文章目錄
- 前言
- 一、為什么要用redis
- 二、多路復用模型
- 三、Redis的基操
- 1.String
- 2.Hash
- 3.List
- 4.Set
- 四、專案中購物車模塊整合redis優化
- 1.原始業務
- 2.目標任務
- 3.實作邏輯
- 五、發布與訂閱
- 六、Redis的持久化
- RDB
- AOF
- 使用RDB還是AOF?
- 七、搭建Redis主從復制,實作讀寫分離
- 主從架構
- info replication查看當前主從狀態
- 修改從節點配置
- 八、Redis快取過期與記憶體淘汰機制
- 過期的key怎么處理?
- 記憶體滿了怎么辦?記憶體淘汰機制
- 九、哨兵機制
- 故障轉移
- 約定
- 十、Redis集群:多主多從
- 槽結點
- 十一、快取穿透
- 1. 將非法用戶請求的資訊得到的空值也存到redis里面,屏蔽對資料庫的攻擊
- 2. 布隆過濾器
- 十二、快取雪崩
- 十三、Redis的批量查詢
前言
今天老爸發生活費了,比以前多給了幾百塊,于是就新買了個云服務器結點(學生優惠只能支持一臺服務器,沒優惠就貴得多,所以照著原來的配置只買了兩星期),新結點主要用來做redis主從復制、集群負載均衡, 專案背景:目前是單體架構的一個電商平臺,包括用戶、訂單、購物車、搜索、評價等等,資料庫使用的是MySQL,專案已經部署到了云服務器,并用nginx進行了反向代理,做了動靜分離, 目標:要用redis優化購物車部分(特別關注cookie與redis的快取邏輯),搭建主從復制,優化redis架構,提高redis可靠性,解決快取穿透、預防快取雪崩,一、為什么要用redis
- Redis的優點
- 速度快,Redis完全基于記憶體, 使用C語言實作,網路層使用epoll解決高并發問題,單執行緒模型避免了不必要的背景關系切換及競爭條件,
- 豐富的資料結構,包括String、Hash、Set、List等
- 支持持久化、主從同步、故障轉移等功能
- Redis的缺點
- 單執行緒
- 單核
- Memcache與redis對比
- Memcache不支持持久化
- Memcache多核多執行緒
- Memcache資料結構少
總結:redis適合存盤熱點資料(訪問量大),支持持久化存盤,并且提供了豐富的功能,
二、多路復用模型
前文已經提到,redis是單執行緒、單核的,設想下面的情況:假若有多個IO任務需要redis去完成,對于redis來說,如果一直阻塞等待IO,會導致效率的低下,
redis采用了多路復用模型,當請求到來時,若要等待,多路復用器就去處理其他請求;在處理請求時,多路復用器并不真正實作處理邏輯,而是把任務丟給后面的處理器,
一方面單執行緒避免了CPU的切換及加鎖,另一方面多路復用避免了阻塞等待的效率損耗,這使redis的速度得以保證,
三、Redis的基操
1.String

2.Hash

3.List

4.Set

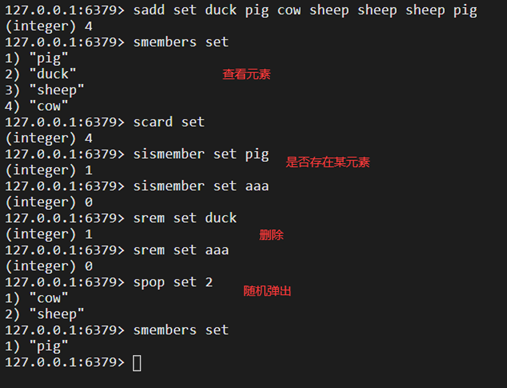
四、專案中購物車模塊整合redis優化
1.原始業務
原本的購物車中資料并沒有更新到資料庫,只是做了一個cookie進行瀏覽器的快取,當用戶未登錄,可以提交商品到購物車,但是不能下單,當用戶登錄后,可以進行下單操作,并將訂單更新到資料庫,
2.目標任務
使用redis將購物車中資料進行持久化存盤,并且要能和cookie進行融合
3.實作邏輯
1.redis中無資料
如果cookie中的購物車為空,那么這個時候不做處理
如果cookie中的購物車不為空,直接覆寫redis
2.redis中有資料
如果cookie中的購物車為空,那么直接把redis的購物車覆寫本地cookie中
如果cookie中的購物車不為空,redis中也存在,則以cookie為準,覆寫redis
3.同步到redis中之后,覆寫本地cookie購物車的資料,保證本地購物車的資料是同步的
/*
* 注冊登錄成功后,同步cookie和redis中的購物車資料
* */
private void sychShopcartData(String userId, HttpServletRequest request,
HttpServletResponse response) {
//1 從redis中獲取購物車
String shopcartJsonRedis = redisOperator.get(FOODIE_SHOPCART + ":" + userId);
//2 從cookie中獲取購物車
String shopcartStrCookie = CookieUtils.getCookieValue(request, FOODIE_SHOPCART, true);
if (StringUtils.isBlank(shopcartJsonRedis)) {
//redis為空,cookie不為空,把cookie放進redis
if (StringUtils.isNotBlank(shopcartStrCookie)) {
redisOperator.set(FOODIE_SHOPCART + ":" + userId, shopcartStrCookie);
}
} else {
//redis不為空,cookie不為空,合并cookie和redis中購物車的商品資料(同一商品覆寫redis)
if (StringUtils.isNotBlank(shopcartStrCookie)) {
