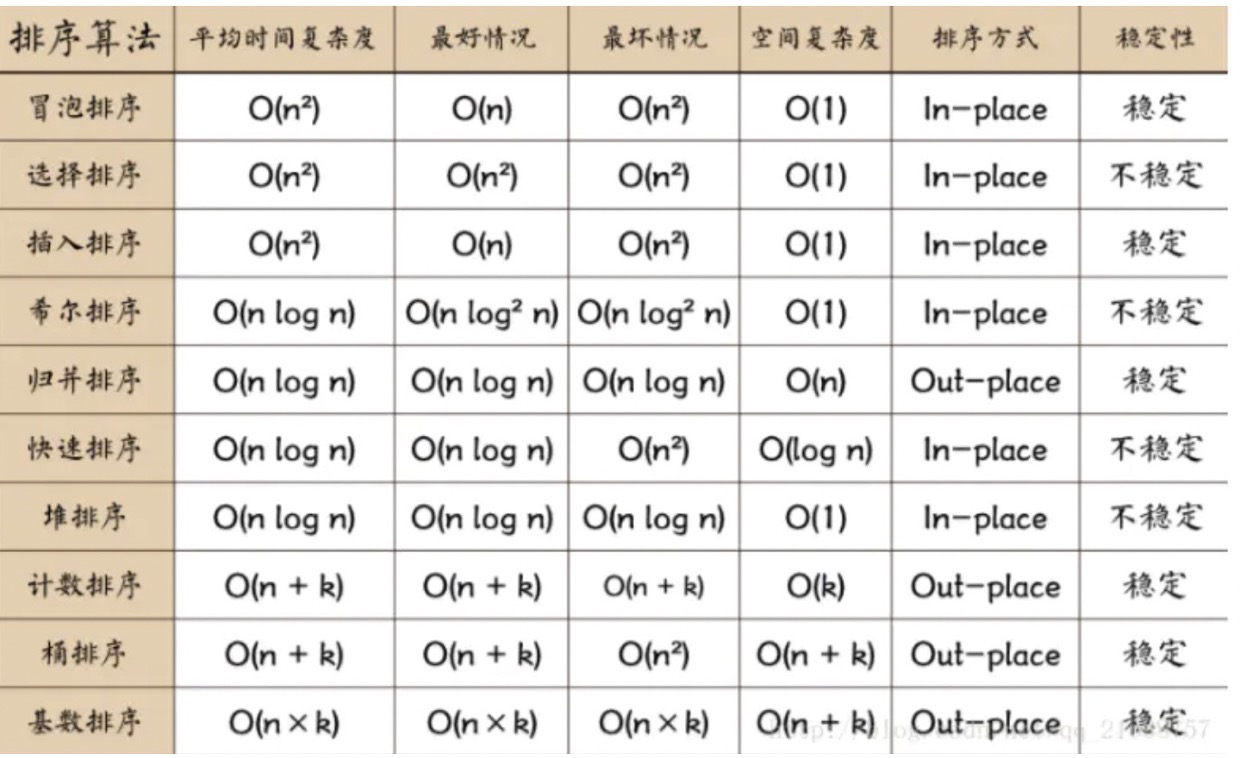
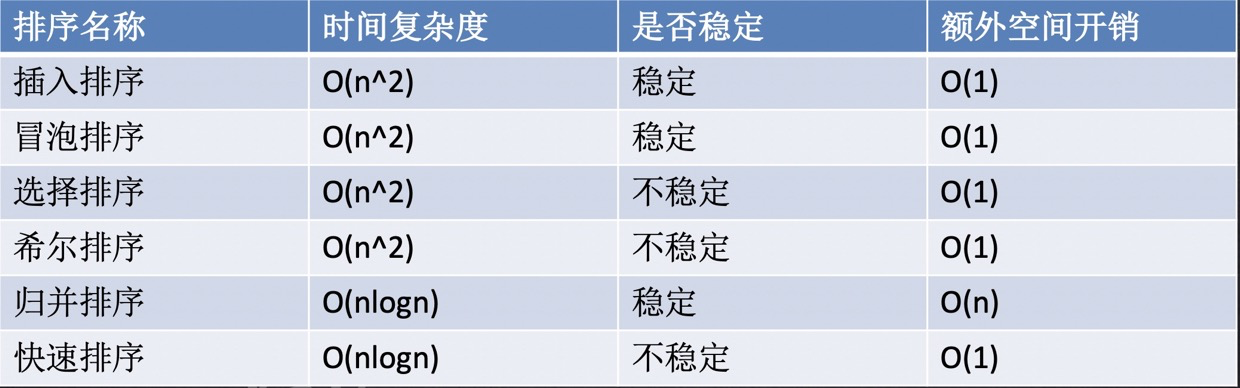
這么多種排序演算法我們究竟應該怎么選擇呢?:
1.分析場景:穩定還是不穩定
2.資料量:資料量小的時候選什么?比如就50個數,優先選插入(5000*5000=25000000)
3.分析空間:
綜上所述,沒有一個固定的排序演算法,都是要根據情況分析的,但是如果你不會分析的情況下 選擇歸并或者快排,
冒泡排序
核心思路:冒泡排序只會操作相鄰的兩個資料,每次冒泡操作都會對相鄰的兩個元素進行比較,看是否滿足大小關系要求,如果不滿足就讓它倆互換,一次冒泡會讓至少一個元素移動到它應該在的位置,重復n次,就完成了n個資料的排序作業
舉例說明:4 5 6 3 2 1,從小到大排序
第一次冒泡的結果:4 5 6 3 2 1->4 5 3 6 2 1 - > 4 5 3 2 6 1 -> 4 5 3 2 1 6,6這個元素的位置確定了
第二次冒泡的結果:4 5 3 2 1 6->4 3 5 2 1 6 -> 4 3 2 5 1 6 -> 4 3 2 1 5 6
第三次冒泡的結果:4 3 2 1 5 6->3 4 2 1 5 6 -> 3 2 4 1 5 6 -> 3 2 1 4 5 6
第四次冒泡的結果:3 2 1 4 5 6->2 3 1 4 5 6 -> 2 1 3 4 5 6
第五次冒泡的結果:2 1 3 4 5 6->1 2 3 4 5 6
1.時間復雜度:O(N^2)
2.空間復雜度:O(n)
3.穩定性:不穩定
import java.util.Arrays;
public class BubbleSort {
public static void main(String[] args) {
int data[] = { 4, 5, 6, 3, 2, 1 };
int n = data.length;
for (int i = 0; i < n - 1; i++) { //排序的次數
boolean flag = false;
for (int j = 0; j < n - 1 - i; j++) { //具體冒泡 n - 1 - i
if (data[j] > data[j + 1]) {
int temp = data[j];
data[j] = data[j + 1];
