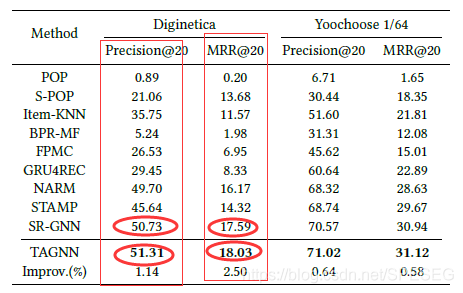
hi本文是gnn系列的延續,前面可參考,TAGNN,SRGNN,LightGCN,根據論文資料比較,GCE-GNN要比TAGNN的效果好很多,如下是同一資料同一指標的對比,可見一斑,考慮到TAGNN并沒有比SRGNN高很多,本菜鳥打算放棄TAGNN了,舍得,
For Video Recommendation in Deep learning QQ Group 277356808
For Visual in deep learning QQ Group 629530787
I'm here waiting for you
別加那么多,沒必要,另外,不接受這個網頁的私聊/私信!!!
年終粉絲福利大獎(代碼)在文末,敬請期待,保持關注,paper地址在此,
paper作者是97的,華科就是牛逼,厲害,
1-現有問題及解決方案
幾乎所有存在的基于會話的推薦擬合用戶的偏好僅僅基于當前會話,而不考慮其他會話,對于當前會話可能包括很多相關和不相關的item轉換,本文提出一個新的方法,全域背景提升GNN,也就是GCEGNN,來發掘item在所有會話中的轉換,特別的,GCEGNN學習兩種item embedding,分別從會話圖和全域圖,會話圖中,通過擬合pairwise item轉換來學習會話級別item embedding;全域圖中,則是全部的會話,在GCEGNN中,提出的新的全域級別item表示學習層是采用會話意識注意力機制【啊啊啊,哪都是注意力,這個面試肯定考】遞回整合全域節點鄰近點的embedding,同時也設計了一個會話級別的item表示學習層,采用的是一個GNN,另外,GCEGNN通過軟注意力機制聚合學習到的表達,試驗證實方法不錯,
2-基本概念與定義
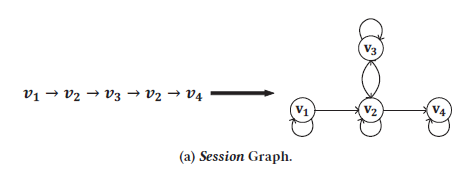
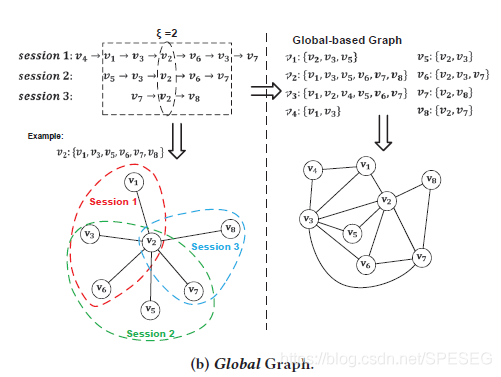
SRGNN是基于gnn的self-attention機制,它通過計算基于會話的每個item和最后一個item之間的pairwise item轉換 的重要性 學習到全部會話的表達,最后的效果嚴重依賴于最后一個item與當前會話用戶喜好的相關性,如圖所示是一個全域級別的item轉換的簡單示例,
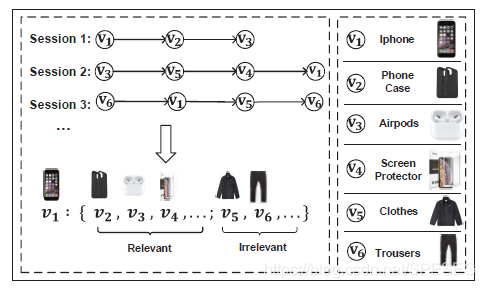
假設當前的會話是Session 2,推薦的目的是給iPhone手機推薦相關的配件,從下圖中觀察得知,1)-使用其他會話的item轉換可能會有助于于擬合用戶的偏好,例如,從session 1和session 3中可以發現Session 2相關的pairwise item轉換資訊,如一個新的pairwiseitem轉換[iPhone, Phone Case]【注意,我發現transition翻譯成轉移其實應該合理點,轉換get不到那個點】;2)-直接使用全部的其他會話的item 轉換資訊可能會引入噪聲,當他們中有不相關的item轉換資訊
定義:
為所有的items,每個匿名的會話定義為
,item個數為l,時間順序,給定會話S,推薦topk個用戶最大可能點擊的items
3-圖模型,會話圖和全域圖
會話圖模型目的是學習會話級別的item embedding,通過擬合會話序列鄰近的item 對,每個會話序列通過GNN轉換成會話圖,定義為如下:
給定會話S,令為相應的會話圖,第一個是V的子集,第二個定義邊集,也就是邊的集合,例如其中一個
,這就是會話級別的item轉換模式,每個item增加一個自我回圈(如下圖),本文定義四種邊,分別是
,對于
,
表明僅存在從后者到前者的轉移,
僅存在前者到后者的轉移,
表示存在兩種情況,最后一個很好理解,就是下圖的這種情況【增加的一個自我轉移】,與傳統的基于深度學習的方法不同,會話圖可以捕獲復雜的圖模式,學到會話級別的item embedding
全域圖模型,考慮全域級別的item轉換,通過整合sessions內所有item轉換對,提出的全域圖模型認為,序列之間不是獨立的,而是items對相連的,首先定義個概念,鄰集,也可表示為𝜀-neighbor set,對于會話
