文章目錄
- 一、哈希表簡介
- 1. 哈希函式簡介
- 2. 哈希碰撞簡介
- 3. 哈希函式深究
- 哈希碼
- 壓縮函式
- 取模運演算法
- MAD方法
- 4. 處理哈希碰撞
- 分離鏈接法
- 線性查找法
- 5. 負載系數和再哈希
- 負載系數
- 再哈希
- 二、哈希表實作映射
- 1. 基于哈希表實作映射的基類`HashMapBase`
- `__init__`
- `_hash_function`
- `__len__`
- `__getitem__`
- `__setitem__`
- `__delitem__`
- 2. 基于分離鏈接法實作的映射`ChainHashMap`
- `_bucket_getitem(j, k)`
- `_bucket_setitem(j, k, v)`
- `_bucket_delitem(j, k)`
- `__iter__()`
- 3. 基于線性查找法實作的映射`ProbeHashMap`
- `_is_available(j)`
- `_find_slot(j, k)`
- `_bucket_getitem(j, k)`
- `_bucket_setitem(j, k, v)`
- `_bucket_delitem(j, k)`
- `__iter__()`
- 三、哈希表實作映射的效率
- 四、哈希表實作映射的測驗代碼
在文章【資料結構Python描述】使用串列手動實作一個字典類中,對UnsortedListMap的5個主要方法進行效率分析后可知,使用串列這種資料結構來實作的映射效率較低,本文將使用哈希表這種資料結構實作的映射,通過這種方式實作的映射,其效率要遠高于前者,
一、哈希表簡介
通過串列保存鍵值對實作的映射之所以效率較低,原因在于最壞情況下,__getitem__、__setitem__、__delitem__、__iter__方法均需要遍歷整個串列,
然而,由于串列天然具有通過索引以 O ( 1 ) O(1) O(1)時間復雜度訪問其中元素的特點,因此可以考慮是否可以將鍵值對中的鍵通過某種轉換關系轉換成串列的索引值,然后將鍵值對保存在使用索引標識的串列單元處,
實際上,上面描述的這種特殊串列就是哈希表,而轉換關系就可以認為是哈希函式,
1. 哈希函式簡介
因此,哈希函式
h
h
h的目標是為了將每一個鍵值對中的鍵
k
k
k轉換為
[
0
,
N
?
1
]
[0, N-1]
[0,N?1]范圍內的一個整數
h
(
k
)
h(k)
h(k)即哈希值,其中
N
N
N是哈希表
A
A
A這種特殊串列的容量,而鍵值對(k, v)就保存在
A
[
h
(
k
)
]
A[h(k)]
A[h(k)]單元處,
在希望獲取某一個鍵值對時,只需先對 k k k執行相同的哈希函式獲得哈希值,然后通過哈希值獲取哈希表對應單元處的鍵值對即可,
2. 哈希碰撞簡介
需要注意的是,針對不同的鍵,如果通過哈希函式得到了相同的哈希值,這時就發生了所謂的哈希碰撞,此時需要對哈希表欄位外的處理,這類額外處理一般都會降低哈希表的效率,具體的處理方案包括分離鏈接法、開放尋址法以及線性查找法等,后面將對其做詳細介紹,
3. 哈希函式深究
實際上,通常將哈希函式分為兩個組成部分,即哈希碼和壓縮函式:
- 哈希碼負責將一個鍵 k k k轉換為一個整數,該整數甚至可以為負;
- 壓縮函式負責將上述整數進一步轉換為 [ 0 , N ? 1 ] [0, N-1] [0,N?1]范圍內的一個整數,
將哈希函式分為哈希碼和壓縮函式兩個部分的好處在于哈希碼的計算可以獨立于哈希表的容量(和普通串列一樣,哈希表的容量需要根據其中元素的數量動態調整),
這樣一來,我們可以對作為鍵的任意不可變物件先通過一種統一的方式計算出其哈希碼,然后由壓縮函式使用哈希碼并根據哈希表的容量來計算該鍵對應的哈希值,
哈希碼
哈希函式的第一部分會先使用作為鍵的任意不可變物件 k k k計算出一個整數,該整數被稱為哈希碼,
Python有一個專門用于計算哈希碼的內建函式hash(x),該函式對任意物件x可回傳一個用作哈希碼的整數,而如本文所一直強調的,在Python中只有不可變型別才是可哈希的,
這一限制可確保一個物件的哈希碼在其生命周期內保持不變,則該物件的哈希值在其生命周期內保持不變,
上述重要性質可避免這樣的可能例外情況:將鍵值對插入哈希表時,鍵的哈希值對應表中某一個單元;在獲取一個鍵值對時,鍵的哈希值可能對應表中另外一個單元,
在Python所有的內建資料型別中,因int、float、str、tuple、以及frozenset的物件均為不可變的,因此這些型別的物件都是可哈希的;而list的物件可變,對于list的實體物件x,執行hash(x)將拋出TypeError例外,
壓縮函式
一般而言,鍵 k k k的哈希碼一般不能立即作為哈希表的索參考,因為哈希碼可能為負,甚至可能超過哈希表的容量,
