作者|THILAKADIBOINA
編譯|Flin
來源|analyticsvidhya
介紹
本文介紹了生成性對抗網路(Generative attersarial Networks,GAN)的使用,這是一種對真實的Covid-19資料進行過采樣的技術,用于預測死亡率,這個故事讓我們更好地理解資料準備步驟(如處理不平衡的資料)如何提高模型性能,
本文的資料和核心模型來自Celestine Iwendi、Ali Kashif Bashir、Atharva Peshkar最近的一項研究(2020年7月)“使用增強隨機森林演算法預測COVID-19患者健康”,本研究使用ADABOST模型增強的隨機森林演算法預測個體患者的死亡率,準確率為94%,本文考慮相同的模型和模型引數,明確分析了采用基于GAN的過采樣技術對現有模型的改進,
對于有抱負的資料科學家來說,學習良好實踐的最好方法之一就是參加不同論壇上的黑客競賽,比如Vidhya、Kaggle或其他論壇,
此外,從這些論壇或出版的研究出版物中獲取已解決的案例和資料;了解他們的方法,并嘗試通過額外的步驟來提高準確性或減少誤差,這將形成一個堅實的基礎,使我們能夠深入思考我們在資料科學價值鏈中所學的其他技術的應用,
研究中使用的資料是用222個病人的13個特征來訓練的,資料有偏差,159例(72%)屬于“0”類或“已恢復”類,由于其偏差性質,各種欠采樣/過采樣技術可應用于資料,偏態資料的問題會導致預測模型的過度擬合,
為了克服這一局限性,許多研究采用過采樣方法來平衡資料集,從而得到更精確的模型訓練,過采樣是一種通過增加少數資料中的樣本數量來補償資料集不平衡的技術,
常規方法包括隨機過采樣(ROS)、合成少數過采樣技術(SMOTE)等,有關使用常規方法處理不平衡類的更多資訊,請參閱:
- https://www.analyticsvidhya.com/blog/2020/07/10-techniques-to-deal-with-class-imbalance-in-machine-learning/
最近,一種基于對抗性學習概念的生成性網路的機器學習模型被提出,即生成性對抗性網路,生成性對抗網路(Generative atterial Networks,GAN)的特點使其較易應用于過采樣研究,因為基于對抗訓練的神經網路的性質允許生成與原始資料相似的人工資料,基于生成性對抗網路的過采樣克服了傳統方法(如過擬合)的局限性,允許建立一個高精度的不平衡資料預測模型,
如何生成合成資料?
兩個神經網路相互競爭,學習目標分布并生成人工資料
發生器網路G:模擬訓練樣本欺騙鑒別器
判別網路D:判別訓練樣本和生成樣本
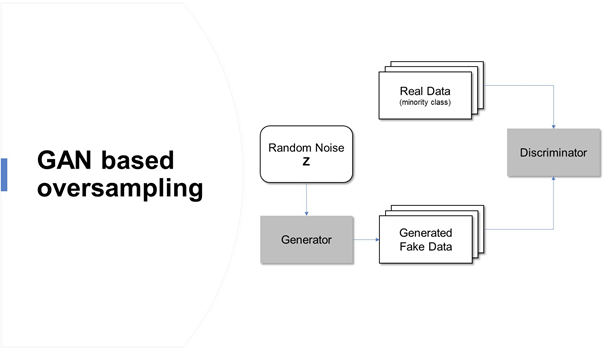
生成性對抗性網路是基于博弈論的場景,其中生成網路必須與對手競爭,隨著GAN學會模擬資料的分布,它被應用于各個領域,如音樂、視頻和自然語言,最近還用于處理不平衡的資料問題,
研究中使用的資料和基本模型可以在這里找到
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, BatchNormalization, Embedding
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.merge import concatenate
from keras.models import Sequential, Model
from keras.optimizers import Adam
from keras.utils import to_categorical
from keras.layers.advanced_activations import LeakyReLU
from keras.utils.vis_utils import plot_model
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder, LabelEncoder
import scipy.stats
import datetime as dt
import pydot
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
df = pd.read_csv('Covid_Train_Oct32020.csv')
df = df.drop('id',axis=1)
df = df.fillna(np.nan,axis=0)
df['age'] = df['age'].fillna(value=https://www.cnblogs.com/panchuangai/archive/2020/11/08/df['age'].mean())
df['sym_on'] = pd.to_datetime(df['sym_on'])
df['hosp_vis'] = pd.to_datetime(df['hosp_vis'])
df['sym_on']= df['sym_on'].map(dt.datetime.toordinal)
df['hosp_vis']= df['hosp_vis'].map(dt.datetime.toordinal)
df['diff_sym_hos']= df['hosp_vis'] - df['sym_on']
df=df.drop(['sym_on', 'hosp_vis'], axis=1)
df['location'] = df['location'].astype(str)
df['country'] = df['country'].astype(str)
df['gender'] = df['gender'].astype(str)
df['vis_wuhan'] = df['vis_wuhan'].astype(str)
df['from_wuhan'] = df['from_wuhan'].astype(str)
df['symptom1'] = df['symptom1'].astype(str)
df['symptom2'] = df['symptom2'].astype(str)
df['symptom3'] = df['symptom3'].astype(str)
df['symptom4'] = df['symptom4'].astype(str)
df['symptom5'] = df['symptom5'].astype(str)
df['symptom6'] = df['symptom6'].astype(str)
df.dtypes
資料說明