中的任意item
,其鄰集為:
![]()
其中i是順序,也就是索引,𝜀是超引數,用來控制item的范圍,注意𝜀偏向于小范圍item轉換,因為它對捕獲全域級別的item轉換資訊,當超出𝜀范圍后幫助很少,
根據上面的定義,對每個item 全域級別的item轉換定義為{(𝑣𝑖, 𝑣 𝑗 ) |𝑣𝑖, 𝑣 𝑗 ∈ 𝑉 ; 𝑣 𝑗 ∈ N𝜀 (𝑣𝑖 )},
這里不區分item轉換的方向性,全域圖可定義為,前者是圖節點,包含所有的item,后者是邊,如圖下是𝜀=2的全域圖,【注意,因為i是索引,與i進行加減運算的肯定也是索引單位,所以這里的𝜀就是下圖的中2個,恰好圖中正方形圈起來的是i=2,𝜀=2的圖】對每個節點,得到其鄰邊權重去區分它的鄰近節點的重要性,對于每個邊(𝑣𝑖 , 𝑣 𝑗) ,使用其在所有會話中頻率作為相應邊的權重,對每個item只要topn個最高權值的邊,注意,全域圖是無方向的,因為鄰集是無方向的,從效率方面考慮,在測驗階段不會動態更新這種拓撲結構,在V中的每個item都通過one-hot進行統一編碼到統一embedding空間,接著轉換為d維度的隱語意空間,通過一個可訓練的權值矩陣W0.
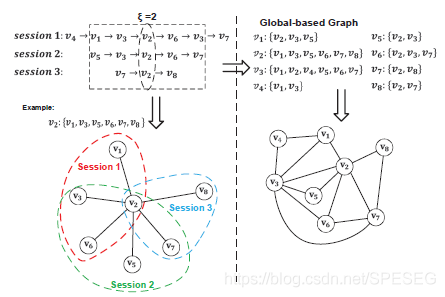
【關于上面左圖的進一步說明,當i=2,𝜀=2時,v2的鄰集就是左下方箭頭所指的(如果展示的只是v2的鄰集,那么v1怎么會和v2直接相連呢?還有v5),v2的鄰集只有{v1,v3,v5,v6,v7,v8},而當𝜀不等于2,或者i不是2,那就構成了全域圖,右邊的部分其實我沒看懂,見我的issue吧】
4-理論分析
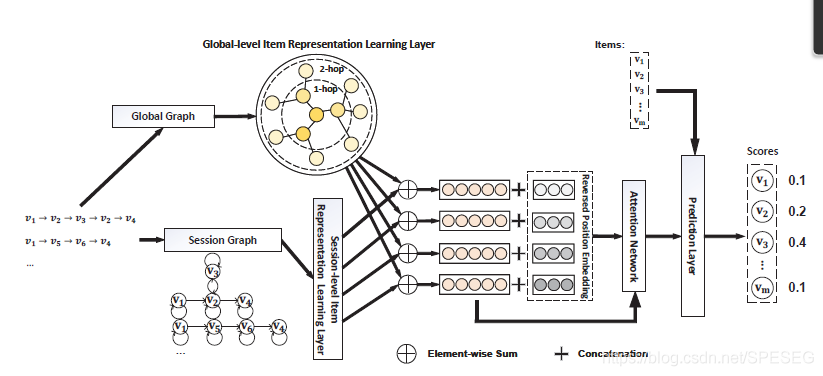
正如第2個圖(表不是圖),展示了GCEGNN的基本結構,1)-全域級別的item表示學習層,在所有會話中采用會話意識的注意力機制遞回整合每個節點鄰居embedding得到全域級別item embedding;2)-會話級別item表示學習層,采用GNN模型學習到會話級別的item embedding;3)-會話表示學習層,通過聚合學習到的前兩者擬合用戶在當前會話的偏好;4)-預測層,輸出推薦的item概率,下面分開詳解,
1)包括兩個部分,資訊傳遞和資訊聚合,
資訊傳遞,一個item可能在多個會話中都有,因此可以得到有用item轉移資訊,有助于當前的預測,為獲得item v的一階鄰居特征,一個直接方法是均值pooling,然而并不是所有的v的鄰集中的item都與用戶的偏好相關(在當前會話中),因此,考慮使用會話注意力區分其鄰集中item的重要性,因而,鄰集中的item的注意力分數可由以下得到,
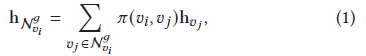
![]()
2式估計item 鄰居的重要性權值,離item越近的越重要,選擇LeakyRelu激活函式,還有點積和拼接符號,W1和q1是訓練的引數,s可視為當前會話的特征,可通過計算當前會話中item表示的均值得到:

與均值pooling不同,提出的方法使得資訊的傳播依賴于S和v中的關系,也就是說,適合當前會話的鄰居則更受喜愛,
采用softmax函式對2式進行歸一化(如下),最后的分數是哪個節點更需要關注,
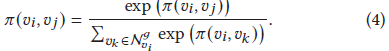
資訊聚合,拼接item的表示和其鄰居的表示,采用relu激活,W2是轉移權重,
![]()
可以探索高階連接資訊,通過擴展多層聚合,這樣允許更多與當前會話有關的資訊整合到當前表示,得到如下,這就確保更多有效的資訊整合到當前會話的表達,
![]()
2)因為會話圖中item的鄰居對item有不同的重要性,采用注意力機制學習不同節點之間的權值,注意力系數可以通過計算每個item之間的內積和非線性轉換得到,
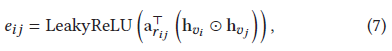
