背景
大資料發展至今,按照 Google 2003年發布的《The Google File System》第一篇論文算起,已走過17個年頭,可惜的是 Google 當時并沒有開源其技術,“僅僅”是發表了三篇技術論文,所以回頭看,只能算是揭開了大資料時代的帷幕,隨著 Hadoop 的誕生,大資料進入了高速發展的時代,大資料的紅利及商業價值也不斷被釋放,現今大資料存盤和處理需求越來越多樣化,在后 Hadoop 時代,如何構建一個統一的資料湖存盤,并在其上進行多種形式的資料分析,成了企業構建大資料生態的一個重要方向,怎樣快速、一致、原子性地在資料湖存盤上構建起 Data Pipeline,成了亟待解決的問題,并且伴隨云原生時代到來,云原生天生具有的自動化部署和交付能力也正催化這一程序,本文就主要介紹如何利用 Iceberg 與 Kubernetes 打造新一代云原生資料湖,
何為 Iceberg
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.
Apache Iceberg 是由 Netflix 開發開源的,其于2018年11月16日進入 Apache 范訓器,是 Netflix 公司資料倉庫基礎,Iceberg 本質上是一種專為海量分析設計的表格式標準,可為主流計算引擎如 Presto、Spark 等提供高性能的讀寫和元資料管理能力,Iceberg 不關注底層存盤(如 HDFS)與表結構(業務定義),它為兩者之間提供了一個抽象層,將資料與元資料組織了起來,
Iceberg 主要特性包括:
- ACID:具備 ACID 能力,支持 row level update/delete;支持 serializable isolation 與 multiple concurrent writers
- Table Evolution:支持 inplace table evolution(schema & partition),可像 SQL 一樣操作 table schema;支持 hidden partitioning,用戶無需顯示指定
- 介面通用化:為上層資料處理引擎提供豐富的表操作介面;屏蔽底層資料存盤格式差異,提供對 Parquet、ORC 和 Avro 格式支持
依賴以上特性,Iceberg 可幫助用戶低成本的實作 T+0 級資料湖,
Iceberg on Kubernetes
傳統方式下,用戶在部署和運維大資料平臺時通常采用手動或半自動化方式,這往往消耗大量人力,穩定性也無法保證,Kubernetes 的出現,革新了這一程序,Kubernetes 提供了應用部署和運維標準化能力,用戶業務在實施 Kubernetes 化改造后,可運行在其他所有標準 Kubernetes 集群中,在大資料領域,這種能力可幫助用戶快速部署和交付大資料平臺(大資料組件部署尤為復雜),尤其在大資料計算存盤分離的架構中,Kubernetes 集群提供的 Serverless 能力,可幫助用戶即拿即用的運行計算任務,并且再配合離在線混部方案,除了可做到資源統一管控降低復雜度和風險外,集群利用率也會進一步提升,大幅降低成本,
我們可基于 Kubernetes 構建 Hadoop 大資料平臺:
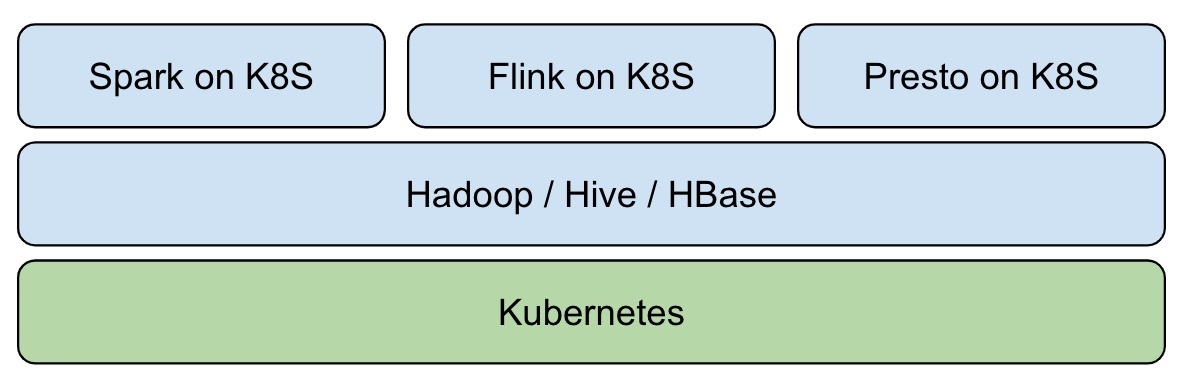
在近幾年大熱的資料湖領域,通過傳統 Hadoop 生態構建實時資料湖,受制于組件定位與設計,較為復雜與困難,Iceberg 的出現使得依賴開源技術快速構建實時資料湖成為可能,這也是大資料未來發展方向 - 實時分析、倉湖一體與云原生,引入 Iceberg 后,整體架構變為:
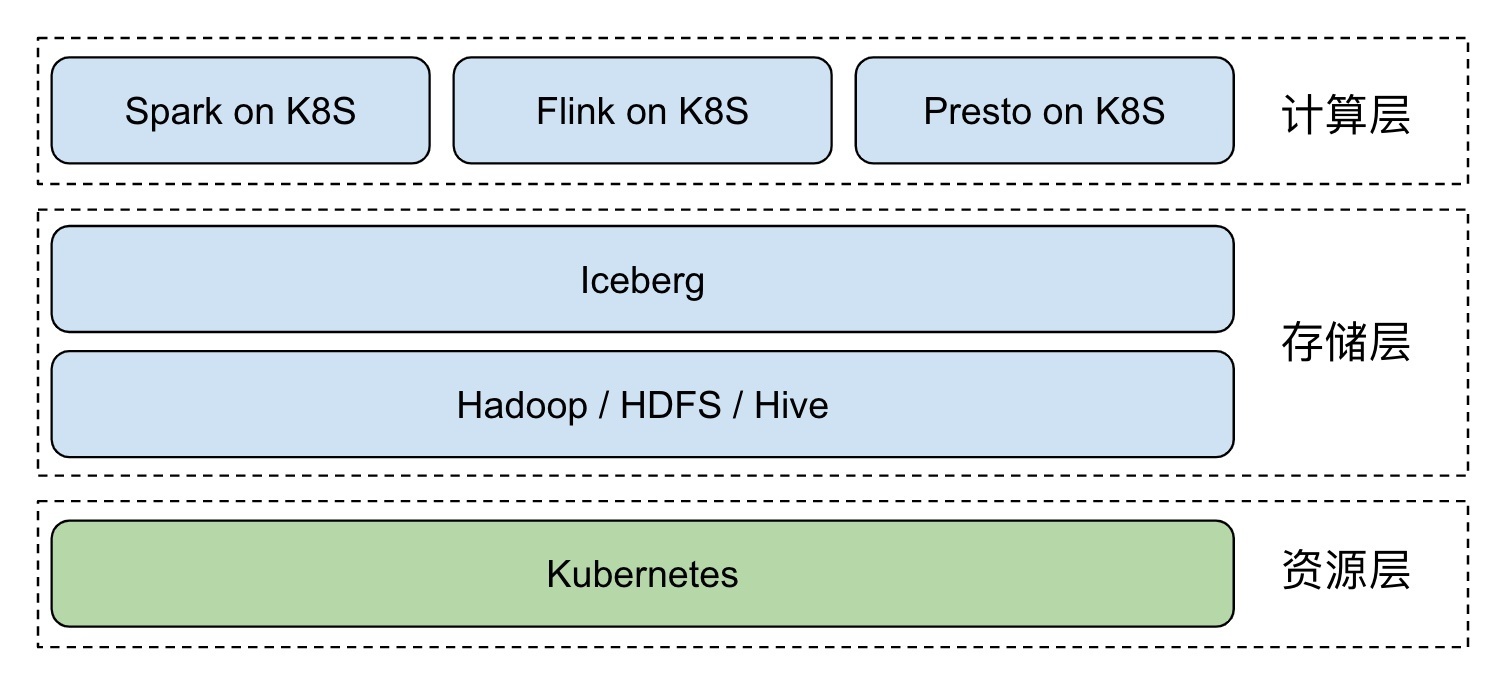
Kubernetes 負責應用自動化部署與資源管理調度,為上層屏蔽了底層環境復雜性,Iceberg + Hive MetaStore + HDFS 實作了基于 Hadoop 生態的實時資料湖,為大資料應用提供資料訪問及存盤,Spark、Flink 等計算引擎以 native 的方式運行在 Kubernetes 集群中,資源即拿即用,與在線業務混部后,更能大幅提升集群資源利用率,
如何構建云原生實時資料湖
架構圖
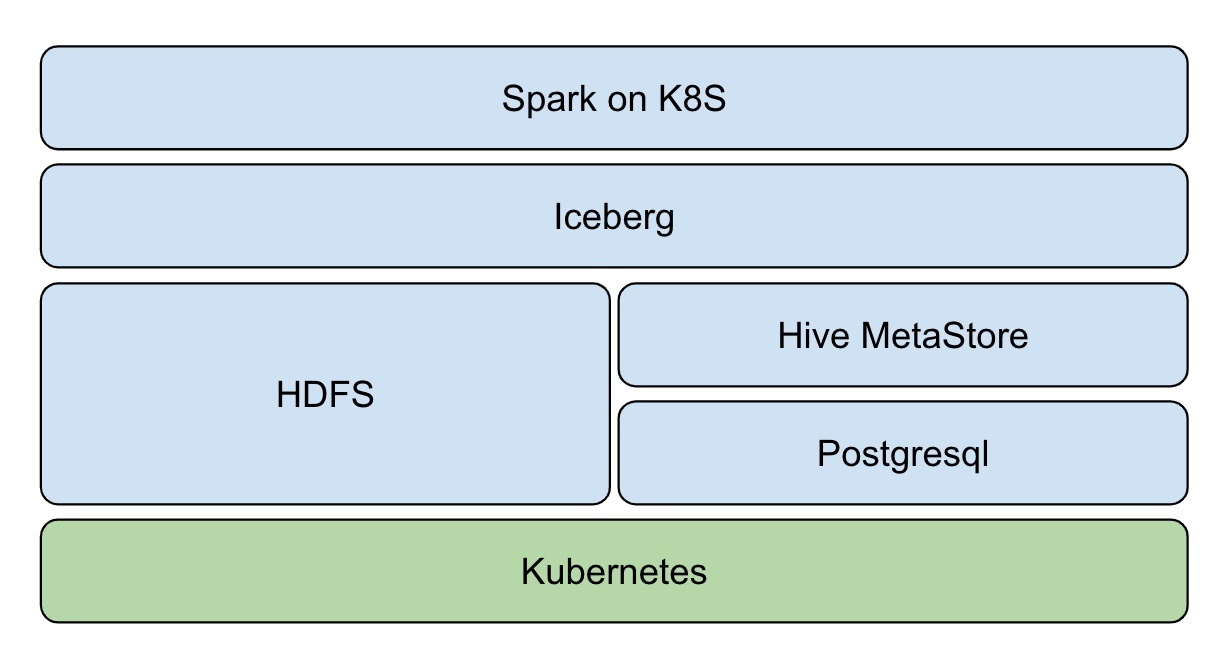
- 資源層:Kubernetes 提供資源管控能力
- 資料層:Iceberg 提供 ACID、table 等資料集訪問操作能力
- 存盤層:HDFS 提供資料存盤能力,Hive MetaStore 管理 Iceberg 表元資料,Postgresql 作為 Hive MetaStore 存盤后端
- 計算層:Spark native on Kubernetes,提供流批計算能力
創建 Kubernetes 集群
首先通過官方二進制或自動化部署工具部署 Kubernetes 集群,如 kubeadm,推薦使用騰訊云創建 TKE 集群,
推薦配置為:3 臺 S2.2XLARGE16(8核16G)實體
部署 Hadoop 集群
可通過開源 Helm 插件或自定義鏡像在 Kubernetes 上部署 Hadoop 集群,主要部署 HDFS、Hive MetaStore 組件,在騰訊云 TKE 中推薦使用 k8s-big-data-suite 大資料應用自動化部署 Hadoop 集群,
k8s-big-data-suite 是我們基于生產經驗開發的大資料套件,可支持主流的大資料組件在 Kubernetes 上一鍵部署,部署之前請先按照要求做集群初始化:
# 標識存盤節點,至少三個
$ kubectl label node xxx storage=true
部署成功后,連入 TKE 集群查看組件狀態:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
alertmanager-tkbs-prometheus-operator-alertmanager-0 2/2 Running 0 6d23h
cert-job-kv5tm 0/1 Completed 0 6d23h
elasticsearch-master-0 1/1 Running 0 6d23h
elasticsearch-master-1 1/1 Running 0 6d23h
flink-operator-controller-manager-9485b8f4c-75zvb 2/2 Running 0 6d23h
kudu-master-0 2/2 Running 2034 6d23h
kudu-master-1 2/2 Running 0 6d23h
kudu-master-2 2/2 Running 0 6d23h
kudu-tserver-0 1/1 Running 0 6d23h
kudu-tserver-1 1/1 Running 0 6d23h
kudu-tserver-2 1/1 Running 0 6d23h
prometheus-tkbs-prometheus-operator-prometheus-0 3/3 Running 0 6d23h
superset-init-db-g6nz2 0/1 Completed 0 6d23h
thrift-jdbcodbc-server-1603699044755-exec-1 1/1 Running 0 6d23h