data[j + 1] = temp;
flag = true;
}
}
if(!flag) break;
}
System.out.println(Arrays.toString(data));
}
}選擇排序
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后再從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾,以此類推,直到所有元素均排序完畢
public class SelectionSort {
public int[] selectionSort(int[] A, int n) {
//記錄最小下標值
int min=0;
for(int i=0; i<A.length-1;i++){
min = i;
//找到下標i開始后面的最小值
for(int j=i+1;j<A.length;j++){
if(A[min]>A[j]){
min = j;
}
}
if(i!=min){
swap(A,i,min);
}
}
return A;
}
private void swap(int[] A,int i,int j){
int temp = A[i];
A[i] = A[j];
A[j] = temp;
}
}插入排序
插入排序演算法的作業原理是通過構建有序序列,對于未排序資料,在已排序序列中從后向前掃描,找到相應位置并插入,因而在從后向前掃描程序中,需要反復把已排序元素逐步向后挪位,為最新元素提供插入空間
public class InsertionSort {
public int[] insertionSort(int[] A, int n) {
//用模擬插入撲克牌的思想
//插入的撲克牌
int i,j,temp;
//已經插入一張,繼續插入
for(i=1;i<n;i++){
temp = A[i];
//把i前面所有大于要插入的牌的牌往后移一位,空出一位給新的牌
for(j=i;j>0&&A[j-1]>temp;j--){
A[j] = A[j-1];
}
//把空出來的一位填滿插入的牌
A[j] = temp;
}
return A;
}
}歸并排序
先使每個子序列有序,再將兩個已經排序的序列合并成一個序列的操作
若將兩個有序表合并成一個有序表,稱為二路歸并
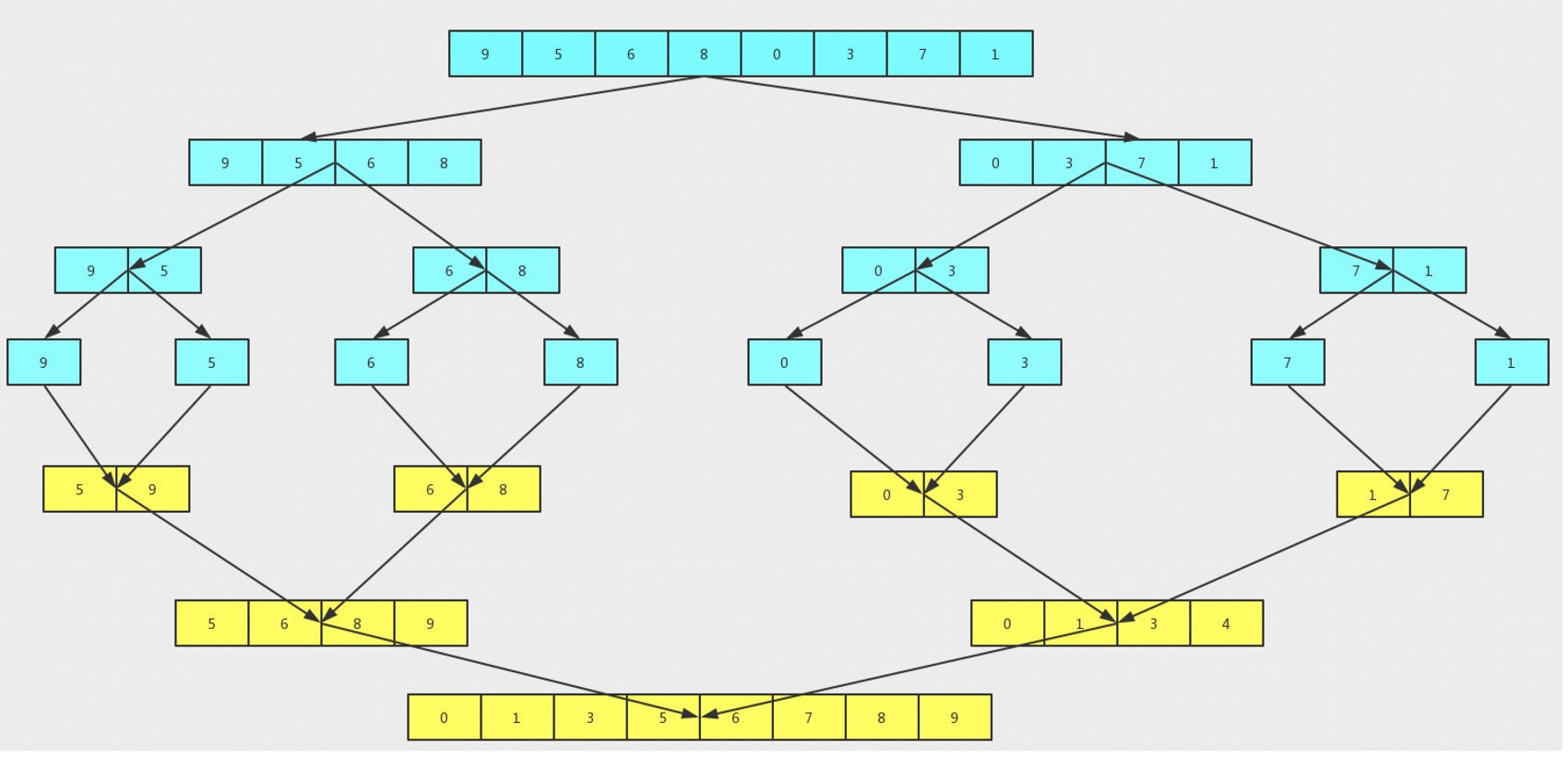