因此,我們需要一種方式能夠將哈希碼映射成 [ 0 , N ? 1 ] [0, N-1] [0,N?1]范圍內的一個證書,該方式就是壓縮函式,評價一個壓縮函式好壞的標準是:對于給定的一組各不相同的哈希碼,壓縮函式可以將哈希碰撞的可能性降到最低,
下面是一些典型的壓縮函式:
取模運演算法
一種簡單的壓縮函式為取模運演算法,即取:
i m o d N i \ mod \ N i mod N
其中 i i i為哈希碼, N N N為哈希表的容量,而且在 N N N為質數時發生哈希碰撞的可能性將比較小,
當 N N N不是質數時,發生哈希碰撞的可能性將大大增加,例如:當一組鍵的哈希碼為 { 200 , 205 , 210 , 215 , 220 , ? ? ? , 600 } \{200, 205, 210, 215, 220, \cdot\cdot\cdot, 600\} {200,205,210,215,220,???,600},且哈希表的容量為100時,則每一個哈希碼都將和另外3個哈希碼發生碰撞,
如果壓縮函式選擇得當,那么兩個不同的哈希碼發生碰撞的概率為 1 / N {\left. 1\middle/ N\right.} 1/N,
MAD方法
上述取模演算法有一個缺點是,當哈希碼為 p N + q pN+q pN+q的形式,則發生哈希碰撞的概率依然很大,而所謂的MAD(Multiply-Add-and-Divide)方法可以很好的改善這個問題,即:
[ ( a i + b ) m o d p ] m o d N [(ai+b) \ mod \ p] \ mod \ N [(ai+b) mod p] mod N
其中 N N N依然為哈希表的容量, p p p是比 N N N更大的質數,而 a a a和 b b b都是 [ 0 , p ? 1 ] [0, p-1] [0,p?1]范圍內的整數且 a > 0 a\gt0 a>0,
4. 處理哈希碰撞
由上述討論可知,使用哈希表實作用于保存鍵值對的映射的主要思想在于:給定一個哈希表表
A
A
A,以及一個哈希函式
h
h
h,實作將鍵值對(k, v)保存在哈希表的
A
[
h
(
k
)
]
A[h(k)]
A[h(k)]單元,
然而,問題在于:當對于兩個不同的鍵
k
1
k_1
k1?和
k
2
k_2
k2?有
h
(
k
1
)
=
h
(
k
2
)
h(k_1)=h(k_2)
h(k1?)=h(k2?),即發生了哈希碰撞,此時不能簡單的將鍵值對(k, v)插入哈希表,同樣,在進行查找、洗掉等操作時也需要對這種情況進行考慮,
因此,下面就將介紹幾種處理哈希碰撞的方案:
分離鏈接法
處理哈希碰撞的一種簡單而高效的方式是分離鏈接法(Separate Chaining),即將所有滿足
h
(
k
)
=
j
h(k)=j
h(k)=j的鍵值對(k, v)保存一個二級容器(如:使用串列保存鍵值對實作的映射物件)中,而哈希表的單元
A
[
j
]
A[j]
A[j]參考該二級容器,
如下圖所示,一個容量為13的哈希表保存了10個鍵值對(圖中省略了所有鍵值對中的值),且哈希函式為 h ( k ) = k m o d 13 h(k)=k \ mod \ 13 h(k)=k mod 13:
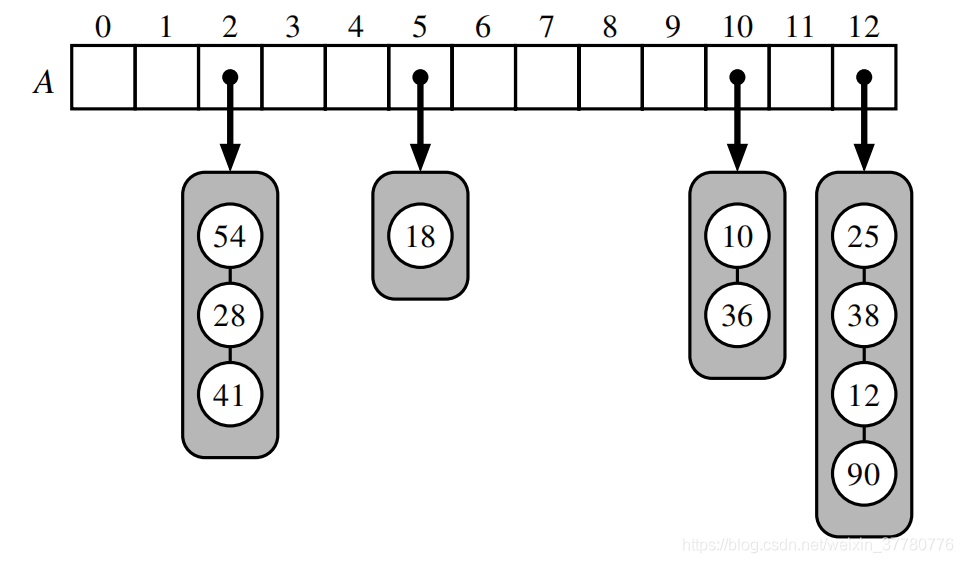
對于上述處理哈希碰撞的方案,對某一個單元 A [ j ] A[j] A[j]所參考的二級容器進行查找時,在最壞的情況下,時間復雜度和二級容器的大小呈正比,
假設現在有一個能盡量降低哈希碰撞發生概率的哈希函式,待存盤的鍵值對數目為 n n n,哈希表容量為 N N N,則期望每一個哈希表單元處參考的二級容器的容量為 n / N {\left. n\middle/ N\right.} n/N,
基于以上設定,則映射__getitem__、__setitem__以及__delitem__這三個核心方法的最壞時間復雜度為
O
(
?
n
/
N
?
)
O(\lceil {\left. n\middle/ N\right.} \rceil)
O(?n/N?),一般將
λ
=
n
/
N
\lambda={\left. n\middle/ N\right.}
λ=n/N記為哈希表的負載系數,顯然
λ
\lambda
λ最好應當小于1,否則必然會發生哈希碰撞,此時映射幾個核心方法的期望時間復雜度為
O
(
1
)
O(1)
O(1),
線性查找法
上述解決哈希碰撞的分離鏈接法雖然實作起來較為方便,但是其也有一個缺陷:需要一個輔助的二級容器來保存發生哈希碰撞的鍵值對,這對記憶體敏感的可穿戴設備不利,下面將要介紹的線性查找法就可以確保不使用額外的二級容器來避免哈希沖突:
在使用線性查找法時,當嘗試將鍵值對(k, v)向哈希表
A
[
j
]
A[j]
A[j](其中
j
=
h
(
k
)
j=h(k)
j=h(k))單元插入時發現后者已被占用,則嘗試
A
[
(
j
+
1
)
m
o
d
N
]
A[(j+1) \ mod \ N]
A[(j+1) mod N]單元,如果
