Hive原始碼閱讀(1)閱讀環境搭建
- 前言:讓學習成為一種習慣
- 環境準備
- Hive原始碼下載
- Hive原始碼目錄
- hive三個最重要的組件:
- 其他組件
- hive輔助組件
- 編譯原始碼
- 配置Hive本地除錯
- 配置IDEA-DEBUG(注意埠和Host)
- 開始Debug,配置成功圖片一張,入口類選擇了CLi,想看一下具體的原始碼執行流程
前言:讓學習成為一種習慣
作業已經兩年多了,各種各樣的大資料框架也使用過,各種官網也翻了很多,但是對于框架的底層原始碼從未細細的了解過,有一位大佬對我說如果你遇到瓶頸就去看看原始碼,看看別人的代碼怎么寫,看看別人的思想,然后總結歸納,與自己的思想相結合,于是我就有了閱讀原始碼的計劃,說實話這個計劃我糾結了很久,一直未付出實踐,糾結Flink,Spark,Hive,Hadoop原始碼我究竟該從那一方面下手,經過我苦苦思考,最終將目光放在了ApacheHive之上,Hive身為主流的資料倉庫框架,可以說已經很成熟了,并且應用廣泛,而且兼容Spark,Flink,所以我決定先從Hive原始碼開始,原始碼閱讀不是說你看這人家的原始碼全部讀一遍就是閱讀原始碼,這樣無非是浪費時間,首先定義重點,我們如何閱讀Hive原始碼,應該從那里下手,應該閱讀那幾部分的原始碼,廢話不多說,我們開始
環境準備
我推薦系統Linux或者Mac作為主系統,測驗過win但是沒有成功,準備以下環境
- JDK這是必備的,個人目前主要是使用JDK8;
- Hadoop單機環境,沒必要集群環境,因為我們只是為了閱讀原始碼,不是為了去執行計算;
- Spark環境,這個隨自己,主要是我自己本身就有這個環境,如果是新環境Hadoop+Hive就夠了;