/*
* 1.已經存在的,把cookie中對應的數量,覆寫redis
* 2.該項商品標記為待洗掉,統一放入一個待洗掉的list
* 3.從cookie 中清理所有的待洗掉list
* 4.合并redis和cookie中的資料
* 5.更新到redis和cookie中
* */
List<ShopcartBO> shopcartBOListRedis = JsonUtils.jsonToList(shopcartJsonRedis, ShopcartBO.class);
List<ShopcartBO> shopcartBOListCookie = JsonUtils.jsonToList(shopcartStrCookie, ShopcartBO.class);
//定義待洗掉List
List<ShopcartBO> pendingDeleyeList = new ArrayList<>();
for (ShopcartBO redisShopcart : shopcartBOListRedis) {
String redisSpecId = redisShopcart.getSpecId();
for (ShopcartBO cookieShopcart : shopcartBOListCookie) {
String cookieSpecId = redisShopcart.getSpecId();
if (redisSpecId.equals(cookieSpecId)) {
//覆寫購買數量,不累加
redisShopcart.setBuyCounts(cookieShopcart.getBuyCounts());
//把cookieShopcart放入待洗掉串列,用于最后的洗掉合并
pendingDeleyeList.add(cookieShopcart);
}
}
}
//從現有cookie中洗掉對應的覆寫過的商品資料
shopcartBOListCookie.removeAll(pendingDeleyeList);
//合并兩個list
shopcartBOListRedis.addAll(shopcartBOListCookie);
//更新到cookie和redis
CookieUtils.setCookie(request, response, FOODIE_SHOPCART, JsonUtils.objectToJson(shopcartBOListRedis), true);
redisOperator.set(FOODIE_SHOPCART + ":" + userId, JsonUtils.objectToJson(shopcartBOListRedis));
} else {
//redis不為空,cookie為空,直接把redis覆寫cookie
CookieUtils.setCookie(request, response, FOODIE_SHOPCART, shopcartJsonRedis, true);
}
}
}
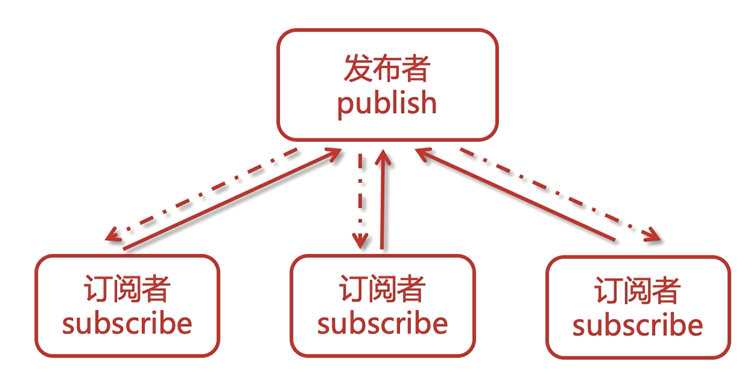
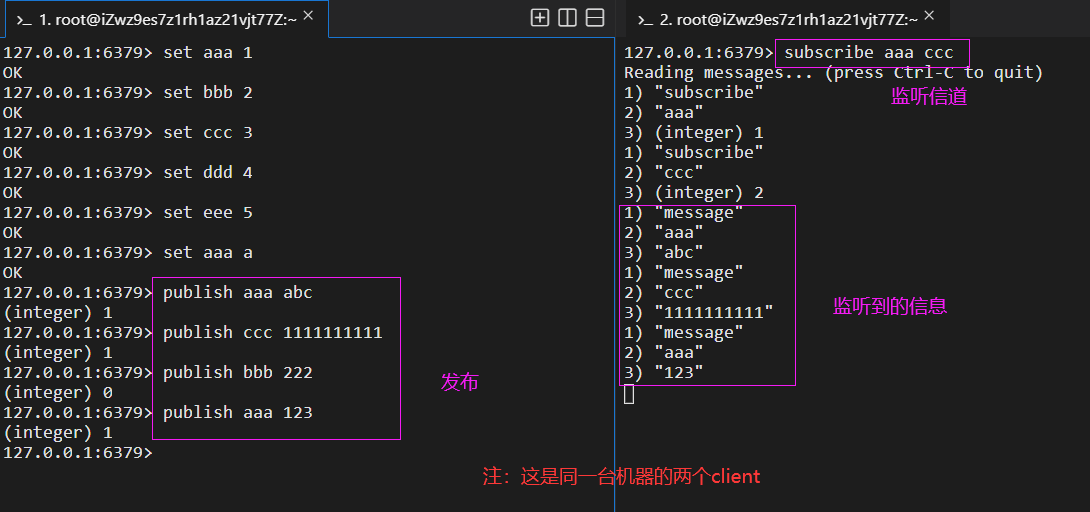
五、發布與訂閱
六、Redis的持久化
看了前面的理論,可能會有人感到懵逼:redis完全基于記憶體的,然而它卻可以持久化??當斷電了,記憶體里面的資料不就沒了??
參考:Redis官方檔案
Redis提供兩種持久化方案:RDB(Redis Database)、AOF(Append Only File)
RDB
每隔一段時間,把記憶體中的資料寫入磁盤的臨時檔案,作為快照,恢復的時候把快照檔案讀進記憶體,如果宕機重啟,記憶體里的資料丟失,那么再次啟動Redis后,則會恢復
- 優點:
- 每隔一段時間備份,全量備份
- 災備簡單,可以遠程傳輸
- 子行程備份的時候,主行程不會有任何的IO操作(可讀),保證備份資料的完整性
- 相對于AOF,當有更大的檔案的時候可以快速的重啟恢復
- 劣勢:
- 發生故障時,可能會丟失最后一次的備份資料
- 子行程所占用的記憶體會和父行程一模一樣,會造成CPU的負擔
- 由于定時全量備份是重量級操作,所以對于實時備份,就無法處理
配置RDB:
- 保存機制:

- 開啟RDB檔案壓縮模式
rdbcompression:yes - 對RDB檔案進行校驗(但是會有10%的記憶體損耗)
rdbchecksum:yes
總結:RDB適合大量資料的恢復,但是資料的完整性和一致性可能會不足,不過嘞,RDB丟失的那一點點其實也無所謂,反正是快取,丟了就丟了
AOF
AOF可以保證資料的完整性,
特點:1.以日志的形式來記錄用戶請求的寫操作,讀操作不會記錄,
2.檔案以追加的形式而不是修改的形式
3.redis通過AOF恢復,其實就是讀取日志,把寫操作重新執行一遍
-
優點:
- AOF可以以秒級別為單位進行備份,若發生問題,也只會丟失最后一秒資料,增加資料可靠性和完整性,
- 以log日志形式追加,若磁盤滿了,會執行redis-check-aof工具
- 當資料量太大,redis在后臺可以自動重寫aof,當redis繼續把日志追加到老的檔案中去,重寫也非常安全,不會影響客戶端的讀寫操作,
-
缺點
- 同一份資料,AOF檔案會比RDB檔案大
- 針對不同的同步機制,AOF會比RDB慢,因為AOF每秒都會備份做寫操作,
配置AOF

使用RDB還是AOF?
