作者|Travis Tang (Voon Hao)
編譯|VK
來源|Towards Data Science
在這一點上,任何人都認為機器學習在醫學領域的潛力是老生常談的,有太多的例子支持這一說法-其中之一就是微軟利用醫學影像資料幫助臨床醫生和放射科醫生做出準確的癌癥診斷,同時,先進的人工智能演算法的發展大大提高了此類診斷的準確性,毫無疑問,醫療資料如此驚人的應用,人們有充分的理由對其益處感到興奮,
然而,這種尖端演算法是黑匣子,可能很難解釋,黑匣子模型的一個例子是深度神經網路,輸入資料通過網路中的數百萬個神經元后,作出一個單一的決定,這種黑盒模型不允許臨床醫生用他們的先驗知識和經驗來驗證模型的診斷,使得基于模型的診斷不那么可信,
事實上,最近對歐洲放射科醫生的一項調查描繪了一幅在放射學中使用黑匣子模型的現實圖景,調查顯示,只有55.4%的臨床醫生認為沒有醫生的監督,患者不會接受純人工智能的應用,[1]

在接受調查的635名醫生中,超過一半的人認為患者還沒有準備好接受僅僅由人工智能生成的報告,
下一個問題是:如果人工智能不能完全取代醫生的角色,那么人工智能如何幫助醫生提供準確的診斷?
這促使我探索有助于解釋機器學習模型的現有解決方案,一般來說,機器學習模型可以分為可解釋模型和不可解釋模型,簡而言之,可解釋的模型提供的輸出與每個輸入特征的重要性相關,這些模型的例子包括線性回歸、logistic回歸、決策樹和決策規則等,另一方面,神經網路形成了大量無法解釋的模型,
有許多解決方案可以幫助解釋黑匣子模型,這些解決方案包括Shapley值、部分依賴圖和Local Interpretable Model Agnostic Explanations(LIME),這些方法在機器學習實踐者中很流行,今天,我將關注LIME,
根據Ribeiro等人[2]的LIME論文,LIME的目標是“在可解釋表示上識別一個區域忠實于分類器的可解釋模型”,換句話說,LIME能夠解釋某一特定點的分類結果,LIME也適用于所有型別的模型,使其不受模型影響,
直觀解釋LIME
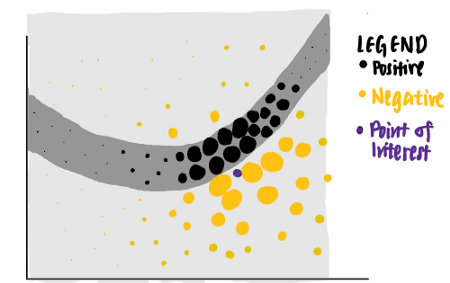
聽起來很難理解,讓我們一步一步地把它分解,假設我們有以下具有兩個特征的玩具資料集,每個資料點都與一個基本真相標簽(正或負)相關聯,
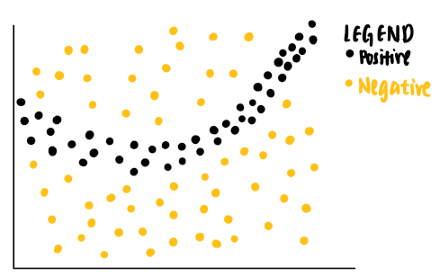
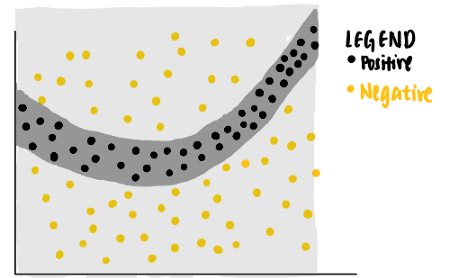
從資料點可以看出,線性分類器將無法識別區分正負標簽的邊界,因此,我們可以訓練一個非線性模型,例如神經網路,來對這些點進行分類,如果模型經過良好訓練,它能夠預測落在深灰色區域的新資料點為正,而落在淺灰色區域的另一個新資料點為負,
現在,我們很好奇模型對特定資料點(紫色)所做的決定,我們捫心自問,為什么這個特定的點被神經網路預測為負?