tkbs-admission-5559c4cddf-w7wtf 1/1 Running 0 6d23h
tkbs-admission-init-x8sqd 0/1 Completed 0 6d23h
tkbs-airflow-scheduler-5d44f5bf66-5hd8k 1/1 Running 2 6d23h
tkbs-airflow-web-84579bc4cd-6dftv 1/1 Running 2 6d23h
tkbs-client-844559f5d7-r86rb 1/1 Running 6 6d23h
tkbs-controllers-6b9b95d768-vr7t5 1/1 Running 0 6d23h
tkbs-cp-kafka-0 3/3 Running 2 6d23h
tkbs-cp-kafka-1 3/3 Running 2 6d23h
tkbs-cp-kafka-2 3/3 Running 2 6d23h
tkbs-cp-kafka-connect-657bdff584-g9f2r 2/2 Running 2 6d23h
tkbs-cp-schema-registry-84cd7cbdbc-d28jk 2/2 Running 4 6d23h
tkbs-grafana-68586d8f97-zbc2m 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-6jng4 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-rn8z9 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-t68zq 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-0 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-1 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-2 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-nn-0 2/2 Running 5 6d23h
tkbs-hadoop-hdfs-nn-1 2/2 Running 0 6d23h
tkbs-hbase-master-0 1/1 Running 3 6d23h
tkbs-hbase-master-1 1/1 Running 0 6d23h
tkbs-hbase-rs-0 1/1 Running 3 6d23h
tkbs-hbase-rs-1 1/1 Running 0 6d23h
tkbs-hbase-rs-2 1/1 Running 0 6d23h
tkbs-hive-metastore-0 2/2 Running 0 6d23h
tkbs-hive-metastore-1 2/2 Running 0 6d23h
tkbs-hive-server-8649cb7446-jq426 2/2 Running 1 6d23h
tkbs-impala-catalogd-6f46fd97c6-b6j7b 1/1 Running 0 6d23h
tkbs-impala-coord-exec-0 1/1 Running 7 6d23h
tkbs-impala-coord-exec-1 1/1 Running 7 6d23h
tkbs-impala-coord-exec-2 1/1 Running 7 6d23h
