1. 為什么使用Kudu作為存盤介質
- 資料庫資料上的快速分析
?目前很多業務使用事務型資料庫(MySQL、Oracle)做資料分析,把資料寫入資料庫,然后使用 SQL 進行有效資訊提取,當資料規模很小的時候,這種方式確實是立竿見影的,但是當資料量級起來以后,會發現資料庫吃不消了或者成本開銷太大了,此時就需要把資料從事務型資料庫里拷貝出來或者說剝離出來,裝入一個分析型的資料庫里,發現對于實時性和變更性的需求,目前只有 Kudu 一種組件能夠滿足需求,所以就產生了這樣的一種場景:
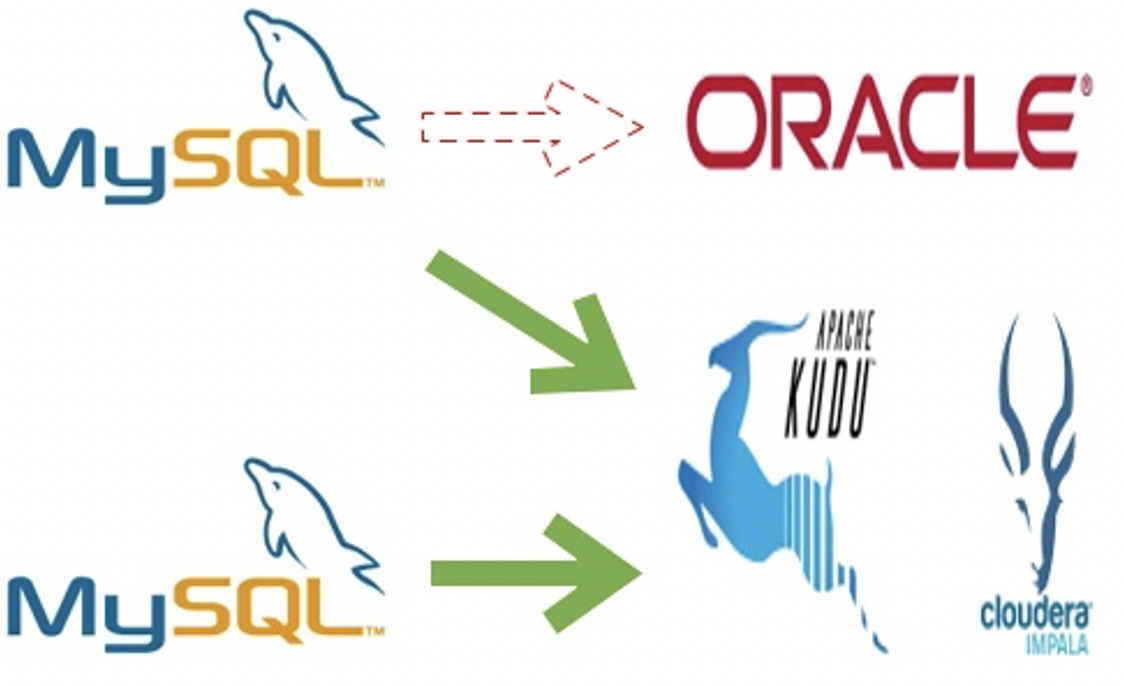
?MySQL 資料庫增、刪、改的資料通過 Binlog 實時的被同步到 Kudu 里,同時在 Impala(或者其他計算引擎如 Spark、Hive、Presto、MapReduce)上可以實時的看到,
這種場景也是目前業界使用最廣泛的,認可度最高,
- 用戶行為日志的快速分析
對于用戶行為日志的實時性敏感的業務,比如電商流量、AB 測驗、優惠券的點擊反饋、廣告投放效果以及秒級匯入秒級查詢等需求,按 Kudu 出現以前的架構基本上都是這張圖的模式:
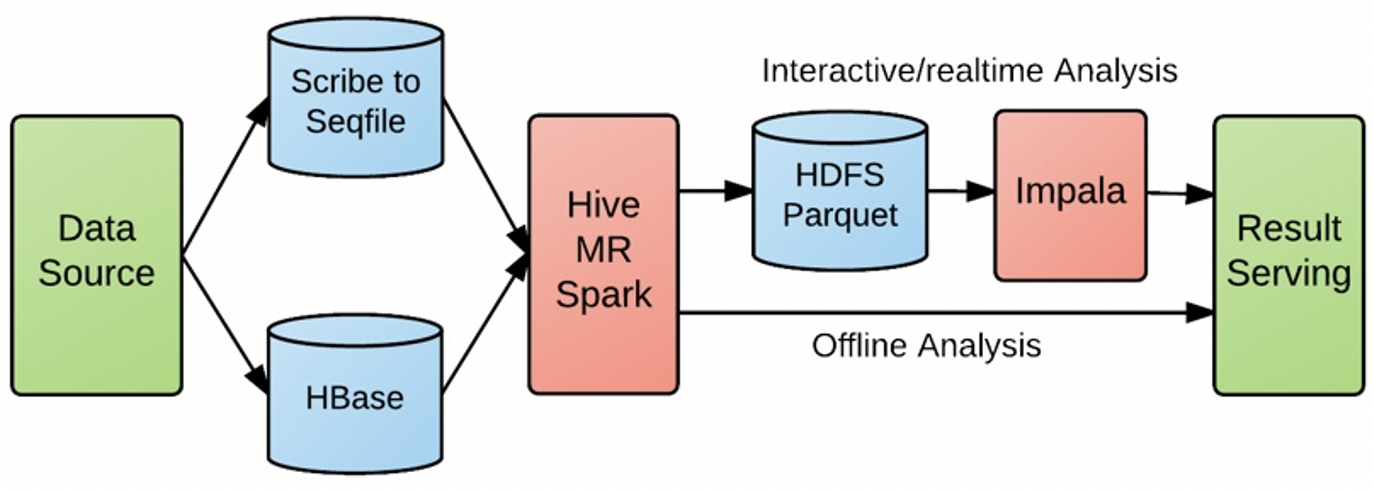
?不僅鏈路長而且實時性得不到有力保障,有些甚至是 T + 1 的,極大的削弱了業務的豐富度,
?引入 Kudu 以后,大家看,資料的匯入和查詢都是在線實時的:
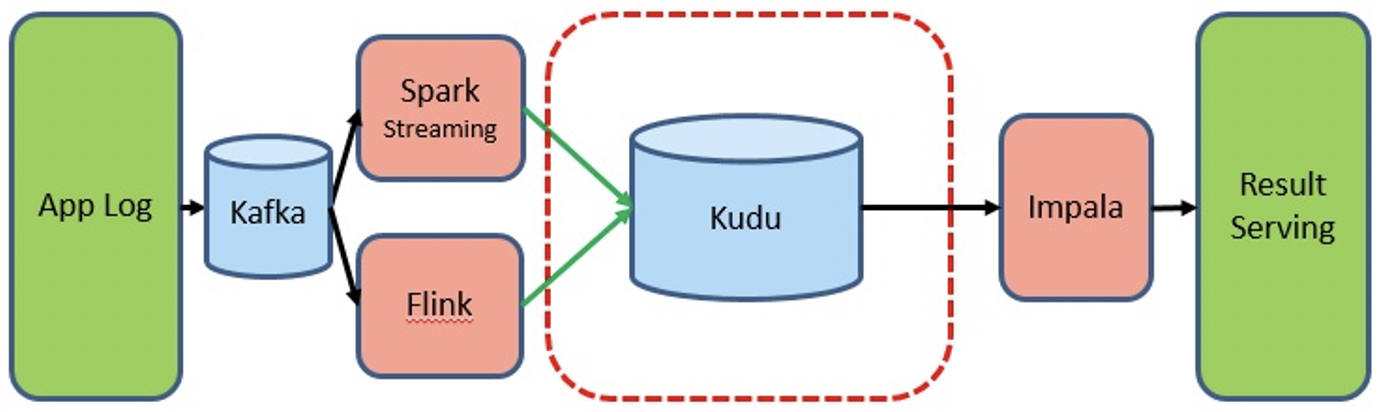
?這種場景目前也是網易考拉和hub在使用的,其中hub甚至把 Kudu 當 HBase 來作點查使用,
2. Kudu入門
2.1 Kudu介紹
2.1.1 背景介紹
在Kudu之前,大資料主要以兩種方式存盤;
- 靜態資料:
- 以 HDFS 引擎作為存盤引擎,適用于高吞吐量的離線大資料分析場景,
- 這類存盤的局限性是資料無法進行隨機的讀寫,
- 動態資料:
- 以 HBase、Cassandra 作為存盤引擎,適用于大資料隨機讀寫場景,
- 這類存盤的局限性是批量讀取吞吐量遠不如 HDFS,不適用于批量資料分析的場景,
?從上面分析可知,這兩種資料在存盤方式上完全不同,進而導致使用場景完全不同,但在真實的場景中,邊界可能沒有那么清晰,面對既需要隨機讀寫,又需要批量分析的大資料場景,該如何選擇呢?這個場景中,單種存盤引擎無法滿足業務需求,我們需要通過多種大資料工具組合來滿足這一需求,
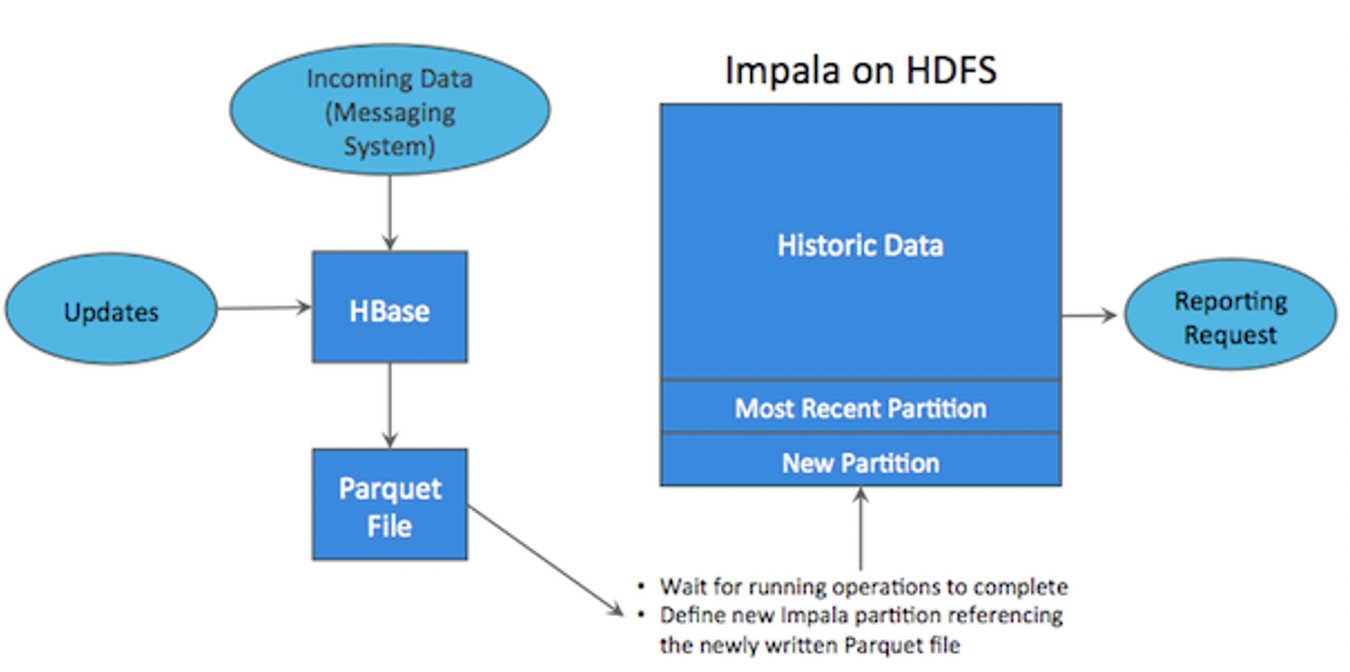
?如上圖所示,資料實時寫入 HBase,實時的資料更新也在 HBase 完成,為了應對 OLAP 需求,我們定時(通常是 T+1 或者 T+H)將 HBase 資料寫成靜態的檔案(如:Parquet)匯入到 OLAP 引擎(如:HDFS),這一架構能滿足既需要隨機讀寫,又可以支持 OLAP 分析的場景,但它有如下缺點:
- 架構復雜,從架構上看,資料在HBase、訊息佇列、HDFS 間流轉,涉及環節太多,運維成本很高,并且每個環節需要保證高可用,都需要維護多個副本,存盤空間也有一定的浪費,最后資料在多個系統上,對資料安全策略、監控等都提出了挑戰,
- 時效性低,資料從HBase匯出成靜態檔案是周期性的,一般這個周期是一天(或一小時),在時效性上不是很高,
- 難以應對后續的更新,真實場景中,總會有資料是延遲到達的,如果這些資料之前已經從HBase匯出到HDFS,新到的變更資料就難以處理了,一個方案是把原有資料應用上新的變更后重寫一遍,但這代價又很高,
?為了解決上述架構的這些問題,Kudu應運而生,Kudu的定位是Fast Analytics on Fast Data,是一個既支持隨機讀寫、又支持 OLAP 分析的大資料存盤引擎,
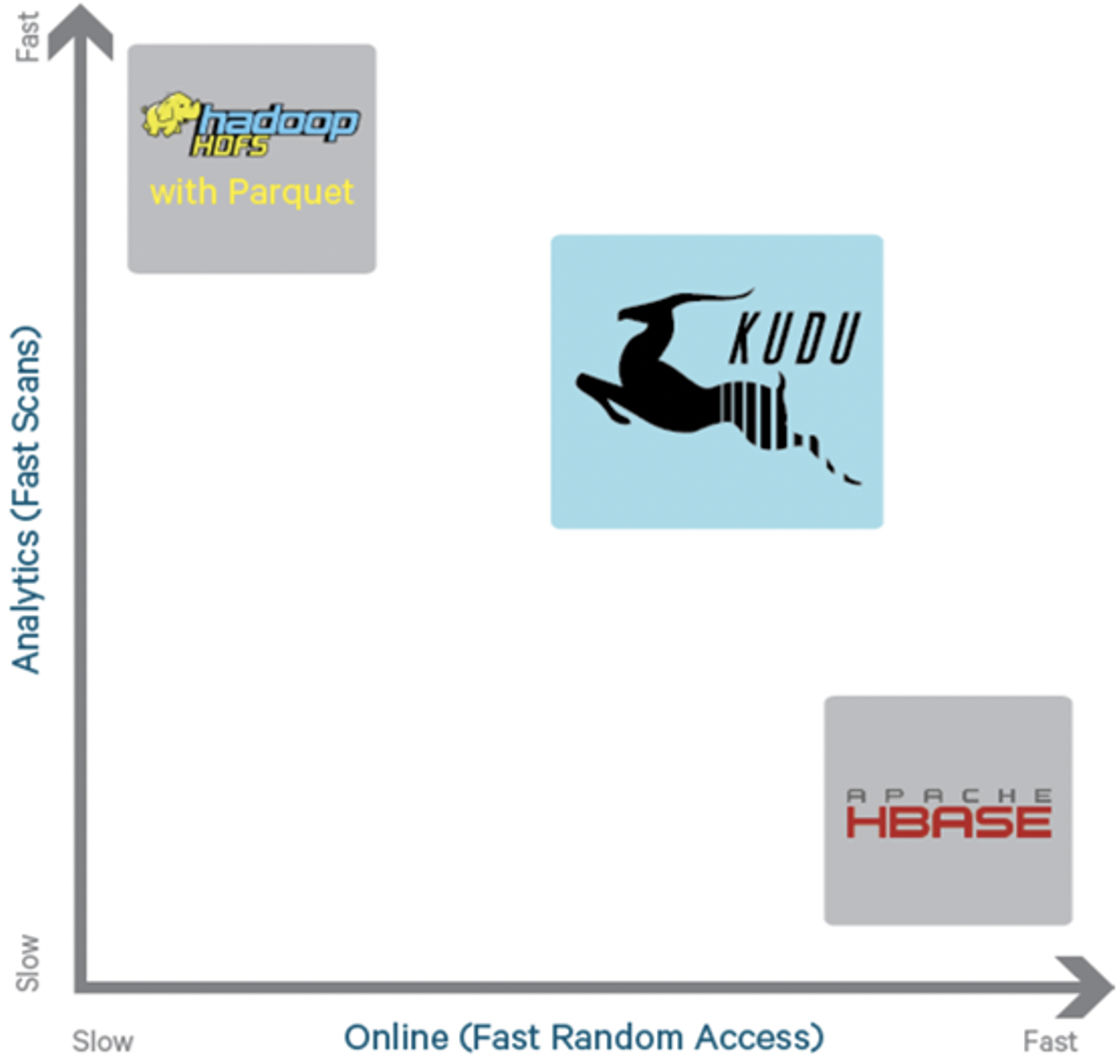
?從上圖可以看出,KUDU 是一個折中的產品,在 HDFS 和 HBase 這兩個偏科生中平衡了隨機讀寫和批量分析的性能,從 KUDU 的誕生可以說明一個觀點:底層的技術發展很多時候都是上層的業務推動的,脫離業務的技術很可能是空中樓閣,
2.1.2 新的硬體設備
?記憶體(RAM)的技術發展非常快,它變得越來越便宜,容量也越來越大,Cloudera的客戶資料顯示,他們的客戶所部署的服務器,2012年每個節點僅有32GB RAM,現如今增長到每個節點有128GB或256GB RAM,存盤設備上更新也非常快,在很多普通服務器中部署SSD也是屢見不鮮,HBase、HDFS、以及其他的Hadoop工具都在不斷自我完善,從而適應硬體上的升級換代,然而,從根本上,HDFS基于03年GFS,HBase基于05年BigTable,在當時系統瓶頸主要取決于底層磁盤速度,當磁盤速度較慢時,CPU利用率不足的根本原因是磁盤速度導致的瓶頸,當磁盤速度提高了之后,CPU利用率提高,這時候CPU往往成為系統的瓶頸,HBase、HDFS由于年代久遠,已經很難從基本架構上進行修改,而Kudu是基于全新的設計,因此可以更充分地利用RAM、I/O資源,并優化CPU利用率,