public class MergeSort {
public static void main(String[] args) {
int data[] = { 9, 5, 6, 8, 0, 3, 7, 1 };
megerSort(data, 0, data.length - 1);
System.out.println(Arrays.toString(data));
}
public static void mergeSort(int data[], int left, int right) { // 陣列的兩端
if (left < right) { // 相等了就表示只有一個數了 不用再拆了
int mid = (left + right) / 2;
mergeSort(data, left, mid);
mergeSort(data, mid + 1, right);
// 分完了 接下來就要進行合并,也就是我們遞回里面歸的程序
merge(data, left, mid, right);
}
}
public static void merge(int data[], int left, int mid, int right) {
int temp[] = new int[data.length]; //借助一個臨時陣列用來保存合并的資料
int point1 = left; //表示的是左邊的第一個數的位置
int point2 = mid + 1; //表示的是右邊的第一個數的位置
int loc = left; //表示的是我們當前已經到了哪個位置了
while(point1 <= mid && point2 <= right){
if(data[point1] < data[point2]){
temp[loc] = data[point1];
point1 ++ ;
loc ++ ;
}else{
temp[loc] = data[point2];
point2 ++;
loc ++ ;
}
}
while(point1 <= mid){
temp[loc ++] = data[point1 ++];
}
while(point2 <= right){
temp[loc ++] = data[point2 ++];
}
for(int i = left ; i <= right ; i++){