- 若可以接受一段時間的快取丟失,可以用RDB
- 若對實時性的資料比較關心,就用AOF
- 還可以使用RDB和AOF一起做持久化,RDB做冷備,可以在不同時期對不同版本做恢復,AOF做熱備,保證資料僅僅有1秒的損失,當AOF破損不可用,再用RDB進行恢復,即Redis先去加載AOF,若AOF出了問題,再去加載RDB,
七、搭建Redis主從復制,實作讀寫分離
主從架構
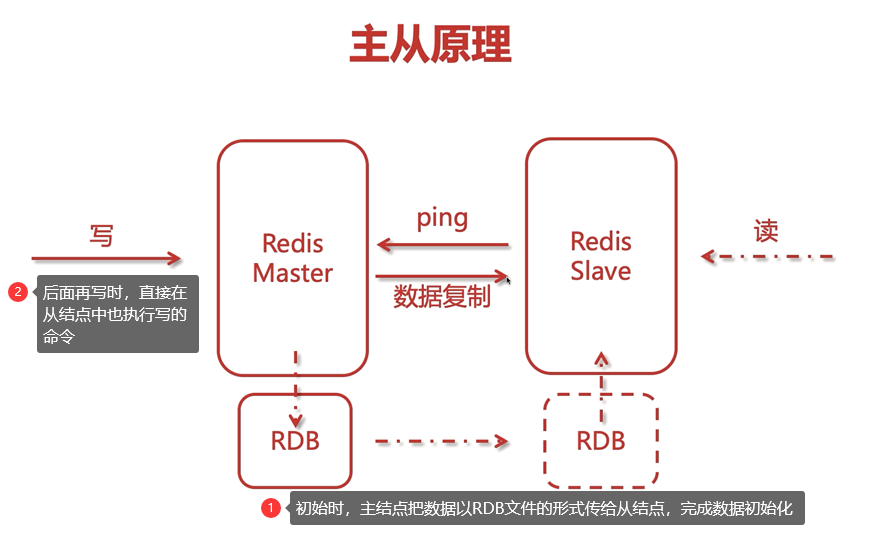
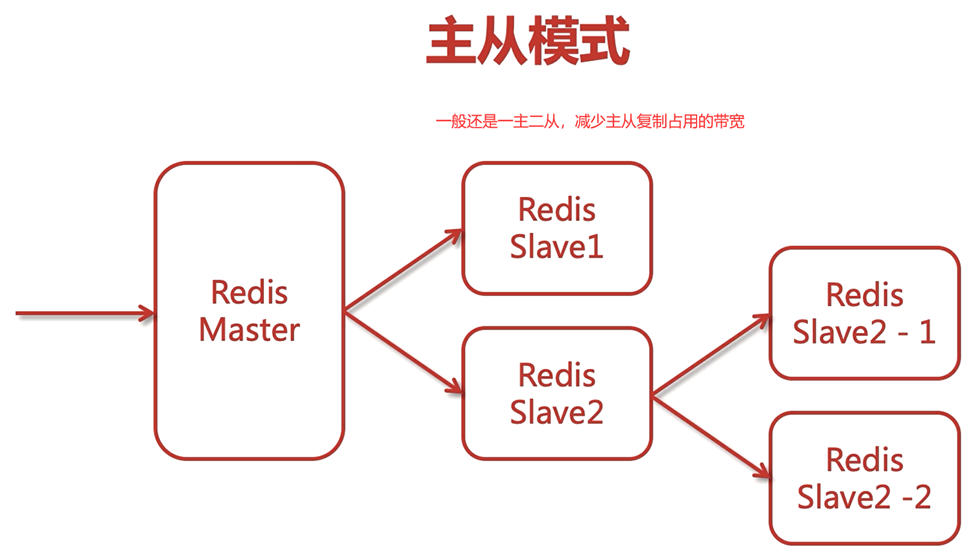
一般來說,主從模式是采用一主二從,但是由于資金有限,下面的配置中只搞了一個從結點,即一主一從
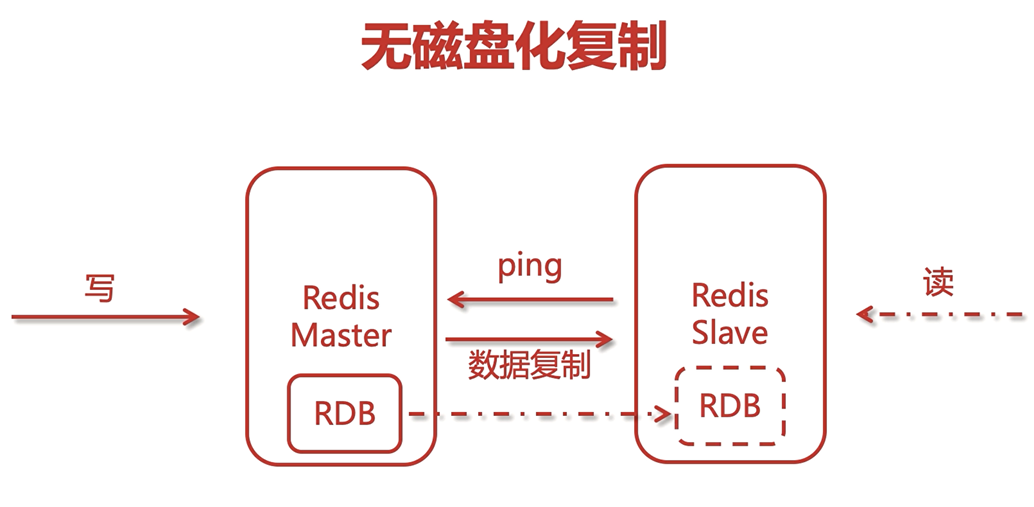
另一種主從方式:無磁盤化復制,若服務器中的磁盤是機械硬碟,可能磁盤的讀寫效率比較低,那么若網路帶寬比較好的話,可以采用網路的方式進行傳輸,避免了磁盤的互動,