A
[
(
j
+
1
)
m
o
d
N
]
A[(j+1) \ mod \ N]
A[(j+1) mod N]依然已被占用則嘗試
A
[
(
j
+
2
)
m
o
d
N
]
A[(j+2) \ mod \ N]
A[(j+2) mod N],以此類推,直到在哈希表中找到空的單元,
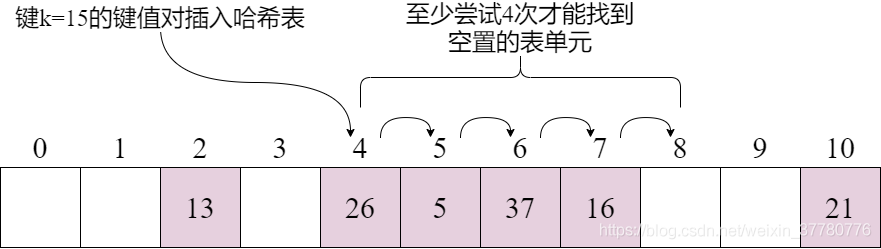
為解釋上述程序,假定哈希表容量為11,鍵均為整數,哈希函式為 h ( k ) = k m o d 11 h(k) = k \ mod \ 11 h(k)=k mod 11,則下圖(省略鍵值對中的值)表示了在如圖狀態下插入鍵為15的鍵值對所要嘗試的操作:
上述策略使得映射的三個核心方法__getitem__、__setitem__以及__delitem__在實作的第一步就需要進行特別的考慮,
具體地,當實作__delitem__時,我們不能簡單地將找到的鍵值對進行洗掉,例如:如插入鍵為15的鍵值對后,如果洗掉了鍵為37的鍵值對,則后續對于鍵為15的鍵值對的搜索就將失敗,因為線性查找策略將先從索引為4的單元處開始,然后到索引為5處,然后再發現索引為6的單元為空,因此:
- 對于
__delitem__:在洗掉某單元處的鍵值對后,將其參考一個用于標記的物件(一般為object的實體); - 對于
__getitem__:在查找鍵值對時,當遇到object的實體時就跳過,直到找到期望的鍵值對或空的單元,抑或回到查找開始的單元; - 對于
__setitem__:
5. 負載系數和再哈希
負載系數
負載系數 λ = n / N \lambda={\left. n\middle/ N\right.} λ=n/N會極大地影響哈希表的操作效率,因為:
對于使用分離鏈接法處理哈希碰撞的哈希表,當 λ \lambda λ非常接近1時,發生哈希碰撞的幾率就會大大增加,這會降低后續操作的效率,因此實驗表明這種哈希表的的負載系數應滿足 λ < 0.9 \lambda\lt0.9 λ<0.9,
對于使用線性查找法處理哈希碰撞的哈希表,實驗證明當 λ \lambda λ從0.5開始接近1時,鍵值對將在哈希表一系列連續單元處發生簇集,此時也會降低后續操作的效率,因此實驗表明這種哈希表的負載系數應滿足 λ < 0.5 \lambda\lt0.5 λ<0.5,
再哈希
為了保持哈希表的負載系數在合理范圍內,當插入鍵值對后導致負載系數超過某范圍,則通常的做法都是先擴充哈希表的容量以降低負載系數,然后重新將所有鍵值對插入擴充后的哈希表中,這個程序就叫做再哈希,
實際上,由于哈希函式被分為兩個部分,而第一部分計算哈希碼的程序和哈希表的容量無關,因此再哈希時只需要通過壓縮函式計算處最終的哈希值(代表鍵值對應該保存的哈希表單元的索引)即可,
二、哈希表實作映射
根據使用的哈希函式在產生哈希碰撞時是采用分離鏈接法還是線性查找法處理,下面給出兩種基于哈希表實作的兩個映射類,
1. 基于哈希表實作映射的基類HashMapBase
雖然處理哈希碰撞的兩種策略各異,但是通過二者實作的映射依然具有很多共通之處,為此這里先將映射基類MapBase進行擴充得到HashMapBase,具體地:
- 映射中的鍵值對的哈希表用串列來表示,即映射中有
self._table實體屬性,且所有單元初始化為None; - 映射中的鍵值對數量使用實體屬性
self._n來表示; - 如果哈希表的負載系數超過0.5,則倍增哈希表容量且通過再哈希將所有鍵值對轉到新的哈希表中;
- 定義了一個新的實用方法
_hash_function(),該方法基于Python內建的函式hash()先計算出一個哈希碼,然后實用本文介紹的MAD方法作為壓縮函式,
擴充后的基類HashMapBase中留待具體子類實作的是如何表示哈希表的每一個單元,對于分離鏈接法,一個單元是一個二級容器(如:串列、鏈表等);對于線性查找法,單元的含義不一定是哈希表一個索引代表的位置,有可能是幾個索引代表的位置,
因此,這里的HashMapBase類假定下列方法為抽象方法,留待具體子類實作:
_bucket_getitem(j, k):根據鍵 k k k的哈希值 j j j搜索第 j j j個單元處鍵為 k k k的鍵值對,回傳找到的鍵值對,否則拋出KeyError例外;_bucket_setitem(j, k, v):根據鍵 k k k的哈希值 j j j修改第 j j j個單元處鍵為 k k k的鍵值對,如果鍵 k k k已存在則修改已有的值,否則插入新的鍵值對然后為self._n加一;_bucket_delitem(j, k):根據鍵 k k k的哈希值 j j j洗掉第 j j j個單元處鍵為 k k k的鍵值對并將self._n減一,如不存在該鍵值對則拋出KeyError例外,
__init__
def __init__(self, cap=11, p=109345121):
"""創建一個空的映射"""