| 列 | 描述 | 值(用于分類變數) | 型別 |
| id | 患者編號 | 不適用 | 數字 |
| location | 患者所屬的位置 | 遍布全球的多個城市 | 字串,分類 |
| country | 患者的國家 | 多個國家 | 字串,分類 |
| gender | 患者性別 | 男,女 | 字串,分類 |
| age | 患者年齡 | 不適用 | 數字 |
| sym_on | 患者開始注意到癥狀的日期 | 不適用 | 日期 |
| hosp_vis | 病人去醫院的日期 | 不適用 | 日期 |
| vis_wuhan | 患者是否去過中國武漢 | 是(1),否(0) | 數值,分類 |
| from_wuhan | 患者是否屬于中國武漢 | 是(1),否(0) | 數值,分類 |
| death | 患者是否因COVID-19而去世 | 是(1),否(0) | 數值,分類 |
| Recov | 患者是否康復 | 是(1),否(0) | 數值,分類 |
| symptom1. symptom2, symptom3, symptom4, symptom5, symptom6 | 患者注意到的癥狀 | 患者注意到多種癥狀 | 字串,分類 |
該研究考慮了11個分類輸入特征和2個數字輸入特征,目標變數是死亡/恢復,已填充新列“ diff_sym_hos”,以提供當天在醫院發現和接受的癥狀之間的差異,
研究的重點是改善少數類別資料,即死亡== 1,從訓練資料中提取了一個子集,子集按類別和數字分開,并傳遞給GAN模型,
df_minority_data=https://www.cnblogs.com/panchuangai/archive/2020/11/08/df.loc[df['death'] == 1]
#Subsetting input features without target variable
df_minority_data_withouttv=df_minority_data.loc[:, df_minority_data.columns != 'death']
numerical_df = df_minority_data_withouttv.select_dtypes("number")
categorical_df = df_minority_data_withouttv.select_dtypes("object")
scaling = MinMaxScaler()
numerical_df_rescaled = scaling.fit_transform(numerical_df)
get_dummy_df = pd.get_dummies(categorical_df)
#Seperating Each Category
location_dummy_col = [col for col in get_dummy_df.columns if 'location' in col]
location_dummy = get_dummy_df[location_dummy_col]
country_dummy_col = [col for col in get_dummy_df.columns if 'country' in col]
country_dummy = get_dummy_df[country_dummy_col]
gender_dummy_col = [col for col in get_dummy_df.columns if 'gender' in col]
gender_dummy = get_dummy_df[gender_dummy_col]
vis_wuhan_dummy_col = [col for col in get_dummy_df.columns if 'vis_wuhan' in col]
vis_wuhan_dummy = get_dummy_df[vis_wuhan_dummy_col]
from_wuhan_dummy_col = [col for col in get_dummy_df.columns if 'from_wuhan' in col]
from_wuhan_dummy = get_dummy_df[from_wuhan_dummy_col]
symptom1_dummy_col = [col for col in get_dummy_df.columns if 'symptom1' in col]
symptom1_dummy = get_dummy_df[symptom1_dummy_col]
symptom2_dummy_col = [col for col in get_dummy_df.columns if 'symptom2' in col]
symptom2_dummy = get_dummy_df[symptom2_dummy_col]
symptom3_dummy_col = [col for col in get_dummy_df.columns if 'symptom3' in col]
symptom3_dummy = get_dummy_df[symptom3_dummy_col]
symptom4_dummy_col = [col for col in get_dummy_df.columns if 'symptom4' in col]
symptom4_dummy = get_dummy_df[symptom4_dummy_col]
symptom5_dummy_col = [col for col in get_dummy_df.columns if 'symptom5' in col]
symptom5_dummy = get_dummy_df[symptom5_dummy_col]
symptom6_dummy_col = [col for col in get_dummy_df.columns if 'symptom6' in col]
symptom6_dummy = get_dummy_df[symptom6_dummy_col]

定義生成器
生成器從潛在空間獲取輸入并生成新的合成樣本,泄露修正線性單元(LeakyReLU)是在發生器和鑒別器模型中用于處理某些負值的函式,
它使用默認建議值0.2和適當的權重初始化程式“ he_uniform”使用,此外,在不同的層之間使用批處理歸一化來標準化來自先前層的激活(零均值和單位方差)并穩定訓練程序,
在輸出層中,softmax激活函式用于分類變數,而sigmoid 函式用于連續變數,