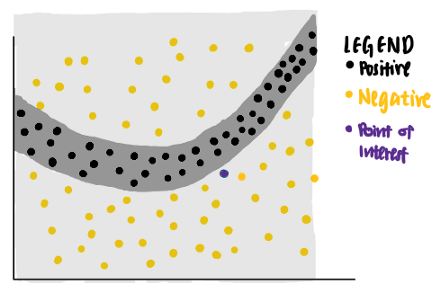
我們可以用LIME來回答這個問題,LIME首先從原始資料集中識別隨機點,并根據每個資料點到紫色興趣點的距離為每個資料點分配權重,采樣資料點越接近感興趣的點,就越重要,(在圖片中,較大的點表示分配給資料點的權重更大,)
使用這些不同權重的點,LIME給出了一個具有最高可解釋性和區域保真度的解釋,
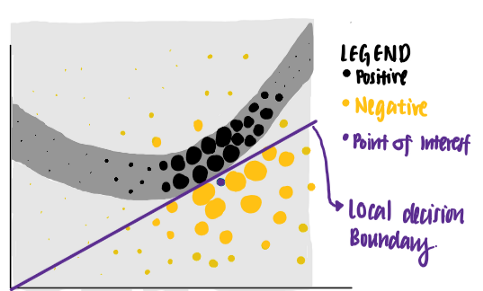
使用這個標準,LIME將紫色線標識為興趣點的已知解釋,我們可以看到,紫線可以解釋神經網路的決策邊界靠近資料點,所學的解釋具有較高的區域保真度,但全域保真度較低,
讓我們看看LIME在實際中的作用:現在,我將重點介紹LIME在解釋威斯康辛州乳腺癌資料訓練的機器學習模型中的使用,
威斯康星州乳腺癌資料集:了解癌細胞的預測因子
威斯康星州乳腺癌資料集[3],由UCI于1992年發布,包含699個資料點,每個資料點代表一個細胞樣本,可以是惡性的也可以是良性的,每個樣品也有一個數字1到10,用于以下特征,
-
腫塊厚度:Clump Thickness
-
細胞大小均勻性:Uniformity of Cell Size
-
細胞形狀均勻性:Uniformity of Cell Shape
-
單個上皮細胞大小:Single Epithelial Cell Size
-
有絲分裂:Mitoses
-
正常核:Normal Nucleoli
-
乏味染色體:Bland Chromatin
-
裸核:Bare Nuclei
-
邊緣粘著性:Marginal Adhesion
讓我們試著理解這些特征的含義,下面的插圖使用資料集的特征顯示了良性和惡性細胞之間的區別,
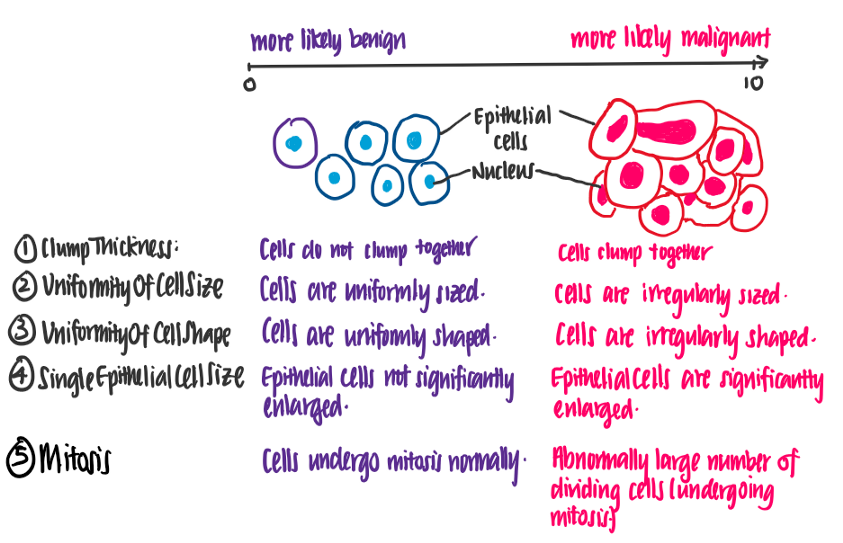
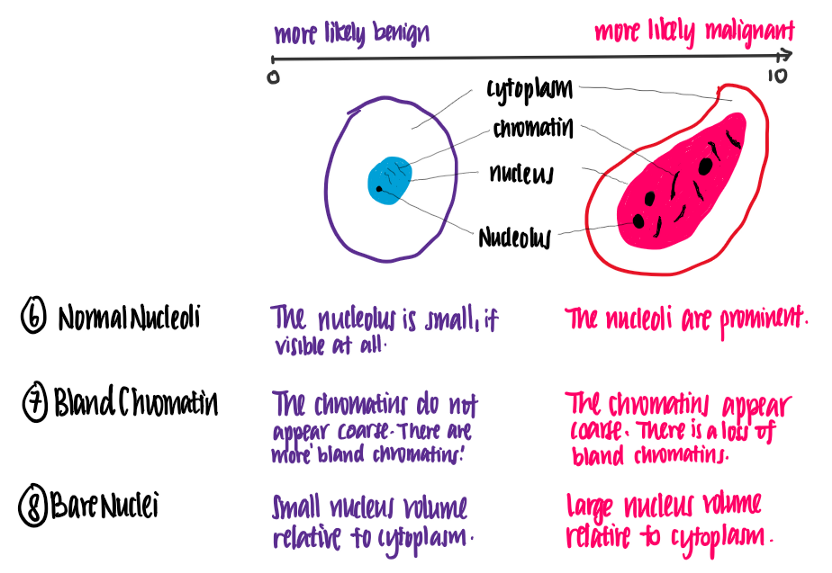
感謝醫學院的朋友的專題講解,
從這個例子中,我們可以看到每個特征值越高,細胞越有可能是惡性的,
預測細胞是惡性還是良性
現在我們已經理解了資料的含義,讓我們開始編碼吧!我們首先讀取資料,然后通過洗掉不完整的資料點并重新格式化類列來清理資料,
資料匯入、清理和探索
# 資料匯入和清理
import pandas as pd
df = pd.read_csv("/BreastCancerWisconsin.csv",
dtype = 'float', header = 0)
df = df.dropna() # 洗掉所有缺少值的行
# 原始資料集在Class列中使用值2和4來標記良性和惡性細胞,此代碼塊將其格式化為良性細胞為0類,惡性細胞為1類,
def reformat(value):
