簡介
本文通過 Pytorch 實作 GCN 對 Cora 資料集進行節點分類,
資料集說明
Cora 是一個引文關系資料集,由 2708 篇論文以及它們之間的參考關系構成邊形成一個圖(Graph),這些論文按照主題被分為了 7 類,分別為神經網路、強化學習、規則學習、概率方法、遺傳演算法、理論研究和案例相關,每篇論文的特征通過詞袋模型獲得,維度為 1433,每一維代表一個詞, 1 1 1表示該詞在該文章中出現, 0 0 0表示未出現,
資料預處理
首先是下載 Cora 原始資料集,這里由于外網訪問的原因,我已經將原始資料集和本文代碼處理過的資料集上傳到BaiduNetDisk,code:zczc,將該資料集下解壓后放到 dataset 目錄下即可,
獲得原始資料集之后,對其進行處理,得到一個命名元組,該元組包含以下內容:
x: 所有節點的特征,shape為(2708, 1433)
y: 所有節點的label,shape為(2708, )
adjacency: 所有節點的鄰接矩陣,shape為(2708, 2708),這里采用稀疏矩陣存盤
train_mask: 訓練集掩碼向量,shape為(2708, )屬于訓練集的位置值為True,否則False,共140個
val_mask: 訓練集掩碼向量,shape為(2708, )屬于驗證集的位置值為True,否則False,500
test_mask: 訓練集掩碼向量,shape為(2708, )屬于測驗集的位置值為True,否則False,共1000個
Cora 資料集由于比較小,這里沒有采取分批讀取的思路,而是讀出來之后再分批取,這樣因為沒有了本地 IO 會大大提高效率,這部分由于代碼比較瑣碎,就不列出了,可以通過文末Github訪問倉庫原始碼,
GCN 模型
根據GCN的定義 X ′ = σ ( L ~ s y m X W ) X' = \sigma(\widetilde{L}_{sym} X W) X′=σ(L sym?XW)來定義GCN層,然后堆疊三層GCN層構建圖卷積網路,原始碼如下,
class GraphConvolution(nn.Module):
def __init__(self, input_dim, output_dim, use_bias=True):
"""
L*X*\theta
:param input_dim: 節點輸入特征維度
:param output_dim: 輸出特征維度
:param use_bias: 是否偏置
"""
super(GraphConvolution, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.use_bias = use_bias
self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim))
if self.use_bias:
self.bias = nn.Parameter(torch.Tensor(output_dim))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
if self.use_bias:
init.zeros_(self.bias)
def forward(self, adjacency, input_feature):
support = torch.mm(input_feature, self.weight)
output = torch.sparse.mm(adjacency, support)
if self.use_bias:
output += self.bias
return output