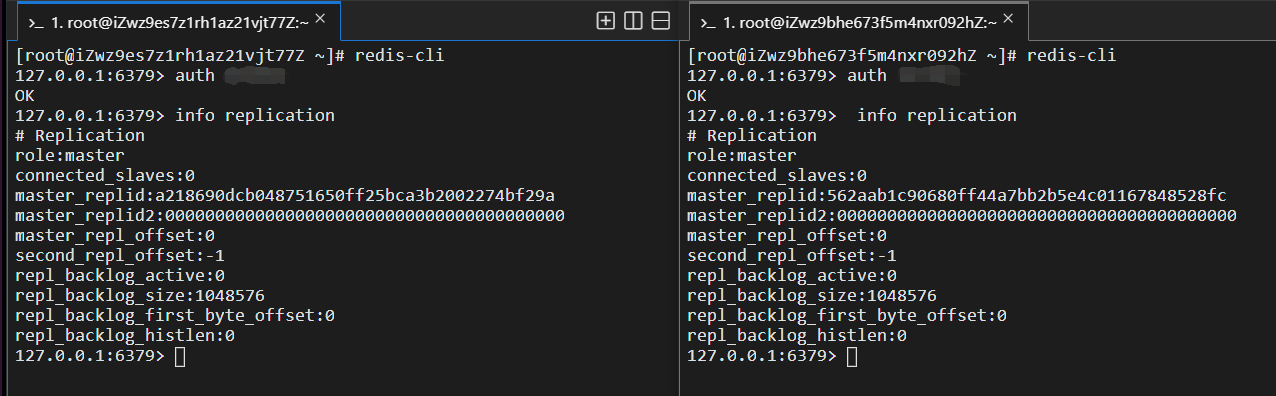
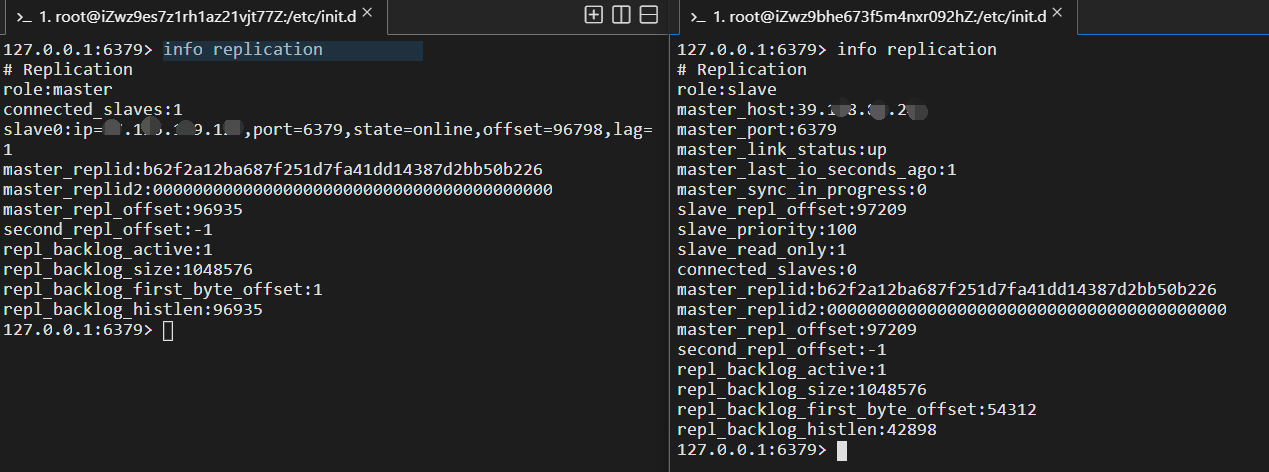
info replication查看當前主從狀態
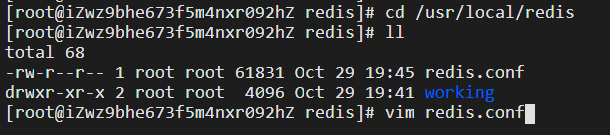
修改從節點配置
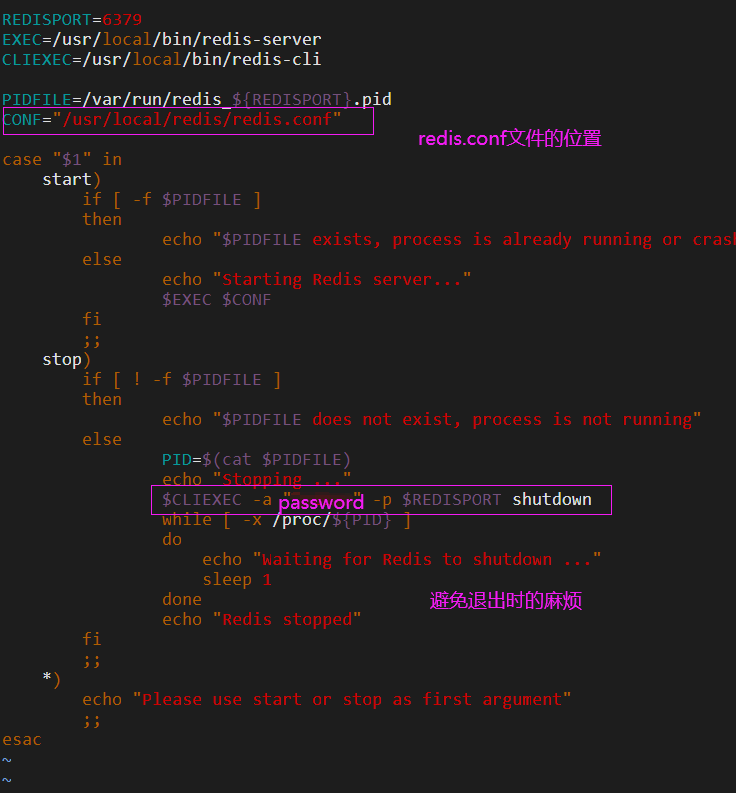
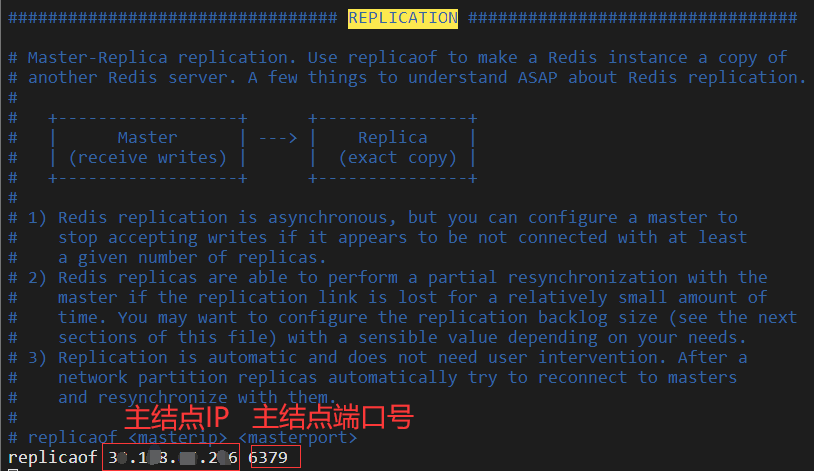


這時候,我們的slave即從節點已經配置好了,通過/etc/init.d下的redis_init_script進行重啟
在主結點上添加資訊,從節點上可以看到,而從節點不能寫資料
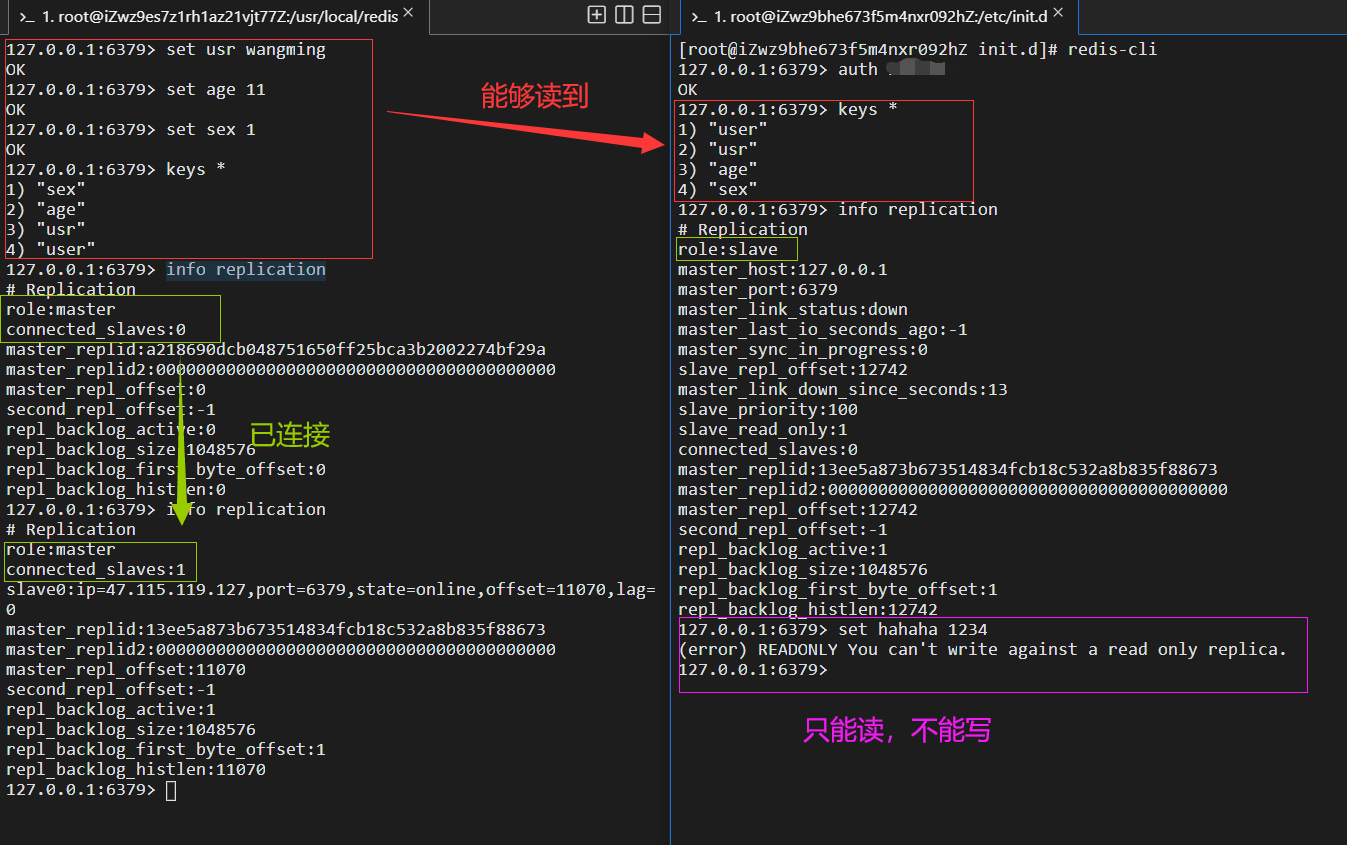
在這程序中可能遇到的問題:莫名其妙連接不上?建議檢查一下redis.conf檔案中的replicaof,可能是我的幻覺吧,不知道為啥它會自動的改為127.0.0.1 感覺有一絲恐怖,上面截圖里面就可以看到,它不正常
