基于Ubuntu14.04.6單機偽分布式安裝Hadoop2.7.1
- 前言
- 一、創建用戶
- 二、安裝配置SSH
- 三、安裝Java環境
- 四、安裝hadoop
- 五、hadoop偽分布式配置
- 運行實體
前言
上一篇blog介紹了多節點Linux集群的構造,本篇blog介紹基于單一節點Hadoop偽分布安裝,有時間再嘗試多節點Hadoop安裝,Hadoop有三種安裝模式,分別是:
- 單機模式:所有程式都在單個JVM上執行,不使用HDFS,主要用于除錯MapReduce程式的應用邏輯,
- 偽分布模式:所有檔案儲存在單一節點上,所有的守護行程都運行在同一臺機器上,
- 集群安裝:存盤采用分布式檔案系統HDFS,而且,HDFS的名稱節點和資料節點位于不同機器上,這時,資料就可以分布到多個節點上,不同資料節點上的資料計算可以并行執行,這時的MapReduce分布式計算能力才能真正發揮作用,
一、創建用戶
添加一名“hadoop”用戶,并給與管理員權限,方便系統的部署,
- 創建新用戶hadoop
sudo useradd -m hadoop -s /bin/bash
- 設定密碼,按照提示輸入密碼
sudo passwd hadoop
- 設定管理員權限
sudo adduser hadoop sudo
二、安裝配置SSH
Ubuntu默認安裝了SSH client,還需要安裝SSH server,
sudo apt-get install openssh-server
安裝后需要使用密碼登錄本機,先看下是否安裝成功,
ssh localhost
每次登錄要密碼顯然不方便,需要配置為SSH無密碼登錄,設定方法如下:
exit # 退出剛才的 ssh localhost
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 采用rsa加密,在/home/當前用戶/.ssh目錄下找到id_rsa(私鑰)和id_rsa.pub(公鑰)
cat ./id_rsa.pub >> ./authorized_keys # 將公鑰追加到authorized_keys中(authorized_keys用于保存所有允許以當前用戶身份登錄到ssh客戶端用戶的公鑰內容)
代碼含義如注釋所寫,
最后,使用ssh localhost查看是不是不需要輸入秘鑰就可以直接登陸了,
三、安裝Java環境
下載JDK版本為1.8及以上的版本,創建安裝目錄,將檔案解壓到安裝目錄,
cd /usr/lib
sudo mkdir jvm #創建/usr/lib/jvm目錄用來存放JDK檔案
cd ~ #進入hadoop用戶的主目錄
cd Downloads #注意區分大小寫字母,剛才已經通過FTP軟體把JDK安裝包jdk-8u162-linux-x64.tar.gz上傳到該目錄下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK檔案解壓到/usr/lib/jvm目錄下
設定環境變數
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
讓配置生效
source ~/.bashrc
檢查是否安裝成功,回傳正確的版本資訊就是安裝成功了
java -version
四、安裝hadoop
到hadoop官網下載安裝檔案到本地,本文是基于2.7.1裝的,其他的版本好像也大差不差,
- 解壓,
sudo tar -zxf ~/下載/hadoop-3.1.3.tar.gz -C /usr/local # 解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 將檔案夾名改為hadoop
sudo chown -R hadoop ./hadoop # 修改檔案權限
- 檢查是否成功,如果回傳正確的版本資訊就說明可用,
cd /usr/local/hadoop
./bin/hadoop version
五、hadoop偽分布式配置
在偽分布式中,節點即作為NameNode也作為DataNode,同時讀取HDFS中的檔案,需要修改位于/usr/local/hadoop/etc/hadoop/ 中的core-site.xml 和 hdfs-site.xml兩個檔案,
1、修改core-site.xml 檔案
cd /usr/local/hadoop
vim ./etc/hadoop/core-site.xml
把檔案改為
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
上述配置是設定hadoop的臨時目錄(hadoop.tmp.dir)和分布式檔案系統的地址(fs.defaultFS),通過這個地址訪問分布式檔案系統的各種資料,
2、修改 hdfs-site.xml檔案
cd /usr/local/hadoop
vim ./etc/hadoop/hdfs-site.xml
把檔案改為
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication代表副本的個數,由于偽分布式檔案就只在一個機器上,副本數量設定為1,dfs.namenode.name.dir設定namenode的檔案保存位置;dfs.datanode.data.dir設定DataNode的檔案保存位置,
3、NameNode初始化
cd /usr/local/hadoop
./binfs namenode -format
4、開啟NameNode和DataNode守護行程
cd /usr/local/hadoop
./sbin/start-dfs.sh
如果出現SSH提示,輸入yes就好了
5、檢查是否啟動成功
jps
如果啟動成功就有以下界面:

如果少一個,就要查看提示資訊,看看是不是前面的配制出錯了,詳細檢查一下,
運行實體
通過簡單的實體看hadoop是否安裝成功
./bin/hdfs dfs -mkdir -p /user/hadoop #在HDFS中創建用戶目錄
./bin/hdfs dfs -mkdir input #在用戶目錄下創建一個input檔案夾
./bin/hdfs dfs -put ./etc/hadoop/*.xml input#把./etc/hadoop檔案下所有的xml檔案復制上傳到input檔案夾中
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+' #執行一個grep操作并將結果放到output的檔案夾中
./bin/hdfs dfs -cat output/* #查看檔案運行結果
如果出現以下結果說明安裝好了

雖然運行成功了,但發現老是出現Unable to load native-hadoop library for your platform… using builtin-java classes where applicable這個錯誤,雖然不影響運行結果,但這玩意還是挺煩的哈,于是就搜了一些資料,比較好的有:
- 解決 Unable to load native-hadoop library for your platform
- 解決unable to load native-hadoop問題
我的解決辦法:
vim ~/.bashrc #更改環境變數
在環境變數檔案中加入紅框中的三行內容
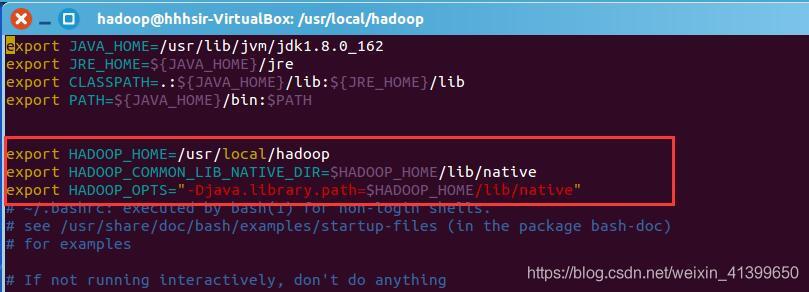
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
當然,保存后需要再次讓組態檔生效,
source ~/.bashrc
應該最后就不會報錯了,
說明:
博主本人還是屬于初級學習階段,很多東西沒解釋明白,如果有錯誤歡迎交流,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208513.html
標籤:其他
上一篇:python編程入門十三:遞回
下一篇:cgb2007-京淘day09