端到端的OCR版面分析演算法
- OCR版面分析痛點
- 演算法設計初衷
- 資料增廣策略
- 兩種端到端的方案
- 1、基于xgboost的版面分析演算法
- 2、基于seq2seq的版面分析演算法
- 結語
OCR版面分析痛點
當前OCR之后的版面分析作業大家都是規則寫的,自己也深受規則之苦,看到ocr輸出的一大堆文字和坐標就頭皮發麻,最近受了chineseocr作者模板引擎的啟發,做了兩個端到端的版面分析演算法,希望能夠幫到各位ocrer,github
演算法設計初衷
最開始的想法是在檢測網路上增加類別判斷,預測位置的同時加上box類別的判斷,但是這樣通用性就大大降低了,違背不干預原始的OCR演算法的初衷,版面分析的演算法應該和OCR演算法無縫銜接,所以模型輸入應該是OCR輸出的box坐標和相應文本,
基于此,延伸出兩個思路,一個是忽略box間的位置關系,直接將box坐標和文本編碼,送入分類器,即基于xgboost的分類方案,另一個考慮box間的相互關系,將版面分析當成一種翻譯任務,即基于seq2seq的翻譯方案
資料增廣策略
其次標注資料不能太多,如果標注投入過大就有些得不償失了,演算法設計初衷就是希望只標注一些具有代表性的版面,因此增廣策略就顯得特別重要,增廣策略有以下幾條:
- 隨機擾動檢測框坐標點1~3個像素
- 隨機切分檢測框,并隨機拆分文本
- 隨機替換 數字、日期等文本內容
- 隨機丟棄3~5檢測框
兩種端到端的方案
1、基于xgboost的版面分析演算法
- 編碼方案
- 1)文本使用doc2vec無監督訓練句向量50dim(可選)
將OCR識別后的文本收集起來加上外部資料可以利用gensim的doc2vec訓練一個該版面的句向量,也曾嘗試用字向量做加權平均,但是感覺上會丟失資訊,后續會補上相關實驗,向量為度選取50dim,這樣每個box的文本都可以編碼為50dim的向量,在實驗程序中,發現基于機器學習的方法比較吃人工特征,加上句向量后提升大約0.5個點,所以該項是可選項, - 2)文本的數字比例、英文比例、符號比例、其他比例4dim
這部分算是特征工程吧,統計每個單元格數字占比、英文占比、符號占比、其他字符占比一共四個維度資訊,還可以根據自身業務提取更多人工特征資訊 - 3)box坐標點8dim
文字檢測輸出的四邊形,一共四個頂點,8個數值 - 4)三個類別資訊相拼,一共50+4+8=62維資訊,作為模型輸入
- 1)文本使用doc2vec無監督訓練句向量50dim(可選)
- 模型輸出
- onehot編碼
每個格子按照業務需求進行類別劃分,將決議問題轉化為分類問題,比如:發票一共有18個關鍵欄位,加上其他類別,一共19個類別,對這19個類別做onthot編碼作為模型輸出,
- onehot編碼
- 模型選擇
既然是分類問題,可選的方案就很多,線性回歸、隨機森林、SVM等,這里只嘗試了xgboost,大家可以在自己的業務場景多多嘗試,鑒于傳統機器學習代碼過于簡單,sklearn幾行就可以搞定,這里就不提供開源代碼了,
2、基于seq2seq的版面分析演算法
剛開始想既然考慮格子的位置關系,那不是得用圖演算法么,最近也有人開源了PICK,正要去嘗試,作者撤銷了代碼,而且工業中基于圖的演算法應用不多,后來靈機一動,lstm不也是一種圖么,只不過是線性圖,要做的就是把box拉伸排序成線性,不就可以解決了么, 自然而然的想到了seq2seq,絕配!
- 編碼方案
- 1)文本編碼方案同xgboost,只不過維度增加為100維
- 2)box坐標點因為維度過小,做了維度拉伸,8個坐標點暴力復制8遍
- 3)最終每個格子的編碼為100+8*8=164維度
- 4)需要注意的是,xgboost是每一個格子當作一個訓練樣本模型輸入維度為1維(62),seq2seq是整版的格子當作一個訓練樣本,在發票場景中,整版格子不超過100,所以選取100為最長輸入序列,一個樣本的維度為2維(100*164)
- 模型輸出
- onehot編碼同xgboost
- seq2seq模型修改
- 1)不用teacher forcing的訓練方式
最開始嘗試的時候,一直使用基于teacher forcing的訓練方式,這可是seq2seq的標配,試的程序一直不收斂,一直以為是資料量小的問題,后來抱著試試的想法,把teacher forcing干掉了,索性把上一個格子的類別替換成當前格子編碼,損失下降嗖嗖的,想想也是,翻譯的時候前一個字對后一個字影響很大,這個場景中依賴就沒那么大了,對類別判斷影響比較大的是位置資訊和文字資訊,歪打正著, - 2)去除起始符和終止符
在翻譯的場景因為不知道第一個字如何開始,所以加入了起始符號,但是版面分析中是可以提供原始資訊的,因此洗掉了這兩個占位符,(可以保留終止符,減少不必要計算) - 3) 模型結構示意圖
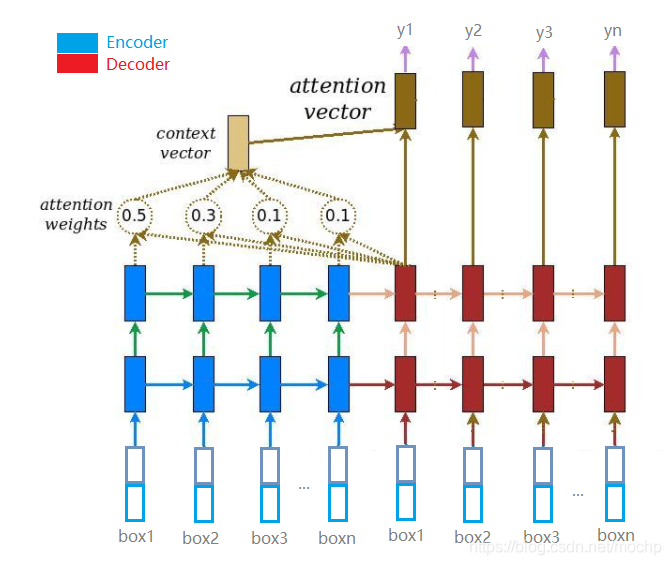
- 1)不用teacher forcing的訓練方式
結語
兩種方案目前在發票的版面分析中都取得了不錯的結果,其中xgboost的方案在版式比較固定的時候表現比較適用,seq2seq的方案在任意拍照場景中比較適用,需要注意的是,如果文字檢測把一些無關的文字和關鍵欄位框到一起的話,還需要稍微做些后處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/204812.html
標籤:其他