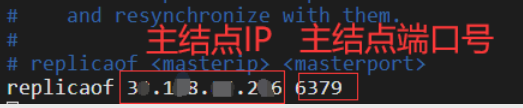
這才是正確的資訊:
八、Redis快取過期與記憶體淘汰機制
過期的key怎么處理?
- 主動定時清理:定時隨機檢查過期的key,如果過期則清除(配置頻率HZ),
- 被動惰性洗掉:當客戶端請求一個key時,若這個key過期了,就洗掉,
(因此,雖然key過期了,但只要沒被清理,它就還是占著記憶體)
記憶體滿了怎么辦?記憶體淘汰機制

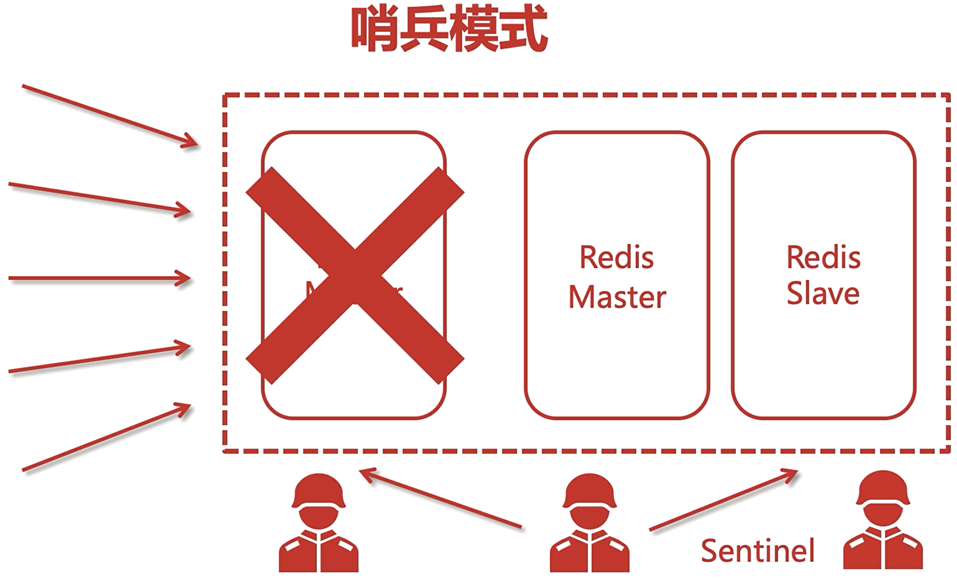
九、哨兵機制
在主從模式中,當主結點掛掉了怎么辦?它會導致寫不了,從結點也不能使用,
可以采用哨兵機制進行控制,當主結點被干掉了,就可以用哨兵來將子結點設定為主結點,
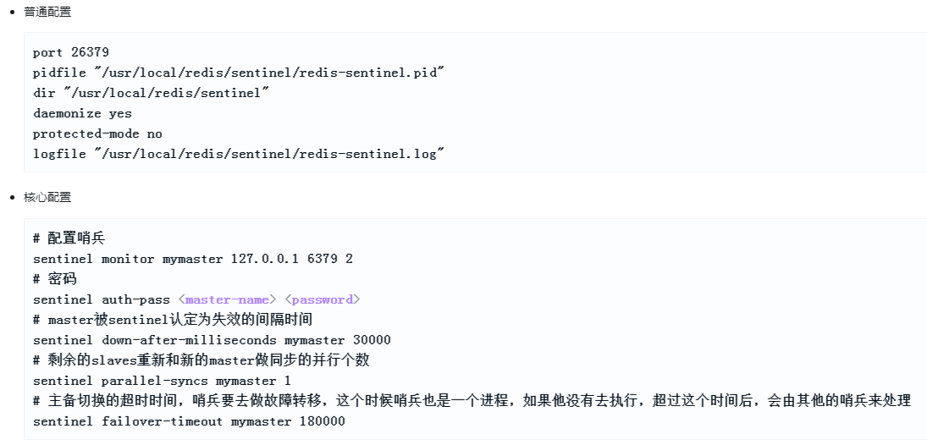
配置哨兵
故障轉移