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.input_dim) + ' -> ' + str(self.output_dim) + ')'
class GCN(nn.Module):
def __init__(self, input_dim=1433):
"""
兩層GCN模型
:param input_dim: 輸入維度
"""
super(GCN, self).__init__()
self.gcn1 = GraphConvolution(input_dim, 256)
self.gcn2 = GraphConvolution(256, 64)
self.gcn3 = GraphConvolution(64, 7)
def forward(self, adjacency, feature):
h = F.relu(self.gcn1(adjacency, feature))
logits = self.gcn2(adjacency, h)
return logits
訓練及其可視化
利用Cora資料集進行訓練,訓練代碼如下,由于Cora很小,這里就直接全集進行訓練,
from collections import namedtuple
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from dataset import CoraData
from model import GCN
# hyper params
LEARNING_RATE = 0.1
WEIGHT_DACAY = 5e-4
EPOCHS = 50
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
Data = namedtuple('Data', ['x', 'y', 'adjacency', 'train_mask', 'val_mask', 'test_mask'])
# 加載資料,并轉換為torch.Tensor
dataset = CoraData().data
node_feature = dataset.x / dataset.x.sum(1, keepdims=True) # 歸一化資料,使得每一行和為1
tensor_x = torch.from_numpy(node_feature).to(DEVICE)
tensor_y = torch.from_numpy(dataset.y).to(DEVICE)
tensor_train_mask = torch.from_numpy(dataset.train_mask).to(DEVICE)
tensor_val_mask = torch.from_numpy(dataset.val_mask).to(DEVICE)
tensor_test_mask = torch.from_numpy(dataset.test_mask).to(DEVICE)
normalize_adjacency = CoraData.normalization(dataset.adjacency) # 規范化鄰接矩陣
num_nodes, input_dim = node_feature.shape
indices = torch.from_numpy(np.asarray([normalize_adjacency.row, normalize_adjacency.col]).astype('int64')).long()
values = torch.from_numpy(normalize_adjacency.data.astype(np.float32))
tensor_adjacency = torch.sparse.FloatTensor(indices, values, (num_nodes, num_nodes)).to(DEVICE)