data[i] = temp[i];
}
}
}希爾排序
希爾排序的核心在于間隔序列的設定,既可以提前設定好間隔序列,也可以動態的定義間隔序列
基本思想:演算法先將要排序的一組數按某個增量d(n/2,n為要排序數的個數)分成若干組,每組中記錄的下標相差d,對每組中全部元素進行直接插入排序,然后再用一個較小的增量(d/2)對它進行分組,在每組中再進行直接插入排序,當增量減到1時,進行直接插入排序后,排序完成
希爾排序法(縮小增量法) 屬于插入類排序,是將整個無序列分割成若干小的子序列分別進行插入排序的方法

public class ShellSort {
public int[] shellSort(int[] A, int n) {
int temp,j,i;
//設定增量D,增量D/2逐漸減小
for(int D = n/2;D>=1;D=D/2){
//從下標d開始,對d組進行插入排序
for(j=D;j<n;j++){
temp = A[j];
for(i=j;i>=D&&A[i-D]>temp;i-=D){
A[i]=A[i-D];
}
A[i]=temp;
}
}
return A;
}
}快速排序
快速排序的基本思想:通過一趟排序將待排記錄分隔成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分的關鍵字小,則可分別對這兩部分記錄繼續進行排序,以達到整個序列有序
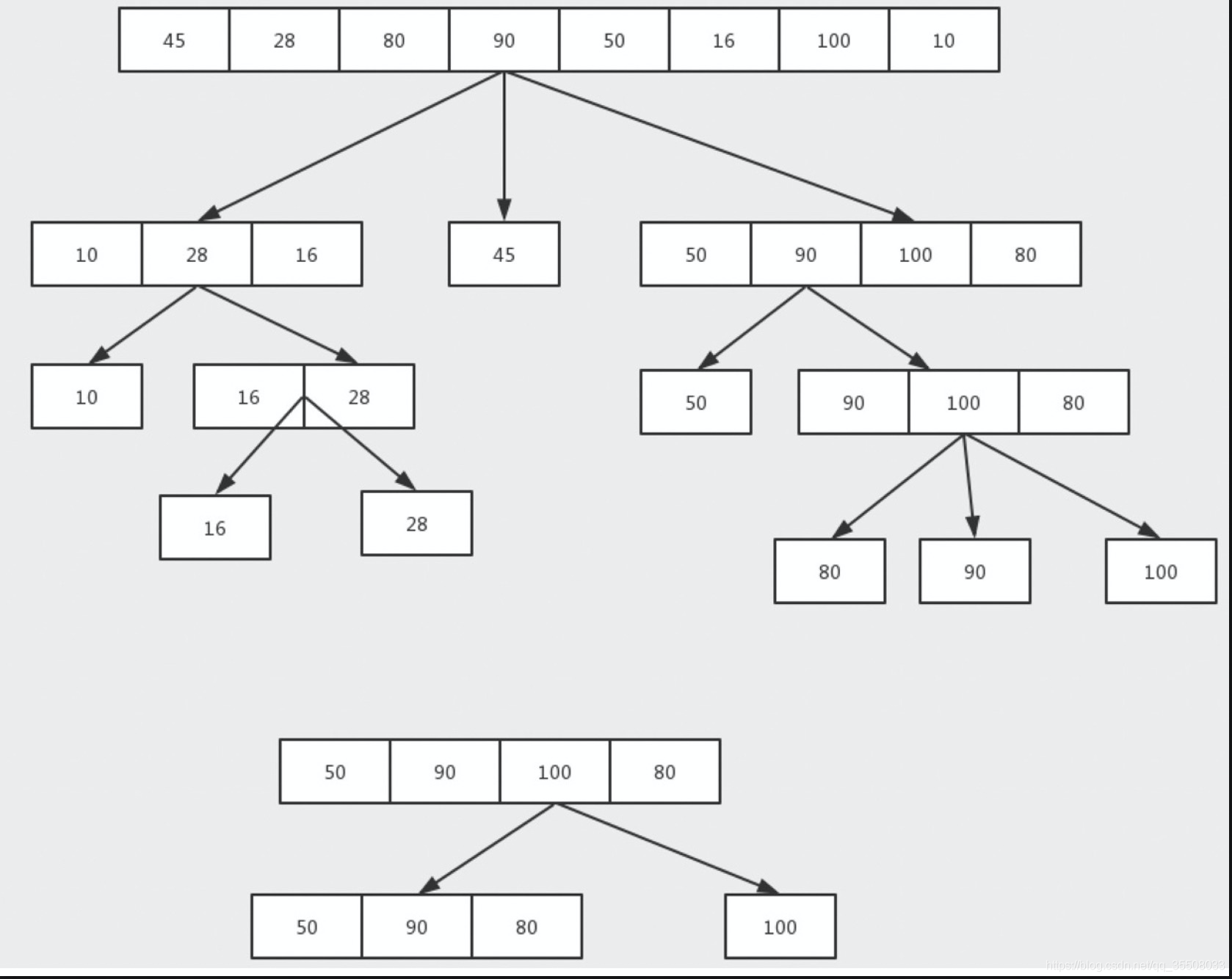
基準數一般就是取要排序序列的第一個
從后面往前找到比基準數小的數進行對換
從前面往后面找比基準數大的進行對換
public class QuickSort {
public static void quickSort(int[]arr,int low,int high){
if (low < high) {
int middle = getMiddle(arr, low, high);
quickSort(arr, low, middle - 1);//遞回左邊
quickSort(arr, middle + 1, high);//遞回右邊
}
}
public static int getMiddle(int[] list, int low, int high) {
int tmp = list[low];
while (low < high) {