7式是節點vj對節點vi的重要性,選擇LeakyRelu激活函式,r是vi和vj之間的相關性,r和a是權值向量,正如3中所示,訓練4個權值向量,即.因為并不是所有兩個節點都連接,只需計算鄰集中節點的7式,為了不同節點系數相容,采用softmax歸一化注意力權值
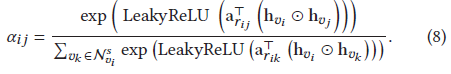
8式中的注意力系數并不對等,因為其鄰居不同,也就是說,他們相互的貢獻是不同的【一句話道出了難找物件的真實原因】,通過線性轉換得到每個節點的輸出特征,
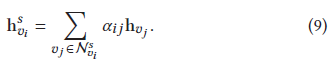
會話圖中的item表達由它自己及鄰居的特征聚合得到,通過注意力機制,會話級別item表達的噪聲影響減少了,
3)對于每個item,通過整合全域背景和會話背景得到其表達,最終的表達是通過sum pool得到(也就是直接相加):
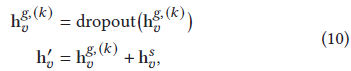
而對于全域級別的表達采用dropout避免過擬合,不同于之前paper中只關注于最后一個item,此文采用綜合策略學習會話中每個部分,會話表達基于會話中所有item來構建,不同item對于下個item的預測是不等的,很顯然,用戶最新的點擊更能代表用戶當前的偏好,然而,發現用戶的主要目的和過濾噪聲才是重要的,因此整合反轉位置資訊和會話資訊做一個好的預測,喂給gnn一個會話序列后,得到item的表達,同時使用一個位置embedding矩陣P = [p1, p2, ..., p𝑙 ],l是會話的序列長度,通過拼接和非線性轉換整合位置資訊,
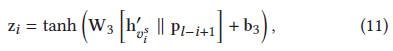
采用反轉位置embedding的原因是會話的序列長度是不固定的,對比正向位置資訊,當前item到預測的item之間的距離包含更多有效的資訊,例如會話中{𝑣2 → 𝑣3 →?},v3是第2個,對于預測的item很有影響,但對于會話{𝑣2 → 𝑣3 → 𝑣5 → 𝑣6 → 𝑣8 →?},v3的影響就不是那么大了,很小了,因此,相反的位置資訊更準確【個人解讀,位置越大影響越小, 也就是相反的 】通過計算會話中item的平均得到會話表達,

通過軟注意力機制得到相應的權值(如下13式),W4和W5,q2和b4均是可學習的引數,會話表達S可通過線性轉換item表達得到14式,
![]()

會話表達S中的item的貢獻由其在會話圖中資訊及序列中的順序決定,
4)得到會話表達S后,最終每個item推薦的概率基于它們最初的embedding及當前會話的表達,先用點積再用softmax得到15式,?y𝑖是當前會話中下個點擊中出現的概率,損失函式由交叉熵得到:y是one-hot編碼
![]()
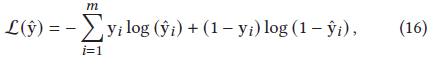
5-試驗
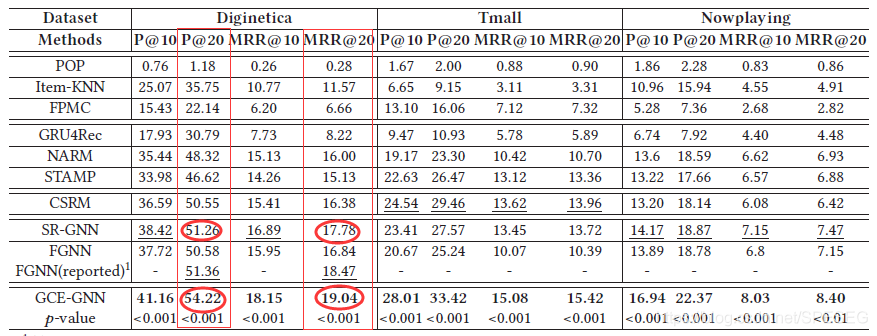
如果你對我之前的代碼(博文)比較熟悉的話,GCE-GNN代碼里面其實與SRGNN及TAGNN是一樣的資料處理流程【盡可能點擊我提到的鏈接,都不一樣的】
1)評估全域級特征編碼和會話級別特征編碼,主要有4個模型對比:
GCE-GNN w/o global:沒有全域級特征編碼,只有區域特征
GCE-GNN w/o session:沒有會話級特征編碼,只有全域特征
GCE-GNN-1-hop:全域級特征編碼,hop設為1,只有1圈,如圖2,也就是第2個鄰居
GCE-GNN-2-hop:hop為2,
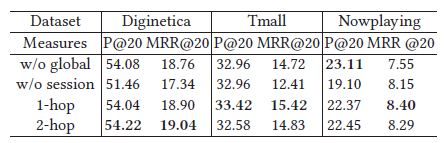
考慮到計算量,hop為1即可,這是我說的,
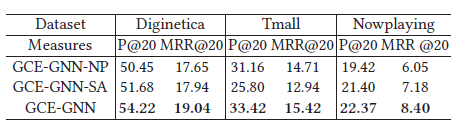
2)盡管有SASRec中正向位置權重對模型有提高的效果,但下面證實這種效果是有限的,
GCE-GNN-NP:帶有正向位置權值,而不是反向的
GCE-GNN-SA:帶有self-attention而不是position-aware attention