# 模型定義:Model, Loss, Optimizer
model = GCN(input_dim).to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=WEIGHT_DACAY)
def train():
model.train()
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_loss_history = []
train_y = tensor_y[tensor_train_mask]
for epoch in range(EPOCHS):
logits = model(tensor_adjacency, tensor_x) # 前向傳播
train_mask_logits = logits[tensor_train_mask] # 只選擇訓練節點進行監督
loss = criterion(train_mask_logits, train_y) # 計算損失值
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc, _, _, train_loss = test(tensor_train_mask, tensor_y)
val_acc, _, _, val_loss = test(tensor_val_mask, tensor_y)
train_loss_history.append(loss.item())
train_acc_history.append(train_acc)
val_loss_history.append(val_loss)
val_acc_history.append(val_acc.item())
print("epoch {:03d}: training loss {:.4f}, training acc {:.4}, validation acc {:.4f}".format(epoch, loss.item(),
train_acc.item(),
val_acc.item()))
return train_loss_history, train_acc_history, val_loss_history, val_acc_history
def test(mask, y):
model.eval()
with torch.no_grad():
logits = model(tensor_adjacency, tensor_x)
test_mask_logits = logits[mask]
loss = criterion(test_mask_logits, y[mask])
predict_y = test_mask_logits.max(1)[1]
accuarcy = torch.eq(predict_y, tensor_y[mask]).float().mean()
return accuarcy, test_mask_logits.cpu().numpy(), tensor_y[mask].cpu().numpy(), loss
def plot_loss_with_acc(train_loss_history, train_acc_history, val_loss_history, val_acc_history):
plt.figure(figsize=(12, 8))
plt.plot(range(len(train_loss_history)), train_loss_history, c=np.array([255, 71, 90]) / 255.,
