1. Java并發類:
1、ConcurrentHashMap
ConcurrentHashMap其實就是執行緒安全版本的hashMap,前面我們知道HashMap是以鏈表的形式存放hash沖突的資料,以陣列形式存放HashEntry等hash出來不一致的資料,為了保證容器的資料一致性,需要加鎖,HashMap的實作方式是,只有put和remove的時候會引發資料的不一致,那為了保證資料的一致性,我在put和remove的時候進行加鎖操作,但是隨之而來的是性能問題,因為key-value形式的資料,讀寫頻繁是很正常的,也就意味著我有大量資料做讀寫操作時會引發長時間的等待,為了解決這個問題,Java并發包問我們提供了新的思路,在每一個HashEntry上加一把鎖,對于hash沖突的資料,因為采用鏈表存盤,公用一把鎖,這樣我才在做不同hash數值的資料時,則是在不同的鎖環境下執行,基本上是互不干擾的,在最好情況下,可以保證16個執行緒同時進行無阻塞的操作(HashMap的默認HashEntry是16,亦即默認的陣列大小是16),
那ConcurrentHashMap是如何保證資料操作的一致性呢?對于資料元素的大小,ConcurrentHashMap將對應陣列(HashEntry的長度)的變數為voliate型別的,也就是任何HashEntry發生變更,所有的地方都會知道資料的大小,對于元素,如何保證我取出的元素的next不發生變更呢?(HashEntry中的資料采用鏈表存盤,當讀取資料的時候可能又發生了變更),這一點,ConcurrentHashMap采取了最簡單的做法,hash值、key和next取出后都為final型別的,其next等資料永遠不會發生變更,
另外ConcurrentHashMap采用的鎖結構是將讀和寫分開的,大大的提升了性能,
2.CopyOnWriteArrayList
CopyOnWriteArrayList是執行緒安全版本的ArrayList,和ArrayList不同的是,CopyOnWriteArrayList默認是創建了一個大小為0的容器,通過ReentrantLock來保證執行緒安全,CopyOnWriteArrayList其實每次增加的時候,需要新創建一個比原來容量+1大小的陣列,然后拷貝原來的元素到新的陣列中,同時將新插入的元素放在最末端,然后切換參考,
針對CopyOnWriteArrayList,因為每次做插入和洗掉操作,都需要重新開辟空間和復制陣列元素,因此對于插入和洗掉元素,CopyOnWriteArrayList的性能遠遠不如ArrayList,但是每次讀取的時候,CopyOnWriteArrayList在不加鎖的情況下直接鎖定資料,會快很多(但是可能會引發臟讀:臟讀又稱無效資料的讀出,是指在資料庫訪問中,事務T1將某一值修改,然后事務T2讀取該值,此后T1因為某種原因撤銷對該值的修改,這就導致了T2所讀取到的資料是無效的,值得注意的是,臟讀一般是針對于update操作的,),對于迭代,CopyOnWriteArrayList會生成一個快照陣列,因此當迭代程序中出現變化,快照資料沒有變更,因此讀到的資料也是不會變化的,在讀多寫少的環境下,CopyOnWriteArrayList的性能還是不錯的,
2.Spring的IOC以及AOP.
IOC(DI):把物件的創建權限交給Spring容器,讓spring幫我們實體化物件,我們只是從spring容器中取得實體,
AOP:把一些非核心業務的代碼抽取到一個通知類(增強),再創建需要被增強的類的代理物件,在呼叫代理物件的方法時,織入增強代碼,并呼叫目標方法的一種面向切面技術,一種對OOP進行補充的編程方式,
3.Spring的Bean的加載程序.