- Maven這個是必須的;
Hive原始碼下載
- CDH原始碼
原始碼下載戳我 - 社區原始碼
原始碼下載戳我
(我沒有用過CDH的原始碼除錯,但是因為目前公司使用的是CDH環境,所以是有嘗試的想法)
Hive原始碼目錄
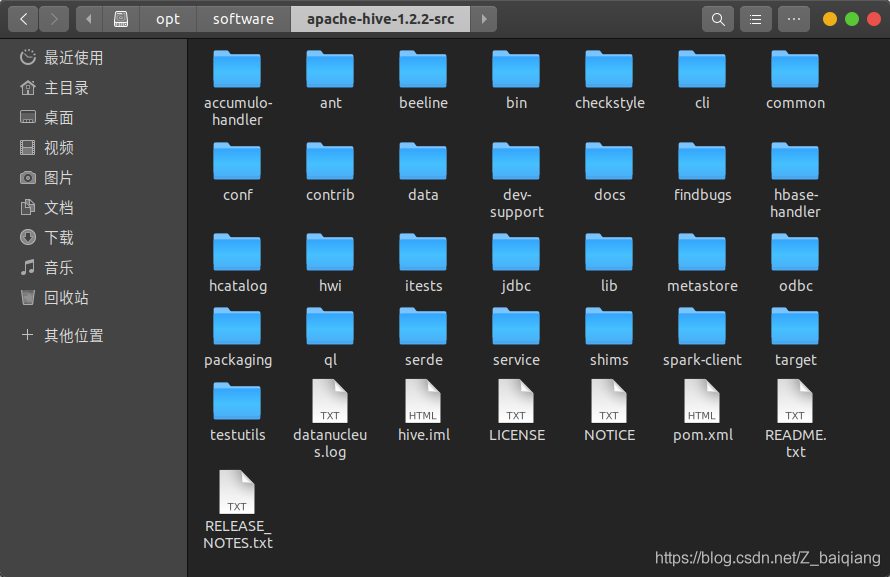
hive三個最重要的組件:
serde: 這個組件是 hive內置的一些序列化決議類,此組件允許用戶自己開發自定義序列化、反序列化檔案決議器
MetaStore: hive的元資料服務器,用來存放資料倉庫中所有表和磁區的資訊,hive元資料建表sql、升級sql腳本都存放在此目錄下
ql: 此組件用于決議sql生成執行計劃(hive核心包,熟讀此包,可了解hive執行流程核心)
其他組件
cli: hive命令的入口,用于處理命令列提交作業
service: 此組件所有對外api介面的服務端(通過thrift實作),可用于其他客戶端與hive互動,比如jdbc,
common: hive基礎代碼庫,hive各個組件資訊的傳遞也是有此包HiveConf類來管理,
ant: 此組件包含一些ant任務需要的基礎代碼
bin: 此組件包涵hive里的所有腳本,包括hivecli的腳本
beeline: HiveServer2提供的一個新的命令列工具Beeline
hcatalog: 是apache開源的對于表和底層資料管理統一服務平臺,HCatalog底層依賴于Hive Metastore
findbugs: Findbugs是一個在java程式中查找bug的程式,它查找bug模式的實體,也就是可能出錯的代碼實體,注意Findbugs是檢查java位元組碼,也就是*.class檔案,
