安徽京準:基于人工智能的微表情識別技術
安徽京準:基于人工智能的微表情識別技術
摘要: 應對重大突發事件的能力是一個城市現代化程度的重要標志,自911 事件以后,各個國家更加迫切需要行之有效的社會安全風險預警,目前我國正進入“突發公共事件的高發期”和“社會高風險期”,如何利用科技手段應對“兩高”,是我國政府的當務之急,隨著人工智能技術的發展,機器智能可以利用海量的視頻資料,結合模式識別、深度學習等先進演算法,使視頻分析精細化、可視化、自動化、智能化,本文介紹了一種新穎的基于人工智能的情緒分析技術,在非接觸微表情研究、微表情與情緒關系的心理學研究理論基礎上,介紹了基于微表情識別的靈敏、精準和魯棒無感知情緒監測分析系統,并制定相應的預警策略,使其能夠輔助人們理解和分析人員的動機,為社會安全風險控制提供預警與決策的潛在線索,該系統也可推廣應用于金融評估、商業談判、心理干預等,用于對人員的真實情緒進行分析,具有良好的潛在應用價值,
關鍵詞: 人工智能,微表情,情緒

針對人們真實情緒和意圖的研究始終是心理學和社會學主要研究方向,在20世紀早期,有學者開始以生理指標為基礎的情緒或者意圖研究,1921年加州大學John Larson發明了測謊儀,之后又出現了基于熱影像、腦電信號以及功能磁共振成像等方法的生理監測方法,但這些方法的資訊采集需要專門設備,而且這些評估手段基本公開,人們可以經過一定的訓練來隱瞞其真實意圖,與上述生理線索相比,面部表情是在人類進化程序中形成的,是人類之間傳遞社會資訊的主要手段和直觀手段,由于面部表情特征包含豐富直觀的情緒資訊,并且可以通過非接觸的采集方式獲取,因此獲得人們廣泛關注,
表情是情緒的主觀體驗的外部表現模式,分為生理表情(真實心理狀態)、情緒表情(真實心理狀態+偽裝決策)和社交表情(理性決策和控制)等,美國Paul Ekman教授將人類的面部表情分為六類:高興、驚訝、悲傷、憤怒、厭惡、恐懼,其中,心理學家和神經學家發現,欺騙者會通過情緒欺騙試圖壓抑某些反映真實情緒的信號,但卻無法完全壓抑,導致其真實情緒信號泄露,這便出現了微弱且快速的面部動作,即微表情,微表情則特指人類試圖壓抑或隱藏真實情感時泄露的非常短暫且不能自主控制的面部表情,美國著名心理學家,表情和微表情的奠基者Ekman經過研究認為,微表情具有三個特點:持續時間不超過1/5秒,能反映人的真實情感,在全人類是普遍存在的,
微表情可能是判斷一個人真實情感的最有利的線索,經過幾十年的理論發展和試驗驗證,微表情逐漸被學術界接受和認可,美國已經在這方面進行了幾十年的研究作業,已被美國交通運輸安全部用于多個機場的安檢中,此外,在美國司法審訊、臨床醫學等領域也進行了應用測驗,但國內在微表情的研究起步較晚,研究成果較少,而由于該領域的研究在很大程度上對于國家安全和司法實踐較為重要,所能獲得的國外資料較少,這種封鎖在一定程度上也說明了微表情研究的重要意義和潛在價值,因此有必要加強對微表情的研究,
在實際應用中,人們往往需要針對長視頻中的面部表情進行分析,因此,作為一套完整實用系統,首先需要研究微表情和宏表情聯合檢測技術,并對檢測到的面部序列進行糾正,然后以糾正過的面部序列為基礎,對其中包含的情緒進行分類識別,進而建立從檢測到識別的系統體系, 主要研究內容如下:
(1)基于長視頻的宏表情與微表情檢測研究
目前大多微表情研究仍基于對樣本影像和確定視頻幀的識別,而真實系統則需要從長視頻中檢測到微表情的出現才能進一步對微表情進行分析,由此,作為微表情研究的技識訓礎,首先將在微表情與宏表情檢測的研究基礎上,研究并刻畫宏表情與微表情在時間和空間上的差異性,降低宏表情在微表情檢測時的干擾影響,并通過對面部運動強度和時空約束的分析來探索實時性和可靠性的制約關系,建立優化模型進行問題求解,解決微表情和宏表情并存的檢測難題,最終為實作表情變化分析提供良好的基礎保障,
(2)基于人臉通用三維模型配準的正面視角表情影像合成
人臉姿態的任意性客觀上造成了不同程度形變壓縮的人臉形狀和自遮擋的不可見紋理,這將使表情識別和分類子系統性能急劇惡化,因此,如何高效準確的對輸入影像進行姿態估計是提高合成影像準確率的關鍵問題,對于給定的輸入影像,如何協調計算復雜性和結果精確度二者的矛盾,進行關鍵區域的必要特征點標定,是合成正面影像的又一難點,
(3)基于多動態區域特征融合的微表情識別