tkbs-impala-shell-844796695-fgsjt 1/1 Running 0 6d23h
tkbs-impala-statestored-798d44765f-ffp82 1/1 Running 0 6d23h
tkbs-kibana-7994978d8f-5fbcx 1/1 Running 0 6d23h
tkbs-kube-state-metrics-57ff4b79cb-lmsxp 1/1 Running 0 6d23h
tkbs-loki-0 1/1 Running 0 6d23h
tkbs-mist-d88b8bc67-s8pxx 1/1 Running 0 6d23h
tkbs-nginx-ingress-controller-87b7fb9bb-mpgtj 1/1 Running 0 6d23h
tkbs-nginx-ingress-default-backend-6857b58896-rgc5c 1/1 Running 0 6d23h
tkbs-nginx-proxy-64964c4c79-7xqx6 1/1 Running 6 6d23h
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 6d23h
tkbs-postgresql-ha-pgpool-5cbf85d847-v5dsr 1/1 Running 1 6d23h
tkbs-postgresql-ha-postgresql-0 2/2 Running 0 6d23h
tkbs-postgresql-ha-postgresql-1 2/2 Running 0 6d23h
tkbs-prometheus-node-exporter-bdp9v 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-cdrqr 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-cv767 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-l82wp 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-nb4pk 1/1 Running 0 6d23h
tkbs-prometheus-operator-operator-f74dd4f6f-lnscv 2/2 Running 0 6d23h
tkbs-promtail-d6r9r 1/1 Running 0 6d23h
tkbs-promtail-gd5nz 1/1 Running 0 6d23h
tkbs-promtail-l9kjw 1/1 Running 0 6d23h
tkbs-promtail-llwvh 1/1 Running 0 6d23h
tkbs-promtail-prgt9 1/1 Running 0 6d23h
tkbs-scheduler-74f5777c5d-hr88l 1/1 Running 0 6d23h
tkbs-spark-history-7d78cf8b56-82xg7 1/1 Running 4 6d23h
tkbs-spark-thirftserver-5757f9588d-gdnzz 1/1 Running 4 6d23h
tkbs-sparkoperator-f9fc5b8bf-8s4m2 1/1 Running 0 6d23h
tkbs-sparkoperator-f9fc5b8bf-m9pjk 1/1 Running 0 6d23h