hwi: hive web頁面的介面
shims: shims相關類是用來兼容不同的hadoop和hive版本
llap: 是基于tez的一種近實時查詢方案
hive輔助組件
conf: 此目錄包涵hive組態檔hive-default.xml、hive-site.xml
data: hive測驗所用資料
lib: hive運行期間依賴的jar
更多詳細資訊可以到官網看 ApacheHive
編譯原始碼
- 編譯命令:mvn clean package -DskipTests -Phadoop-2 -Pdist
mvn clean install -DskipTests -Phadoop-2 -Pdist
(二選一,注意依賴的Hadoop版本)
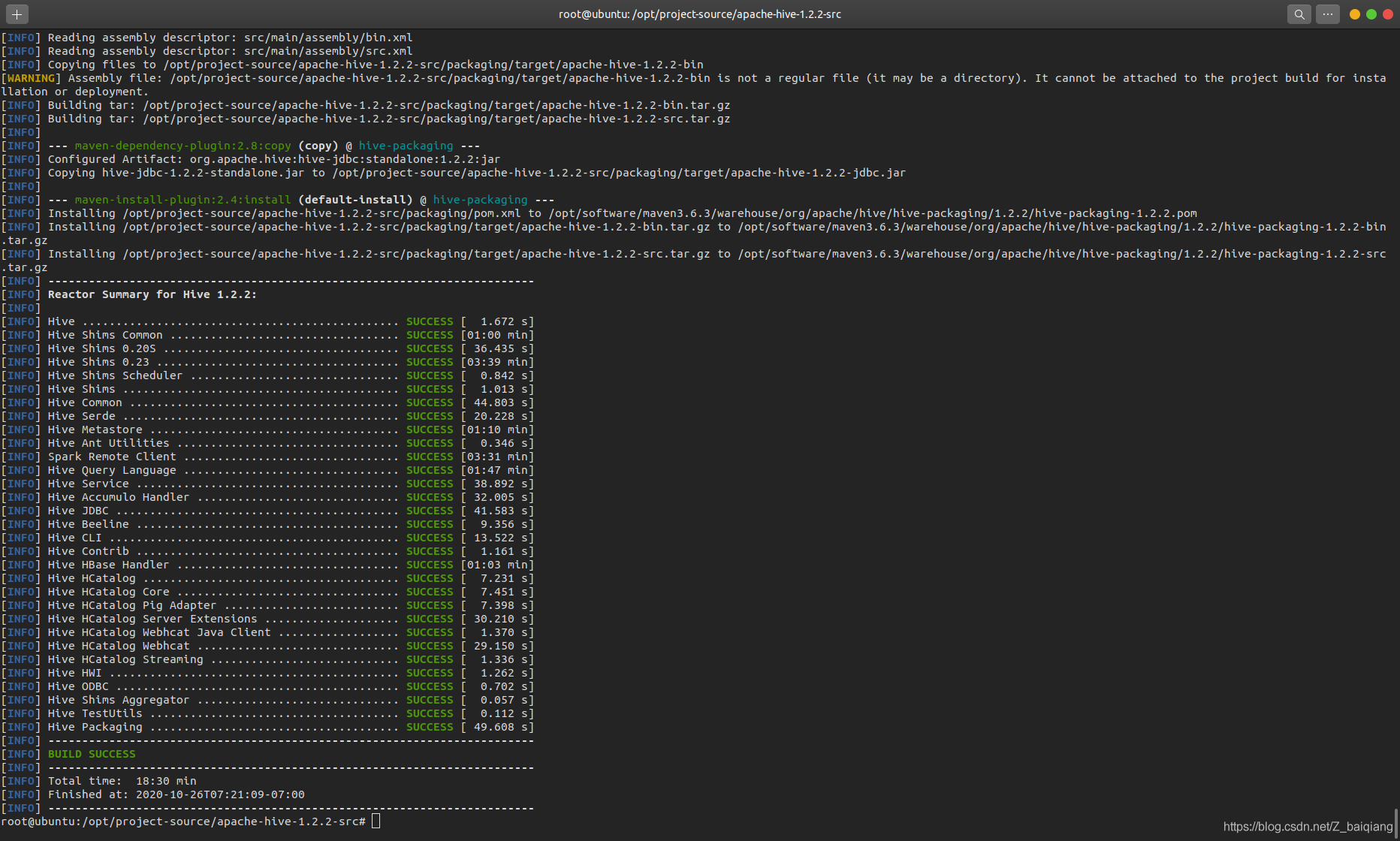
- 編譯完成后匯入IDEA
配置Hive本地除錯
- 配置Hadoop位置
進入/opt/software/apache-hive-1.2.2-src/packaging/target/apache-hive-1.2.2-bin/apache-hive-1.2.2-bin/conf
目錄復制目錄下的hive-env.sh.template為hive-env.sh(cp命令拷貝一份就行)
添加Hadoop所在目錄:export HADOOP_HOME=/opt/environment_variable/hadoop-2.6.0 - 初始化Hive元資料資訊
進入/opt/software/apache-hive-1.2.2-src/packaging/target/apache-hive-1.2.2-bin/apache-hive-1.2.2-bin