self._table = cap * [None]
self._n = 0
self._prime = p # MAD壓縮函式中大于哈希表容量的大質數
self._scale = 1 + randrange(p-1) # MAD壓縮函式中的縮放系數a
self._shift = randrange(p) # MAD壓縮函式中的負載系數b
_hash_function
根據下列公式計算哈希值:
[ ( a i + b ) m o d p ] m o d N [(ai+b) \ mod \ p] \ mod \ N [(ai+b) mod p] mod N
def _hash_function(self, k):
"""哈希函式"""
return (self._scale * hash(k) + self._shift) % self._prime % len(self._table)
__len__
def __len__(self):
return self._n
__getitem__
def __getitem__(self, k):
j = self._hash_function(k)
return self._bucket_getitem(j, k) # 可能拋出KeyError例外
__setitem__
def __setitem__(self, k, v):
j = self._hash_function(k)
self._bucket_setitem(j, k, v)
if self._n > len(self._table) // 2: # 確保負載系數小于0.5
self._resize(2 * len(self._table) - 1) # 通常2 * n - 1為質數
def _resize(self, cap):
"""將哈希表容量調整為cap"""
old = list(self.items()) # 通過迭代獲得已有的所有鍵值對
self._table = cap * [None]
self._n = 0
for k, v in old:
self[k] = v # 將鍵值對重新插入新的哈希表中
需要注意的是,items()方法來源于繼承鏈上的Mapping類,在Mapping類中該方法的回傳值是ItemsView(self)(self是一個映射物件),
而ItemsView的初始化方法直接繼承自MappingView,因此映射物件用以初始化ItemsView的實體,因為其初始化方法具體為:
def __init__(self, mapping):
self._mapping = mapping
因此,ItemsView有一個實體屬性_mapping為映射實體物件,而ItemsView的實體又是一個迭代器物件,因為其中的__iter__方法使用yield (key, self._mapping[key]),
__delitem__
def __delitem__(self, k):
j = self._hash_function(k)
self._bucket_delitem(j, k) # 可能拋出KeyError例外
self._n -= 1
2. 基于分離鏈接法實作的映射ChainHashMap
下面先給出基于分離鏈接法處理哈希碰撞實作的映射類ChainHashMap,在其下面實作的前三個方法均使用索引j來訪問哈希表的某單元處,且檢查該單元處是否為空(即參考None),只有在呼叫_bucket_setitem且當該單元處為空時才需要使之參考一個二級容器(這里使用的是基于普通串列實作的映射UnsortedListMap的的實體),
_bucket_getitem(j, k)
def _bucket_getitem(self, j, k):
bucket = self._table[j]
if bucket is None:
raise KeyError('Key Error: ' + repr(k))
return bucket[k]
_bucket_setitem(j, k, v)
需要注意的是,當鍵k對應的鍵值對第一次插入映射中時,需要將映射中鍵值對的數量加一,
def _bucket_setitem(self, j, k, v):
if self._table[j] is None:
self._table[j] = UnsortedListMap() # 使得哈希表該單元處參考一個二級容器
oldsize = len(self._table[j])
self._table[j][k] = v
if len(self._table[j]) > oldsize: # k為新的鍵
self._n += 1
_bucket_delitem(j, k)
def _bucket_delitem(self, j, k):
bucket = self._table[j]
if bucket is None:
raise KeyError('Key Error: ' + repr(k))