?我們可以理解為:Kudu相比與以往的系統,CPU使用降低了,I/O的使用提高了,RAM的利用更充分了,
2.1.3 Kudu是什么
?Apache Kudu是由Cloudera開源的存盤引擎,可以同時提供低延遲的隨機讀寫和高效的資料分析能力,它是一個融合HDFS和HBase的功能的新組件,具備介于兩者之間的新存盤組件,
?Kudu支持水平擴展,并且與Cloudera Impala和Apache Spark等當前流行的大資料查詢和分析工具結合緊密,
2.1.4 Kudu的應用場景
?Kudu的很多特性跟HBase很像,它支持索引鍵的查詢和修改,Cloudera曾經想過基于Hbase進行修改,然而結論是對HBase的改動非常大,Kudu的資料模型和磁盤存盤都與Hbase不同,HBase本身成功的適用于大量的其它場景,因此修改HBase很可能吃力不討好,最后Cloudera決定開發一個全新的存盤系統,
- Strong performance for both scan and random access to help customers simplify complex hybrid architectures(適用于那些既有隨機訪問,也有批量資料掃描的復合場景)
- High CPU efficiency in order to maximize the return on investment that our customers are making in modern processors(高計算量的場景)
- High IO efficiency in order to leverage modern persistent storage(使用了高性能的存盤設備,包括使用更多的記憶體)
- The ability to upDATE data in place, to avoid extraneous processing and data movement(支持資料更新,避免資料反復遷移)
- The ability to support active-active replicated clusters that span multiple data centers in geographically distant locations(支持跨地域的實時資料備份和查詢)
2.1.5 Kudu架構
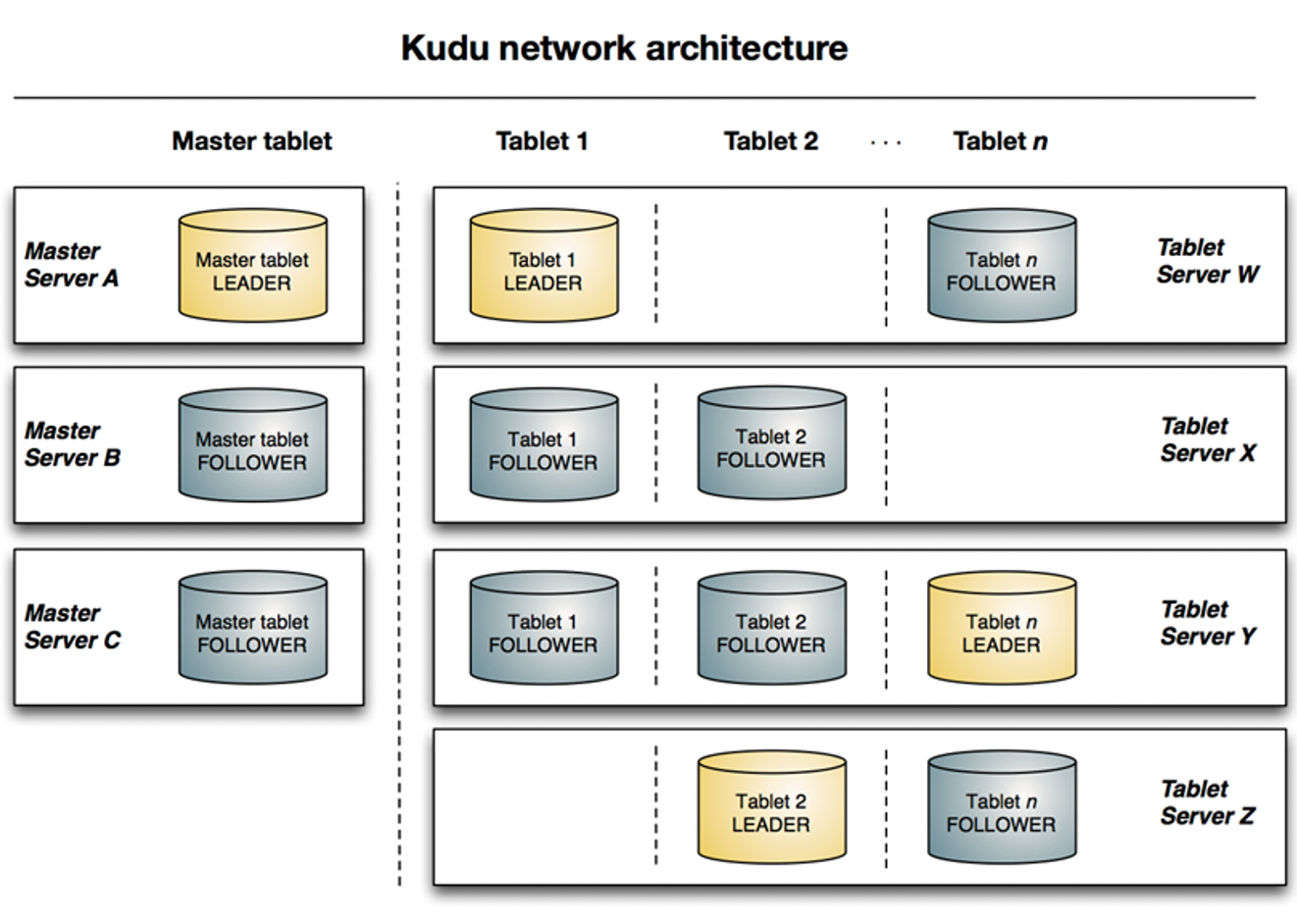
?下圖顯示了一個具有三個 master 和多個 tablet server 的 Kudu 集群,每個服務器都支持多個 tablet,
?它說明了如何使用 Raft 共識來允許 master 和 tablet server 的 leader 和 follow,
?此外,tablet server 可以成為某些 tablet 的 leader,也可以是其他 tablet 的 follower,leader 以金色顯示,而 follower 則顯示為藍色,
下面是一些基本概念:
| 角色 | 作用 |
|---|---|
| Master | 集群中的老大,負責集群管理、元資料管理等功能 |
| Tablet Server | 集群中的小弟,負責資料存盤,并提供資料讀寫服務 一個 tablet server 存盤了table表的tablet 和為 tablet 向 client 提供服務,對于給定的 tablet,一個tablet server 充當 leader,其他 tablet server 充當該 tablet 的 follower 副本, 只有 leader服務寫請求,然而 leader 或 followers 為每個服務提供讀請求 ,一個 tablet server 可以服務多個 tablets ,并且一個 tablet 可以被多個 tablet servers 服務著, |
| Table(表) | 一張table是資料存盤在Kudu的tablet server中,表具有 schema 和全域有序的primary key(主鍵),table 被分成稱為 tablets 的 segments, |
| Tablet | 一個 tablet 是一張 table連續的segment,tablet是kudu表的水平磁區,類似于google Bigtable的tablet,或者HBase的region,每個tablet存盤著一定連續range的資料(key),且tablet兩兩間的range不會重疊,一張表的所有tablet包含了這張表的所有key空間,與其它資料存盤引擎或關系型資料庫中的 partition(磁區)相似,給定的tablet 冗余到多個 tablet 服務器上,并且在任何給定的時間點,其中一個副本被認為是leader tablet,任何副本都可以對讀取進行服務,并且寫入時需要在為 tablet 服務的一組 tablet server之間達成一致性, |