while (low < high && list[high] >= tmp) {//大于關鍵字的在右邊
high--;
}
list[low] = list[high];//小于關鍵字則交換至左邊
while (low < high && list[low] <= tmp) {//小于關鍵字的在左邊
low++;
}
list[high] = list[low];//大于關鍵字則交換至左邊
}
list[low] = tmp;
return low;
}
}public class QuickSort {
public static void quickSort(int data[], int left, int right) {
int base = data[left]; // 基準數,取序列的第一個
int ll = left; // 表示的是從左邊找的位置
int rr = right; // 表示從右邊開始找的位置
while (ll < rr) {
// 從后面往前找比基準數小的數
while (ll < rr && data[rr] >= base) {
rr--;
}
if (ll < rr) { // 表示是找到有比之大的
int temp = data[rr];
data[rr] = data[ll];
data[ll] = temp;
ll++;
}
while (ll < rr && data[ll] <= base) {
ll++;
}
if (ll < rr) {
int temp = data[rr];
data[rr] = data[ll];
data[ll] = temp;
rr--;
}
}
// 肯定是遞回 分成了三部分,左右繼續快排,注意要加條件不然遞回就堆疊溢位了
if (left < ll)
quickSort(data, left, ll - 1);
if (ll < right)
quickSort(data, ll + 1, right);
}
}快速排序優化
基本的快速排序選取第一個或最后一個元素作為基準,但是,這是一直很不好的處理方法
如果陣列已經有序時,此時的分割就是一個非常不好的分割,因為每次劃分只能使待排序序列減一,此時為最壞情況,快速排序淪為冒泡排序,時間復雜度為O(n^2)
三數取中
一般的做法是使用左端、右端和中心位置上的三個元素的中值作為樞紐元