del bucket[k]
__iter__()
需要注意的是,映射物件的每一個非空單元處都參考了一個二級容器,這里使用的二級容器是UnsortedListMap,其是一個迭代器,
def __iter__(self):
for bucket in self._table:
if bucket is not None:
for key in bucket:
yield key
3. 基于線性查找法實作的映射ProbeHashMap
_is_available(j)
def _is_available(self, j):
"""當哈希表索引為j的單元處為慷訓鍵值對被洗掉,則回傳True"""
return self._table[j] is None or self._table[j] is ProbeHashMap._AVAIL
_find_slot(j, k)
def _find_slot(self, j, k):
"""查找索引為j的哈希表單元處是否有鍵k
該方法的回傳值為一個元組,且回傳的情況如下:
- 當在索引為j的哈希表單元處找到鍵k,則回傳(True, fisrt_avail);
- 當未在哈希表任何單元處找到鍵k,則回傳(False, j),
"""
first_avail = None
while True:
if self._is_available(j):
if first_avail is None:
first_avail = j
if self._table[j] is None:
return False, first_avail
elif k == self._table[j].key:
return True, j
j = (j + 1) % len(self._table)
_bucket_getitem(j, k)
def _bucket_getitem(self, j, k):
found, s = self._find_slot(j, k)
if not found:
raise KeyError('Key Error: ' + repr(k))
return self._table[s].value
_bucket_setitem(j, k, v)
def _bucket_setitem(self, j, k, v):
found, s = self._find_slot(j, k)
if not found:
self._table[s] = self._Item(k, v)
self._n += 1
else:
self._table[s].value = v
_bucket_delitem(j, k)
def _bucket_delitem(self, j, k):
found, s = self._find_slot(j, k)
if not found:
raise KeyError('Key Error: ' + repr(k))
self._table[s] = ProbeHashMap._AVAIL
__iter__()
def __iter__(self):
for j in range(len(self._table)):
if not self._is_available(j):
yield self._table[j].key
三、哈希表實作映射的效率
| 操作 | 基于普通串列的效率 | 基于哈希表的期望效率 | 基于哈希表的最壞效率 |
|---|---|---|---|
__getitem__ | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
__setitem__ | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
__delitem__ | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
__len__ | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) |
__iter__ | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) |
四、哈希表實作映射的測驗代碼
from abc import ABC, abstractmethod
from collections.abc import MutableMapping
from random import randrange
class MapBase(MutableMapping, ABC):
"""提供用于保存鍵值對記錄類的自定義映射基類"""
class _Item:
__slots__ = 'key', 'value'
def __init__(self, key, value):
self.key = key
self.value = value