tkbs-sparkoperator-webhook-init-m6fn5 0/1 Completed 0 6d23h
tkbs-superset-54d587c867-b99kw 1/1 Running 0 6d23h
tkbs-zeppelin-controller-65c454cfb9-m4snp 1/1 Running 0 6d23h
tkbs-zookeeper-0 3/3 Running 0 6d23h
tkbs-zookeeper-1 3/3 Running 0 6d23h
tkbs-zookeeper-2 3/3 Running 0 6d23h
注意
當前 TKE k8s-big-data-suite 1.0.3 在初始化 Postgresql 時,缺少對 Hive transaction 的支持,從而導致 Iceberg 表創建失敗,請先執行以下命令手動修復:
$ kubectl get pod | grep postgresql
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d18h
$ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "UPDATE pg_database SET datallowconn = 'false' WHERE datname = 'metastore';SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'metastore'"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "drop database metastore"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "create database metastore"
$ kubectl get pod | grep client
tkbs-client-844559f5d7-r86rb 1/1 Running 7 7d18h
$ kubectl exec tkbs-client-844559f5d7-r86rb -- schematool -dbType postgres -initSchema
集成 Iceberg
當前 Iceberg 對 Spark 3.0 有較好支持,對比 Spark 2.4 有以下優勢:
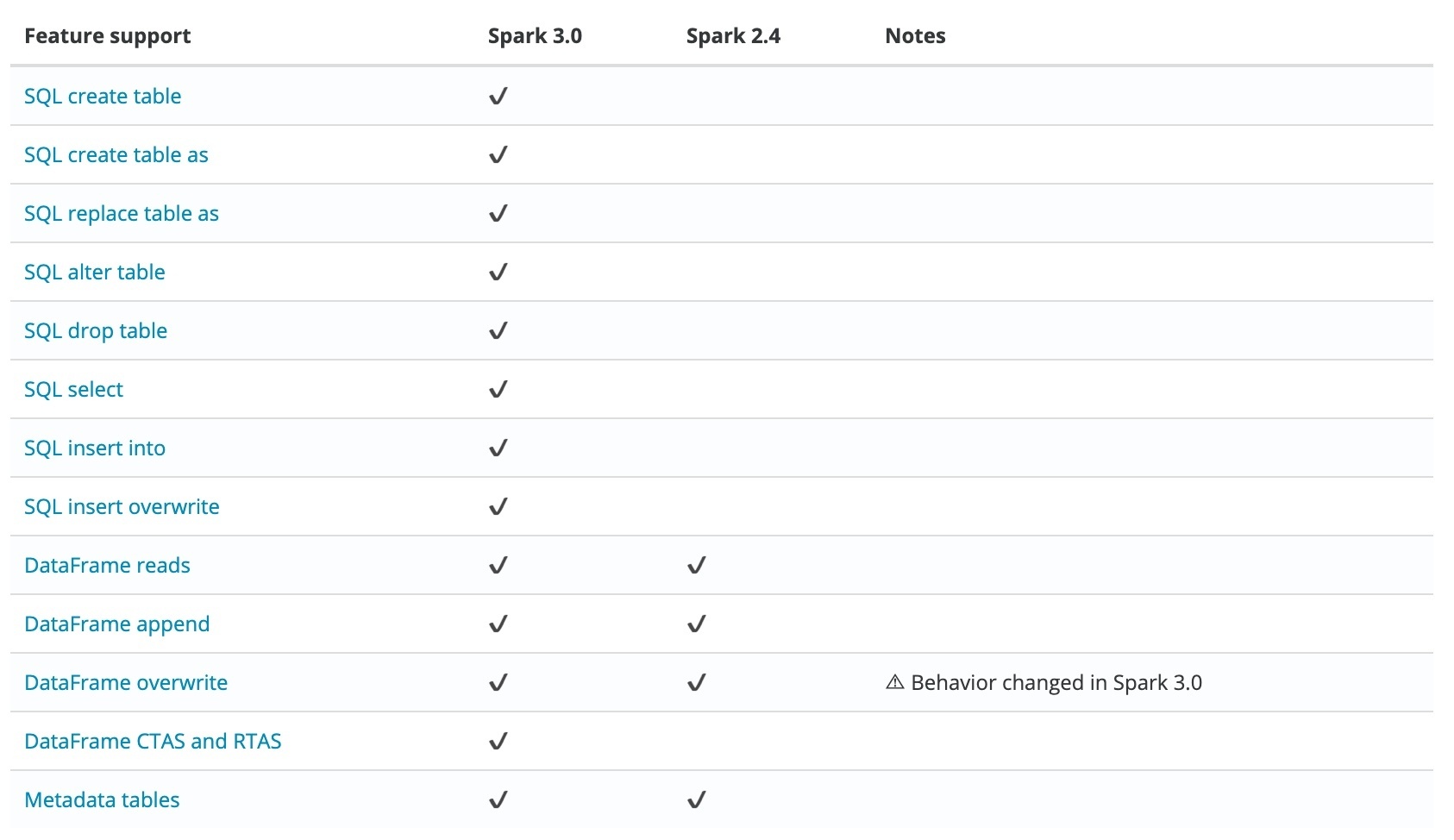
所以我們默認采用 Spark 3.0 作為計算引擎,Spark 集成 Iceberg,首先需引入 Iceberg jar 依賴,用戶可在提交任務階段手動指定,或將 jar 包直接引入 Spark 安裝目錄,為了便于使用,我們選擇后者,筆者已打包 Spark 3.0.1 的鏡像,供用戶測驗使用:ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1,
我們使用 Hive MetaStore 管理 Iceberg 表資訊,通過 Spark Catalog 訪問和使用 Iceberg 表,在 Spark 中做如下配置:
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port
若使用 TKE k8s-big-data-suite 套件部署 Hadoop 集群,可通過 Hive Service 訪問 Hive MetaStore:
$ kubectl get svc | grep hive-metastore