Spring通過資源加載器加載相應的XML檔案,使用讀取器讀取資源加載器中的檔案到讀取器中,在讀取程序中,決議相應的xml檔案元素,轉化為spring定義的資料結BeanDefinition,把相應的BeanDefinition注冊到注冊表中,注冊表中包含的BeanDefinition的資料結構,沒有經過加工處理過,無法得到我們想要的bean物件,
我們如何得到Bean物件,spring都做了那些作業?BeanFactory提供了多種方式得到bean物件,getBean()方法是最核心得到bean物件
getBean主要由AbstractBeanFactory、AbstractAutowireCapableBeanFactory、以及DefaultListableBeanFactory實作
AbstractBeanFactory 實作了依賴關系處理
AbstractAutowireCapableBeanFactory 實作了bean的create程序
DefaultListableBeanFactory 實作了BeanDefinition的管理
以下是getBean方法的實作流程,
getBean經過方法多載后,最終呼叫的是doGetBean方法,
需要的方法引數如下:
1.name 你要得到bean物件的名稱 不能為空
2.requiredType 這個bean物件的Class型別,可以為null
3.args 可以為null,如果有引數,則代表在找到這個bean定義后,通過構造方法或工廠方法或其他方法傳入args引數來改變這個bean實體,
spring 工廠開始自動化處理了.
4. Spring的回圈依賴處理方式.
所謂Spring的回圈依賴,指的是這樣一種場景:
當我們注入一個物件A時,需要注入物件A中標記了某些注解的屬性,這些屬性也就是物件A的依賴,把物件A中的依賴都初始化完成,物件A才算是創建成功,那么,如果物件A中有個屬性是物件B,而且物件B中有個屬性是物件A,那么物件A和物件B就算是回圈依賴,如果不加處理,就會出現:創建物件A–>處理A的依賴B–>創建物件B–>處理B的物件A–>創建物件A–>處理A的依賴B–>創建物件B…這樣無限的回圈下去,
這事顯然不靠譜,
Spring處理回圈依賴的基本思路是這樣的:
雖說要初始化一個Bean,必須要注入Bean里的依賴,才算初始化成功,但并不要求此時依賴的依賴也都注入成功,只要依賴物件的構造方法執行完了,這個依賴物件就算存在了,注入就算成功了,至于依賴的依賴,以后再初始化也來得及(參考Java的記憶體模型),
因此,我們初始化一個Bean時,先呼叫Bean的構造方法,這個物件就在記憶體中存在了(物件里面的依賴還沒有被注入),然后把這個物件保存下來,當回圈依賴產生時,直接拿到之前保存的物件,于是回圈依賴就被終止了,依賴注入也就順利完成了,
舉個例子:
假設物件A中有屬性是物件B,物件B中也有屬性是物件A,即A和B回圈依賴,
創建物件A,呼叫A的構造,并把A保存下來,