if value =https://www.cnblogs.com/panchuangai/p/= 2:
return 0 # 良性
elif value == 4:
return 1 # 惡性
df['Class'] = df.apply(lambda row: reformat(row['Class']), axis = 'columns')
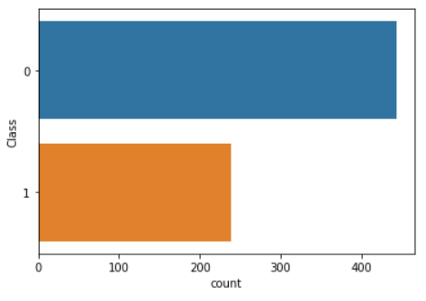
在洗掉了不完整的資料之后,我們對資料進行了簡單的研究,通過繪制細胞樣本類別(惡性或良性)的分布圖,我們發現良性(0級)細胞樣本多于惡性(1級)細胞樣本,
import seaborn as sns
sns.countplot(y='Class', data=https://www.cnblogs.com/panchuangai/p/df)
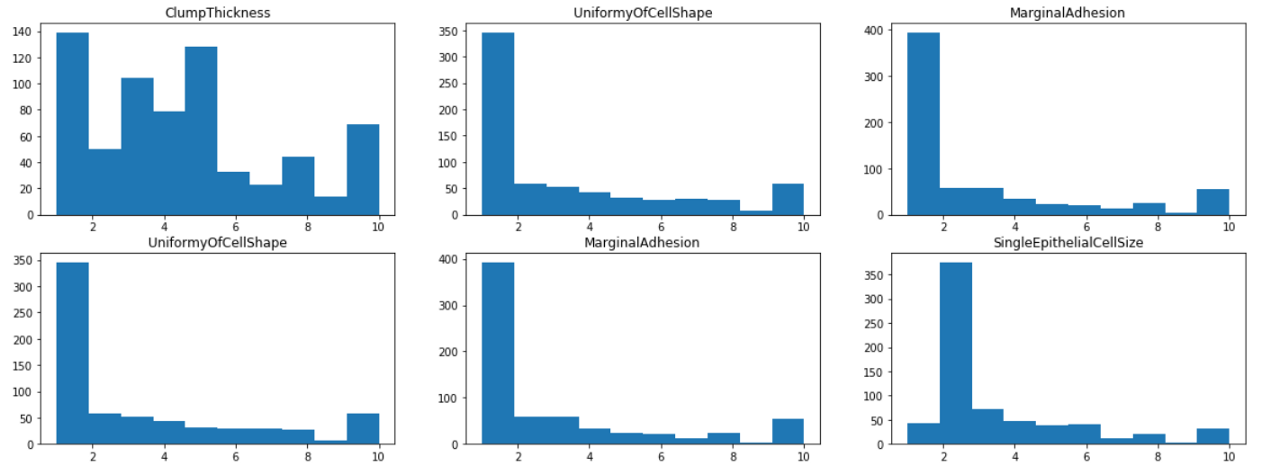
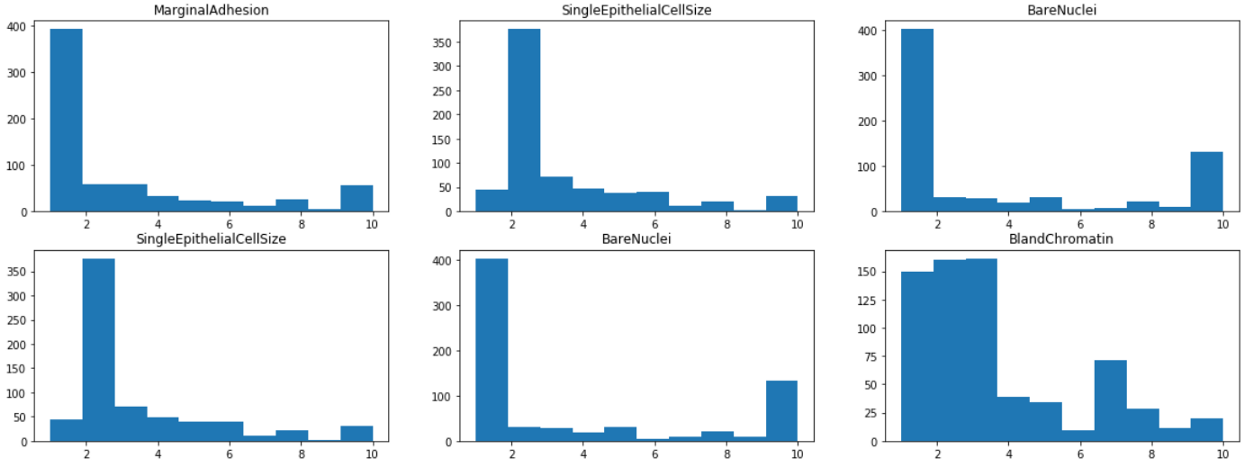
通過可視化每個特征的直方圖,我們發現大多數特征都有1或2的模式,除了塊狀和淡色質,其分布在1到10之間更為均勻,這表明團厚和乏味的染色質可能是該類的較弱的預測因子,
from matplotlib import pyplot as plt
fig, axes = plt.subplots(4,3, figsize=(20,15))
for i in range(0,4):
for j in range(0,3):
axes[i,j].hist(df.iloc[:,1+i+j])
axes[i,j].set_title(df.iloc[:,1+i+j].name)
模型訓練和測驗
然后,將資料集按80%-10%-10%的比例分成典型的訓練驗證測驗集,利用Sklearn建立K-近鄰模型,經過一些超引數調整(未顯示),發現k=10的模型在評估階段表現良好-它的F1分數為0.9655,代碼塊如下所示,
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
# 訓練測驗拆分
X_traincv, X_test, y_traincv, y_test = train_test_split(data, target, test_size=0.1, random_state=42)
# K-折疊驗證
kf = KFold(n_splits=5, random_state=42, shuffle=True)
for train_index, test_index in kf.split(X_traincv):
X_train, X_cv = X_traincv.iloc[train_index], X_traincv.iloc[test_index]