3)因為采用區域和全域特征編碼,所以對比GCEGNN中不同的聚合操作是有意義的,例如,門,max pooling,拼接,如下表明,sum pooling是最佳
在門機制中,采用線性插值在區域特征表達和全域特征表達之間,采用sigmoid激活函式,是可學習的,用來平衡兩個特征的重要性,如下:
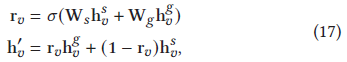
對于max pool,取每個維度的最大值,第i個維度的item表達是:g代表全域,s代表會話
![]()
對于拼接操作,最終的表達是下面兩者的拼接,M是轉換權值,
![]()
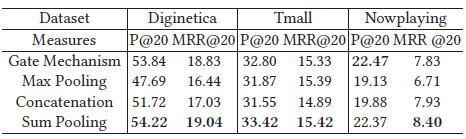
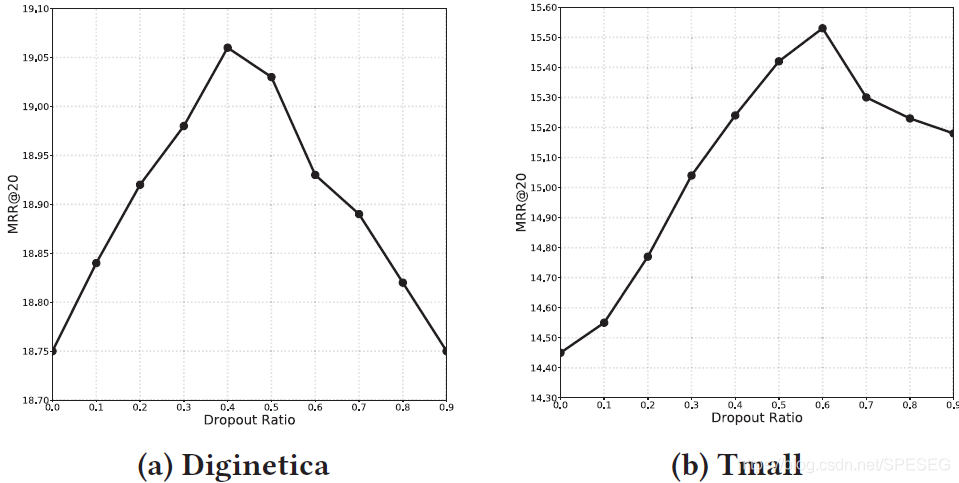
4)在訓練中以概率p隨機丟掉神經元,在測驗中則用所有的,如下可知,0.4,0.6對應的資料不錯,小明哥建議0.3即可
6)代碼
然而卡在了安裝這個破玩意torch_geometric,錯誤一堆咋整啊,想到之前的博文,猜想可能要安裝exe,后來發現wine沒有(sudo 裝不了),
ERROR: Command errored out with exit status 1:
command: /home/xulm1/anaconda3/bin/python -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-xny0ior0/torch-scatter/setup.py'"'"'; __file__='"'"'/tmp/pip-install-xny0ior0/torch-scatter/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-install-xny0ior0/torch-scatter/pip-egg-info
cwd: /tmp/pip-install-xny0ior0/torch-scatter/
Complete output (34 lines):
WARNING: The repository located at pip.ifengidc.com is not a trusted or secure host and is being ignored. If this repository is available via HTTPS we recommend you use HTTPS instead, otherwise you may silence this warning and allow it anyway with '--trusted-host pip.ifengidc.com'.
WARNING: The repository located at pip.ifengidc.com is not a trusted or secure host and is being ignored. If this repository is available via HTTPS we recommend you use HTTPS instead, otherwise you may silence this warning and allow it anyway with '--trusted-host pip.ifengidc.com'.
ERROR: Could not find a version that satisfies the requirement pytest-runner (from versions: none)
ERROR: No matching distribution found for pytest-runner
Traceback (most recent call last):
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/setuptools/installer.py", line 126, in fetch_build_egg