然后準備注入物件A中的依賴,發現物件A依賴物件B,那么開始創建物件B,
呼叫B的構造,并把B保存下來,
然后準備注入B的構造,發現B依賴物件A,物件A之前已經創建了,直接獲取A并把A注入B(注意此時的物件A還沒有完全注入成功,物件A中的物件B還沒有注入),于是B創建成功,
把創建成功的B注入A,于是A也創建成功了,
于是回圈依賴就被解決了,
5.快取穿透與快取擊穿問題
5.1快取穿透(資料查詢不到—>假資料、set集合放ID布隆過濾器過濾)
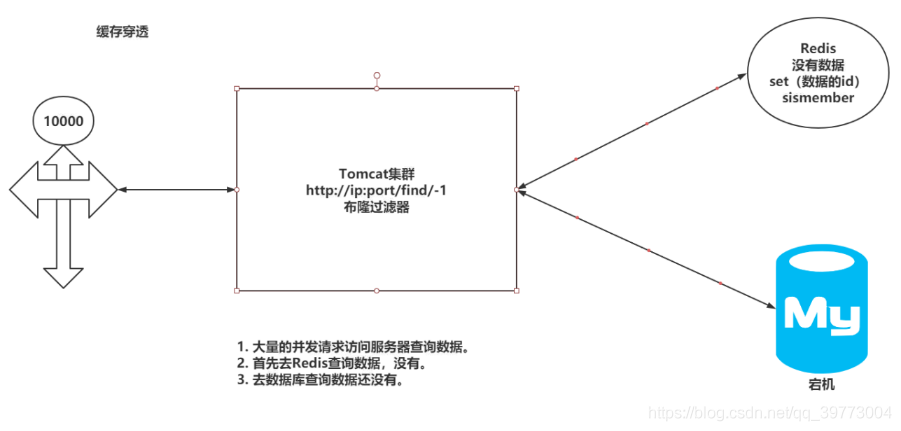
解決方案(防止mysql宕機)
在Redis中放入
1.假資料
2.set集合,里面放入所有mysql中的id,再通過布隆過濾器過濾,沒有這個id的請求就不在mysql中找了
5.2、快取擊穿(熱點資料到期—>訪問一次加一次訪問時間、加鎖)
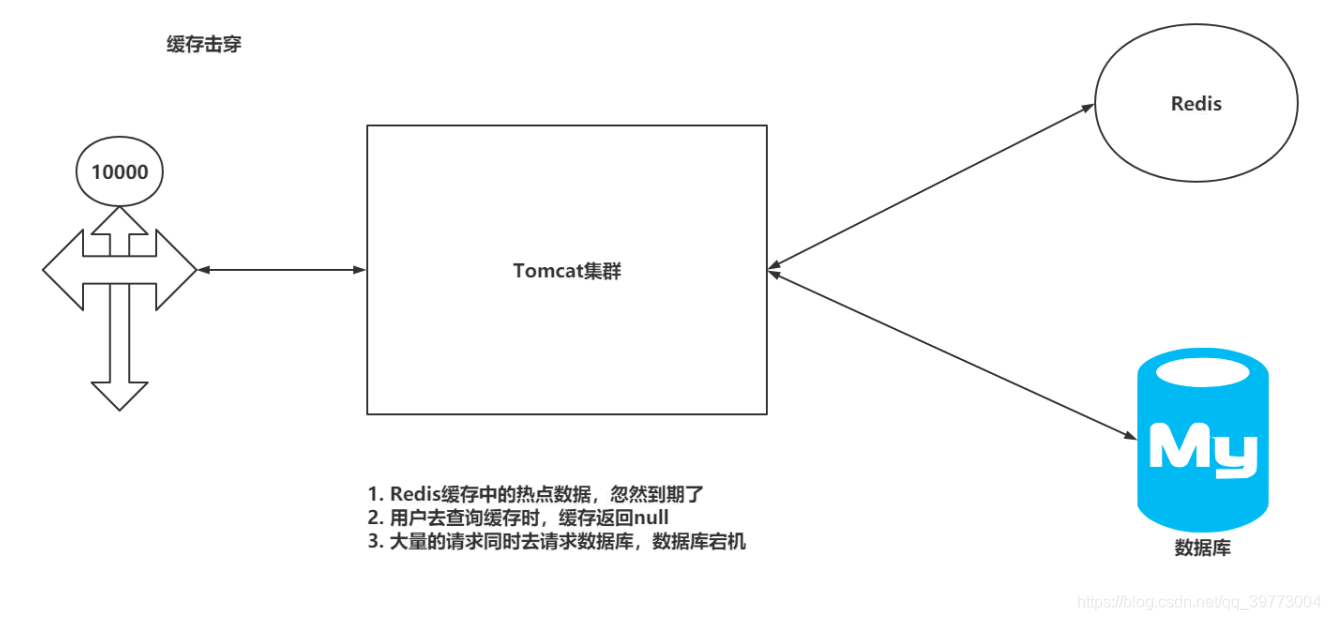
解決方案
1.從Redis處理:一個請求,給這個熱點資料加一點時間(避免熱點資料過期)
2.分布式鎖:Tomcat集群synchronized-Tomcat分布式鎖-Redis(避免大量資料訪問資料庫)
6、MySql存盤引擎
資料庫存盤引擎是資料庫底層軟體組織,資料庫管理系統(DBMS)使用資料引擎進行創建、查詢、更新和洗掉資料,不同的存盤引擎提供不同的存盤機制、索引技巧、鎖定水平等功能,使用不同的存盤引擎,還可以獲得特定的功能,現在許多不同的資料庫管理系統都支持多種不同的資料引擎,
因為在關系資料庫中資料的存盤是以表的形式存盤的,所以存盤引擎也可以稱為表型別(Table Type,即存盤和操作此表的型別),
InnoDB存盤引擎
InnoDB是事務型資料庫的首選引擎,通過上圖也看到了,InnoDB是目前MYSQL的默認事務型引擎,是目前最重要、使用最廣泛的存盤引擎,支持事務安全表(ACID),支持行鎖定和外鍵,InnoDB主要特性有:
1、InnoDB給MySQL提供了具有提交、回滾和崩潰恢復能力的事物安全(ACID兼容)存盤引擎,InnoDB鎖定在行級并且也在SELECT陳述句中提供一個類似Oracle的非鎖定讀,這些功能增加了多用戶部署和性能,在SQL查詢中,可以自由地將InnoDB型別的表和其他MySQL的表型別混合起來,甚至在同一個查詢中也可以混合
2、InnoDB是為處理巨大資料量的最大性能設計,它的CPU效率可能是任何其他基于磁盤的關系型資料庫引擎鎖不能匹敵的
3、InnoDB存盤引擎完全與MySQL服務器整合,InnoDB存盤引擎為在主記憶體中快取資料和索引而維持它自己的緩沖池,InnoDB將它的表和索引在一個邏輯表空間中,表空間可以包含數個檔案(或原始磁盤檔案),這與MyISAM表不同,比如在MyISAM表中每個表被存放在分離的檔案中,InnoDB表可以是任何尺寸,即使在檔案尺寸被限制為2GB的作業系統上