label='training loss')
plt.plot(range(len(val_loss_history)), val_loss_history, c=np.array([120, 80, 90]) / 255.,
label='validation loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc=0)
plt.title('loss')
plt.savefig("../assets/loss.png")
plt.show()
plt.figure(figsize=(12, 8))
plt.plot(range(len(train_acc_history)), train_acc_history, c=np.array([255, 71, 90]) / 255.,
label='training acc')
plt.plot(range(len(val_acc_history)), val_acc_history, c=np.array([120, 80, 90]) / 255.,
label='validation acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc=0)
plt.title('accuracy')
plt.savefig("../assets/acc.png")
plt.show()
train_loss, train_acc, val_loss, val_acc = train()
test_acc, test_logits, test_label, _ = test(tensor_test_mask, tensor_y)
print("Test accuarcy: ", test_acc.item())
plot_loss_with_acc(train_loss, train_acc, val_loss, val_acc)
# tsne visualize
tsne = TSNE()
out = tsne.fit_transform(test_logits)
fig = plt.figure()
for i in range(7):
indices = test_label == i
x, y = out[indices].T
plt.scatter(x, y, label=str(i))
plt.legend(loc=0)
plt.savefig('tsne.png')
plt.show()
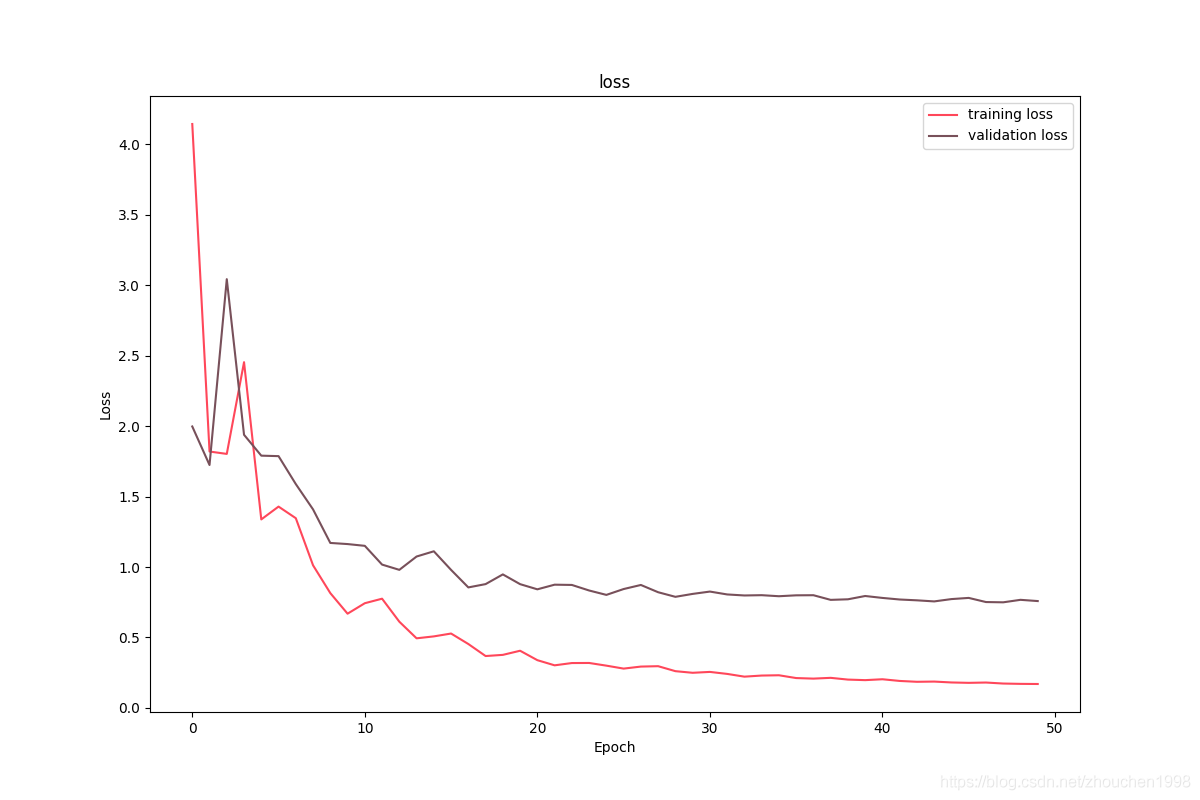
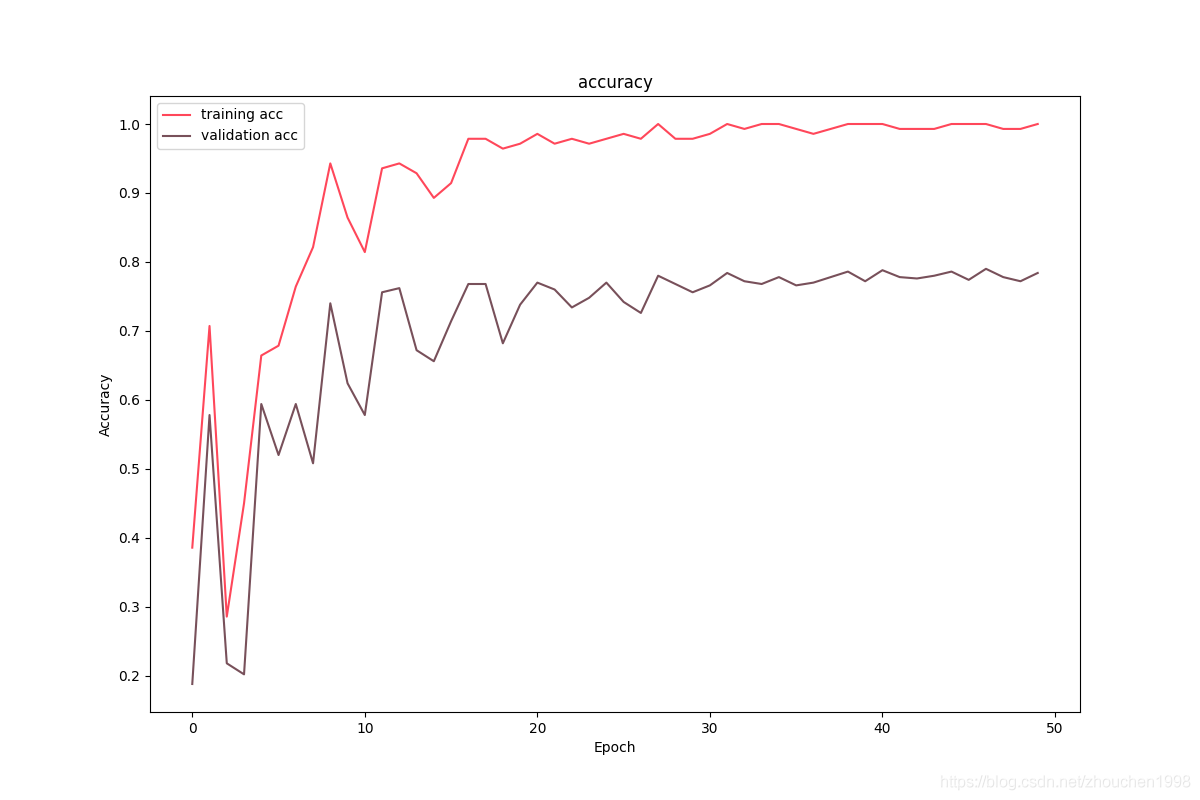
訓練程序的可視化如下面兩張圖,分別是訓練集和驗證集上的loss變化和訓練集和驗證集上的準確率變化,可以看到,訓練集損失很快下降且準確率到達1,驗證集也很快收斂準確率在0.8左右,這也說明,三層GCN的建模能力雖然不錯但也很有限,
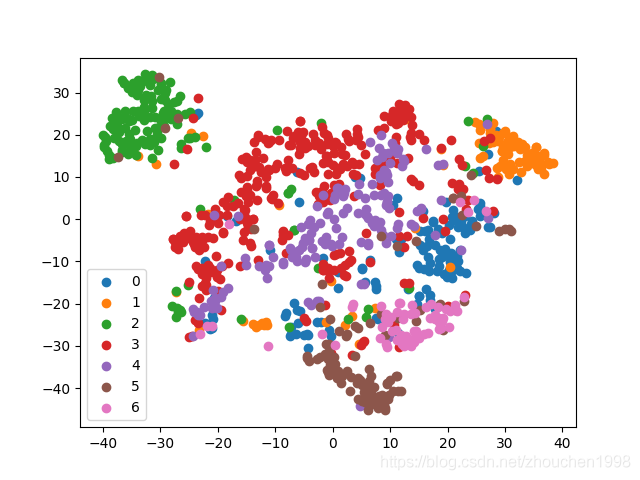
同時,通過TSNE將輸出層的score嵌入進行二維可視化,可以發現,區分度還是很高的,這表示GCN學到的特征其實是很有效的,
補充說明
本文資料處理部分思路參考自PyG框架以及《深入淺出圖神經網路》的內容,對圖網路理論感興趣的可以閱讀這本書,本文涉及到的代碼開源于 Github,歡迎 star 和 fork,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/206458.html
標籤:其他
上一篇:2020年1024活動Top50的博主名單總結分析,請為你喜歡的博主打Call!(精選文章整合)
下一篇:C語言資料結構——串(再學一次)