行人重識別閱讀筆記之Unity Style Transfer for Person Re-Identification
- 摘要
- 主要問題
- CamStyle的不足
- UnityGAN
- 論文貢獻
- 模型
- UnityGAN
- UnityStyle
- Deep Re-ID Model
- Pipeline
- Training
- Testing
- 總結
paper: https://arxiv.org/pdf/2003.02068.pdf
摘要
風格變換一直是ReID的一個主要挑戰,其目的是在不同的攝像機下匹配相同的行人,現有的研究試圖用相機不變描述子空間學習來解決這個問題,當不同相機拍攝的影像差異較大時,會產生更多的影像偽影,
為了解決這個問,作者提出了一種統一風格UnityStyle自適應方法,此方法可以平滑同一個攝像機和不同攝像機之間的風格差異,具體來說,首先創建UnityGAN來學習相機之間的風格變化,給每個相機生成形態穩定的風格統一影像,即UnityStyle影像,使用UnityStyle影像來消除不同影像之間的風格差異,使query和gallery之間更好的匹配,
主要問題
由于環境、光線等因素的影響,每個攝像頭拍攝的影像風格對于同一個人往往是不同的,即便是同一個攝像機,也會因為時間不同,拍出風格不同的照片,因此,影像的風格變化,對最終結果有相當大的影響,
解決思路是在不同的攝像機之間獲得穩定的特征表示,此前的方法:
1、傳統方法有KISSME、DNS等,
2、IDE、PCB通過深度表示學習來解決,
3、使用GANs學習不同相機之間的風格差異,通過風格轉移的方法對資料進行增強,從而得到CamStyle,
CamStyle的不足
本文對前者方法CamStyle指出不足之處:
1、在CycleGAN生成的轉移樣本中會有影像偽影,尤其是對于成型部分,生成了大量的錯誤影像,
2、生成的影像增強會給系統帶來噪音,需要用標簽光滑正則化Label Smooth Regularization(LSR)需要調整網路性能,
3、生成的增強影像只能作為擴展訓練集的資料增強方法,效果不明顯,
4、需要訓練的模型數量是C2?C(C是攝像機的個數),這意味著隨著攝像機的增加,需要訓練的模型將越來越多,這不適用于算力不足的場景,
UnityGAN
針對上述問題,本文構建了一種UnityStyle自適應方法,用于平滑同一個攝像機內部和不同攝像機之間的風格差異,作者使用UnityGAN來克服CycleGAN容易變形的問題,利用UnityGAN學習的每個攝像頭的style資料,得到適合所有相機風格的UnityStyle影像,使得生成的增強影像更加高效,最后,結合真實影像和UnityStyle影像作為新的資料增強訓練集,
UnityStyle自適應方法具有以下優點:
1、作為一種資料增強方案,生成的增強樣本可以與原始影像一樣處理,因此UnityStyle影像不再需要LSR,
2、通過適應不同的攝像機模式,它對同一個攝像機內的樣式變化也具有魯棒性,
3、不需要額外的資訊,而卻所有增強都來自ReID任務,
4、只需要訓練C個UnityGAN模型,不需要太多的計算資源,
論文貢獻
綜上所述,本文的貢獻可以概括為:
1、提出UnityStyle方法,用于生產形態穩定、風格變化的增強影像,并與真實影像等效,不在需要LSR,
2、UnityStyle不需要訓練大量的模型,只需要使用少量的計算資源來訓練C個模型,
