[鳶尾花的種類]
預測鳶尾花的種類
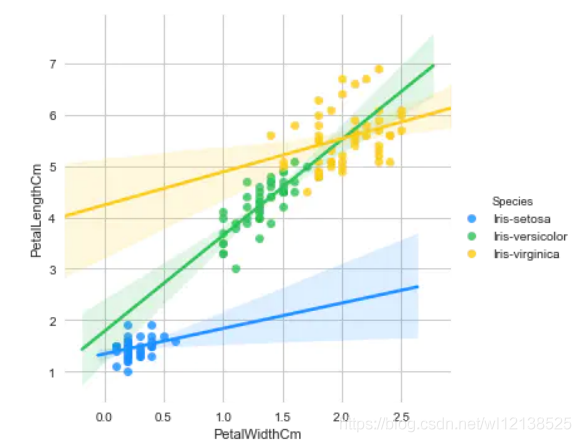
Iris資料集在RA Fisher于1936年發表的經典論文《分類問題中的多重測量的使用》中使用,也可以在UCI中找到,它包括三個種類,每個種類有50個樣本以及每朵花的一些特性,一種花可以與其他兩種花是線性可分的,但是另兩種不是線性可分的,
如圖
目標
分類
預測鳶尾花的種類,
進階
想辦法在預測模型上提高精度
說明
- 給出匯入資料的方式
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
x_train, y_train # train data
x_test, y_test # test data
- 資料均是實數沒有文本
- 請在訓練集上訓練模型,在測驗集上進行預測
分析問題
影像的分類問題可以使用神經網路來寫,
這里我創建了一個兩層的神經網路Network
交叉熵誤差
使用的是交叉熵誤差公式為
E
=
?
1
N
∑
n
∑
k
t
n
k
l
o
g
y
n
k
E = -\frac{1}{N}\sum_{n}\sum_{k}t_{nk}logy_{nk}
E=?N1?n∑?k∑?tnk?logynk?
對應的代碼
def cross_entropy_error(y, t):
# y為測驗標簽,t為正確標簽
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 監督資料是one-hot-vector的情況下,轉換為正確解標簽的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
sigmoid
我這個兩層神經網路中使用的激活函式是
s
i
g
m
o
i
d
(
x
)
=
1
1
+
e
?
x
sigmoid(x) = \frac{1}{1+e^{-x}}
sigmoid(x)=1+e?x1?
在反向傳播中他的導數為sigmoid(x)(1 - sigomid(x))
sigmoid在反向傳播中的代碼如下:
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
其中forward回傳正向傳播的值,backward回傳反向傳播的結果,
因為在反向傳播的時候需要他的輸出變數,所以在正向傳播的時候要將輸出值out存盤在實體變數out中,
Affine
反向傳播中Affine層為 W*X + B,因為W,X,B均為矩陣,所以運用到了numpy中的dot函式,np.dot(X, W) 表示矩陣X和W相乘(矩陣X * W != W * X)
方向傳播可以寫為(T代表矩陣轉置的意思):
?
L
?
X
=
?
L
?
Y
?
W
T
\frac{\partial L}{\partial X} = \frac{\partial L}{\partial Y} · W^T
?X?L?=?Y?L??WT
?
L
?
Y
=
X
T
?
?
L
?
Y
\frac{\partial L}{\partial Y} = X^T·\frac{\partial L}{\partial Y}
?Y?L?=XT??Y?L?
所以在反向傳播中Affine層所對應的代碼如下:
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.original_x_shape = None
# 權重和偏置引數的導數
self.dW = None
self.db = None
def forward(self, x):
# 對應張量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 還原輸入資料的形狀(對應張量)
return dx
其中forward回傳正向傳播的值,backward回傳反向傳播的結果,(在兩層的神經網路中他需要用到兩次~)
Softmax-With-Loss
Softmax
在介紹Softmax-With-Loss之前先介紹一下Softmax
它是用來計算輸出層每一個神經元的概率的:
S
o
f
t
m
a
x
=
e
y
k
∑
e
y
k
Softmax = \frac{e^{y_k}}{\sum{e^{y_k}}}
Softmax=∑eyk?eyk??
因為e的指數容易變得非常大,可能會導致溢位,所以對此函式進行了改進,如下:
S
o
f
t
m
a
x
=
e
y
k
+
C
∑
e
y
k
+
C
Softmax = \frac{e^{y_k+C}}{\sum{e^{y_k+C}}}
Softmax=∑eyk?+Ceyk?+C?