2.2 Java代碼操作Kudu
2.2.1 構建maven工程
2.2.2 匯入依賴
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client-tools</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kudu/kudu-spark2 -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
2.2.3 創建包結構
| 包名 | 說明 |
|---|---|
| com.erainm | 代碼所在的包目錄 |
2.2.4 初始化方法
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Type;
import org.apache.kudu.client.KuduClient;
import org.junit.Before;
public class TestKudu {
//定義KuduClient客戶端物件
private static KuduClient kuduClient;
//定義表名
private static String tableName = "person";
/**
* 初始化方法
*/
@Before
public void init() {
//指定master地址
String masterAddress = "node2";
//創建kudu的資料庫連接
kuduClient = new KuduClient.KuduClientBuilder(masterAddress).defaultSocketReadTimeoutMs(6000).build();
}
//構建表schema的欄位資訊
//欄位名稱 資料型別 是否為主鍵
public ColumnSchema newColumn(String name, Type type, boolean isKey) {
ColumnSchema.ColumnSchemaBuilder column = new ColumnSchema.ColumnSchemaBuilder(name, type);
column.key(isKey);
return column.build();
}
}
2.2.5 創建表
/** 使用junit進行測驗
*
* 創建表
* @throws KuduException
*/
@Test
public void createTable() throws KuduException {
//設定表的schema
List<ColumnSchema> columns = new LinkedList<ColumnSchema>();
columns.add(newColumn("CompanyId", Type.INT32, true));
columns.add(newColumn("WorkId", Type.INT32, false));
columns.add(newColumn("Name", Type.STRING, false));
columns.add(newColumn("Gender", Type.STRING, false));
columns.add(newColumn("Photo", Type.STRING, false));
Schema schema = new Schema(columns);
//創建表時提供的所有選項
CreateTableOptions tableOptions = new CreateTableOptions();
//設定表的副本和磁區規則
LinkedList<String> list = new LinkedList<String>();
list.add("CompanyId");
//設定表副本數
tableOptions.setNumReplicas(1);
//設定range磁區
//tableOptions.setRangePartitionColumns(list);
//設定hash磁區和磁區的數量
tableOptions.addHashPartitions(list, 3);
try {
kuduClient.createTable("person", schema, tableOptions);
} catch (Exception e) {
e.printStackTrace();
