爬蟲百例專欄連載已經結束,歡迎訂閱 🙈100 篇爬蟲文章合計 29.9 元,每篇只需 2.9 毛錢 🙈
最新弄到一本不錯的書《中國妖怪故事(全集)》,忽然想到做一個收集整理中國妖怪的網站應該挺有意思的,故得此文,

寫爬蟲前的分析作業
對于撰寫爬蟲,很多時候找到一個目標網站,然后對該站點進行分析,總會找到一種途徑獲取到你想要的資料;還有一種情況就是今天這種了,我們碰到一個想法,覺得這個想法還不錯,然后嘗試抓取一些基本資料,在結合一下 PHP,JAVA 這些語言編一個網站出來,沒準能獲得不錯的流量,
今天要抓取的資料是 中國妖怪,除了自己整理以外,找到一個資料源網站就顯得很重要了,所以我直接打開百度一頓搜索,果然,以橡皮擦(https://dream.blog.csdn.net/)的智力還是很難想到一個市面上沒有人做過的點子的,
雖然關于妖怪的網站不多,但還真有一個 知妖 ,這個網站還真做了整理妖怪這么一個趣味性蠻強的作業,在這里為比我提前想到的 大佬,點個贊,

既然已經找到目標站點了,接下來的作業就比較簡單了,分析走起,
先看資料量是否全,我經常在博客里面寫的一句話是“只要人眼能看到的資料,爬蟲都能抓取到”,這個網站由于是個人維護的,所以資料展示的比較全面,當然量也不是很大,合計 130 頁左右,每次看到類似最后一頁這樣的描述,我就知道這網站爬取肯定有戲,

獲取分頁地址規律
隨便點擊 1~2 頁,就可以獲取到分頁的基本規律了,
https://www.cbaigui.com/page/4
https://www.cbaigui.com/page/3
https://www.cbaigui.com/page/130
可以看到上述地址中,頁碼就是一個單純的數字,
撰寫正則運算式
本次的目標是獲取到妖怪資料,爬蟲爬取程序中允許出現一定的冗余資料,所以直接分析頁面元素即可,看一下哪些資料有價值,

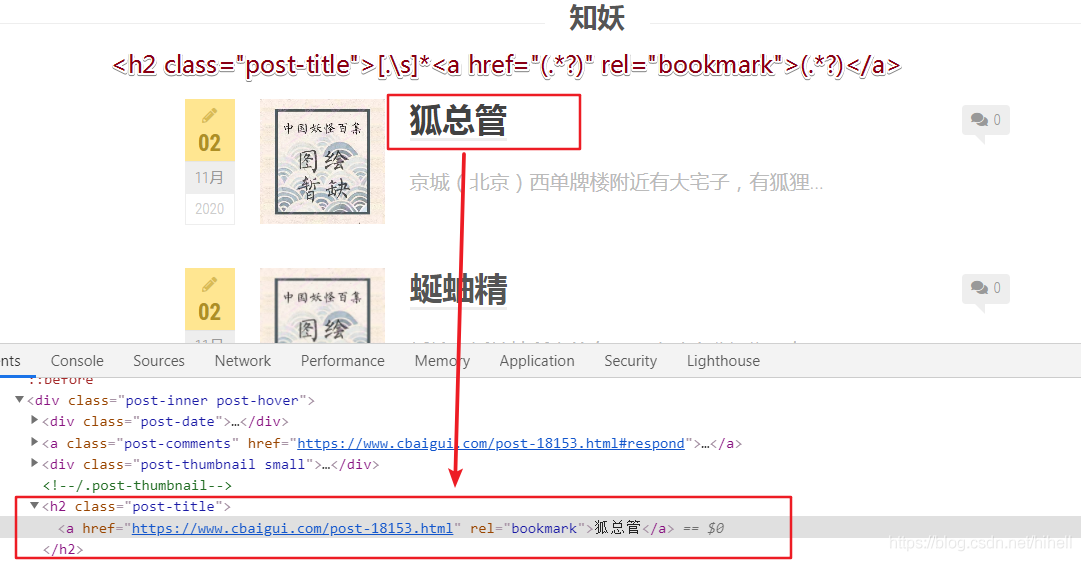
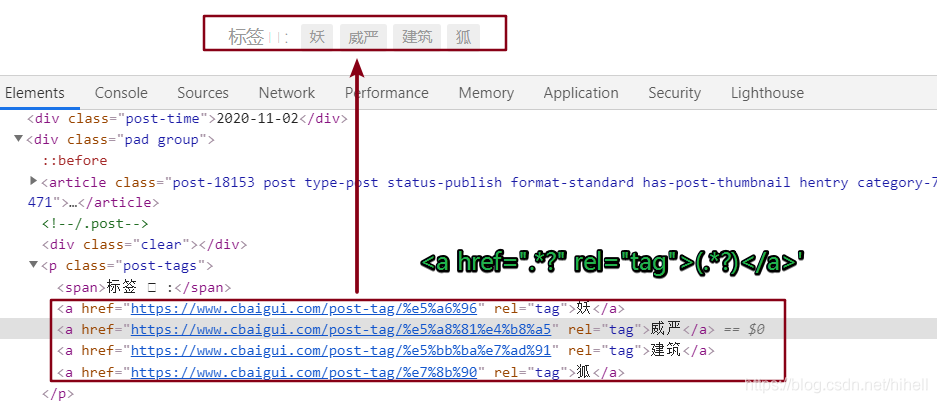
上圖紅框所示區域,為串列頁面比較核心的資料,這里其實要抓取 2 個值,第一個是標題,第二個是標題點擊之后的鏈接,抓取到鏈接,才可以獲取到內頁資料,即下面紅框所示的 tag 標簽區域,關于為何獲取這個標簽的原因,這里因人而異,我主要是為了獲取標簽之后進行相應的分類,