當哨兵集群中的一個哨兵發現了Master掛掉了,它并不能決定是否進行主從的切換即故障轉移,因為在網路環境中,有可能是因為網路問題導致的錯誤判斷,這是稱為主觀下線
當多個哨兵都發現這個結點有問題時(客觀下線),才會進行故障轉移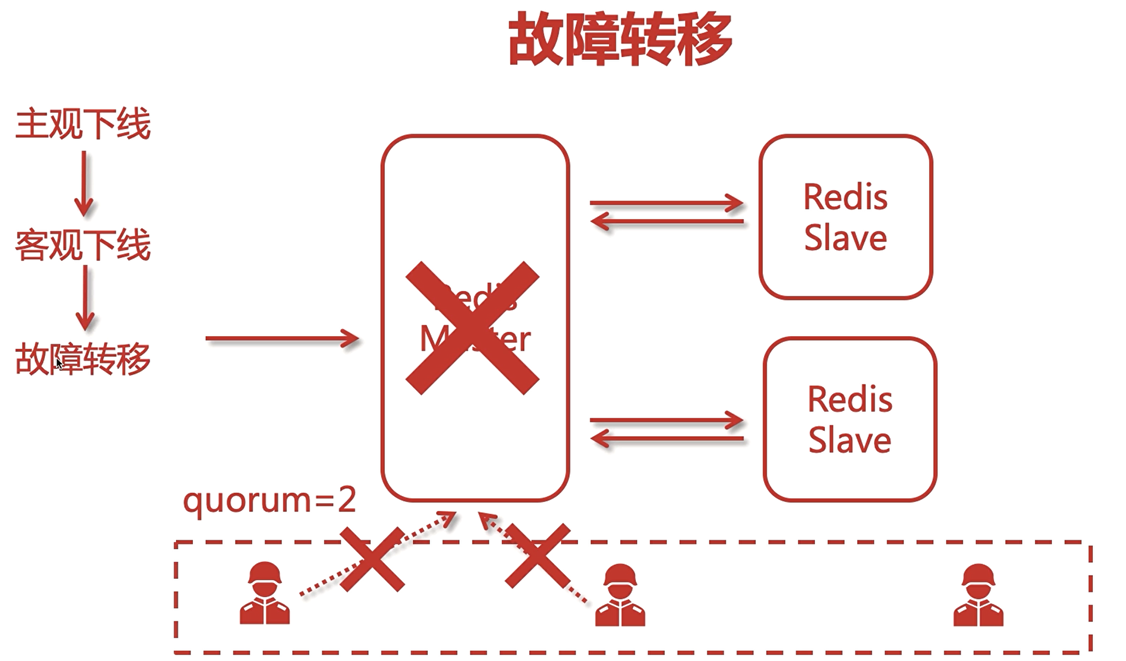
故障轉移:將slave轉為Master繼續進行服務,這個程序由眾多哨兵中的一個leader來執行,leader要進行選舉(少數服從多數),
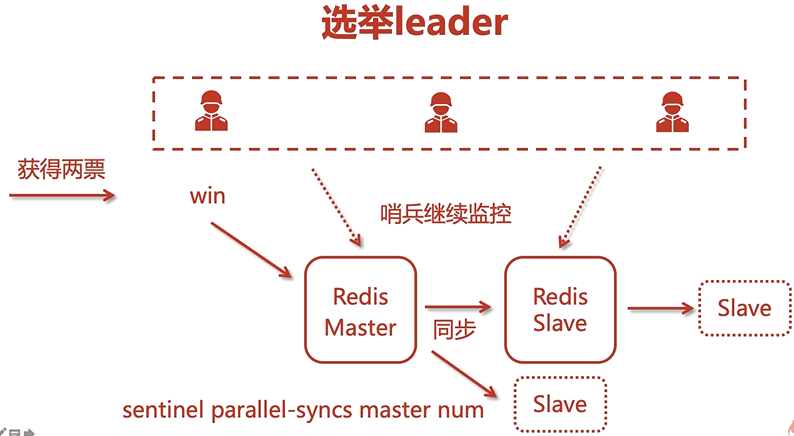
當某個哨兵獲得了多票之后,它就稱為leader,將原來的某個Slave轉為Master,然后將新Master的資訊和Slave進行同步,
若之前的Master恢復了,之前的Master會作為Slave重新加入,
約定
- 哨兵的結點至少有三個,或者奇數結點,(便于進行選舉,少數服從多數)