舉例:待排序序列為:8 1 4 9 6 3 5 2 7 0
左邊為:8,右邊為0,中間為6
我們這里取三個數排序后,中間那個數作為樞軸,則樞軸為6
插入排序
當待排序序列的長度分割到一定大小后,使用插入排序
原因:對于很小和部分有序的陣列,快排不如插排好,當待排序序列的長度分割到一定大小后,繼續分割的效率比插入排序要差,此時可以使用插排而不是快排
重復陣列
在一次分割結束后,可以把與Key相等的元素聚在一起,繼續下次分割時,不用再對與key相等元素分割
在一次劃分后,把與key相等的元素聚在一起,能減少迭代次數,效率會提高不少
具體程序:在處理程序中,會有兩個步驟
第一步,在劃分程序中,把與key相等元素放入陣列的兩端
第二步,劃分結束后,把與key相等的元素移到樞軸周圍
舉例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三數取中選取樞軸:下標為4的數6
轉換后,待分割序列:6 4 6 7 1 6 7 6 8 6
樞軸key:6
第一步,在劃分程序中,把與key相等元素放入陣列的兩端
結果為:6 4 1 6(樞軸) 7 8 7 6 6 6
此時,與6相等的元素全放入在兩端了
第二步,劃分結束后,把與key相等的元素移到樞軸周圍
結果為:1 4 66(樞軸) 6 6 6 7 8 7
此時,與6相等的元素全移到樞軸周圍了
之后,在1 4 和 7 8 7兩個子序列進行快排
堆排序
如何建堆:
1.從最后一個非葉子節點開始,依次比較元素大小,開始堆化
2. 從倒數第二個非葉子節點堆化
3.重復操作
堆排序:
1.將堆頂和最后一個元素交換
2.排除最后一個元素,繼續建堆
3.重復1,2操作
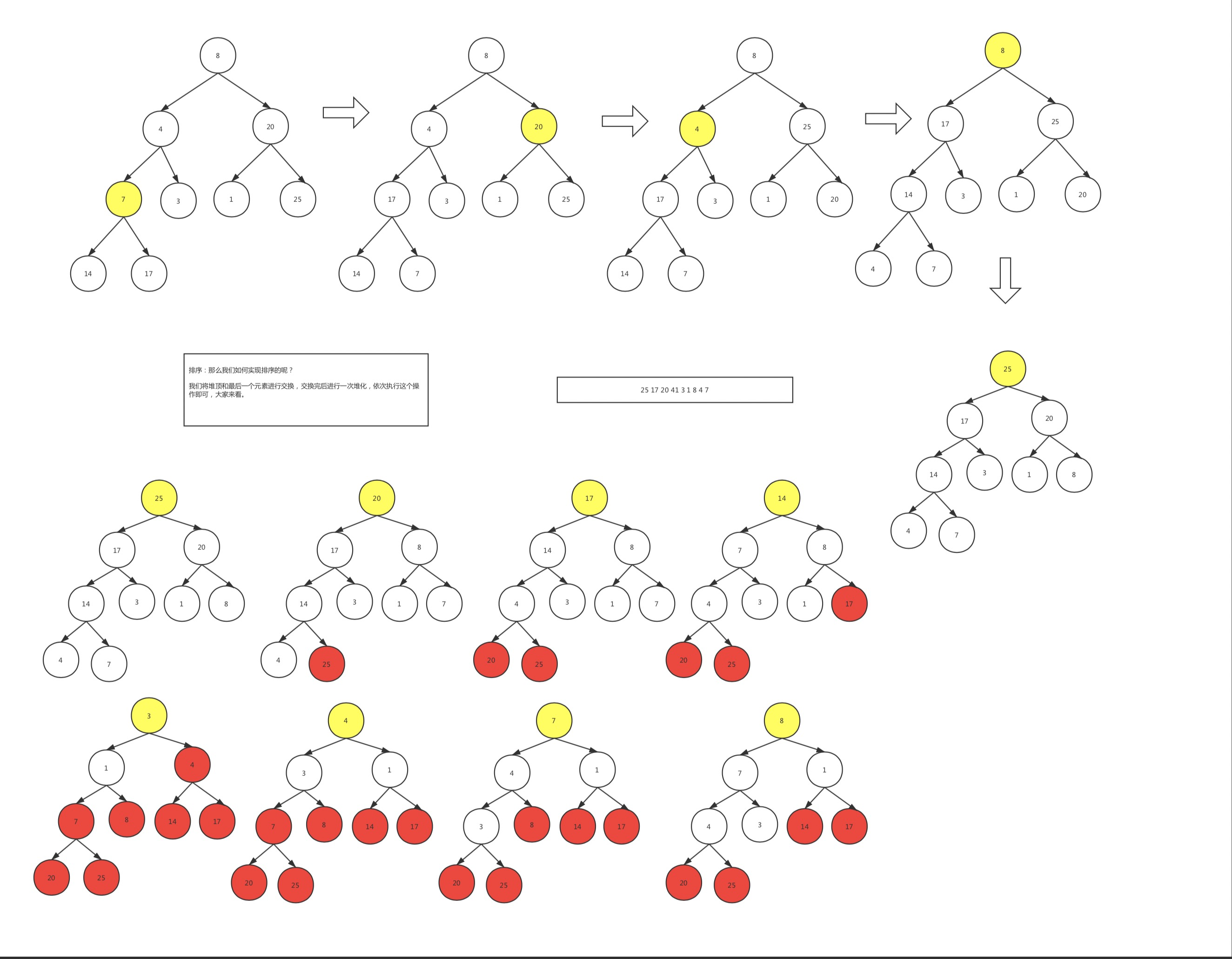
package algorithm.cm.tree;
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
int data[] = { 8, 4, 20, 7, 3, 1, 25, 14, 17 };
heapSort(data);
System.out.println(Arrays.toString(data));
}
public static void maxHeap(int data[], int start, int end) { // 建一個大頂堆,end表示最多建到的點 lgn