運行命令bin/schematool -dbType derby -initSchema(這里為了方便使用的是derby,也可設定為MySQL)
看到結果,說明成功;(圖都丟了,所以沒辦法,這個裝過Hive的應該都沒問題) - 啟動HiveDebug
hive --debug --hiveconf hive.root.logger=DEBUG,console
出現Listening即為成功
./hive --debug --hiveconf ^Cve.root.logger=DEBUG,console
Listening for transport dt_socket at address: 8000
配置IDEA-DEBUG(注意埠和Host)
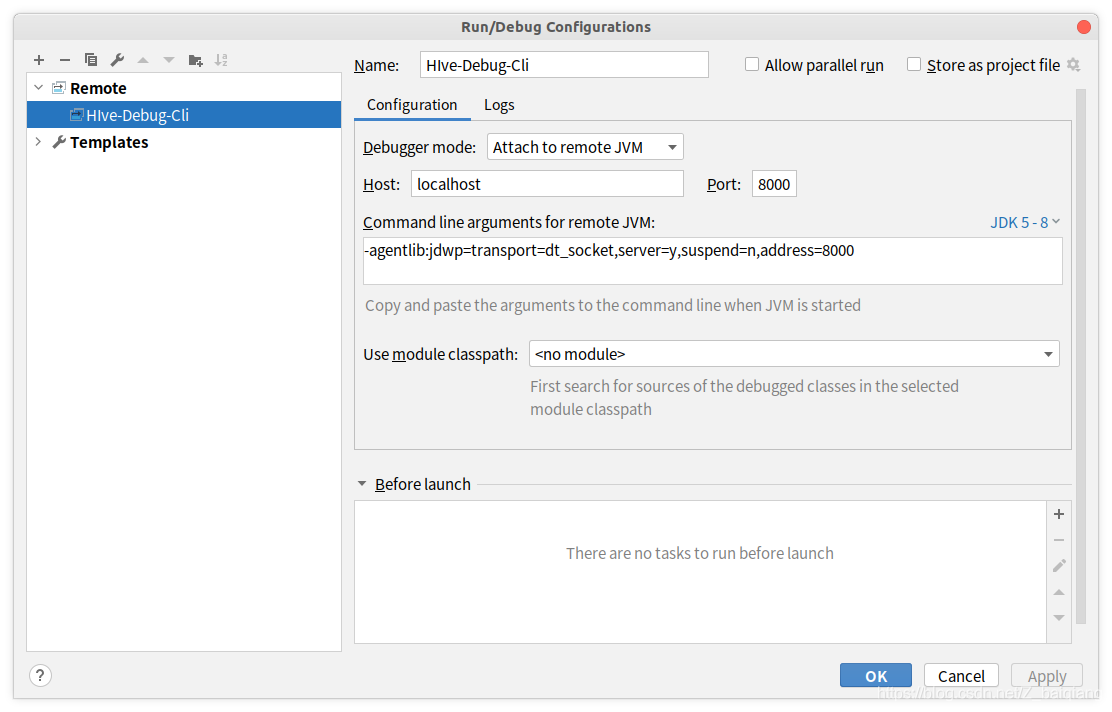
開始Debug,配置成功圖片一張,入口類選擇了CLi,想看一下具體的原始碼執行流程
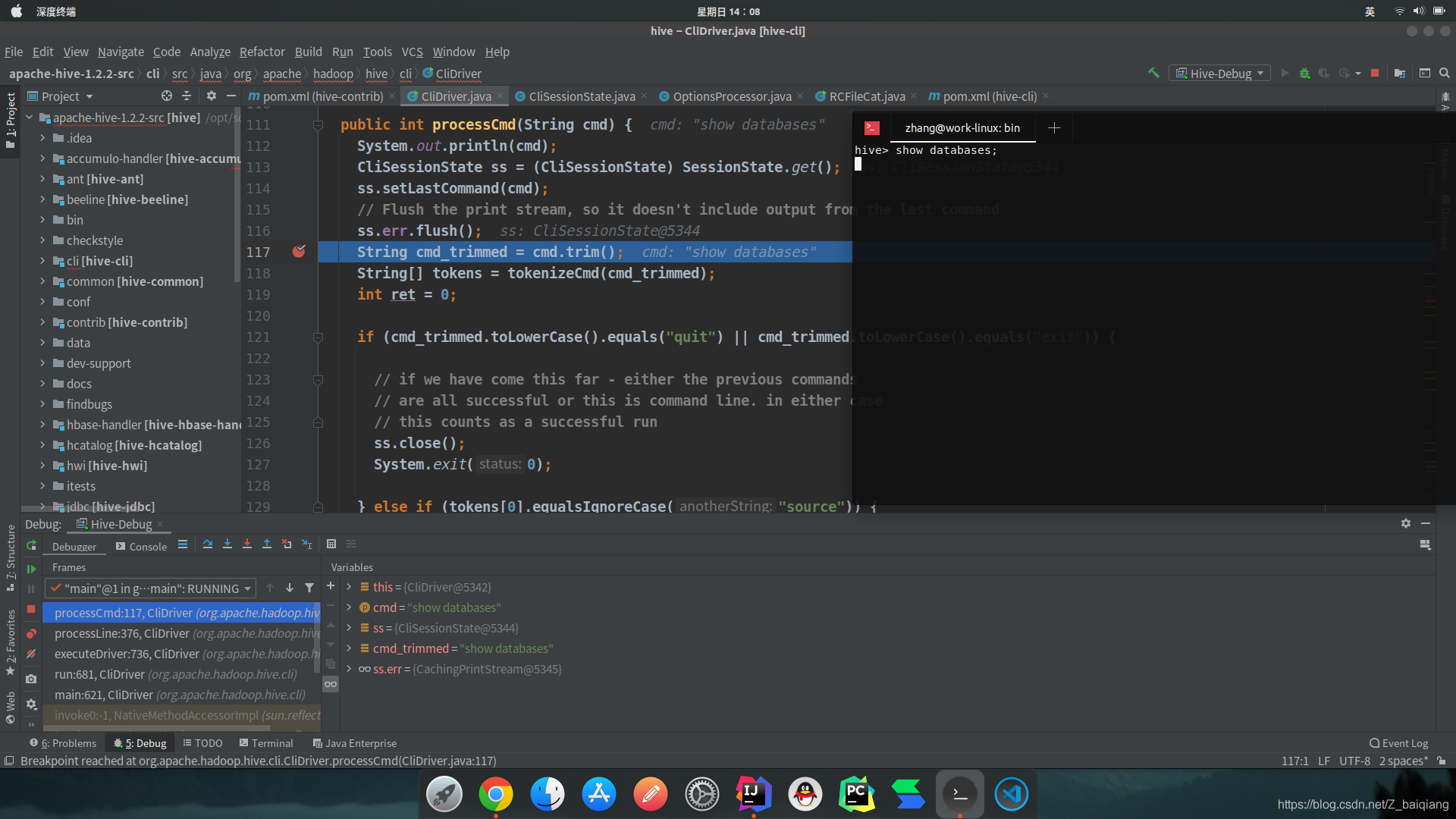
這里說一下,我沒有解決代碼報紅,因為爆紅也不影響Debug,但是有時間的最好解決一下,因為如果不解決會很坑的,本次文章就到這里拉,如果覺得作者的文章不錯,點個贊吧,開始我的原始碼閱讀之旅,之后每周都會更新一篇原始碼閱讀心得,在說一下如果有那位大佬測驗了CDH版本的希望可以指點一下小弟,感謝閱讀
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208508.html
標籤:其他
上一篇:搭建全分布式集群全程序
下一篇:雙十一秒殺系統這你搶得過嗎?