def define_generator (catsh1,catsh2,catsh3,catsh4,catsh5,catsh6,catsh7,catsh8,catsh9,catsh10,catsh11,numerical):
#Inputting noise from latent space
noise = Input(shape = (70,))
hidden_1 = Dense(8, kernel_initializer = "he_uniform")(noise)
hidden_1 = LeakyReLU(0.2)(hidden_1)
hidden_1 = BatchNormalization(momentum = 0.8)(hidden_1)
hidden_2 = Dense(16, kernel_initializer = "he_uniform")(hidden_1)
hidden_2 = LeakyReLU(0.2)(hidden_2)
hidden_2 = BatchNormalization(momentum = 0.8)(hidden_2)
#Branch 1 for generating location data
branch_1 = Dense(32, kernel_initializer = "he_uniform")(hidden_2)
branch_1 = LeakyReLU(0.2)(branch_1)
branch_1 = BatchNormalization(momentum = 0.8)(branch_1)
branch_1 = Dense(64, kernel_initializer = "he_uniform")(branch_1)
branch_1 = LeakyReLU(0.2)(branch_1)
branch_1 = BatchNormalization(momentum=0.8)(branch_1)
#Output Layer1
branch_1_output = Dense(catsh1, activation = "softmax")(branch_1)
#Likewise, for all remaining 10 categories branches will be defined
#Branch 12 for generating numerical data
branch_12 = Dense(64, kernel_initializer = "he_uniform")(hidden_2)
branch_12 = LeakyReLU(0.2)(branch_3)
branch_12 = BatchNormalization(momentum=0.8)(branch_12)
branch_12 = Dense(128, kernel_initializer = "he_uniform")(branch_12)
branch_12 = LeakyReLU(0.2)(branch_12)
branch_12 = BatchNormalization(momentum=0.8)(branch_12)
#Output Layer12
branch_12_output = Dense(numerical, activation = "sigmoid")(branch_12)
#Combined output
combined_output = concatenate([branch_1_output, branch_2_output, branch_3_output,branch_4_output,branch_5_output,branch_6_output,branch_7_output,branch_8_output,branch_9_output,branch_10_output,branch_11_output,branch_12_output])
#Return model
return Model(inputs = noise, outputs = combined_output)
generator = define_generator(location_dummy.shape[1],country_dummy.shape[1],gender_dummy.shape[1],vis_wuhan_dummy.shape[1],from_wuhan_dummy.shape[1],symptom1_dummy.shape[1],symptom2_dummy.shape[1],symptom3_dummy.shape[1],symptom4_dummy.shape[1],symptom5_dummy.shape[1],symptom6_dummy.shape[1],numerical_df_rescaled.shape[1])
generator.summary()
定義鑒別器
鑒別器模型將從我們的資料(例如矢量)中獲取樣本,并輸出關于樣本是真實還是假的分類預測,這是一個二進制分類問題,因此在輸出層中使用sigmoid 激活函式,在模型編譯中使用二進制交叉熵損失函式,使用學習率LR為0.0002且建議的beta1動量值為0.5的Adam優化演算法,
def define_discriminator(inputs_n):
#Input from generator
d_input = Input(shape = (inputs_n,))
d = Dense(128, kernel_initializer="he_uniform")(d_input)
d = LeakyReLU(0.2)(d)
d = Dense(64, kernel_initializer="he_uniform")(d)
d = LeakyReLU(0.2)(d)
d = Dense(32, kernel_initializer="he_uniform")(d)
d = LeakyReLU(0.2)(d)
d = Dense(16, kernel_initializer="he_uniform")(d)
d = LeakyReLU(0.2)(d)
d = Dense(8, kernel_initializer="he_uniform")(d)
d = LeakyReLU(0.2)(d)
#Output Layer
d_output = Dense(1, activation = "sigmoid")(d)
#compile and return model
model = Model(inputs = d_input, outputs = d_output)