int parent = start;
int son = parent * 2 + 1; // 下標是從0開始的就要加1,從1就不用
while (son < end) {
int temp = son;
// 比較左右節點和父節點的大小
if (son + 1 < end && data[son] < data[son + 1]) { // 表示右節點比左節點大
temp = son + 1; // 就要換右節點跟父節點
}
// temp表示的是 我們左右節點大的那一個
if (data[parent] > data[temp])
return; // 不用交換
else { // 交換
int t = data[parent];
data[parent] = data[temp];
data[temp] = t;
parent = temp; // 繼續堆化
son = parent * 2 + 1;
}
}
return;
}
public static void heapSort(int data[]) {
int len = data.length;
for (int i = len / 2 - 1; i >= 0; i--) { //o(nlgn)
maxHeap(data, i, len); //
}
for (int i = len - 1; i > 0; i--) { //o(nlgn)
int temp = data[0];
data[0] = data[i];
data[i] = temp;
maxHeap(data, 0, i); //這個i能不能理解?因為len~i已經排好序了
}
}
}如何實作一個用戶熱門搜索排行榜功能(微博熱搜)?給你一個包含1億關鍵詞的用戶檢索的日志,如何取出排行前10的關鍵詞,
給你的處理機器:2CPU 2G記憶體 一臺,年齡,0~200
1.統計出現的頻率,Hash
2.維護一個大小為10的大頂堆,資料量太多,記憶體不夠
分治,分成很多份,1億個我分成 10個檔案
Hash%10=當前這個詞放在哪個檔案,
分成了10個檔案后:分別求top10,然后再把這個top10合起來,也就是有100個數,再求一次,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/200050.html
標籤:其他
下一篇:哈KK成長之路--集合框架