y_train, y_cv = y_traincv.iloc[train_index], y_traincv.iloc[test_index]
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import f1_score,
# 訓練KNN模型
KNN = KNeighborsClassifier(k=10)
KNN.fit(X_train, y_train)
# 評估KNN模型
score = f1_score(y_testset, y_pred, average="binary", pos_label = 4)
print ("{} => F1-Score is {}" .format(text, round(score,4)))
使用LIME的模型解釋
一個Kaggle行家可能會說這個結果很好,我們可以在這里完成這個專案,然而,人們應該對模型的決策持懷疑態度,即使模型在評估中表現良好,因此,我們使用LIME來解釋KNN模型對這個資料集所做的決策,這通過檢查決策是否符合我們的直覺來驗證模型的有效性,
import lime
import lime.lime_tabular
# LIME準備
predict_fn_rf = lambda x: KNN.predict_proba(x).astype(float)
# 創建一個LIME解釋器
X = X_test.values
explainer = lime.lime_tabular.LimeTabularExplainer(X,feature_names =X_test.columns, class_names = ['benign','malignant'], kernel_width = 5)
# 選擇要解釋的資料點
chosen_index = X_test.index[j]
chosen_instance = X_test.loc[chosen_index].values
# 使用LIME解釋器解釋資料點
exp = explainer.explain_instance(chosen_instance, predict_fn_rf, num_features = 10)
exp.show_in_notebook(show_all=False)
在這里,我選擇了3點來說明LIME是如何使用的,
解釋為什么樣本被預測為惡性

這里,我們有一個資料點,實際上是惡性的,并且被預測為惡性,在左邊的面板上,我們看到KNN模型預測這一點有接近100%的概率是惡性的,在中間,我們觀察到LIME能夠使用資料點的每一個特征,按照重要性的順序來解釋這種預測,根據LIME的說法,
-
事實上,樣本對于裸核的值大于6.0,這使得它更有可能是惡性的,
-