def __eq__(self, other):
return self.key == other.key # 使用'=='語法基于鍵比較兩個鍵值對是否相等
def __ne__(self, other):
return not (self == other) # 使用'!='語法基于鍵比較兩個鍵值對是否不等
def __lt__(self, other):
return self.key < other.key # 使用'<'語法基于鍵比較兩個鍵值對
class UnsortedListMap(MapBase):
def __init__(self):
"""創建一個空的映射物件"""
self._table = [] # 映射中的鍵值對記錄保存在串列中
def __getitem__(self, key):
"""回傳與鍵key關聯的值value,當鍵key不存在則拋出KeyError例外"""
for item in self._table:
if key == item.key:
return item.value
raise KeyError('key error: ', repr(key))
def __setitem__(self, key, value):
"""將key-value添加至映射物件中,當存在鍵值key時將其值替換為value"""
for item in self._table: # 遍歷查詢映射中是否存在鍵key
if key == item.key:
item.value = value
return
self._table.append(self._Item(key, value)) # 映射中不存在鍵key
def __delitem__(self, key):
"""洗掉鍵key代表的鍵值對,當鍵key不存在則拋出KeyError例外"""
for j in range(len(self._table)): # 遍歷查詢映射中是否存在鍵key
if key == self._table[j].key:
self._table.pop(j)
return
raise KeyError('key error: ', repr(key)) # 映射中不存在鍵key
def __len__(self):
"""回傳映射中鍵值對數量"""
return len(self._table)
def __iter__(self):
"""生成一個映射中所有鍵的迭代"""
for item in self._table:
yield item.key
def __str__(self):
"""回傳映射物件的字串表示形式"""
return str(dict(self.items()))
class HashMapBase(MapBase):
"""使用哈希表實作映射的基類"""
def __init__(self, cap=11, p=109345121):
"""創建一個空的映射"""
self._table = cap * [None]
self._n = 0
self._prime = p # MAD壓縮函式中大于哈希表容量的大質數
self._scale = 1 + randrange(p-1) # MAD壓縮函式中的縮放系數a
self._shift = randrange(p) # MAD壓縮函式中的便宜系數b
def _hash_function(self, k):
"""哈希函式"""
return (self._scale * hash(k) + self._shift) % self._prime % len(self._table)
@abstractmethod
def _bucket_getitem(self, j, k):
pass
@abstractmethod
def _bucket_setitem(self, j, k, v):
pass
@abstractmethod
def _bucket_delitem(self, j, k):
pass
def __len__(self):
return self._n
def __getitem__(self, k):
j = self._hash_function(k)
return self._bucket_getitem(j, k) # 可能拋出KeyError例外
def __setitem__(self, k, v):
j = self._hash_function(k)
self._bucket_setitem(j, k, v)
if self._n > len(self._table) // 2: # 確保負載系數小于0.5
self._resize(2 * len(self._table) - 1) # 通常2 * n - 1為質數
def __delitem__(self, k):
j = self._hash_function(k)