4、InnoDB支持外鍵完整性約束,存盤表中的資料時,每張表的存盤都按主鍵順序存放,如果沒有顯示在表定義時指定主鍵,InnoDB會為每一行生成一個6位元組的ROWID,并以此作為主鍵
5、InnoDB被用在眾多需要高性能的大型資料庫站點上
InnoDB不創建目錄,使用InnoDB時,MySQL將在MySQL資料目錄下創建一個名為ibdata1的10MB大小的自動擴展資料檔案,以及兩個名為ib_logfile0和ib_logfile1的5MB大小的日志檔案,
場景:由于其支持事務處理,支持外鍵,支持崩潰修復能力和并發控制,如果需要對事務的完整性要求比較高(比如銀行),要求實作并發控制(比如售票),那選擇InnoDB有很大的優勢,如果需要頻繁的更新、洗掉操作的資料庫,也可以選擇InnoDB,因為支持事務的提交(commit)和回滾(rollback),
MyISAM存盤引擎
MyISAM基于ISAM存盤引擎,并對其進行擴展,它是在Web、資料倉儲和其他應用環境下最常使用的存盤引擎之一,MyISAM擁有較高的插入、查詢速度,但不支持事物和外鍵,
MyISAM主要特性有:
1、大檔案(達到63位檔案長度)在支持大檔案的檔案系統和作業系統上被支持
2、當把洗掉和更新及插入操作混合使用的時候,動態尺寸的行產生更少碎片,這要通過合并相鄰被洗掉的塊,以及若下一個塊被洗掉,就擴展到下一塊自動完成
3、每個MyISAM表最大索引數是64,這可以通過重新編譯來改變,每個索引最大的列數是16
4、最大的鍵長度是1000位元組,這也可以通過編譯來改變,對于鍵長度超過250位元組的情況,一個超過1024位元組的鍵將被用上
5、BLOB和TEXT列可以被索引,支持FULLTEXT型別的索引,而InnoDB不支持這種型別的索引
6、NULL被允許在索引的列中,這個值占每個鍵的0~1個位元組
7、所有數字鍵值以高位元組優先被存盤以允許一個更高的索引壓縮
8、每個MyISAM型別的表都有一個AUTO_INCREMENT的內部列,當INSERT和UPDATE操作的時候該列被更新,同時AUTO_INCREMENT列將被重繪,所以說,MyISAM型別表的AUTO_INCREMENT列更新比InnoDB型別的AUTO_INCREMENT更快
9、可以把資料檔案和索引檔案放在不同目錄
10、每個字符列可以有不同的字符集
11、有VARCHAR的表可以固定或動態記錄長度
12、VARCHAR和CHAR列可以多達64KB
存盤格式:
1、靜態表(默認):欄位都是非變長的(每個記錄都是固定長度的),存盤非常迅速、容易快取,出現故障容易恢復;占用空間通常比動態表多,
2、動態表:占用的空間相對較少,但是頻繁的更新洗掉記錄會產生碎片,需要定期執行optimize table或myisamchk -r命令來改善性能,而且出現故障的時候恢復比較困難,
3、壓縮表:使用myisampack工具創建,占用非常小的磁盤空間,因為每個記錄是被單獨壓縮的,所以只有非常小的訪問開支,