- 哨兵應部署在不同的計算機結點,(若都在一個結點上,當結點掛了,哨兵也完蛋了,就沒意義了)
- 一組哨兵只去監聽一組主從,
十、Redis集群:多主多從
一主的缺點:當老的master掛掉了,這時候進行主從故障轉移,然而若此時新來了一些寫操作,就會丟失,于是就有了多主多從
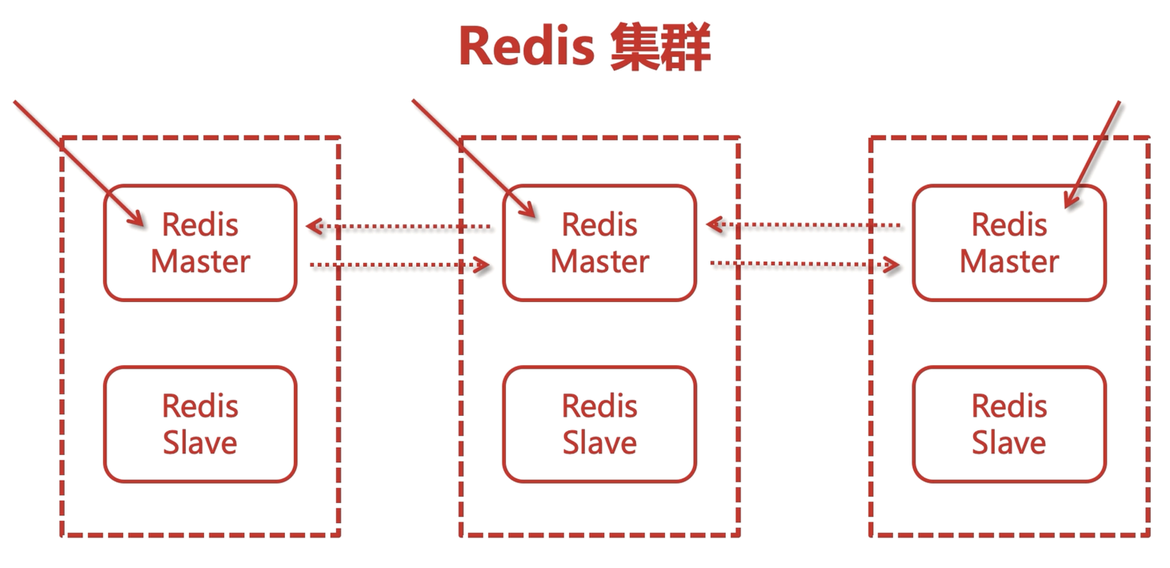
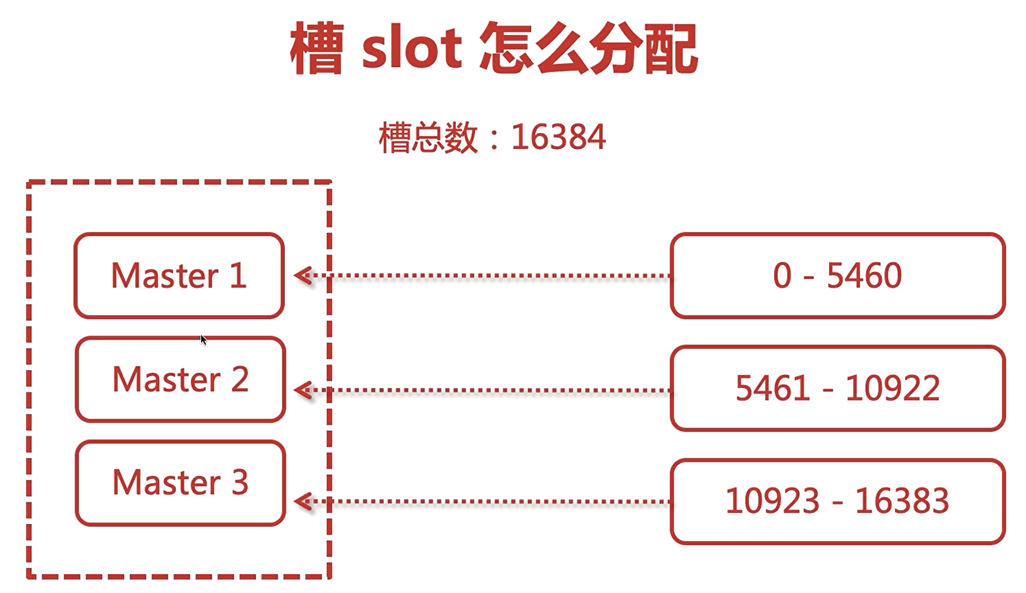
槽結點
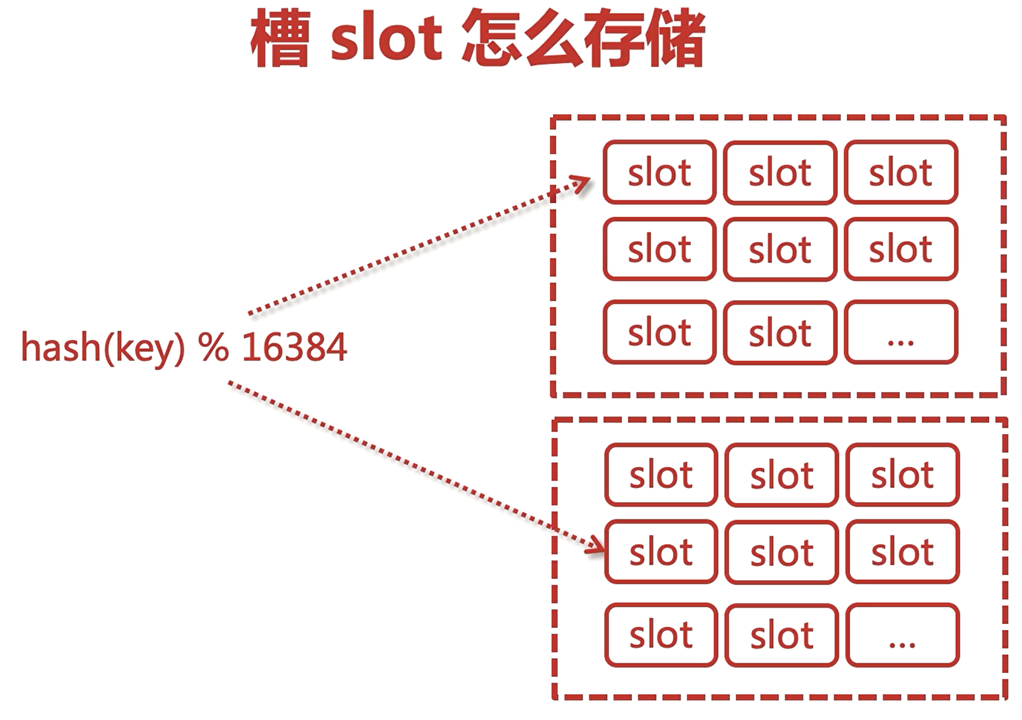
redis中的資料存盤在槽結點中
對于一個資料hash后求模,得到存盤的位置
十一、快取穿透
什么是快取穿透?
對于一些熱點資料,我們是存在redis中的,目的是減少資料庫的訪問量,但是若有一些非法用戶對系統進行攻擊,傳入一些根本不存在的值,按照之前的邏輯,會先去redis找,若查不到就去資料庫中查,如果不進行處理,會導致資料庫的訪問量增大,最后宕機,如何屏蔽掉這種非法訪問?