model.compile(loss = "binary_crossentropy", optimizer = Adam(lr=0.0002, beta_1=0.5), metrics = ["accuracy"])
return model
inputs_n = location_dummy.shape[1]+country_dummy.shape[1]+gender_dummy.shape[1]+vis_wuhan_dummy.shape[1]+from_wuhan_dummy.shape[1]+symptom1_dummy.shape[1]+symptom2_dummy.shape[1]+symptom3_dummy.shape[1]+symptom4_dummy.shape[1]+symptom5_dummy.shape[1]+symptom6_dummy.shape[1]+numerical_df_rescaled.shape[1]
discriminator = define_discriminator(inputs_n)
discriminator.summary()
將生成器和鑒別器組合為GAN模型并完成訓練,考慮了7,000個時期,并考慮了完整的少數派訓練資料,
Def define_complete_gan(generator, discriminator):
discriminator.trainable = False
gan_output = discriminator(generator.output)
#Initialize gan
model = Model(inputs = generator.input, outputs = gan_output)
#Model Compilation
model.compile(loss = "binary_crossentropy", optimizer = Adam(lr=0.0002, beta_1=0.5))
return model
completegan = define_complete_gan(generator, discriminator)
def gan_train(gan, generator, discriminator, catsh1,catsh2,catsh3,catsh4,catsh5,catsh6,catsh7,catsh8,catsh9,catsh10,catsh11,numerical, latent_dim, n_epochs, n_batch, n_eval):
#Upddte Discriminator with half batch size
half_batch = int(n_batch / 2)
discriminator_loss = []
generator_loss = []
#generate class labels for fake and real
valid = np.ones((half_batch, 1))
y_gan = np.ones((n_batch, 1))
fake = np.zeros((half_batch, 1))
#training
for i in range(n_epochs):
#select random batch from real categorical and numerical data
idx = np.random.randint(0, catsh1.shape[0], half_batch)
location_real = catsh1[idx]
country_real = catsh2[idx]
gender_real = catsh3[idx]
vis_wuhan_real = catsh4[idx]
from_wuhan_real = catsh5[idx]
symptom1_real = catsh6[idx]
symptom2_real = catsh7[idx]
symptom3_real = catsh8[idx]
symptom4_real = catsh9[idx]
symptom5_real = catsh10[idx]
symptom6_real = catsh11[idx]
numerical_real = numerical_df_rescaled[idx]
#concatenate categorical and numerical data for the discriminator
real_data = https://www.cnblogs.com/panchuangai/archive/2020/11/08/np.concatenate([location_real, country_real, gender_real,vis_wuhan_real,from_wuhan_real,symptom1_real,symptom2_real,symptom3_real,symptom4_real,symptom5_real,symptom6_real,numerical_real], axis = 1)
#generate fake samples from the noise
noise = np.random.normal(0, 1, (half_batch, latent_dim))
fake_data = generator.predict(noise)
#train the discriminator and return losses and acc
d_loss_real, da_real = discriminator.train_on_batch(real_data, valid)
d_loss_fake, da_fake = discriminator.train_on_batch(fake_data, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
discriminator_loss.append(d_loss)
#generate noise for generator input and train the generator (to have the discriminator label samples as valid)
noise = np.random.normal(0, 1, (n_batch, latent_dim))
g_loss = gan.train_on_batch(noise, y_gan)
generator_loss.append(g_loss)
#evaluate progress
if (i+1) % n_eval == 0:
print ("Epoch: %d [Discriminator loss: %f] [Generator loss: %f]" % (i + 1, d_loss, g_loss))
plt.figure(figsize = (20, 10))
plt.plot(generator_loss, label = "Generator loss")
plt.plot(discriminator_loss, label = "Discriminator loss")
plt.title("Stats from training GAN")
plt.grid()
plt.legend()
latent_dim = 100
gan_train(completegan, generator, discriminator, location_dummy.values,country_dummy.values,gender_dummy.values,vis_wuhan_dummy.values,from_wuhan_dummy.values,symptom1_dummy.values,symptom2_dummy.values,symptom3_dummy.values,symptom4_dummy.values,symptom5_dummy.values,symptom6_dummy.values,numerical_df_rescaled, latent_dim, n_epochs = 7000, n_batch = 63, n_eval = 200)
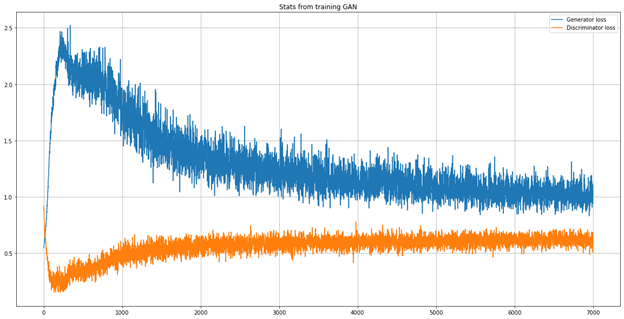
訓練后的模型用于生成少數類的其他96條記錄,以對每個類進行均等分割(159),現在將生成的數值資料與原始資料的均值,標準差和方差進行比較;并根據每個類別的計數比較類別資料,
noise = np.random.normal(0, 1, (96, 100))
generated_mixed_data = https://www.cnblogs.com/panchuangai/archive/2020/11/08/generator.predict(noise)
columns=list(location_dummy.columns)+list(country_dummy.columns)+list(gender_dummy.columns)+list(vis_wuhan_dummy.columns)+list(from_wuhan_dummy.columns)+list(symptom1_dummy.columns)+list(symptom2_dummy.columns)+list(symptom3_dummy.columns)+list(symptom4_dummy.columns)+list(symptom5_dummy.columns)+list(symptom6_dummy.columns)+list(numerical_df.columns)
mixed_gen_df = pd.DataFrame(data = generated_mixed_data, columns = columns)
mixed_gen_df.iloc[:,:-3] = np.round(mixed_gen_df.iloc[:,:-3])
mixed_gen_df.iloc[:,-2:] = scaling.inverse_transform(mixed_gen_df.iloc[:,-2:])
#Original Data
original_df = pd.concat([location_dummy,country_dummy,gender_dummy,vis_wuhan_dummy,from_wuhan_dummy,symptom1_dummy,symptom2_dummy,symptom3_dummy,symptom4_dummy,symptom5_dummy,symptom6_dummy,numerical_df], axis = 1)
def normal_distribution(org, noise):
org_x = np.linspace(org.min(), org.max(), len(org))
noise_x = np.linspace(noise.min(), noise.max(), len(noise))
org_y = scipy.stats.norm.pdf(org_x, org.mean(), org.std())
noise_y = scipy.stats.norm.pdf(noise_x, noise.mean(), noise.std())
n, bins, patches = plt.hist([org, noise], density = True, alpha = 0.5, color = ["green", "red"])
xmin, xmax = plt.xlim()
plt.plot(org_x, org_y, color = "green", label = "Original data", alpha = 0.5)
plt.plot(noise_x, noise_y, color = "red", label = "Generated data", alpha = 0.5)
title = f"Original data mean {np.round(org.mean(), 4)}, Original data std {np.round(org.std(), 4)}, Original data var {np.round(org.var(), 4)}\nGenerated data mean {np.round(noise.mean(), 4)}, Generated data {np.round(noise.std(), 4)}, Generated data var {np.round(noise.var(), 2)}"
plt.title(title)
plt.legend()
plt.grid()
plt.show()
Numeric_columns=numerical_df.columns
for column in numerical_df.columns:
print(column, "Comparison between Original Data and Generated Data")
normal_distribution(original_df
, mixed_gen_df
)
原始資料和生成資料之間的年齡比較
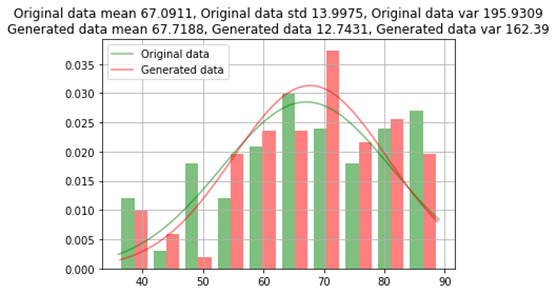