靜態表的資料在存盤的時候會按照列的寬度定義補足空格,在回傳資料給應用之前去掉這些空格,如果需要保存的內容后面本來就有空格,在回傳結果的時候也會被去掉,(其實是資料型別char的行為,動態表中若有這個資料型別也同樣會有這個問題)
使用MyISAM引擎創建資料庫,將產生3個檔案,檔案的名字以表名字開始,擴展名之處檔案型別:frm檔案存盤表定義、資料檔案的擴展名為.MYD(MYData)、索引檔案的擴展名時.MYI(MYIndex),
場景:如果表主要是用于插入新記錄和讀出記錄,那么選擇MyISAM能實作處理高效率,
MERGE存盤引擎
MERGE存盤引擎是一組MyISAM表的組合,這些MyISAM表結構必須完全相同,盡管其使用不如其它引擎突出,但是在某些情況下非常有用,
7.Mybatis的一級快取和二級快取的區別?
一級快取(默認開啟)
SqlSession級別的快取,實作在同一個會話中資料的共享.
基于sqlSession默認開啟,在操作資料庫時需要構造SqlSession物件,在物件中有一個HashMap用于存盤快取資料,不同的SqlSession之間的快取資料區域是互相不影響的,
二級快取
SqlSessionFactory級別的快取,實作不同會話中資料的共享,是一個全域變數,
不同的sqlSession兩次執行相同的namespace下的sql陳述句,且向sql中傳遞的引數也相同,即最終執行相同的sql陳述句,則第一次執行完畢會將資料庫中查詢的資料寫到快取,第二次查詢會從快取中獲取資料,不再去底層資料庫查詢,從而提高效率,
8.HashMap
HashMap剛創建時,table是null,為了節省空間,當添加第一個元素時,table容量 調整為16,當元素個數大于閾值(16*0.75=12)時,會進行擴容,擴容后大小為原來的2倍,目的是 減少調整元素的個數,jdk1.8 當每個鏈表長度大于8,并且陣列元素個數大于等于64時,會調整為紅黑樹,目 的提高執行效率,jdk1.8 當鏈表長度小于等于6時,調整成鏈表,jdk1.8以前,鏈表是頭插入,jdk1.8以后是尾插入
HashMap的安全問題
jdk1.7及之前的HashMap
在HashMap擴容的是時候會呼叫resize()方法中的transfer()方法,在這里由于是頭插法所以在多執行緒情況下可能出現回圈鏈表,所以后面的資料定位到這條鏈表的時候會造成資料丟失,和讀取的可能導致死回圈,
jdk1.8HashMap
1.8的HashMap對此做了優化,resize采用了尾插法,即不改變原來鏈表的順序,所以不會出現1.7的回圈鏈表的問題,但是它也不是執行緒執行緒安全的,不安全性如下:
在多執行緒情況下put時計算出的插入的陣列下標可能是相同的,這時可能出現值的覆寫從而導致size也是不準確的,
9. final , finally , finalize區別
final修飾成員變數,成員方法,類
finally修飾代碼塊
finalize是Object類中的一個方法 -> 復活幣 × 1
10.static關鍵字修飾什么
內部類
方法