模型
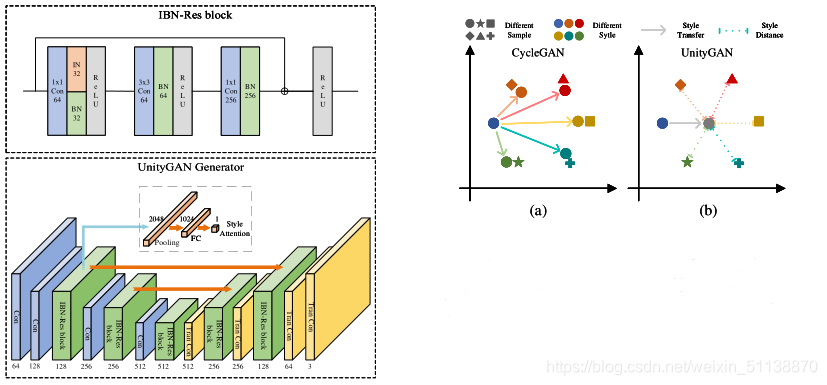
UnityGAN
UnityGAN集合了DiscoGAN和CycleGAN的優點,并加以改進,其中DiscoGAN使用標準架構,其狹窄的瓶頸層bottleneck layer可能會阻止輸出影像在輸入影像中保留視覺細節,CycleGAN引入了殘差快residual blocks來增加DiscoGAN的容量,但是在單個尺度層上使用殘差塊并不能在多個尺度層上保留資訊,
UnityGAN結合了兩個網路,在多尺度層引入殘差塊和跳轉鏈接,可以同時保留多尺度資訊,使變化更加精確和準確,通過多尺度的傳遞,UnityGAN可以生產結構穩定的影像,避免生產結構錯誤的影像,與CycleGAN不同的是,UnityGAN試圖生產一張混合所有樣式的圖片,而不必學習每個樣式的轉換,
此外,創建一個IBN-Res塊,它可以保證結構資訊的同時增強樣式變化的健壯性,在UnityGAN模型中添加IBN-Res塊,使模型適應風格變化,確保模型生成同一風格的偽影像,
給定影像域X和Y,設G:X->Y,F:Y->X,DX和DY分別表示G和F的鑒別器,為了改變樣式的同時保留影像的特征資訊,在公式中加入了身份映射損失identity mapping loss,身份映射損失可以表示為:
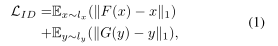
因此,UnityGAN的損失函式包含四種損失歸一化項:標準GANs損失、特征匹配損失、身份映射損失和回圈重建損失,
總目標函式是: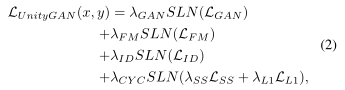
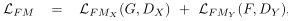
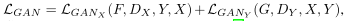
其中,SLN是調度損失歸一化 scheduled loss normalization,
λGAN+λFM+ λID+ λCYC= 1, λSS+ λL1= 1,所有系數都>0,
在訓練程序中,將訓練集的每個攝像頭和所有攝像頭作為一組來訓練一個UnityGAN模型,UnityGAN可以生產穩定的結構影像,減少訓練模型的數量,但是UnityGAN生產的影像在風格上不穩定,為了解決這個問題,提出了UnityStyle loss函式,以確保UnityGAN生成 的影像風格穩定,
UnityStyle
UnityStyle影像是由UnityGAN生成的,可以平滑同一個攝像機內和不同相機之間的風格差異,利用UnityStyle影像進行模型訓練和預測,提高模型的性能,
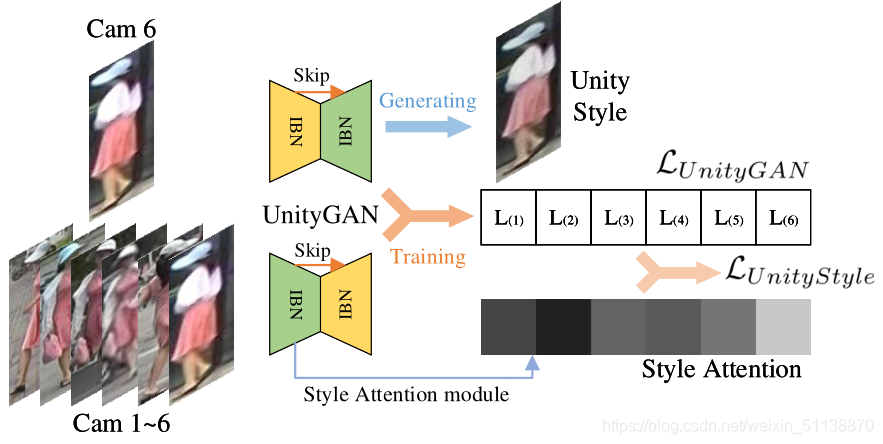
為了保證UnityGAN能夠生成UnityStyle影像,作者在UnityGAN生成器中添加了Style Attention模塊,通過這個模塊,底層影像特征得到Style化的注意特征,定義輸入影像x的Style Attention為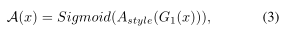
其中Astyle是Style Attention模塊,G1是UnityGAN生成器的第一個IBN-Res塊的輸出,
最終UnityStyle loss函式為: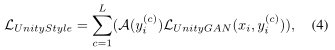