}
kuduClient.close();
}
2.2.6 插入資料
/**
* 向表中加載資料
* @throws KuduException
*/
@Test
public void loadData() throws KuduException {
//打開表
KuduTable kuduTable = kuduClient.openTable(tableName);
//創建KuduSession物件 kudu必須通過KuduSession寫入資料
KuduSession kuduSession = kuduClient.newSession();
//采用flush方式 手動重繪
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
kuduSession.setMutationBufferSpace(3000);
//準備資料
for(int i=1; i<=10; i++){
Insert insert = kuduTable.newInsert();
//設定欄位的內容
insert.getRow().addInt("CompanyId",i);
insert.getRow().addInt("WorkId",i);
insert.getRow().addString("Name","lisi"+i);
insert.getRow().addString("Gender","male");
insert.getRow().addString("Photo","person"+i);
kuduSession.flush();
kuduSession.apply(insert);
}
kuduSession.close();
kuduClient.close();
}
2.2.7 查詢資料
/**
* 查詢表資料
* @throws KuduException
*/
@Test
public void queryData() throws KuduException {
//打開表
KuduTable kuduTable = kuduClient.openTable(tableName);
//獲取scanner掃描器
KuduScanner.KuduScannerBuilder scannerBuilder = kuduClient.newScannerBuilder(kuduTable);
KuduScanner scanner = scannerBuilder.build();
//遍歷
while(scanner.hasMoreRows()){
RowResultIterator rowResults = scanner.nextRows();
while (rowResults.hasNext()){
RowResult result = rowResults.next();
int companyId = result.getInt("CompanyId");
int workId = result.getInt("WorkId");
String name = result.getString("Name");
String gender = result.getString("Gender");
String photo = result.getString("Photo");
System.out.print("companyId:"+companyId+" ");
System.out.print("workId:"+workId+" ");
System.out.print("name:"+name+" ");
System.out.print("gender:"+gender+" ");
System.out.println("photo:"+photo);
}
}
//關閉
scanner.close();
kuduClient.close();
}
2.2.8 修改資料
/**
* 修改資料
* @throws KuduException
*/
@Test
public void upDATEData() throws KuduException {
//打開表
KuduTable kuduTable = kuduClient.openTable(tableName);
//構建kuduSession物件
KuduSession kuduSession = kuduClient.newSession();
//設定重繪資料模式,自動提交
kuduSession.setFlushMode(SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND);
//更新資料需要獲取UpDATE物件
UpDATE upDATE = kuduTable.newUpDATE();