這里的C可以是任何值,但為了防止溢位,一般使用輸入信號的最大值,看一個具體的例子:
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢位對策
return np.exp(x) / np.sum(np.exp(x))
輸入的X是一個陣列,對他進行exp操作會回傳一個與他大小相同,但對其中每一個元素都進行exp操作的陣列,
下面看Softmax-With-Loss的方向傳播圖
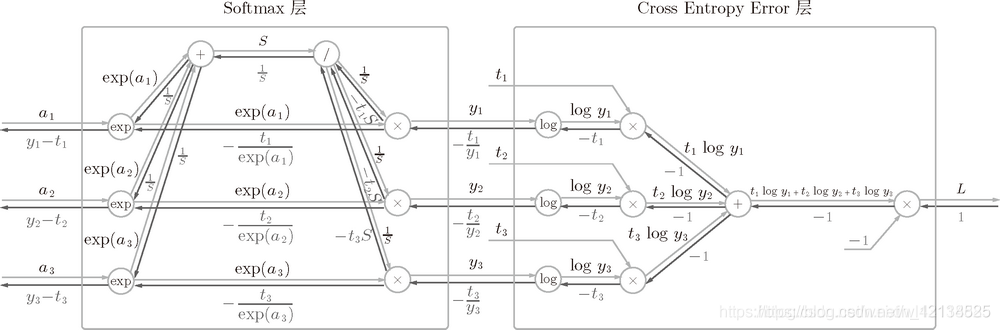
可以發現,反向傳播之后回傳值的是y-t,所以Softmax-With-Loss的代碼如下:
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的輸出
self.t = None # 監督資料
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 監督資料是one-hot-vector的情況
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
所有需要用到的函式以及類都介紹完了,下面開始寫Network
Network
class Network(object):
def __init__(self, input_size, hide_size, output_size, weight_init_std=0.001):
"""
用來宣告該神經網路輸入輸出以及隱藏層的每一層層數
:param input_size: 輸入層數
:param hide_size: 第一個隱藏層層數
:param output_size: 輸出層層數
:param weight_init_std: 防止W過大
"""
self.params = {'w1': weight_init_std * np.random.randn(input_size, hide_size), 'b1': np.zeros(hide_size),
'w2': weight_init_std * np.random.randn(hide_size, output_size), 'b2': np.zeros(output_size),}
self.layers = OrderedDict() # 使字典有序,可以記住像字典中添加元素的順序
self.layers = {'Affine1': Affine(self.params['w1'], self.params['b1']),
'Sigmoid': Sigmoid(),
'Affine2': Affine(self.params['w2'], self.params['b2'])}
self.layer_last = SoftmaxWithLoss()
def predict(self, x):
"""
用來預測資料通過該模型后得到的結果
:param x: 預測的輸入資料
:return: 回傳該網路預測的結果
"""
for layer in self.layers.values():
x = layer.forward(x)
return softmax(x)
def loss(self, x, t):
"""
計算該神經網路所預測結果與實際結果的損失
其中y為預測結果
:param x: 輸入資料
:param t: 真實結果
:return: 交叉熵損失
"""
y = self.predict(x)
return self.layer_last.forward(y, t)
def accuracy(self, x, t):
"""
識別計算精度
其中y為預測結果
:param x: 輸入資料
:param t: 真實結果
:return: 正確率
"""
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1:
t = np.argmax(t, axis=1)
return np.sum(y == t) / float(x.shape[0])
def back_gradient(self, x, t):
"""
進行反向傳播演算法
:return: 反向傳播得到的偏導
"""
self.loss(x, t)
# 將涉及到的layer通過串列存盤起來,以便于進行反向傳播的遍歷
layers = list(self.layers.values())
# 將layers倒序
layers.reverse()
# 第一個反向傳播的引數應該是一
dout = 1
# 反向傳播經過輸出層
dout = self.layer_last.backward(dout)
# 反向傳播從尾到頭依次傳播
for layer in layers:
dout = layer.backward(dout)
# 獲得反向傳播得到的各個引數的偏導
grads = {'w1': self.layers['Affine1'].dW, 'b1': self.layers['Affine1'].db,
'w2': self.layers['Affine2'].dW, 'b2': self.layers['Affine2'].db
}
return grads
network需要介紹的都在注釋中寫的很清楚,
下面來開始訓練:
# 讀入資料
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
# x_train.shape = (112, 4), 所以input_size為4,hide_size可以根據自己的情況隨意設定,output_size 以為y有0, 1, 2三個元素,所以設定為3
network = Network.Network(input_size=4, hide_size=50, output_size=3)
trying_time = 100000 # 回圈的次數
train_size = x_train.shape[0] # 訓練集的大小
batch_size = 1 # 每一次訓練時挑選的一批資料的大小
learning_rate = 5e-4 # 學習率
min_loss = float('inf') # 起初min_loss為無窮大
# 每一個epoch重復的次數
iter_per_epoch = max(train_size / batch_size, 1)
# 開始訓練
for i in range(trying_time):
batch_mask = np.random.choice(train_size, batch_size) # 隨機選擇要進行訓練的下標,由于choice是隨機選擇,所以大回圈結束也不一定會對每一個元素進行學習,
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
# 通過反向傳播來求偏導,并記錄在grad中
grad = network.back_gradient(x_batch, y_batch)
# 更新各個引數
for key in ('w1', 'b1', 'w2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 計算損失
loss = network.loss(x_batch, y_batch)
# 存放當前損失
if loss < min_loss:
min_loss = loss
if i % iter_per_epoch == 0:
# 訓練集的正確率
train_acc = network.accuracy(x_train, y_train)
# 測驗集的正確率X
test_acc = network.accuracy(x_test, y_test)
print(train_acc, test_acc)
print('預測的結果為:{}'.format(np.argmax(network.predict(x_test), axis=1)))
print('實際的結果為:{}'.format(y_test))
print('預測的正確率為:{}'.format(network.accuracy(x_test, y_test)))
print('損失為:{}'.format(min_loss))
需要注意的是learning_rate的設定一定要合理,不然可能導致訓練不會產生任何效果,
運行結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/205432.html
標籤:其他