變數
代碼塊
導包
11.volatile關鍵字
1.被volatile修飾的變數保證對所有執行緒可見,
2.禁止指令重排優化
12.CAS樂觀鎖(比較和交換)
CAS介紹(compare and swap比較和交換):
CAS是項樂觀鎖技術,當多個執行緒嘗試使用CAS同時更新同一個變數時,只有其中一個執行緒能更新變數的值,而其它執行緒都失敗,失敗的執行緒并不會被掛起,而是被告知這次競爭中失敗,并可以再次嘗試,CAS是一種非阻塞式的同步方式,
CAS 有效地說明了“我認為位置 V 應該包含值 A;如果包含該值,則將 B 放到這個位置;否則,不要更改該位置,只告訴我這個位置現在的值即可,
CAS導致ABA問題:添加版本
執行緒1準備用CAS將變數的值由A替換為B,在此之前,執行緒2將變數的值由A替換為C,又由C替換為A,然后執行緒1執行CAS時發現變數的值仍然為A,所以CAS成功,但實際上這時的現場已經和最初不同了,盡管CAS成功,但可能存在潛藏的問題,如果CAS次數過多,會額外損耗CPU性能
解決ABA問題:增加版本號
13.GC的垃圾回收
1.JVM記憶體分代模型
年輕代和老年代
JVM將堆記憶體劃分為了兩個區域,即年輕代和老年代,年輕代主要存放的是創建和使用完即將被回收的物件,老年代存放的是一些長期被使用的物件,
2.確定是否回收
1、參考計數演算法
判斷物件的參考數量
通過判斷物件的參考數量來決定物件是否可以被回收;
每個物件實體都有一個參考計數器,被參考則+1,完成參考則-1;
任何參考計數為0的物件實體可以被當作垃圾收集,
優點:執行效率高,程式執行受影響較小,
缺點:無發檢測出回圈參考的情況,導致記憶體泄露,
2.可達性分析演算法
有一系列名為GC Roots的物件作為起始點,從這些節點開始向下搜索,搜索所走過的路徑被稱
為“參考鏈”,
如果一個物件到GC Roots沒有任何參考鏈相連接時,說明這個物件是不可用的,如果一個物件
到GC Roots有參考鏈相連接時,說明這個物件是可用的,
也就是說,給定一個集合的參考作為根節點出發,通過參考關系遍歷物件圖,能夠遍歷到的物件
就被判定為存活,不能夠被遍歷到的物件說明物件死亡,
3.常用垃圾演算法
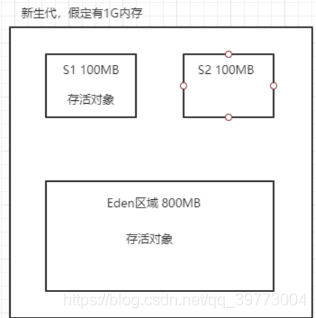
1.復制演算法(新生代回收演算法)
復制演算法主要運用在新生代中,把新生代記憶體劃分為兩塊記憶體區域,然后只使用其中一塊,待
那塊記憶體快滿的時候,就把里面的存活物件一次性轉移到另外一塊記憶體區域,然后回收原來那
塊的垃圾物件,
整個垃圾回收的流程就是,剛開始創建的物件都是在Eden區域的,如果Eden區域快滿了,就會
觸發垃圾回收,Eden區把存活的物件都轉移到空著的S1區域,接著Eden區就會被請客,然后再
次分配物件到Eden區中直到滿了進行下一次垃圾回收,這時會將S1中存活的物件和Eden區存活
的物件轉移到空的Survivor區中(S2) ,這就是為什么新生代會被劃分為8:1:1的結構了,