原始資料與生成的資料之間的比較
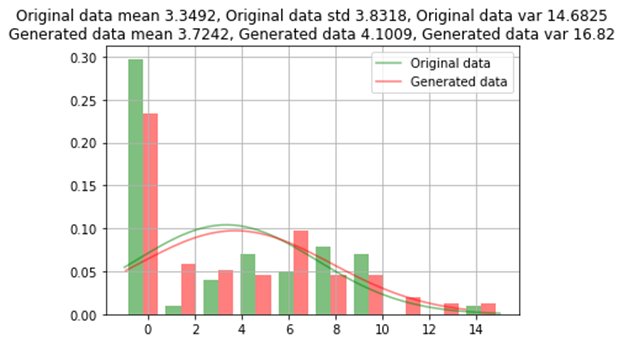
原始資料和生成的資料之間的類別比較
| 特征 | 原始資料 | 產生的資料 | ||
| 0 | 1 | 0 | 1 | |
| location_Hokkaido | 61 | 2 | 95 | 1 |
| gender_female | 49 | 14 | 60 | 36 |
| symptom2_ cough | 62 | 1 | 96 | 0 |
GAN過采樣方法生成的資料幾乎類似于原始資料,原始資料的誤差約為1%,對于一些稀有類別,不會在所有類別值上生成資料,
遵循與原始研究中提到的相同的資料準備步驟,以查看通過使用GAN超采樣與原始方法相比模型性能如何提高,所生成樣本的獨熱編碼資料被轉換為原始資料幀格式,
# Getting Back Categorical Data in Original_Format from Dummies
location_filter_col = [col for col in mixed_gen_df if col.startswith('location')]
location=mixed_gen_df[location_filter_col]
location= pd.get_dummies(location).idxmax(1)
location= location.replace('location_', '', regex=True)
df_generated_data = https://www.cnblogs.com/panchuangai/archive/2020/11/08/pd.DataFrame()
df_generated_data['location']=location
country_filter_col = [col for col in mixed_gen_df if col.startswith('country')]
country=mixed_gen_df[country_filter_col]
country= pd.get_dummies(country).idxmax(1)
country= country.replace('country_', '', regex=True)
df_generated_data['country']=country
gender_filter_col = [col for col in mixed_gen_df if col.startswith('gender')]
gender=mixed_gen_df[gender_filter_col]
gender= pd.get_dummies(gender).idxmax(1)
gender= gender.replace('gender_', '', regex=True)
df_generated_data['gender']=gender
vis_wuhan_filter_col = [col for col in mixed_gen_df if col.startswith('vis_wuhan')]
vis_wuhan=mixed_gen_df[vis_wuhan_filter_col]
vis_wuhan= pd.get_dummies(vis_wuhan).idxmax(1)
vis_wuhan= vis_wuhan.replace('vis_wuhan_', '', regex=True)
df_generated_data['vis_wuhan']=vis_wuhan
from_wuhan_filter_col = [col for col in mixed_gen_df if col.startswith('from_wuhan')]
from_wuhan=mixed_gen_df[from_wuhan_filter_col]
from_wuhan= pd.get_dummies(from_wuhan).idxmax(1)
from_wuhan= from_wuhan.replace('from_wuhan_', '', regex=True)
df_generated_data['from_wuhan']=from_wuhan
symptom1_filter_col = [col for col in mixed_gen_df if col.startswith('symptom1')]
symptom1=mixed_gen_df[symptom1_filter_col]
symptom1= pd.get_dummies(symptom1).idxmax(1)
symptom1= symptom1.replace('symptom1_', '', regex=True)
df_generated_data['symptom1']=symptom1
symptom2_filter_col = [col for col in mixed_gen_df if col.startswith('symptom2')]
symptom2=mixed_gen_df[symptom2_filter_col]
symptom2= pd.get_dummies(symptom2).idxmax(1)
symptom2= symptom2.replace('symptom2_', '', regex=True)
df_generated_data['symptom2']=symptom2
symptom3_filter_col = [col for col in mixed_gen_df if col.startswith('symptom3')]
symptom3=mixed_gen_df[symptom3_filter_col]
symptom3= pd.get_dummies(symptom3).idxmax(1)
symptom3= symptom3.replace('symptom3_', '', regex=True)
df_generated_data['symptom3']=symptom3
symptom4_filter_col = [col for col in mixed_gen_df if col.startswith('symptom4')]
symptom4=mixed_gen_df[symptom4_filter_col]
symptom4= pd.get_dummies(symptom4).idxmax(1)
