Dataset:機器學習和深度學習中對資料集進行高級繪圖(資料集可視化,箱線圖等)的簡介、應用之詳細攻略——daidingdaiding
目錄
箱線圖
箱線圖
箱線圖(box plots):這些圖顯示了一個小長方形,有一個紅線穿過它,紅線代表此列資料的中位數(第50 百分位數),長方形的頂和底分別表示第25 百分位數和第75 百分位數(或者第一四分位數、第三四分位數),
箱線圖又叫為盒須圖(box and whisker plots),在盒子的上方和下方有小的水平線,叫作盒須(whisker),它們分別據盒子的上邊和下邊是四分位間距的1.4 倍,四分位間距就是第75 百分位數和第25 百分位數之間的距離,也就是從盒子的頂邊到盒子底邊的距離,也就是說盒子上面的盒須到盒子頂邊的距離是盒子高度的1.4 倍,這個盒須的1.4 倍距離是可以調整的,詳見箱線圖
的相關檔案,
在有些情況下,盒須要比1.4 倍距離近,這說明資料的值并沒有擴散到原定計算出來的盒須的位置,在這種情況下,盒須被放在最極端的點上,在另外一些情況下,資料擴散到遠遠超出計算出的盒須的位置(1.4 倍盒子高度的距離),這些點被認為是例外點,
箱線圖的目的:一種比列印出資料更快、更直接的發現例外點的方法,但是最后一個環數屬性(最右邊的盒子)的取值范圍導致其他屬性都被“壓縮”了(導致很難看清楚),T1、一種簡單的解決方法就是把取值范圍最大的那個屬性洗掉,
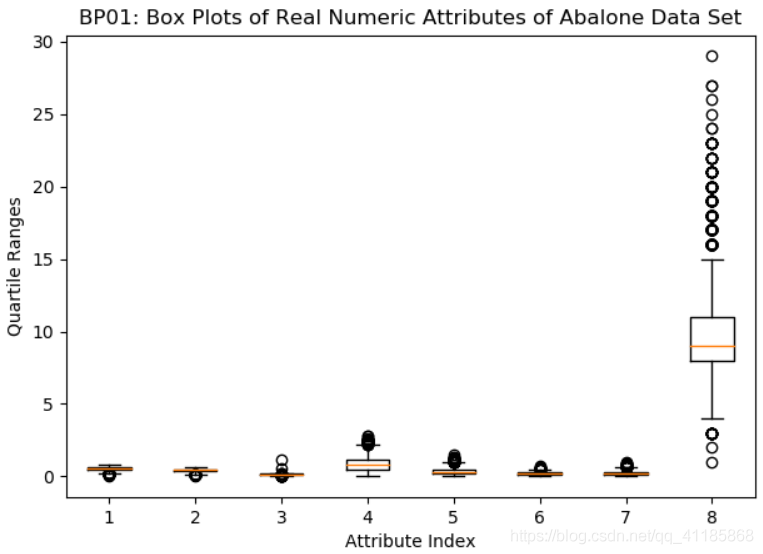

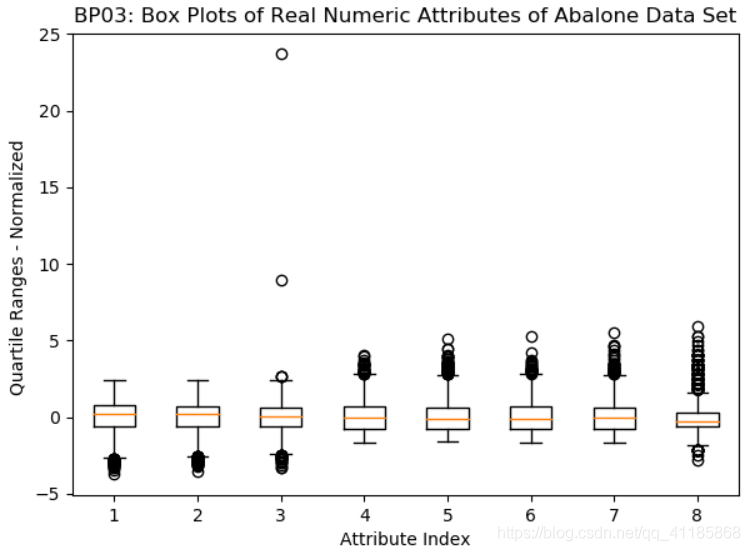
T2、畫箱線圖之前采用將屬性值歸一化:因為沒有實作根據取值范圍自動縮放(自適應),在畫箱線圖之前將屬性值歸一化(normalization),此處的歸一化指確定每列資料的中心,然后對數值進行縮放,使屬性1 的一個單位值與屬性2 的一個單位值相同,在資料科學中有相當數量的演算法需要這種歸一化,例如,K-means聚類方法是根據行資料之間的向量距離來進行聚類的,距離是對應坐標上的點相減然后取平方和,單位不同,算出來的距離也會不同,到一個雜貨店的距離以英里為單位是1 英里,以英尺為單位就是5 280 英尺,代碼清單2-11 中的歸一化是把屬性數值都轉換為均值為0、標準差為1 的分布,這是最通用的歸一化,歸一化計算用到了函式summary() 的結果,歸一化后的效果如圖2-11 所示,
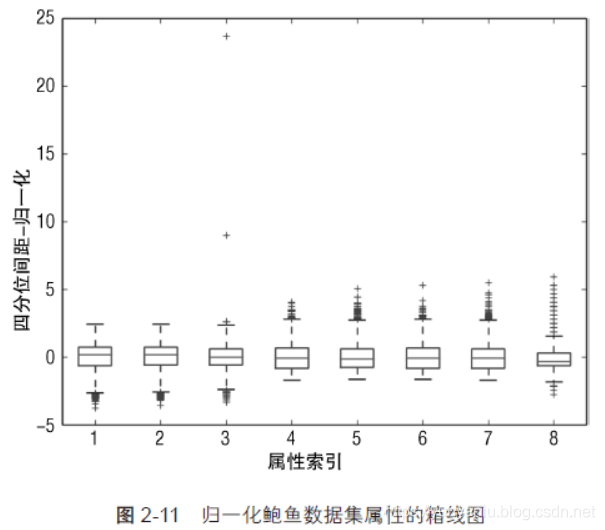
注意歸一化到標準差1.0 并不意味著所有的資料都在?1.0 和+1.0 之間,盒子的頂邊和底邊多少都會在?1.0 和+1.0 附近,但是還有很多資料在這個邊界外,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/20301.html
標籤:其他