//獲取row物件
PartialRow row = upDATE.getRow();
//設定要更新的資料資訊
row.addInt("CompanyId",1);
row.addString("Name","kobe");
//操作這個upDATE物件
kuduSession.apply(upDATE);
kuduSession.close();
}
2.2.9 洗掉資料
/**
* 洗掉表中的資料
*/
@Test
public void deleteData() throws KuduException {
//打開表
KuduTable kuduTable = kuduClient.openTable(tableName);
KuduSession kuduSession = kuduClient.newSession();
//獲取Delete物件
Delete delete = kuduTable.newDelete();
//構建要洗掉的行物件
PartialRow row = delete.getRow();
//設定洗掉資料的條件
row.addInt("CompanyId",2);
kuduSession.flush();
kuduSession.apply(delete);
kuduSession.close();
kuduClient.close();
}
2.2.10 洗掉表
/**
* 洗掉表
*/
@Test
public void dropTable() throws KuduException {
//洗掉表
DeleteTableResponse response = kuduClient.deleteTable(tableName);
//關閉客戶端連接
kuduClient.close();
}
2.2.11 kudu的磁區方式(結合Impala)
?為了提供可擴展性,Kudu 表被劃分為稱為 tablets 的單元,并分布在許多 tablet servers 上,行總是屬于單個tablet ,將行分配給 tablet 的方法由在表創建期間設定的表的磁區決定,
kudu提供了3種磁區方式,
2.2.11.1 Hash Partitioning (哈希磁區)
?哈希磁區通過哈希值將行分配到許多 buckets ( 存盤桶 )之一; 哈希磁區是一種有效的策略,當不需要對表進行有序訪問時,哈希磁區對于在 tablet 之間隨機散布這些功能是有效的,這有助于減輕熱點和 tablet 大小不均勻,
/**
* 測驗磁區:
* hash磁區
*/
@Test
public void testHashPartition() throws KuduException {
//設定表的schema
LinkedList<ColumnSchema> columnSchemas = new LinkedList<ColumnSchema>();
columnSchemas.add(newColumn("CompanyId", Type.INT32,true));
columnSchemas.add(newColumn("WorkId", Type.INT32,false));
columnSchemas.add(newColumn("Name", Type.STRING,false));
columnSchemas.add(newColumn("Gender", Type.STRING,false));
columnSchemas.add(newColumn("Photo", Type.STRING,false));
//創建schema
Schema schema = new Schema(columnSchemas);
//創建表時提供的所有選項
CreateTableOptions tableOptions = new CreateTableOptions();
//設定副本數
tableOptions.setNumReplicas(1);
//設定范圍磁區的規則
LinkedList<String> parcols = new LinkedList<String>();
parcols.add("CompanyId");
//設定按照那個欄位進行range磁區
tableOptions.addHashPartitions(parcols,6);
try {
kuduClient.createTable("dog",schema,tableOptions);
} catch (KuduException e) {
e.printStackTrace();
}
kuduClient.close();
}
2.2.11.2 Range Partitioning (范圍磁區)
?范圍磁區可以根據存入資料的資料量,均衡的存盤到各個機器上,防止機器出現負載不均衡現象.
