
上面的演算法實在太簡單,很多時候我們第一感就可以出來的東西未必靠譜,
我們是不是可以找到一種線性時間級別的演算法,也就是Θ(n)時間級別的演算法?Θ是上下界一致的符號,其實我們很容易證明,不存在比線性時間級別低的演算法,也就是時間o(n),小o不同于大O,是指低階無窮大,證明大致如下:
如果一個演算法可以以o(n)的時間復雜度解決上述問題,因為是比n更低階的無窮大,那么一定存在一個長度為N的陣列,在完成這個演算法之后,陣列內被檢測的元素小于N/2,假設演算法運算的結果為a,然后,我們把這個陣列在運算該演算法時沒有檢測的元素全部替換為成同一個不是演算法所得結果a的數b,然后新的陣列,再通過演算法去運算,因為沒有檢測的數不會影響其演算法結果,結果自然還是a,可實際上,陣列超過N/2次出現的數是b,從而導致矛盾,所以針對該問題的o(n)時間演算法不存在,
我們現在可以開始想點更加深入點的東西,
我們首先會發現,如果一個陣列中有兩個不同的數,將陣列去掉這兩個數,得到一個新陣列,那么這個新陣列依然和老陣列一樣存在相同的眾數,這一條很容易證明:
假設陣列為a,長度為len,眾數為x,出現的次數為t,當然滿足t>len/2,假設其中有兩個數y和z,y≠z,去掉這兩個數,剩下的陣列長度為len-2,如果這兩個數都不等于眾數x,也就是x≠y且x≠z,那么x在新的陣列中出現的次數依然是t,t>len/2>(len-2)/2,所以t依然是新的陣列里的眾數,而如果這兩個數中存在x,那么自然只有一個x,則剩下的陣列中x出現的次數是t-1,t-1>len/2-1=(len-2)/2,所以x依然是新陣列的眾數,
有了上述的思路,我們會去想,如何找到這一對對的不同的數呢,
我們可以記錄數字num和其重復的次數times,遍歷一遍陣列,按照以下流程圖來,
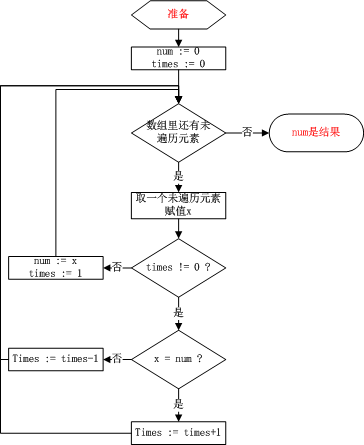
num/times一直記錄著數字和其重復次數,times加1和減1都是隨著陣列新來的數是否和num相同來決定,減1的情況其實就取決于上面證明的那個命題,找到一對不相同的數字,去掉這兩個,剩下的陣列的眾數不變,
關于在于證明最后的結果是所求的眾數,如果后面的結果不是眾數,那么眾數每出現一次,就得與一個不是眾數的數一起“抵消”,所以陣列中不是眾數的數的數量不會少于眾數的數量,然而這不是現實,于是上述演算法成立,它有著線性時間復雜度O(n),常數空間復雜度O(1),
C語言代碼基本如下:
int find(int *a, int len) {
int i, num = 0, times = 0;for(i=0;i<len;i++) { if(times > 0) { if(num == a[i]) times++; else times--; } else { num = a[i]; times = 1; } } return num; }
如果用Scheme撰寫,程式可以簡潔如下:
(define (find s) (car (fold-right (lambda (n r) (if (zero? (cdr r)) (cons n 1) (cons (car r) ((if (eq? n (car r)) + -) (cdr r) 1)))) '(() . 0) s)))
升級之后的問題
上面的眾數是出現次數大于陣列長度的1/2的,如果將這里的1/2改成1/3,要找出來怎么做呢?