symptom4= symptom4.replace('symptom4_', '', regex=True)
df_generated_data['symptom4']=symptom4
symptom5_filter_col = [col for col in mixed_gen_df if col.startswith('symptom5')]
symptom5=mixed_gen_df[symptom5_filter_col]
symptom5= pd.get_dummies(symptom5).idxmax(1)
symptom5= symptom5.replace('symptom5_', '', regex=True)
df_generated_data['symptom5']=symptom5
symptom6_filter_col = [col for col in mixed_gen_df if col.startswith('symptom6')]
symptom6=mixed_gen_df[symptom6_filter_col]
symptom6= pd.get_dummies(symptom6).idxmax(1)
symptom6= symptom6.replace('symptom6_', '', regex=True)
df_generated_data['symptom6']=symptom6
df_generated_data['death']=1
df_generated_data['death']=1
df_generated_data[['age','diff_sym_hos']]=mixed_gen_df[['age','diff_sym_hos']]
df_generated_data = https://www.cnblogs.com/panchuangai/archive/2020/11/08/df_generated_data.fillna(np.nan,axis=0)
#Encoding Data
encoder_location = preprocessing.LabelEncoder()
encoder_country = preprocessing.LabelEncoder()
encoder_gender = preprocessing.LabelEncoder()
encoder_symptom1 = preprocessing.LabelEncoder()
encoder_symptom2 = preprocessing.LabelEncoder()
encoder_symptom3 = preprocessing.LabelEncoder()
encoder_symptom4 = preprocessing.LabelEncoder()
encoder_symptom5 = preprocessing.LabelEncoder()
encoder_symptom6 = preprocessing.LabelEncoder()
# Loading and Preparing Data
df = pd.read_csv('Covid_Train_Oct32020.csv')
df = df.drop('id',axis=1)
df = df.fillna(np.nan,axis=0)
df['age'] = df['age'].fillna(value=https://www.cnblogs.com/panchuangai/archive/2020/11/08/tdata['age'].mean())
df['sym_on'] = pd.to_datetime(df['sym_on'])
df['hosp_vis'] = pd.to_datetime(df['hosp_vis'])
df['sym_on']= df['sym_on'].map(dt.datetime.toordinal)
df['hosp_vis']= df['hosp_vis'].map(dt.datetime.toordinal)
df['diff_sym_hos']= df['hosp_vis'] - df['sym_on']
df = df.drop(['sym_on','hosp_vis'],axis=1)
df['location'] = encoder_location.fit_transform(df['location'].astype(str))
df['country'] = encoder_country.fit_transform(df['country'].astype(str))
df['gender'] = encoder_gender.fit_transform(df['gender'].astype(str))
df[['symptom1']] = encoder_symptom1.fit_transform(df['symptom1'].astype(str))
df[['symptom2']] = encoder_symptom2.fit_transform(df['symptom2'].astype(str))
df[['symptom3']] = encoder_symptom3.fit_transform(df['symptom3'].astype(str))
df[['symptom4']] = encoder_symptom4.fit_transform(df['symptom4'].astype(str))
df[['symptom5']] = encoder_symptom5.fit_transform(df['symptom5'].astype(str))
df[['symptom6']] = encoder_symptom6.fit_transform(df['symptom6'].astype(str))
# Encoding Generated Data
df_generated_data['location'] = encoder_location.transform(df_generated_data['location'].astype(str))
df_generated_data['country'] = encoder_country.transform(df_generated_data['country'].astype(str))
df_generated_data['gender'] = encoder_gender.transform(df_generated_data['gender'].astype(str))