如果為了補全資料的完整性,你可以抓取頭部的一些其他資訊,里面包含一些朝代和妖怪的出處,

分析完畢,在橡皮擦看來,最難的作業就做完了,剩下的就是寫代碼抓取了,
爬蟲撰寫作業
這里大家需要注意下,該網站應該屬于個人開發者,所以我們在爬取的時候注意限制一下爬取速度,爬的太快對網站造成影響就不好了,
接下來編碼正式開始,
首先你可以通過一些正則運算式工具,先把正則匹配寫好,其實這部分寫好了,代碼也就撰寫一大部分了,
該頁面中用到了 2 處正則,第一個用來匹配標題與鏈接,正則如下:
第一個正則運算式:
<h2 class="post-title">[.\s]*<a href="(.*?)" rel="bookmark">(.*?)</a>
第二個正則運算式:
<a href=".*?" rel="tag">(.*?)</a>'
對于正則運算式寫的嚴謹性,在本系列專欄中不做要求,夠用,好用即可,
下面展示一下部分代碼,核心代碼已經完成,剩下的就交給你來實作啦!~
import requests
import re
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
def get_tags(url):
res = requests.get(url, headers=headers)
pattern = re.compile(
r'<a href=".*?" rel="tag">(.*?)</a>')
all = pattern.findall(res.text)
print(all)
def get_list(page):
url_format = "https://www.cbaigui.com/page/{page}"
url = url_format.format(page=page)
res = requests.get(url, headers=headers)
pattern = re.compile(
r'<h2 class="post-title">[.\s]*<a href="(.*?)" rel="bookmark">(.*?)</a>')
all = pattern.findall(res.text)
for item in all:
get_tags(item[0])
time.sleep(1)
if __name__ == "__main__":
total = int(input("請輸入最大頁碼:"))
for i in range(1, total):
get_list(1)
# get_tags("https://www.cbaigui.com/post-18153.html")
運行之后,發現結果中有個色欲?什么鬼?

好奇心沒忍住,找到鏈接點擊了一下,好好的翻閱了一下相關資訊,很有識訓,

爬蟲課后叨叨
完整的代碼大家自行補齊即可,剩余部分都是資料存盤相關內容了,你可以寫到csv檔案中即可,
爬蟲爬取資料之后,會發現很多的趣味性,例如本案例就無形中給我補充了很多知識,
👯👯👯
廣宣時間
如果你想跟博主建立親密關系,可以關注博主,或者關注博主公眾號“
非本科程式員”,了解一個非本科程式員是如何成長的,
博主 ID:夢想橡皮擦,希望大家點贊、評論、收藏

爬蟲百例教程導航鏈接 : 專欄購買地址
以下內容無用,為本篇博客被搜索引擎抓取使用
(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)
python 是干什么的 零基礎學 python 要多久 python 為什么叫爬蟲
python 爬蟲菜鳥教程 python 爬蟲萬能代碼 python 爬蟲怎么掙錢
python 基礎教程 網路爬蟲 python python 爬蟲經典例子
python 爬蟲 python 爬蟲 python 爬蟲 python 爬蟲 python 爬蟲 python 爬蟲 python 爬蟲
(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)
以上內容無用,為本篇博客被搜索引擎抓取使用
 CSDN認證博客專家
大學老師
高級產品經理
互聯網從業者
CSDN認證博客專家
大學老師
高級產品經理
互聯網從業者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/200931.html
標籤:其他