這樣對記憶體的利用率會大大提升,
2.標記清除法
標記-清除演算法采用從根集合(GC Roots)進行掃描,對存活的物件進行標記,標記完畢后,
再掃描整個空間中未被標記的物件,進行回收,如下圖所示,標記-清除演算法不需要進行對
象的移動,只需對不存活的物件進行處理,在存活物件比較多的情況下極為高效,但由于標
記-清除演算法直接回收不存活的物件,因此會造成記憶體碎片,
3.標記整理演算法(老年代回收演算法)
標記-整理演算法采用標記-清除演算法一樣的方式進行物件的標記,但在清除時不同,在回收不存活
的物件占用的空間后,會將所有的存活物件往左端空閑空間移動,并更新對應的指標,標記-整
理演算法是在標記-清除演算法的基礎上,又進行了物件的移動,因此成本更高,但是卻解決了記憶體
碎片的問題,
15.class檔案是如何加載到JVM記憶體的
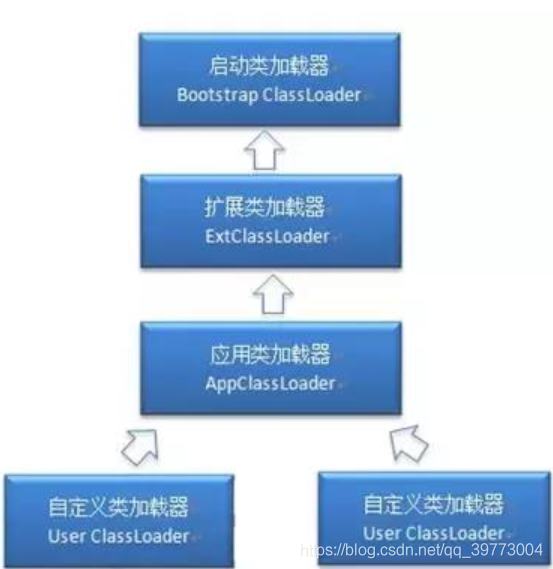
各個加載器的作業責任:
1)Bootstrap ClassLoader:負責加載$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++實作,不是ClassLoader子類
2)Extension ClassLoader:負責加載java平臺中擴展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目錄下的jar包
3)App ClassLoader:負責記載classpath中指定的jar包及目錄中class
作業程序:
1、當AppClassLoader加載一個class時,它首先不會自己去嘗試加載這個類,而是把類加載
請求委派給父類加載器ExtClassLoader去完成,
2、當ExtClassLoader加載一個class時,它首先也不會自己去嘗試加載這個類,而是把類加
載請求委派給BootStrapClassLoader去完成,
3、如果BootStrapClassLoader加載失敗(例如在$JAVA_HOME/jre/lib里未查找到該class)
,會使用ExtClassLoader來嘗試加載;
4、若ExtClassLoader也加載失敗,則會使用AppClassLoader來加載
5、如果AppClassLoader也加載失敗,則會報出例外ClassNotFoundException
這就是所謂的雙親委派模型,簡單來說:如果一個類加載器收到了類加載的請求,它首先不會自己去嘗試加載這個類,而是把請求委托給父加載器去完成,依次向上,
好處:防止記憶體中出現多份同樣的位元組碼(安全性角度)
特別說明:類加載器在成功加載某個類之后,會把得到的 java.lang.Class類的實體快取起來,下次再請求加載該類的時候,類加載器會直接使用快取的類的實體,而不會嘗試再次加載,
類加載詳細程序
加載,查找并加載類的二進制資料,在Java堆中也創建一個java.lang.Class類的物件,