/**
* 測驗磁區:
* RangePartition
*/
@Test
public void testRangePartition() throws KuduException {
//設定表的schema
LinkedList<ColumnSchema> columnSchemas = new LinkedList<ColumnSchema>();
columnSchemas.add(newColumn("CompanyId", Type.INT32,true));
columnSchemas.add(newColumn("WorkId", Type.INT32,false));
columnSchemas.add(newColumn("Name", Type.STRING,false));
columnSchemas.add(newColumn("Gender", Type.STRING,false));
columnSchemas.add(newColumn("Photo", Type.STRING,false));
//創建schema
Schema schema = new Schema(columnSchemas);
//創建表時提供的所有選項
CreateTableOptions tableOptions = new CreateTableOptions();
//設定副本數
tableOptions.setNumReplicas(1);
//設定范圍磁區的規則
LinkedList<String> parcols = new LinkedList<String>();
parcols.add("CompanyId");
//設定按照那個欄位進行range磁區
tableOptions.setRangePartitionColumns(parcols);
/**
* range
* 0 < value < 10
* 10 <= value < 20
* 20 <= value < 30
* ........
* 80 <= value < 90
* */
int count=0;
for(int i =0;i<10;i++){
//范圍開始
PartialRow lower = schema.newPartialRow();
lower.addInt("CompanyId",count);
//范圍結束
PartialRow upper = schema.newPartialRow();
count +=10;
upper.addInt("CompanyId",count);
//設定每一個磁區的范圍
tableOptions.addRangePartition(lower,upper);
}
try {
kuduClient.createTable("student",schema,tableOptions);
} catch (KuduException e) {
e.printStackTrace();
}
kuduClient.close();
}
2.2.11.3 Multilevel Partitioning (多級磁區)
Kudu 允許一個表在單個表上組合多級磁區,
?當正確使用時,多級磁區可以保留各個磁區型別的優點,同時減少每個磁區的缺點 需求.
/**
* 測驗磁區:
* 多級磁區
* Multilevel Partition
* 混合使用hash磁區和range磁區
*
* 哈希磁區有利于提高寫入資料的吞吐量,而范圍磁區可以避免tablet無限增長問題,
* hash磁區和range磁區結合,可以極大的提升kudu的性能
*/
@Test
public void testMultilevelPartition() throws KuduException {
//設定表的schema
LinkedList<ColumnSchema> columnSchemas = new LinkedList<ColumnSchema>();
columnSchemas.add(newColumn("CompanyId", Type.INT32,true));
columnSchemas.add(newColumn("WorkId", Type.INT32,false));
columnSchemas.add(newColumn("Name", Type.STRING,false));
columnSchemas.add(newColumn("Gender", Type.STRING,false));
columnSchemas.add(newColumn("Photo", Type.STRING,false));
//創建schema
Schema schema = new Schema(columnSchemas);
//創建表時提供的所有選項
CreateTableOptions tableOptions = new CreateTableOptions();
//設定副本數
tableOptions.setNumReplicas(1);
//設定范圍磁區的規則
LinkedList<String> parcols = new LinkedList<String>();
parcols.add("CompanyId");
//hash磁區
tableOptions.addHashPartitions(parcols,5);
//range磁區
int count=0;
for(int i=0;i<10;i++){
PartialRow lower = schema.newPartialRow();
lower.addInt("CompanyId",count);
count+=10;
PartialRow upper = schema.newPartialRow();
upper.addInt("CompanyId",count);
tableOptions.addRangePartition(lower,upper);
}
try {
kuduClient.createTable("cat",schema,tableOptions);
} catch (KuduException e) {
e.printStackTrace();
}
kuduClient.close();
}
2.2.12 修改表
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
/**
* 修改表操作
*/
public class AlterTable {
//定義kudu的客戶端物件
private static KuduClient kuduClient;
//定義一張表名稱
private static String tableName = "person";
/**
* 初始化操作
*/
@Before
public void init() {
//指定kudu的master地址
String masterAddress = "node2";
//創建kudu的資料庫連接
kuduClient = new KuduClient.KuduClientBuilder(masterAddress).defaultSocketReadTimeoutMs(6000).build();
}
/**
* 添加列
*/
@Test
public void alterTableAddColumn() {
AlterTableOptions alterTableOptions = new AlterTableOptions();
alterTableOptions.addColumn(new ColumnSchema.ColumnSchemaBuilder("Address", Type.STRING).nullable(true).build());
try {
kuduClient.alterTable(tableName, alterTableOptions);
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* 洗掉列
*/
@Test
public void alterTableDeleteColumn(){
AlterTableOptions alterTableOptions = new AlterTableOptions().dropColumn("Address");
try {
kuduClient.alterTable(tableName, alterTableOptions);
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* 添加磁區列
*/
@Test
public void alterTableAddRangePartition(){
int lowerValue = 110;
int upperValue = 120;
try {
KuduTable kuduTable = kuduClient.openTable(tableName);
List<Partition> rangePartitions = kuduTable.getRangePartitions(6000);
boolean flag = true;
for (Partition rangePartition : rangePartitions) {
int startKey = rangePartition.getDecodedRangeKeyStart(kuduTable).getInt("Id");
if(startKey == lowerValue){
flag = false;
}
}
if(flag) {