tkbs-hive-metastore ClusterIP 172.22.255.104 <none> 9083/TCP,8008/TCP 6d23h
Spark 配置變更為:
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://tkbs-hive-metastore
創建和使用 Iceberg 表
執行 spark-sql 進行驗證:
$ spark-sql --master k8s://{k8s-apiserver} --conf spark.kubernetes.container.image=ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1 --conf spark.sql.catalog.hive_prod=org.apache.iceberg.spaparkCatalog --conf spark.sql.catalog.hive_prod.type=hive --conf spark.sql.catalog.hive_prod.uri=thrift://tkbs-hive-metastore --conf spark.sql.warehouse.dir=hdfs://tkbs-hadoop-hdfs-nn/iceberg
各引數含義如下:
- --master k8s://{k8s-apiserver}:Kubernetes 集群地址
- --conf spark.kubernetes.container.image=ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1:Spark Iceberg 鏡像
- --conf spark.sql.catalog.hive_prod.type=hive:Spark Catalog 型別
- --conf spark.sql.catalog.hive_prod.uri=thrift://tkbs-hive-metastore:Hive MetaStore 地址
- --conf spark.sql.warehouse.dir=hdfs://tkbs-hadoop-hdfs-nn/iceberg:Spark 資料地址
創建 Iceberg 表:
spark-sql> CREATE TABLE hive_prod.db.table (id bigint, data string) USING iceberg;
查看是否創建成功:
spark-sql> desc hive_prod.db.table;
20/11/02 20:43:43 INFO BaseMetastoreTableOperations: Refreshing table metadata from new version: hdfs://10.0.1.129/iceberg/db.db/table/metadata/00000-1306e87a-16cb-4a6b-8ca0-0e1846cf1837.metadata.json
20/11/02 20:43:43 INFO CodeGenerator: Code generated in 21.35536 ms
20/11/02 20:43:43 INFO CodeGenerator: Code generated in 13.058698 ms
id bigint
data string
# Partitioning
Not partitioned
Time taken: 0.537 seconds, Fetched 5 row(s)