self._bucket_delitem(j, k) # 可能拋出KeyError例外
self._n -= 1
def _resize(self, cap):
"""將哈希表容量調整為cap"""
old = list(self.items()) # 通過迭代獲得已有的所有鍵值對
self._table = cap * [None]
self._n = 0
for k, v in old:
self[k] = v # 將鍵值對重新插入新的哈希表中
class ChainHashMap(HashMapBase):
"""使用分離鏈接法處理哈希碰撞實作的哈希映射"""
def _bucket_getitem(self, j, k):
bucket = self._table[j]
if bucket is None:
raise KeyError('Key Error: ' + repr(k))
return bucket[k]
def _bucket_setitem(self, j, k, v):
if self._table[j] is None:
self._table[j] = UnsortedListMap() # 使得哈希表該單元處參考一個二級容器
oldsize = len(self._table[j])
self._table[j][k] = v
if len(self._table[j]) > oldsize: # k為新的鍵
self._n += 1
def _bucket_delitem(self, j, k):
bucket = self._table[j]
if bucket is None:
raise KeyError('Key Error: ' + repr(k))
del bucket[k]
def __iter__(self):
for bucket in self._table:
if bucket is not None:
for key in bucket:
yield key
class ProbeHashMap(HashMapBase):
"""使用線性查找法處理哈希碰撞實作的哈希映射"""
_AVAIL = object() # 哨兵標識,用于標識被鍵值對被洗掉的哈希表單元
def _is_available(self, j):
"""當哈希表索引為j的單元處為慷訓鍵值對被洗掉,則回傳True"""
return self._table[j] is None or self._table[j] is ProbeHashMap._AVAIL
def _find_slot(self, j, k):
"""查找索引為j的哈希表單元處是否有鍵k
該方法的回傳值為一個元組,且回傳的情況如下:
- 當在索引為j的哈希表單元處找到鍵k,則回傳(True, fisrt_avail);
- 當未在哈希表任何單元處找到鍵k,則回傳(False, j),
"""
first_avail = None
while True:
if self._is_available(j):
if first_avail is None:
first_avail = j
if self._table[j] is None:
return False, first_avail
elif k == self._table[j].key:
return True, j
j = (j + 1) % len(self._table)
def _bucket_getitem(self, j, k):
found, s = self._find_slot(j, k)
if not found:
raise KeyError('Key Error: ' + repr(k))
return self._table[s].value
def _bucket_setitem(self, j, k, v):
found, s = self._find_slot(j, k)
if not found:
self._table[s] = self._Item(k, v)
self._n += 1
else:
self._table[s].value = v
def _bucket_delitem(self, j, k):
found, s = self._find_slot(j, k)
if not found:
raise KeyError('Key Error: ' + repr(k))
self._table[s] = ProbeHashMap._AVAIL
def __iter__(self):
for j in range(len(self._table)):
if not self._is_available(j):
yield self._table[j].key
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/206276.html
標籤:其他