PartialRow lower = kuduTable.getSchema().newPartialRow();
lower.addInt("Id", lowerValue);
PartialRow upper = kuduTable.getSchema().newPartialRow();
upper.addInt("Id", upperValue);
kuduClient.alterTable(tableName,new AlterTableOptions().addRangePartition(lower, upper));
}else{
System.out.println("磁區已經存在,不能重復創建!");
}
} catch (KuduException e) {
e.printStackTrace();
} catch (Exception exception) {
exception.printStackTrace();
}
}
/**
* 洗掉表
* @throws KuduException
*/
@Test
public void dropTable() throws KuduException {
kuduClient.deleteTable(tableName);
}
}
2.3 Spark操作Kudu
- Spark與KUDU集成支持:
- DDL操作(創建/洗掉)
- 本地Kudu RDD
- Native Kudu資料源,用于DataFrame集成
- 從kudu讀取資料
- 從Kudu執行插入/更新/ upsert /洗掉
- 謂詞下推
- Kudu和Spark SQL之間的模式映射
- 到目前為止,我們已經聽說過幾個背景關系,例如SparkContext,SQLContext,HiveContext, SparkSession,現在,我們將使用Kudu引入一個KuduContext,這是可以在Spark應用程式中廣播的主要可序列化物件,此類代表在Spark執行程式中與Kudu Java客戶端進行互動,
- KuduContext提供執行DDL操作所需的方法,與本機Kudu RDD的介面,對資料執行更新/插入/洗掉,將資料型別從Kudu轉換為Spark等,
2.3.1 創建表
- 定義kudu的表需要分成5個步驟:
- 提供表名
- 提供schema
- 提供主鍵
- 定義重要選項;例如:定義磁區的schema
- 呼叫create Table api
- 代碼開發
import java.util
import com.erainm.SparkKuduDemo.TABLE_NAME
import org.apache.kudu.client.CreateTableOptions
import org.apache.kudu.spark.kudu.KuduContext
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object SparkKuduTest {
def main(args: Array[String]): Unit = {
//構建sparkConf物件
val sparkConf: SparkConf = new SparkConf().setAppName("SparkKuduTest").setMaster("local[2]")
//構建SparkSession物件
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//獲取sparkContext物件
val sc: SparkContext = sparkSession.sparkContext
sc.setLogLevel("warn")
//構建KuduContext物件
val kuduContext = new KuduContext("node2:7051", sc)
//1.創建表操作
createTable(kuduContext)
/**
* 創建表
*
* @param kuduContext
* @return
*/
def createTable(kuduContext: KuduContext) = {
//如果表不存在就去創建
if (!kuduContext.tableExists(TABLE_NAME)) {
//構建創建表的表結構資訊,就是定義表的欄位和型別
val schema: StructType = StructType(
StructField("userId", StringType, false) ::
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("sex", StringType, false) :: Nil)
//指定表的主鍵欄位
val keys = List("userId")
//指定創建表所需要的相關屬性
val options: CreateTableOptions = new CreateTableOptions
//定義磁區的欄位
val partitionList = new util.ArrayList[String]
partitionList.add("userId")
//添加磁區方式為hash磁區
options.addHashPartitions(partitionList, 6)
//創建表
kuduContext.createTable(TABLE_NAME, schema, keys, options)
}
}
}
}
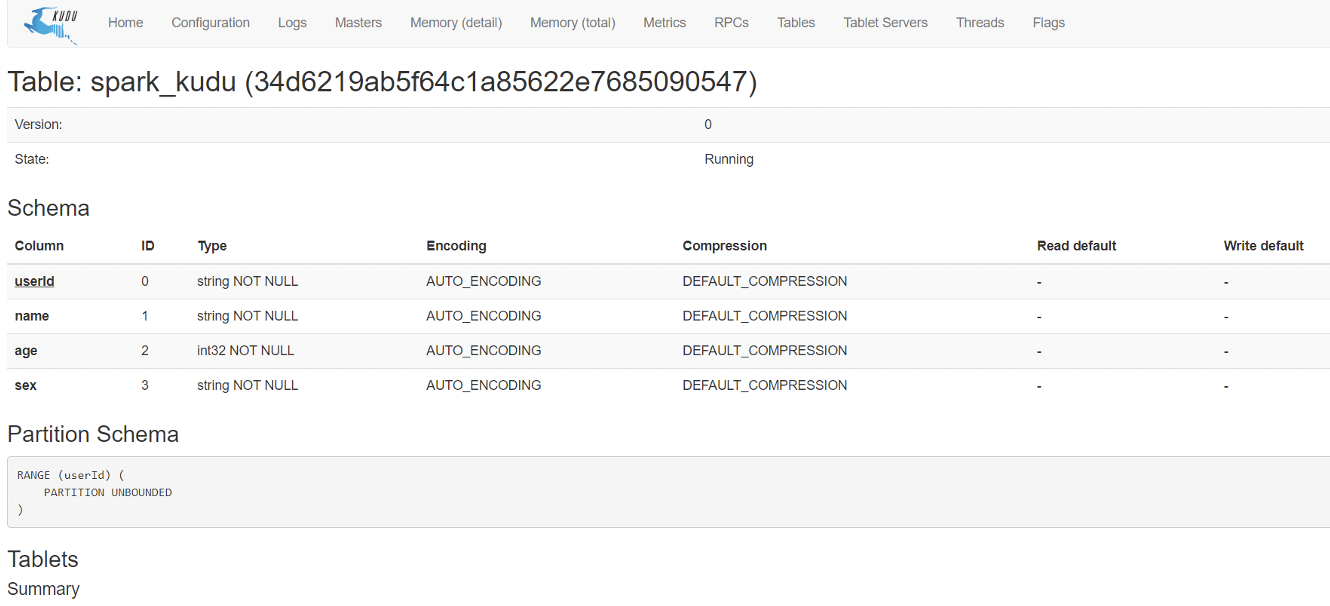
?定義表時要注意的是Kudu表選項值,你會注意到在指定組成范圍磁區列的列名串列時我們呼叫“asJava”方 法,這是因為在這里,我們呼叫了Kudu Java客戶端本身,它需要Java物件(即java.util.List)而不是Scala的List對 象;(要使“asJava”方法可用,請記住匯入JavaConverters庫,) 創建表后,通過將瀏覽器指向http//master主機名:8051/tables
- 來查看Kudu主UI可以找到創建的表,通過單擊表ID,能夠看到表模式和磁區資訊,

點擊Table id 可以觀察到表的schema等資訊:
2.3.2 DML操作
?Kudu支持許多DML型別的操作,其中一些操作包含在Spark on Kudu集成. 包括:
- INSERT - 將DataFrame的行插入Kudu表,請注意,雖然API完全支持INSERT,但不鼓勵在Spark中使用它, 使用INSERT是有風險的,因為Spark任務可能需要重新執行,這意味著可能要求再次插入已插入的行,這樣做會導致失敗,因為如果行已經存在,INSERT將不允許插入行(導致失敗),相反,我們鼓勵使用下面描述 的INSERT_IGNORE,
- INSERT-IGNORE - 將DataFrame的行插入Kudu表,如果表存在,則忽略插入動作,
- DELETE - 從Kudu表中洗掉DataFrame中的行
- UPSERT - 如果存在,則在Kudu表中更新DataFrame中的行,否則執行插入操作,
- UPDATE - 更新dataframe中的行
2.3.2.1 插入資料insert操作
先創建一張表,然后把資料插入到表中
import java.util
import com.erainm.SparkKuduDemo.{TABLE_NAME, erainm}
import org.apache.kudu.client.CreateTableOptions
import org.apache.kudu.spark.kudu.KuduContext
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object SparkKuduTest {
//定義樣例類
case class erainm(id:Int, name:String, age:Int, sex:Int)
def main(args: Array[String]): Unit = {
//構建sparkConf物件
val sparkConf: SparkConf = new SparkConf().setAppName("SparkKuduTest").setMaster("local[2]")
//構建SparkSession物件
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//獲取sparkContext物件
val sc: SparkContext = sparkSession.sparkContext
sc.setLogLevel("warn")
//構建KuduContext物件
val kuduContext = new KuduContext("node2:7051", sc)
//1.創建表操作
createTable(kuduContext)
/**
* 創建表
*
* @param kuduContext
* @return
*/
def createTable(kuduContext: KuduContext) = {
//如果表不存在就去創建
if (!kuduContext.tableExists(TABLE_NAME)) {
//構建創建表的表結構資訊,就是定義表的欄位和型別
val schema: StructType = StructType(
StructField("userId", StringType, false) ::