df_generated_data[['symptom1']] = encoder_symptom1.transform(df_generated_data['symptom1'].astype(str))
df_generated_data[['symptom2']] = encoder_symptom2.transform(df_generated_data['symptom2'].astype(str))
df_generated_data[['symptom3']] = encoder_symptom3.transform(df_generated_data['symptom3'].astype(str))
df_generated_data[['symptom4']] = encoder_symptom4.transform(df_generated_data['symptom4'].astype(str))
df_generated_data[['symptom5']] = encoder_symptom5.transform(df_generated_data['symptom5'].astype(str))
df_generated_data[['symptom6']] = encoder_symptom6.transform(df_generated_data['symptom6'].astype(str))
df_generated_data[['diff_sym_hos']] = df_generated_data['diff_sym_hos'].astype(int)
模型比較
將原始資料分為訓練和測驗后,將GAN生成的資料添加到訓練資料中,以將性能與基本模型進行比較,在實際(原始)分割測驗資料上測驗模型性能,
from sklearn.metrics import recall_score as rs
from sklearn.metrics import precision_score as ps
from sklearn.metrics import f1_score as fs
from sklearn.metrics import balanced_accuracy_score as bas
from sklearn.metrics import confusion_matrix as cm
import numpy as np
import pandas as pd
import datetime as dt
import sklearn
from scipy import stats
from sklearn import preprocessing
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score as rs
from sklearn.metrics import precision_score as ps
from sklearn.metrics import f1_score as fs
from sklearn.metrics import log_loss
rf = RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=2, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
classifier = AdaBoostClassifier(rf,50,0.01,'SAMME.R',10)
#Seperate TV in Generated Data
X1 = df_generated_data.loc[:, df_generated_data.columns != 'death']
Y1 = df_generated_data['death']
#Seperate TV in Original Data
X = df.loc[:, df.columns != 'death']
Y = df['death']
#Splitting Original Data
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2,random_state=0)
#Appending Generated Data to X_train
X_train1=X_train.append(X1, sort=False)
Y_train1=Y_train.append(Y1)
classifier.fit(X_train1,np.array(Y_train1).reshape(Y_train1.shape[0],1))
pred = np.array(classifier.predict(X_test))
recall = rs(Y_test,pred)
precision = ps(Y_test,pred)
r1 = fs(Y_test,pred)
ma = classifier.score(X_test,Y_test)
print('*** Evaluation metrics for test dataset ***\n')
print('Recall Score: ',recall)
print('Precision Score: ',precision)
print('F1 Score: ',f1)
print('Accuracy: ',ma)
| 公制 | 基本模型得分* | 用增強的生成資料評分 |
| 召回分數 | 0.75 | 0.83 |
| 精度分數 | 1 | 1 |
| F1分數 | 0.86 | 0.9 |
| 準確性 | 0.9 | 0.95 |
資料來源:表3基本模型指標
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7350612/
結論
與基本模型相比,所提出的模型提供了更加準確和可靠的結果,表明基于GAN的過采樣克服了不平衡資料的局限性,并適當地擴充了少數類,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/10/lets-improve-the-model-accuracy-of-imbalanced-covid-19-mortality-prediction-using-generative-adversarial-networks-gan-based-oversampling-technique/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/206950.html
標籤:其他