例如,陣列是[1, 1, 2, 3, 4],那么要找出的眾數為1,
再升華一下,如果是1/m,這里的m是一個引數,該怎么找出來呢?這個問題要去之前那個問題要復雜一些,另外我們要意識到,問題升級之后,眾數是有可能不止一個的,比如[1, 1, 2, 2, 3]長度為5,1和2都大于5/3,最多有m-1個眾數,
思路
如果依然是排序之后再遍歷,依然是有效的,可是時間復雜度還是O(nlogn)級別,我們還是期待有著線性時間復雜度的演算法,
對于第一個問題,成立的前提是去掉陣列里兩個不一樣的數,眾數依然不變,那么對于升級之后的問題,是不是依然有類似的結果,不同于之前,我們現在來看在眾數從1/2以上變成1/m以上,我們來看去掉長度為len的陣列a里m個互不相同的數,會發生什么,證明程序如下:
同樣,我們假設a里有一個眾數x,x出現的次數為t,看看去掉m個不一樣的數之后x還是不是眾數,去掉m個數之后,新的陣列長度為len-m,x是眾數,所以x的出現次數t > len/m,如果去掉的m個數中沒有x,則x在剩余的陣列中的出現次數依然是t,t > len/m > (len-m)/m,所以這種情況下x還是眾數;如果去掉的m個數中存在x,因為m個數互不相同,所以其中x只有一個,所以x在剩余的陣列中的出現次數是t-1,t > len/m,從而t-1 > len/m-1 = (len-m)/m,所以x在剩余的陣列里依然是眾數,以上對于陣列中所有的眾數都成立,同理可證,對于陣列中不是眾數的數,剩余的陣列中依然不是眾數,實際上,把上面所有的>替換為≤即可,
有了上面的理解,我們可以仿照之前的演算法,只是這里改成了長度最多為n-1的鏈表,比如對于陣列[1, 2, 1, 3],眾數1超過陣列長度4的1/3,程序如下
初始時,空鏈表[]
檢索第一個元素1,發現鏈表中沒有記錄num=1的表元,鏈表的長度沒有達到2,所以插入到鏈表,得到[(num=1,times=1)]
檢索第二個元素2,發現鏈表中沒有記錄num=2的表元,鏈表的長度沒有達到2,插入到鏈表,得到[(num=1,times=1), (num=2,times=1)]
檢索第三個元素1,發現鏈表中已經存在num=1的表元,則把該表元times加1,得到[(num=1,times=2), (num=2,times=1)]
檢索第四個元素3,發現鏈表中沒有num=3的表元,鏈表長度已經達到最大,等于2,于是執行消去,也就是每個表元的times減1,并把減為0的表元移出鏈表,得到[(num=1,times=1)]
以上就是程序,最終得到眾數為1,
以上程序最終得到的鏈表的確包含了所有的眾數,這一點很容易證明,因為任何一個眾數的times都不可能被完全抵消掉,但是,以上程序實際并不保證最后得到的鏈表里全都是眾數,比如[1,1,2,3,4]最終得到[(num=1,times=1), (num=4,times=1)],但4并不是眾數,
所以我們需要得到這個鏈表之后,再遍歷一遍陣列,將重復次數記載于鏈表之中,
Python下使用map/reduce高階函式來取代程序式下的回圈,上述的演算法也需要如下這么多的代碼,
from functools import reduce def find(a, m): def find_index(arr, test): for i in range(len(arr)): if test(arr[i]): return i return -1 def check(r, n): index = find_index(r, lambda x : x[0]==n) if index >= 0: r[index][1] += 1 return r if len(r) < m-1: return r+[[n,1]] return reduce(lambda arr,x : arr if x[1]==1 else arr+[[x[0],x[1]-1]], r, []) def count(r, n): index = find_index(r, lambda x : x[0]==n) if index < 0: return r r[index][1] += 1 return r return reduce(lambda r,x : r+[x[0]] if x[1]>len(a)//m else r, \ reduce(count, a, \ list(map(lambda x : [x[0],0], reduce(check, a, [])))), [])
如果用C語言撰寫代碼會更多一些,不過可以不用鏈表,改用固定長度的陣列效率會高很多,times=0的情況代表著元素不被占用,此處就不實作了,交給有興趣的讀者自己來實作吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/199899.html
標籤:其他
下一篇:15個最好的性能測驗工具