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("sex", StringType, false) :: Nil)
//指定表的主鍵欄位
val keys = List("userId")
//指定創建表所需要的相關屬性
val options: CreateTableOptions = new CreateTableOptions
//定義磁區的欄位
val partitionList = new util.ArrayList[String]
partitionList.add("userId")
//添加磁區方式為hash磁區
options.addHashPartitions(partitionList, 6)
//創建表
kuduContext.createTable(TABLE_NAME, schema, keys, options)
}
}
/**
* 2)加載資料
* @param session
* @param sc
* @param kuduContext
*/
def inserData(session: SparkSession, sc: SparkContext, kuduContext: KuduContext): Unit = {
//定義資料
val data = List(erainm(1, "tom", 30, 1), erainm(2, "mark", 26, 0))
val erainmRDD = sc.makeRDD(data)
import session.implicits._
val dataFrame: DataFrame = erainmRDD.toDF
kuduContext.insertRows(dataFrame, TABLE_NAME)
}
}
}
2.3.2.2 洗掉資料delete操作
/**
* 4)洗掉資料
* @param session
* @param kuduContext
*/
def deleteData(session: SparkSession, kuduContext: KuduContext): Unit = {
//定義資料
val data = List(erainm(1, "tom", 50, 1), erainm(2, "mark", 30, 0))
import session.implicits._
val dataFrame: DataFrame = data.toDF().select("id")
kuduContext.deleteRows(dataFrame, TABLE_NAME)
}
2.3.2.3 更新資料upsert操作
/**
* 3)修改資料
* @param session
* @param kuduContext
*/
def upDATEData(session: SparkSession, kuduContext: KuduContext): Unit = {
//定義資料
val data = List(erainm(1, "tom", 50, 1), erainm(2, "mark", 30, 0))
import session.implicits._
val dataFrame: DataFrame = data.toDF()
kuduContext.upDATERows(dataFrame, TABLE_NAME)
}
2.3.3 dataFrame操作kudu
2.3.3.1 DataFrameApi讀取kudu表中的資料
?雖然我們可以通過上面顯示的KuduContext執行大量操作,但我們還可以直接從默認資料源本身呼叫讀/寫API,要設定讀取,我們需要為Kudu表指定選項,命名我們要讀取的表以及為表提供服務的Kudu集群的Kudu主服務器串列,
- 代碼示例
/**
* 使用DataFrameApi讀取kudu表中的資料
* @param sparkSession
* @param kuduMaster
* @param tableName
*/
def getTableData(sparkSession: SparkSession, kuduMaster: String, tableName: String): Unit = {
//定義map集合,封裝kudu的master地址和要讀取的表名
val options = Map(
"kudu.master" -> kuduMaster,
"kudu.table" -> tableName
)
sparkSession.read.options(options).kudu.show()
}
2.3.3.2 DataFrameApi寫資料到kudu表中
在通過DataFrame API撰寫時,目前只支持一種模式“append”,尚未實作的“覆寫”模式,
- 代碼示例
/**
* 6)DataFrameApi寫資料到kudu表中
*/
def dataFrame2Kudu(session: SparkSession, kuduContext: KuduContext): Unit ={
val data = List(erainm(3, "canglaoshi", 14, 0), erainm(4, "xiaowang", 18, 1))
import session.implicits._
val dataFrame = data.toDF
//目前,在kudu中,資料的寫入只支持append追加
dataFrame.write.mode("append").options(kuduOptions).kudu
//查看結果
//導包
import org.apache.kudu.spark.kudu._
//加載表的資料,導包呼叫kudu方法,轉換為dataFrame,最后在使用show方法顯示結果
sparkSession.read.options(kuduOptions).kudu.show()
}
2.3.3.3 使用sparksql操作kudu表
?可以選擇使用Spark SQL直接使用INSERT陳述句寫入Kudu表;與’append’類似,INSERT陳述句實際上將默認使用 UPSERT語意處理;
- 代碼示例
/**
* 使用sparksql操作kudu表
* @param sparkSession
* @param sc
* @param kuduMaster
* @param tableName
*/
def SparkSql2Kudu(sparkSession: SparkSession, sc: SparkContext, kuduMaster: String, tableName: String): Unit = {
//定義map集合,封裝kudu的master地址和表名
val options = Map(
"kudu.master" -> kuduMaster,
"kudu.table" -> tableName
)
val data = List(erainm(10, "小張", 30, 0), erainm(11, "小王", 40, 0))
import sparkSession.implicits._
val dataFrame: DataFrame = sc.parallelize(data).toDF
//把dataFrame注冊成一張表
dataFrame.createTempView("temp1")
//獲取kudu表中的資料,然后注冊成一張表
sparkSession.read.options(options).kudu.createTempView("temp2")
//使用sparkSQL的insert操作插入資料
sparkSession.sql("insert into table temp2 select * from temp1")
sparkSession.sql("select * from temp2 where age >30").show()
}
2.3.4 Kudu Native RDD
Spark與Kudu的集成同時提供了kudu RDD.
- 代碼示例
val columnsList = List("id", "name", "age", "sex")
val rowRDD: RDD[Row] = kuduContext.kuduRDD(sc, TABLE_NAME, columnsList)
rowRDD.foreach(println(_))
sc.stop()
//session.read.options(kuduOptions).kudu.show()
2.3.5 修改表
/**
* 添加列
* @param kuduContext
*/
def addColumn(kuduContext: KuduContext): Unit ={
val alterTableOptions: AlterTableOptions = new AlterTableOptions
alterTableOptions.addColumn(new ColumnSchema.ColumnSchemaBuilder("Address", Type.STRING).nullable(true).build)
try {
kuduContext.syncClient.alterTable(tableName, alterTableOptions)
} catch {
case ex:Exception => ex.printStackTrace()
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/200419.html
標籤:其他
上一篇:es客戶端執行緒池配置