由于樣本有很高的邊緣粘附性,它更可能是惡性的而不是良性的,
-
由于樣本的團塊厚度大于4,它更有可能是惡性的,
-
另一方面,樣本的有絲分裂值≤1.00這一事實使其更有可能是良性的,
總的來說,考慮到樣本的所有特征(在右邊的面板上),樣本被預測為惡性,
這四個觀察符合我們對癌細胞的直覺和認識,知道了這一點,我們更相信模型是根據我們的直覺做出正確的預測,讓我們看看另一個例子,
解釋為什么預測樣本是良性的

在這里,我們有一個細胞樣本,預測是良性的,實際上是良性的,LIME通過參考(除其他原因外)解釋了為什么會出現這種情況
-
該樣品的裸核值≤1
-
該樣品的核仁正常值≤1
-
它的團厚度也≤1
-
細胞形狀的均勻性也≤1
同樣,這些符合我們對為什么細胞是良性的直覺,
解釋樣本預測不清楚的原因
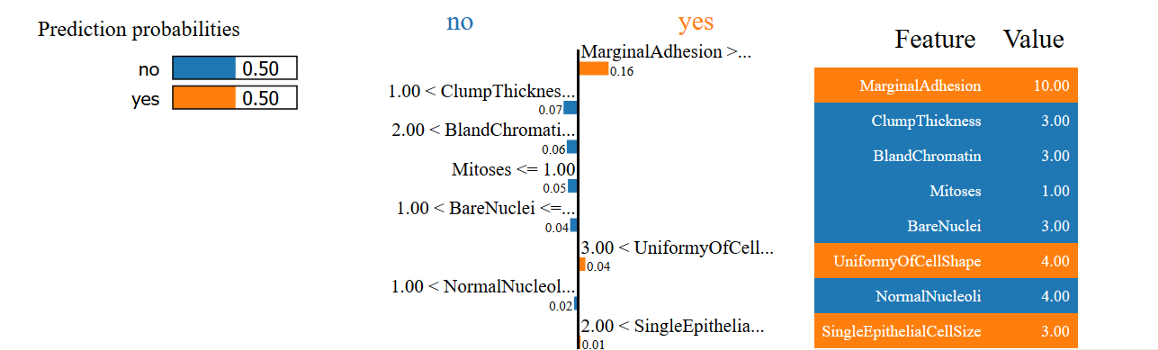
在最后一個例子中,我們看到這個模型無法很好地預測細胞是良性還是惡性,你能用LIME的解釋明白為什么會這樣嗎?
結論
LIME的有用性從表格資料擴展到文本和影像,使其具有難以置信的通用性,然而,仍有作業要做,例如,本文作者認為,當前的演算法在應用于影像時速度太慢,無法發揮作用,
盡管如此,在彌補黑盒模型的有用性和難處理性之間的差距方面,LIME仍然是非常有用的,如果你想開始使用LIME,一個很好的起點就是LIME的Github頁面,
參考參考
[1] Codari, M., Melazzini, L., Morozov, S.P. et al., Impact of artificial intelligence on radiology: a EuroAIM survey among members of the European Society of Radiology (2019), Insights into Imaging
[2] M. Ribeiro, S. Singh and C. Guestrin, ‘Why Should I Trust You?’ Explining the Predictions of Any Clasifier (2016), KDD
[3] Dr. William H. Wolberg, Wisconsin Breast Cancer Database (1991), University of Wisconsin Hospitals, Madison
原文鏈接:https://towardsdatascience.com/interpreting-black-box-ml-models-using-lime-4fa439be9885
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/202802.html
標籤:其他