subprocess.check_call(cmd)
File "/home/xulm1/anaconda3/lib/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['/home/xulm1/anaconda3/bin/python', '-m', 'pip', '--disable-pip-version-check', 'wheel', '--no-deps', '-w', '/tmp/tmpuix7xn3n', '--quiet', 'pytest-runner']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-xny0ior0/torch-scatter/setup.py", line 52, in <module>
packages=find_packages(),
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/setuptools/__init__.py", line 152, in setup
_install_setup_requires(attrs)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/setuptools/__init__.py", line 147, in _install_setup_requires
dist.fetch_build_eggs(dist.setup_requires)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/setuptools/dist.py", line 676, in fetch_build_eggs
replace_conflicting=True,
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/pkg_resources/__init__.py", line 766, in resolve
replace_conflicting=replace_conflicting
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/pkg_resources/__init__.py", line 1049, in best_match
return self.obtain(req, installer)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/pkg_resources/__init__.py", line 1061, in obtain
return installer(requirement)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/setuptools/dist.py", line 732, in fetch_build_egg
return fetch_build_egg(self, req)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/setuptools/installer.py", line 128, in fetch_build_egg
raise DistutilsError(str(e)) from e
distutils.errors.DistutilsError: Command '['/home/xulm1/anaconda3/bin/python', '-m', 'pip', '--disable-pip-version-check', 'wheel', '--no-deps', '-w', '/tmp/tmpuix7xn3n', '--quiet', 'pytest-runner']' returned non-zero exit status 1.