連接,連接又包含三塊內容:驗證、準備、決議,
1)驗證,檔案格式、元資料、位元組碼、符號參考驗證;
2)準備,為類的靜態變數分配記憶體,并將其初始化為默認值;
3)決議,把類中的符號參考轉換為直接參考
初始化,為類的靜態變數賦予正確的初始值,
16.JVM記憶體模型(待完善)
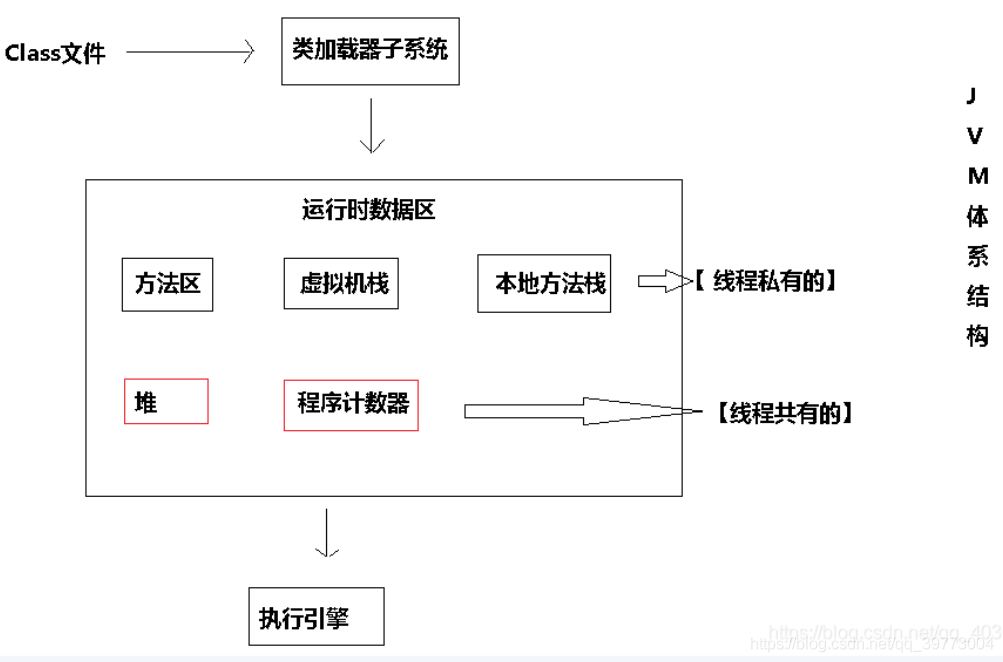
1.程式計數器(PC暫存器):
程式計數器是一塊較小的記憶體空間,是當前執行緒正在執行的哪一條位元組碼指令的地址,若當前
執行緒正在執行的是一個本地方法
2.Java虛擬機堆疊(待完善)
描述Java方法運行程序的記憶體模型,保存區域變數、基本資料型別以及堆記憶體中物件的參考變數
隨著執行緒創建而創建,隨著執行緒的結束而銷毀
3.本地方法堆疊
為JVM提供使用native方法的服務,本地方法堆疊描述本地方法運行程序的記憶體模型
也會拋出StackOverFlowError和OutOfMemoryError例外
4.堆
執行緒共享、垃圾回收的主要場地,在虛擬機啟動的時候就被創建
堆這塊區域是JVM中最大的,堆記憶體的大小是可以調節的
5.方法區
執行緒共享、 存盤的是類資訊+普通常量+靜態常量+編譯器編譯后的代碼等,
常量池(Constant Pool)是方法區的一部分
16.1虛擬機堆疊如何執行方法的

16.2方法區在JDK各個版本的更新

17.SQL陳述句的優化
sql本身優化,避免全盤掃描
18.聚簇索引和非聚簇索引
主鍵索引:
其他索引:
19.索引的常見結構
hash:資料量不大,效率遠高于BTree
BTree,B+Tree:資料量大,更加穩定
樹高問題,葉子節點指標
20.ES保存資料后,為什么不能立即查看到
我們經常有這樣的需求,在對 Elasticsearch 資料進行操作的時候,要及時回傳剛剛操作完畢的資料,或者資料串列,
比如加入存盤一條資料后,我馬上要回傳資料的總條數,這個時候,會出問題,Elasticsearch會回傳操作之前的資料,也就是假如開始有500條資料,我Insert了一條進去,按道理來說應該是501條,但是這個時候查詢會發現,只有500條資料,再次請求又得到501條資料,
BulkRequestBuilder bulkRequest = ESTools.client.prepareBulk().setRefresh(true);
這里的setRefresh(true);
就是自動重繪的用處,所以在我們CRUD的時候,如果對資料增刪改操作的時候,如果要及時回傳最新資料,那么我們就需要加這個方法,及時重繪資料,
21.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/203638.html
標籤:其他
下一篇:can only accept this command while in the powered on state(iOS藍牙 打開app后的第一次掃描要掃描兩次)