其中,c是攝像機編號,C是攝像機數量,A(yi)是第i個攝像機的style attention,
在此loss函式的約束下,模型會生產一副風格穩定的影像,該影像的風格介于所有攝像機風格之間,
Deep Re-ID Model
這里論文中以IDE舉例嵌入他們的方法,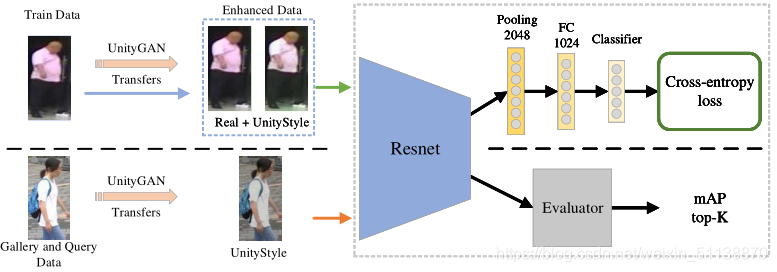
輸入影像大小指定為256x128,在訓練程序中,需要確保最終分類層輸出和訓練集中的標簽數量一致,如上圖所示,將最后一層分類層替換為兩個全連接層,在測驗程序中,使用模型的2048維特征輸出進行評估,Evaluator使用輸出特征計算平均精度(mAP)和top-K(表示正確結果在K個top檢索結果中所占比例)
Pipeline
Training
在訓練之前,使用訓練好的UnityGAN Transfers來生成UnityStyle影像,結合真實影像和UnityStyle影像作為增強的訓練集,在訓練中,以增強后的資料量中的影像作為輸入,大小指定為256x128,隨機抽取N副真實影像 和N副UnityStyle影像,根據上述定義,得到損失函式: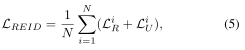

其中,xR是真實影像樣本,xU是UnityStyle影像樣本,LCross是交叉熵損失函式,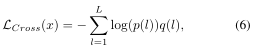
其中L是標簽數量,p(l)是x的標簽被預測為l的概率,q(l) = {1 if l = y|0 if l 6=y}是真實分布,根據前面的描述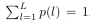
在q(l)中,y是當前影像對應的真實標簽,
對于有真實標簽y的x,根據公式(6)可以得到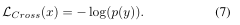
進一步根據公式(7)和公式(5),可以得到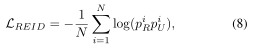
這里,piR是第i個真實影像被正確預測的概率,piU是第i個UnityStyle影像被正確預測的概率,
Testing
為了進行測驗,將其分為查詢資料集和圖庫資料集,前面引入UnitStyle的概率,以確保兩個資料集的影像在開始測驗之前通過UnityStyle傳輸生成相應的UnityStyle影像,使用生成的UnityStyle影像作為新的輸入進行測驗,UnityStyle縮小了測驗集中元素樣式之間的差異,可以進一步提高查詢性能,
總結
在我看來本篇論文可以說是做為一種資料增強的方法更貼切,所做的作業看上去就是在增強資料,
核心思想是通過GANs生成影像來盡可能的減小攝像頭之間以及攝像頭影像內部的風格差異,
其方法是通過所構建的UnityGAN來集合所有攝像頭中同一行人的影像來生成符合所有攝像頭不同風格的影像,其中影像生成被UnityStyle約束,然后以生成的UnityStyle影像并上真實影像作為增強資料集去訓練模型,在預測階段使用UnityGAN來生成符合模型風格的偽影像進行預測,相當于訓練和測驗都進行了資料預處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208681.html
標籤:其他
上一篇:速學-分布式系統與一致性協議