20/11/02 20:43:43 INFO SparkSQLCLIDriver: Time taken: 0.537 seconds, Fetched 5 row(s)
查看 HDFS 是否存在表資訊:
$ hdfs dfs -ls /iceberg/db.db
Found 5 items
drwxr-xr-x - root supergroup 0 2020-11-02 16:37 /iceberg/db.db/table
查看 Postgresql 是否存在表元資料資訊:
$ kubectl get pod | grep postgresql
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d19h$ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -d metastore -c 'select * from "TBLS"'
向 Iceberg 表插入資料:
spark-sql> INSERT INTO hive_prod.db.table VALUES (1, 'a'), (2, 'b');
查看是否插入成功:
spark-sql> select * from hive_prod.db.table;
...
1 a
2 b
Time taken: 0.854 seconds, Fetched 2 row(s)
20/11/02 20:49:43 INFO SparkSQLCLIDriver: Time taken: 0.854 seconds, Fetched 2 row(s)
查看 Kubernetes 集群 Spark 任務運行狀態:
$ kubectl get pod | grep spark
sparksql10-0-1-64-ed8e6f758900de0c-exec-1 1/1 Running 0 86s
sparksql10-0-1-64-ed8e6f758900de0c-exec-2 1/1 Running 0 85s
Iceberg Spark 支持的更多操作可見:https://iceberg.apache.org/spark/
通過以上步驟,我們即可在 Kubernetes 上快速部署生產可用的實時資料湖平臺,
總結
在這個資料量爆炸的時代,傳統數倉已較難很好滿足資料多樣性需求,資料湖憑借開放、低成本等優勢,逐漸居于主導地位,并且用戶和業務也不再滿足于滯后的分析結果,對資料實時性提成了更多要求,以 Iceberg、Hudi、Delta Lake 為代表的開源資料湖技術,填補了這部分市場空白,為用戶提供了快速搭建適用于實時 OLAP 的資料湖平臺能力,另外云原生時代的到來,更是大大加速了這一程序,大資料毋庸置疑正朝著實時分析、計算存盤分離、云原生,乃至于湖倉一體的方向發展,大資料基礎設施也正因為 Kubernetes、容器等云原生技術的引入,正發生巨大變革,未來大資料會更好的“長于云上”,Bigdata as a Service 的時代,相信很快會到來,
參考材料
- https://iceberg.apache.org/
- https://github.com/apache/iceberg
- https://cloud.tencent.com/product/tke
- https://github.com/tkestack/charts/tree/main/incubator/k8s-big-data-suite
- 基于Apache Iceberg打造T+0實時數倉
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/204740.html
標籤:其他