1. 將非法用戶請求的資訊得到的空值也存到redis里面,屏蔽對資料庫的攻擊
List<CategoryVO> list = new ArrayList<>();
String subCatsStr = redisOperator.get("subCat:"+rootCatId);
if (StringUtils.isBlank(subCatsStr)) {
list = categoryService.getSubCatList(rootCatId);
if (list!=null && list.size()>0){
redisOperator.set("subCat:"+rootCatId, JsonUtils.objectToJson(list));
}else {
/*
* 若被非法用戶攻擊(瘋狂訪問資料庫,使資料庫宕機)
* 即快取穿透
* 解決方法:將用戶非法的請求得到的空資料也快取在redis中,避免直接訪問資料庫
* */
redisOperator.set("subCat:"+rootCatId, JsonUtils.objectToJson(list),5*60);
}
} else {
list = JsonUtils.jsonToList(subCatsStr, CategoryVO.class);
}
return IMOOCJSONResult.ok(list);
2. 布隆過濾器
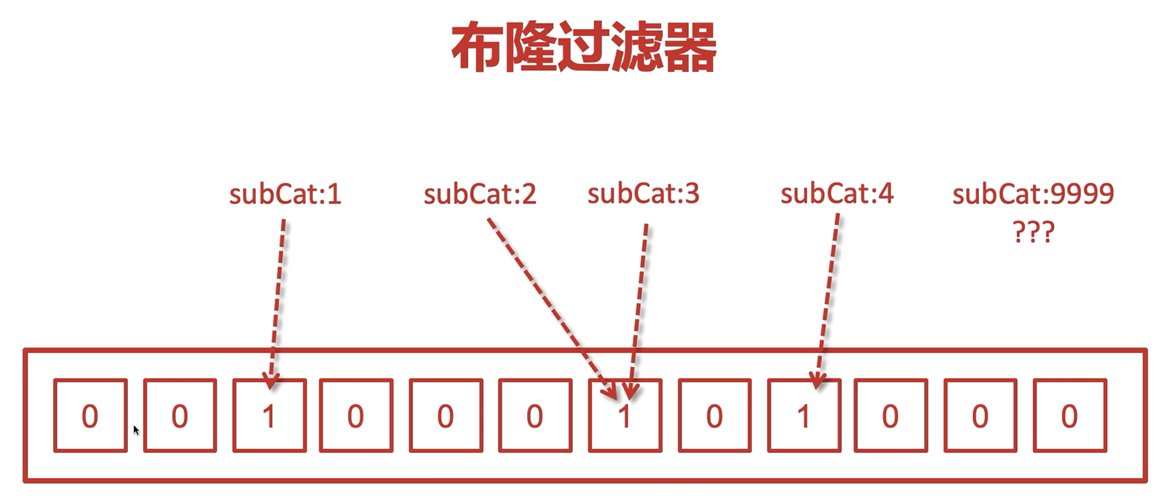
對于每個key,經過一定的運算,保存到陣列上的某個位置,并設定為1
當一個非法值過來之后,它匹配不上1,就連redis都不會進(很明顯,會存在誤判)
布隆過濾器的缺點:
- 不能移除資料(多個資料存在同一個位置)
- 存在誤判
- 錯誤率越低,占用空間越大
- 要維護一個集合,且要和redis互動
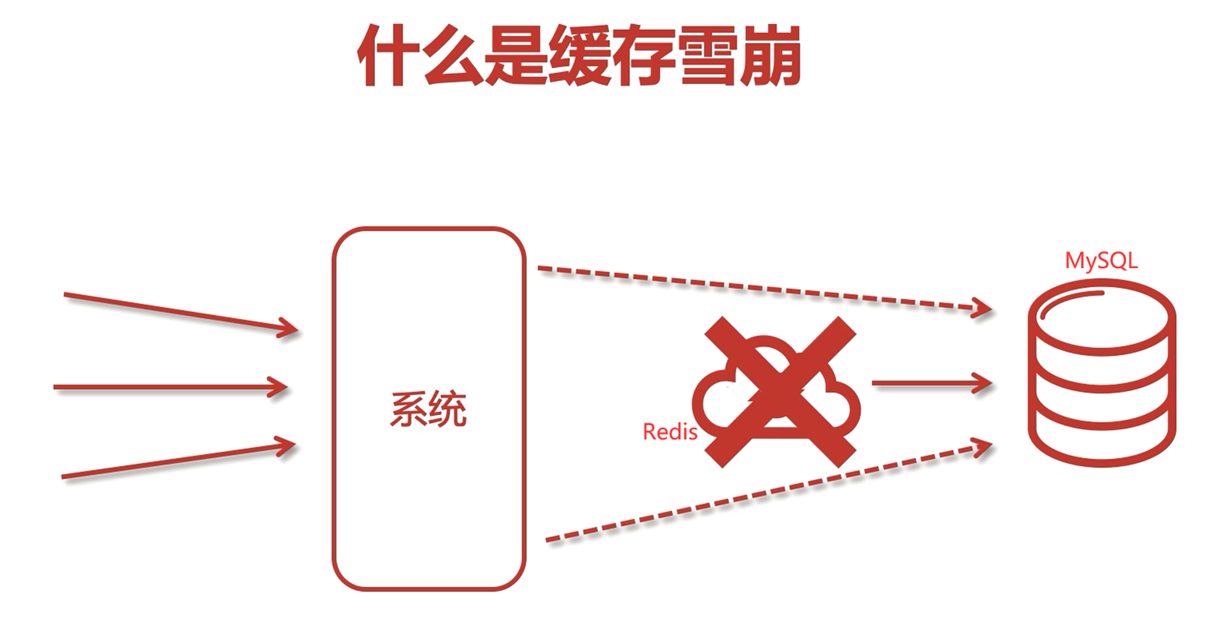
十二、快取雪崩
Redis中的快取恰好在某一時間點大面積的失效,而此時恰好出現了大量的請求,導致資料庫宕機

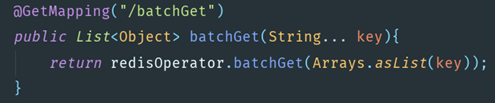
十三、Redis的批量查詢
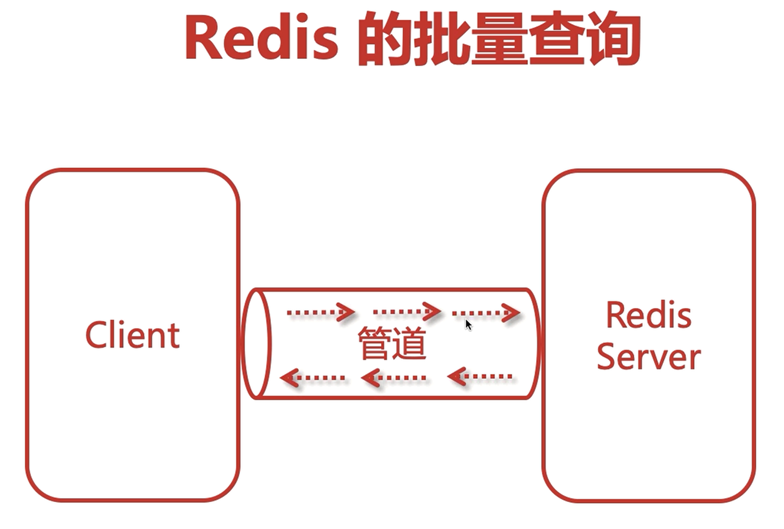
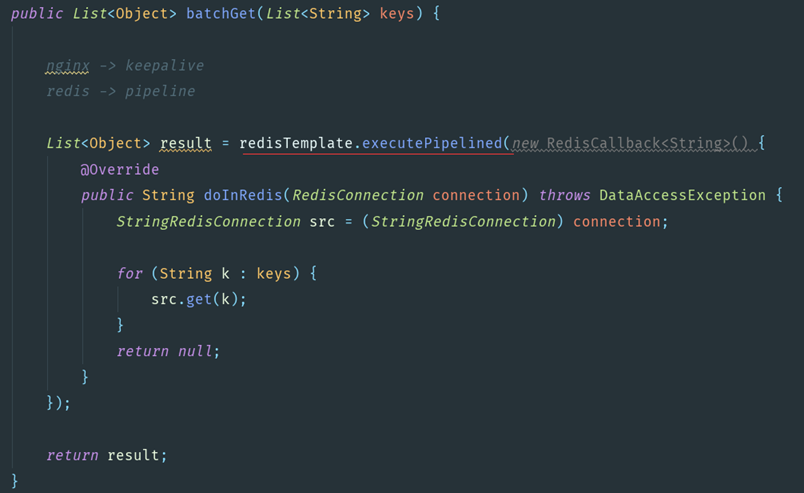
可以建立一個管道來一次性完成多個key的查詢
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/200423.html
標籤:其他
上一篇:安裝虛擬機開啟失敗,是什么情況