----------------------------------------
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.$ wine vcredist_x86.exe
No command 'wine' found, did you mean:
Command 'wing' from package 'wing' (universe)
Command 'twine' from package 'twine' (universe)
Command 'line' from package 'util-linux' (main)
Command 'win' from package 'wily' (universe)
Command 'xine' from package 'xine-ui' (universe)
Command 'wipe' from package 'wipe' (universe)
wine: command not found
看了相關issue,解決了這個問題,當然我在此之前也升級了torch,也可參考這里的安裝方法及錯誤解決方法
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html執行中又出錯了,WOC,這個類MultiSessionsGraph繼承的InMemoryDataset,使用繼承super后,它自己將資料train.txt和test.txt洗掉了,然后下面又讀取這個破檔案,我去,還有這種神仙操作,服氣啊,咋整啊?有點懵逼啊,去掉super它又告訴我啥幾把沒有定義,
Processing...
Traceback (most recent call last):
File "mymain.py", line 83, in <module>
main()
File "mymain.py", line 36, in main
train_dataset = MultiSessionsGraph(cur_dir + '/datasets/' + opt.dataset, phrase='train')
File "/data1/xulm1/GCE-GNN/pytorch_code/graph_loader.py", line 15, in __init__
super(MultiSessionsGraph, self).__init__(root, transform, pre_transform)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/torch_geometric/data/in_memory_dataset.py", line 54, in __init__
pre_filter)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/torch_geometric/data/dataset.py", line 92, in __init__
self._process()
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/torch_geometric/data/dataset.py", line 165, in _process
self.process()
File "/data1/xulm1/GCE-GNN/pytorch_code/graph_loader.py", line 31, in process
data = pickle.load(open(self.root + '/' + self.raw_file_names[0], 'rb'))
FileNotFoundError: [Errno 2] No such file or directory: '/data1/xulm1/GCE-GNN/pytorch_code/datasets/diginetica/train.txt'
后來發現一個github確實是這么用的,而且SRGNN官方github也提及了,我試試看看
發現人家用的下面的,但我換成這個也是不行啊,
data = pickle.load(open(self.raw_dir + '/' + self.raw_file_names[0], 'rb'))Traceback (most recent call last):
File "mymain.py", line 83, in <module>
main()
File "mymain.py", line 36, in main
train_dataset = MultiSessionsGraph(cur_dir + '/datasets/' + opt.dataset, phrase='train')
File "/data1/xulm1/GCE-GNN/pytorch_code/graph_loader.py", line 15, in __init__
super(MultiSessionsGraph, self).__init__(root, transform, pre_transform)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/torch_geometric/data/in_memory_dataset.py", line 54, in __init__
pre_filter)
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/torch_geometric/data/dataset.py", line 92, in __init__
self._process()
File "/home/xulm1/anaconda3/lib/python3.7/site-packages/torch_geometric/data/dataset.py", line 165, in _process
self.process()
File "/data1/xulm1/GCE-GNN/pytorch_code/graph_loader.py", line 30, in process
data = pickle.load(open(self.raw_dir + '/' + self.raw_file_names[0], 'rb'))
FileNotFoundError: [Errno 2] No such file or directory: '/data1/xulm1/GCE-GNN/pytorch_code/datasets/diginetica/raw/train.txt'
我暫時不知道哪句把它給刪了,我去,我也是服了這種操作,完全無法復現啊,,這種福利不知道有人接沒?【這是坑啊,哪個大佬搞定了教我下,多謝,我順便提個issue吧】
順便將我上面的paper中的不理解的問問paper作者,發郵件試試,也順便看看能不能公開代碼,
拜拜
天造之才,皆有其用
振翅高飛,無需在夢中
【20201109補充】
作者凌晨就答復我了,厲害,果然大佬都是不睡覺的大神,兩個國人用英語交流,也是厲害,哈哈,國際化,潮流,
現在理解了點,對于下圖,作者說選定的窗長是2,選定中心item為v2,那么窗長為2范圍內的皆為它的鄰居(認為是相關的),可以直接相連,回答了我的第2個問題;右邊v1的鄰集寫錯了,若以v1為中心item,窗長為2,那么其鄰集為{v2,v3,v4},作者寫錯了,他是這么說的,回答了我的第1個問題;由前述可得右邊下邊的圖,關于我的第3個問題,大佬說下個月底開源,敬請期待【搓手手】
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208748.html
標籤:其他
上一篇:游戲魂,技術夢