微表情識別的可靠性是保障微表情分析的基礎和關鍵,目前微表情的識別率和實時性都遠遠達不到真實環境下的性能要求,如何通過對微表情資料的分析,減少冗余幀的干擾和提高微表情的識別速度是識別效率的關鍵性技術,為此,如何探索基于紋理特征和基于運動特征對微表情的刻畫程度,同時考慮到微表情在面部區域性的視覺體現,建立基于權重策略的區域紋理特征和運動特征融合的特征提取求解模型,最終實作實時可靠的微表情識別演算法,為表情變化分析提供支撐,
(4)基于實時表情變化分析的行為預警
微表情識別的目的在于通過機器智能為人們提供預警參考,如何根據表情識別的結果,進行合理的表情變化預測分析,進而及時排查出可疑人員是預警系統的核心難題,研究多指標聯合預警策略,保障預警的實時性和可靠性,輔助相關人員對特殊事件快速做出反應,是對情感分析所反映的潛在行為分析的有效途徑,
微表情自動分析可以分為檢測和識別兩個程序,相比于可以借鑒宏表情檢測技術的微表情監測,微表情的識別技術具有更大的研究挑戰,這也是目前微表情領域的研究重點,
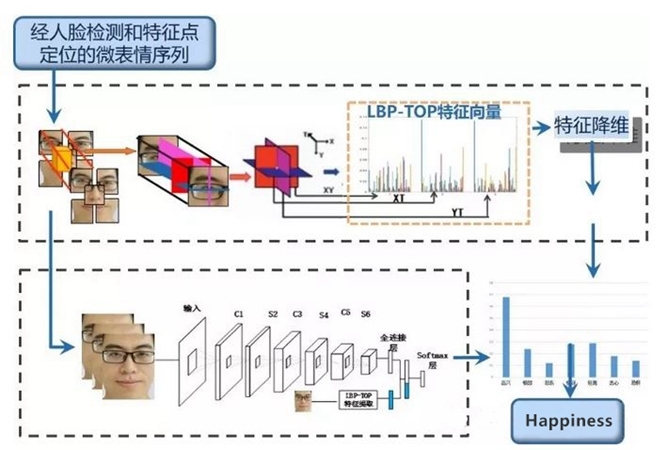
由于微表情持續時間短和動作幅度小兩大識別難點,目前的識別率仍有很大的提升空間,傳統大多采用基于聚類的方法,聯合3D高斯濾波器和K均值演算法,來測量微表情的開始、峰值和結尾階段,然而在這個方法中,聚類的數量很難決定,另一種基于分類的方法可以利用時空區域紋理描述器來表示特征,隨后通過支持向量機SVM(Support Vector Machine, SVM)分類器來進行分類,這些作業大都致力于在特征的層面上改進微表情識別的性能,取得了一定的性能改進,但是仍然欠缺計算得到特征的可解釋性,為此,我們提出一種基于深度學習的微表情識別方法、深度學習的概念由Hinton等人于2006年提出,屬于機器學習研究中的一個新的領域,是一種試圖使用包含復雜結構或由多重非線性變換構成的多個處理層對資料進行高層抽象的演算法,演算法本質是對資料的表征學習,目標是尋求更好的表示方法并創建更好的模型來從大規模未標記資料中學習這些表示方法,例如,針對一幅影像,觀測值可以使用多種方式來表示,如每個像素強度值的向量,或者更抽象地表示成一系列邊、特定形狀的區域等,而使用某些特定的表示方法更容易從實體中學習任務,按照訓練樣本標簽的有無,深度學習可以分為有監督學習(supervised learning)和無監督學習(unsupervised learning),
深度學習理論基礎是機器學習中的分散表示(distributed representation),分散表示假定觀測值是由不同因子相互作用生成,在探究這種相互作用的程序中,深度學習受到人類視覺原理的啟發,人類的視覺原理如下:從原始信號攝入開始(瞳孔攝入像素),接著做初步處理(大腦皮層某些細胞發現邊緣和方向),然后抽象(大腦判定,眼前的物體的形狀,是圓形的),然后進一步抽象(大腦進一步判定該物體是只氣球),因而,深度學習也采用逐層依次進行,逐步泛化抽象的基本結構:假定不同因子相互作用的程序可分為多個層次,代表對觀測值的多層抽象,不同的層數和層的規模可用于不同程度的抽象,更高層次的概念從低層次的概念學習得到,這一分層結構常常使用貪婪演算法逐層構建而成,并從中選取有助于機器學習的更有效的特征,
基于深度學習的微表情識別作業流程包括以下四個步驟:
1) 準備資料集:包含微表情的視頻片段采集、視頻影像歸一化處理、訓練/驗證/測驗集分割等;
2) 設計學習模型:選擇基本模型框架為卷積神經網路CNN+回圈神經網路RNN、調整網路層數、確定損失函式、設計學習率等超引數;
3) 訓練模型:將模型輸出誤差通過BP演算法反向傳播,利用隨機梯度下降SGD或Adam演算法優化模型引數;
4) 驗證模型:利用未訓練的資料驗證模型的泛化能力,如果預測結果不理想,則需要重新設計模型,進行新一輪的訓練;
至今已有數種成熟的深度學習模型,包括深度神經網路DNN、卷積神經網路CNN和深度置信網路DBN和遞回神經網路RNN等,在語音識別、機器視覺、自然語言處理、生物資訊學等領域得到廣泛應用、并且取得了顯著效果,
微表情分析是目前極具前瞻性的研究領域,人工智能深度學習模型的引入,較大提升了微表情識別性能,也將加速該領域的應用進展,但是,由于深度學習的黑盒特性,難以對微表情識別的特征提取程序進行定性研究,為此,仍需要進一步加強對深度學習模型的可視化技術研究,提高學習模型的可靠性分析并在可解釋性的基礎上進一步提高微表情識別準確度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/201305.html
標籤:其他
上一篇:STL 方法記錄